 寄存器阵列低功耗设计方案
寄存器阵列低功耗设计方案

芯片通常会用到一个寄存器阵列。用户通过SPI, I2C之类的接口对寄存器进行读写操作,实现各个模块的配置,状态查询等等。
如果不考虑功耗,CTS时工具会插入一个类似下面这样结构的clock tree。不妨做个简单估算。
假设寄存器阵列有128个8-bit寄存器。每个8-bit寄存器由8个DFF组成。总共1024个DFF。
假设每8个DFF工具插入一个CTB。128个8-bit寄存器就需要插入128个CTB。
假设每8个CTB又需要插入一个CTB来驱动。前一步插入的128个CTB需要再插入16个CTB驱动。
这16个CTB又需要再插入两个CTB来驱动。
总共需要插入128+16+2=146个CTB。
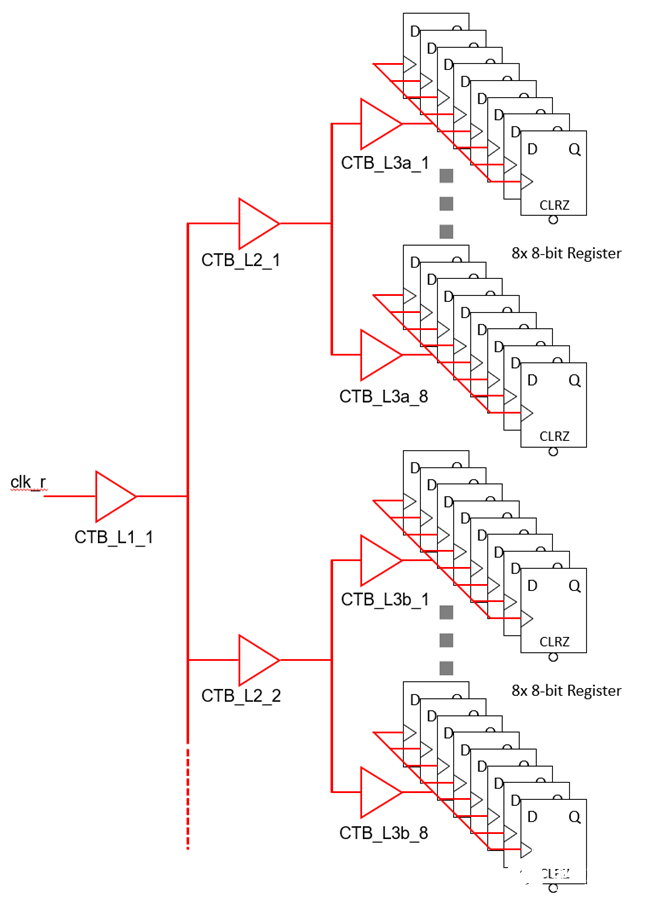
假设接口为SPI,读写protocol是1位RW,7位地址,8位数据。每次读写都是16个SPI clock。假设SPI clock直接用做寄存器阵列时钟(通常有片子里有OSC,需要SPI clock domain到OSC clock domain transfer。那是另一个技巧了。这里就不展开了)。如果不插入ICG,每次读写时1024个DFF + 146个CTB都switch 16个SPI clock,那可是不小的功耗,尤其是频繁读写的场景。
上述这种实现方法比较“蠢”。我们知道,每次读写只能对一个寄存器进行操作,没必要所有的寄存器都给时钟。基于这个朴素的想法,我们可以利用工具降低功耗。
寄存器阵列的结构有规律。综合工具可以根据地址解码插入ICG。假设插入的ICG驱动能力足够,整个寄存器的clock tree会变成类似下面这样的结构。
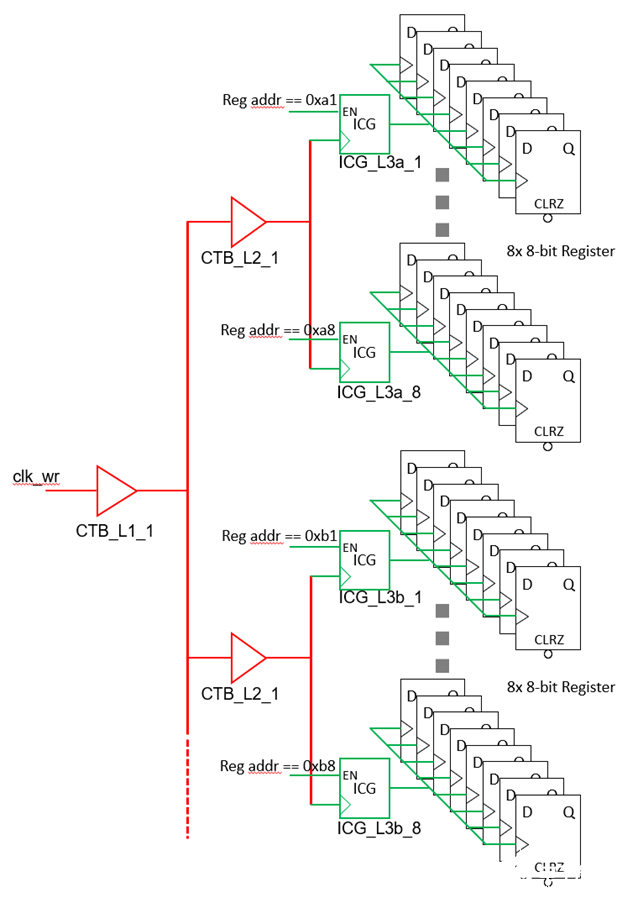
