 SoC常见问题 - axi deadlock
SoC常见问题 - axi deadlock
最近多个项目并行,实在是没有时间分享了,今天在评论区看到了一个非常有意义的问题,同样也是社招,校招最常见的问题。那就是AXI协议怎么避免死锁呢?
两种死锁场景分别是乱序读和写交织,有的人更熟悉英文,那就是out of order和interleaving。下面我们分析原因。
乱序读:我们知道AXI协议支持乱序读,那么为什么能实现呢?这也是常见面试题目,那就是因为AXI(现在单指AXI3)每个通路都有相应的ID,通过请求和响应ID的一致来将打乱的顺序恢复。
现在假设M1发给S1的请求ID可以是1,2,3,M1发给S2的ID可以是3,4,5。现在M1分别发起了两组outstanding传输给S1和S2,RID是随机的,也就是ARID_S1和ARID_S2存在都是3的可能。并且如图,S1/S2响应的时间是不同的,所以也就存在S1和S2 RID=3的响应顺序是不确定的,例如M1>S2先发出ID=3的请求,长度为16,又发出M1>S1的ID=3的请求,长度为8,但是由于S2响应慢,M1会先拿到S1的响应,那么M1收到ID为3的响应时该怎么区分呢?答案是无法区分,所以这种场景会造成M1工作异常(接到全部数据的时候没有rlast信号,此时正处于S2响应的中间,并没有RLAST会导致M1认为传输错误)。具体解决方案是per slave per id,M0发起访问时,会判断已经发出去的ID,保证每个slave收到的ID是唯一的,所以我们设计axi master时也要这样,当然,我们也可以投机取巧,固定值。
想必一定有熟悉coreconsulatant和ARM NIC的同学,配置的时候有两个参数,那就是每组outstanding可以使用的ID个数,以及每个ID对应的指令个数,两者相乘就是outstanding能力,所以为了避免死锁我们会将ID个数配置为1(当然仅限第一级矩阵,也就是和自研AXI_M连接的地方,这样太暴力),这样Master就很容易区分不同slave设备的响应了,但是缺点也很明显,那就是会降低性能,不同ID的请求会被矩阵master反压,所以我们设置的需要合理。怎么算合理呢?首先如果大家看过cpu文档,会发现ID个数以及不同ID的含义是有明确定义的,所以我们配置时要考虑master的ID个数,但是master cpu访问我们时限制不了的,所以我们会在那里下手呢?那就是矩阵,需要做remap,NIC和NOC都有这种设计,实时保证ID的唯一性。
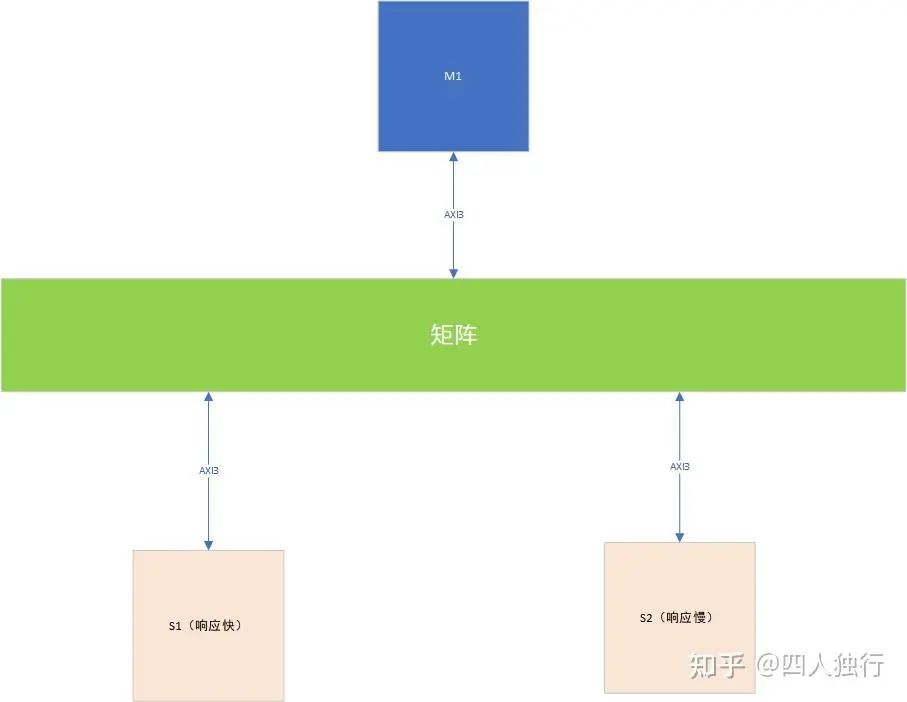
