 放下你的PhotoShop!无限图像编辑已开源!
放下你的PhotoShop!无限图像编辑已开源!
0. 笔者个人体会
最近文本到图像的工作很火,生成的图像也非常真实。但还有个问题,现有工作效率比较低,往往只能接受一次text指令,再修改就要重新输入text重新生成,可能会影响原本的语义信息,这样导出的图像和最初图像可能差距甚远。
今天笔者将为大家分享一项最新开源的工作LEDITS++,可以一次输入无限多的编辑指令,一次性生成真实图像!而且LEDITS++是无参数方案,不需要微调和优化。不得不感慨AI发展之迅速,距离人们真实生活也越来越近了。
下面一起来阅读一下这项工作,文末附论文和代码链接~
1. 效果展示
先看一下具体效果,输入具体指令就可以直接产生对应效果。PS要想在几十秒内达到同等效果应该是有点困难。

LEDITS++很强调编辑前后的图像一致性,也就是仅修改图像的相关区域,保持原始图像的语义信息。这里也推荐工坊推出的新课程《彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析》。

代码已经开源了,官方主页也开放了交互式demo,感兴趣的读者可以上传自己的图像和文本指令尝鲜一下效果。
2. 具体原理是什么?
LEDITS++可以分为三个部分:(1)有效的图像反转;(3)多功能文本编辑;(3)图像变化的语义基础。
我们知道扩散模型生成图像是通过反转采样来进行的,重点是识别噪声。LEDITS++从DDPM反演中提取特征,并提出一种有效的反演方法,大大减少所需的步骤,同时降低重建误差。当将反向扩散过程公式化为SDE时,DDPM可以被视为一阶SDE解算器。使用高阶微分方程解算器可以更有效地解算,因此作者推导出一种新的更快技术------DPM-solver++反演。

在创建重建序列之后,可以通过一组编辑指令操纵噪声来编辑图像。根据有条件和无条件估计,作者分别设计了一个专门的引导项,既反映了编辑的方向,又最大化了对所需编辑效果的细粒度控制。

最后,LEDITS++还包括一个Mask项,由交叉注意层生成的Mask和噪声估计导出的Mask取交集计算得到。Mask可以捕捉与编辑概念相关的图像区域,对于多次编辑特别有效。这里也推荐工坊推出的新课程《彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析》。

3. 和其他SOTA方法对比如何?
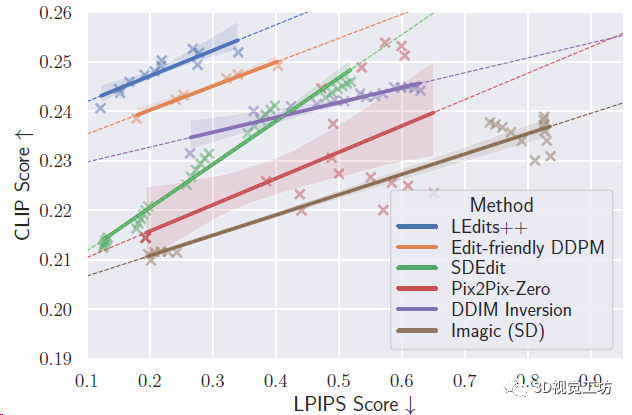
不同编辑方法的指令对齐和图像相似度权衡的比较,侧重CLIP得分(越高越好)与LPIPS相似度(越低越好),也就是图中越靠近左上角效果越好。
-
图像
+关注
关注
2文章
1089浏览量
40600 -
AI
+关注
关注
87文章
31845浏览量
270673 -
开源
+关注
关注
3文章
3421浏览量
42783
原文标题:放下你的PhotoShop!无限图像编辑已开源!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
SparseViT:以非语义为中心、参数高效的稀疏化视觉Transformer

开源鸿蒙技术分论坛在武汉成功举办
与鸿同行,探索无限!开源鸿蒙技术分论坛在武汉成功举办

高倍金相自动测量显微镜无限远光学系统

字节发布SeedEdit图像编辑模型
图像采集卡的接口类型有哪些?






 工商网监
工商网监
评论