 燧原科技和芯砺智能发布Chiplet高效NPU联合计算架构
燧原科技和芯砺智能发布Chiplet高效NPU联合计算架构
近日,芯砺智能与燧原科技联手推出了基于Chiplet定制化NPU的高效协同运算架构,这项成果显著提升了多个精巧芯片(Chiplet)内众多NPU运算单元之间的协同工作效率,有助于推动AI算力向着更高性能、更低成本以及更加易于扩展的趋势迈进,有力地推动算力基础设施的构建。
伴随着AI大模型时代的来临,全球算力需求呈现出旺盛增长态势。在摩尔定律放缓背景下,传统单一芯片模式已无法准确应对日益复杂多元的算法和应用需求。而高性能的Chiplet芯片作为解决此难题的关键方案正逐渐成为主流选择。然而,如何使两个及更多的算力单元达成至线性算力叠加的极致效果,始终是业界面临的重大挑战。
本次财经新闻中提到的燧原科技与芯砺智能的合作研发项目,是双方团队长期积累的技术硕果和紧密协作的产物。他们共同开发的这套全新NPU协同运算架构,建立在芯砺智能超低延迟(《5ns)的专利Chiplet D2D互连技术之上,成功填补了跨Die数据传输导致的性能损失。此外,结合芯砺智能独特的模型切割及优化技术,实现在跨Die算力单元NPU上的复杂大型网络部署,进而确保了高效的运算效率。
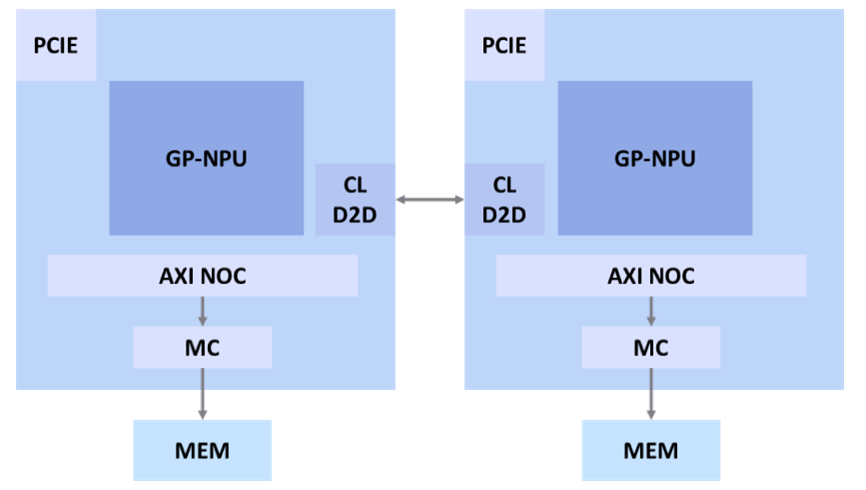
经过工程团队在FPGA原型平台上的反复测试验证,他们发现Resnet50等常见算法在双FPGA机组与单FPGA组相比,联合运的效率提升达到惊人的1.936倍,基本达到预期的线性叠加效果。
对此,燧原科技首席运营官张亚林表示,基于Chiplet的NPU协同运算架构具有极高的实用价值,它是我们关注的重点方向之一,也是我们基于人工智能算力基础设施建设的一次重大尝试与突破。通过与芯砺智能的深度合作,我们成功展示了如何运用这种新的算力扩展方式来更好地适应超大规模数据中心对于性能与功能的持续提升需求。展望未来,我们期待能够继续深化与芯砺智能的合作关系,共同为中国算力底座的建设添砖加瓦。
尤其值得一提的是,芯砺智能首席执行官张宏宇透露,该公司推出的首款基于Chiplet的高效NPU协同运算架构为其Chiplet D2D互连IP技术的又一重要突破。他深感欣慰的是,本次与燧原科技携手推出NPU协同运算架构,更进一步强化了两家企业的战略合作伙伴关系。未来,芯砺智能将继续积极响应并配合燧原的算力普惠战略,大力推进算力基础设施的搭建进程。同时,这种新型的协同运算架构也表明,芯砺智能具备向边缘端应用场景提供多种可扩展AI算力的坚实实力,进一步坚定了芯砺智能构建人工智能时代算力基础设施,致力于提供人人共享可用算力的宏愿。
-
摩尔定律
+关注
关注
4文章
637浏览量
79350 -
chiplet
+关注
关注
6文章
437浏览量
12670 -
大模型
+关注
关注
2文章
2764浏览量
3416
发布评论请先 登录
相关推荐
燧原科技联合腾讯云入选“行业云平台领航者典型案例”
勇芯科技智能戒指 Chiplet 新品发布会盛大召开,开启智能穿戴新纪元

NPU的工作原理解析
NPU在边缘计算中的优势
NPU技术如何提升AI性能
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
IMEC组建汽车Chiplet联盟

RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
苹芯科技发布AI革命新品,引领高效能计算新纪元
基于RK3588的NPU案例分享!6T是真的强!
英伟达联合计算机制造商发布Blackwell架构系统
黑芝麻智能推出基于武当C1296芯片多域融合计算平台方案






 工商网监
工商网监
评论