乱序读死锁常见结构
交织写:AXI3协议支持交织写,原因就是容易造成总线死锁,其实并不是交织写容易造成死锁,而是某些场景容易出现(矩阵配置不合理,或者不同路径delay分析不正确)。我们分析一下原因。
如下图,假设M1对S1地址发起多次burst传输,并且因为矩阵支持交织写,会把M1访问的顺序打乱(原因是master的数据也是由上级传递过来的,顺序可能不同)。如果不好理解的话,可以抽象将M1和M2认为是一个master,都在访问S1,矩阵的interleaving深度是>1的,也就是S1出口会将写的顺序打乱,导致waddr和wdata的顺序改变,那么结果是什么呢?那就是驴头不对马嘴,想写A1,但是数据却写到了A2地址,但是控制通路已经规定了burst长度,如果wlast出现的时候数据不够,或者多了,当然会让slave出现问题喽。
这也是为什么AXI4取消了WID的主要原因。
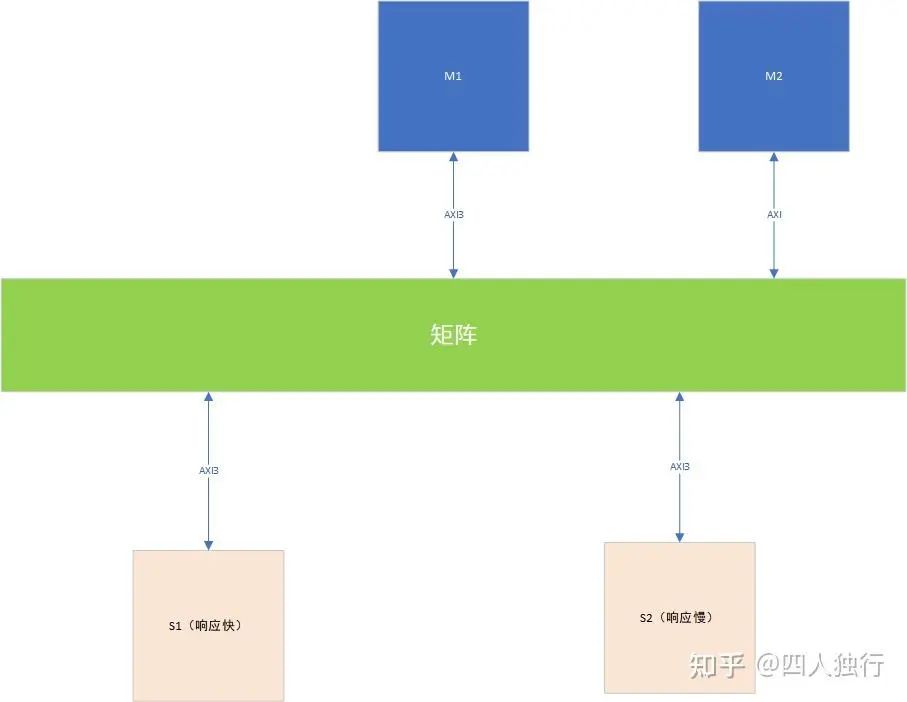
交织写死锁常见结构
交织读为什么不容易死锁呢?
如果是M1访问S1,根本不会出现交织,这个场景安全。
如果M1同时访问S1和S2,因为矩阵延迟的不同,很有可能发生交织,但是由于ARID和RID不同,也不会造成死锁。也是安全的。
但是当然存在不安全的场景,那就是master不支持交织,矩阵支持交织,同样会导致总线异常,所以我们配置矩阵IP时,一定要充分了解所有的master设备和slave设备。主要参数如下:outstanding能力,read interleaving深度,master id宽度,master个数,slave id宽度(矩阵slave口ID宽度会受master个数影响,id一定不能截位,但是可以remap)等。
-
soc
+关注
关注
38文章
4236浏览量
219751 -
MASTER
+关注
关注
0文章
104浏览量
11412 -
AXI
+关注
关注
1文章
128浏览量
16807
原文标题:SoC常见问题 - axi deadlock
文章出处:【微信号:IP与SoC设计,微信公众号:IP与SoC设计】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

soc开发流程常见问题及解决方案
KeyStone设备的PCI Express (PCle)常见问题

PCB设计中的常见问题有哪些?

SoC设计中总线协议AXI4与AXI3的主要区别详解

步进电机常见问题及维护






 工商网监
工商网监
评论