对寄存器阵列进行操作时,只有地址符合的寄存器ICG才会被打开,该寄存器的DFF才会得到时钟。而其他地址不符合的寄存器ICG关闭,没有时钟,也就没有switching power。这样一来,每次写操作实际只有一个寄存器会switching,大大减少了switching power。美中不足的是,对任何寄存器操作时ICG前面的CTB都会有时钟,这部分clock tree仍消耗switching power。
寄存器写操作的时候会改变寄存器内容,需要时钟锁入新的数据。但是,对寄存器进行读操作的时候,寄存器内容不改变,寄存器不需要时钟。这个特点工具是不知道的,但是designer可以利用起来。一个很自然的想法就是只在寄存器写操作放clock进来。
其次,虽然每个SPI写操作需要16个SPI clock。但是实际上寄存器阵列只需要在地址,数据都收到后给一个写时钟脉冲就可以了,不需要多个时钟反复写几次。
基于上面这两个想法,我们可以在寄存器阵列的时钟入口处加一个ICG。这个ICG只在写操作的时候打开,且只在地址数据都收到后打开一个时钟周期,放一个时钟脉冲过去。这样整个clock tree的switching power就大大降低了。
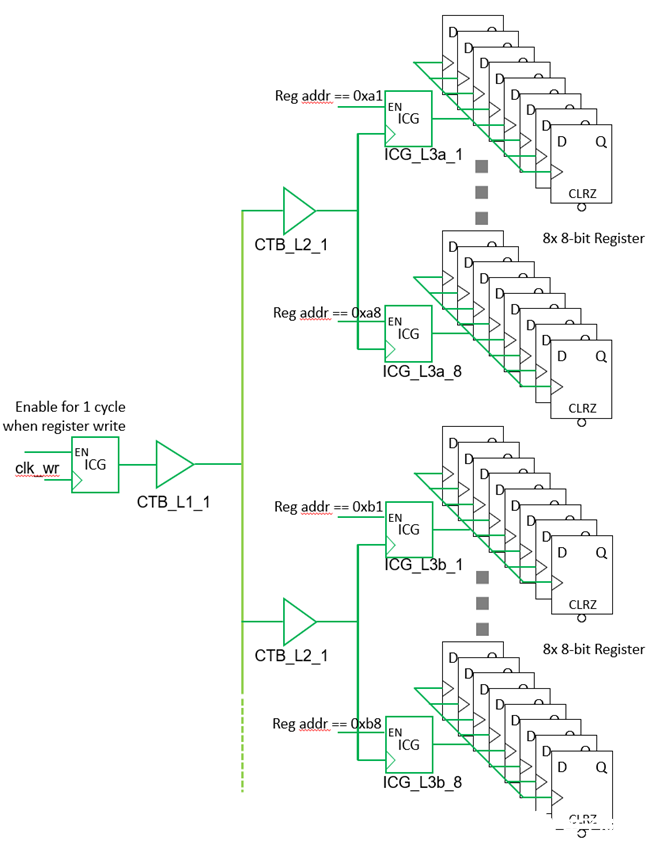
寄存器阵列时钟入口处的ICG要在RTL里加。
写RTL的时候就考虑功耗并手动插入ICG是实现低功耗的最有效手段。再加上工具辅助优化一下,就很完美了。
审核编辑:黄飞
-
寄存器
+关注
关注
31文章
5619浏览量
130409 -
SPI
+关注
关注
17文章
1900浏览量
102118 -
时钟设计
+关注
关注
0文章
29浏览量
11199 -
时钟脉冲
+关注
关注
0文章
20浏览量
13239
发布评论请先 登录
MAX11120-MAX11128低功耗,逐次逼近寄存器串行ADC

在学习低功耗设计?看看如何解决寄存器传输功耗问题
寄存器分为基本寄存器和什么两种
浅谈低功耗晶振的设计方案




评论