 WiMinet评说1.2:多跳无线网络的困境
WiMinet评说1.2:多跳无线网络的困境
1、前言
在工业应用中,低速率,大规模和长距离的无线自组织网络一直没有得到广泛的部署,根本原因在于其稳定性,可靠性和实时性一直无法得到良好的保证。在这种自组织网络中,节点之间的跳转关系大多是根据其相对位置和信号强度来决定的;由于安装位置,部署密度,启动时间等差异,其网络拓扑往往会有比较明显的不同,在网络的某些分支,其跳数可能会比较浅,比如1-2跳,而有些分支则比较深,比如6-8跳。在这些网络跳数比较浅的区域,其丢包率比较小,通讯延迟比较小,可靠性和实时性也比较好;而在那些网络跳数比较深的区域,其丢包率也比较高,通讯延迟比较大,可靠性和实时性自然也就比较差。
2、业内问题
作为一个上层的应用系统,用户在设定数据传输频率(是每秒给目标节点发出去多少个应用层的数据包,不是网络本身的无线通讯速率)的时候,往往是不太关心网络的拓扑结构的;实际上这个也没办法关心,因为它本身就不太固定,因此在设定重传的时间门限的时候,往往不能充分地考虑到不同的网络跳数所导致的通讯延迟和丢包率。一旦设置不合理,就会形成严重的应答超时和通讯失败;即便设置了正确的时间参数,由于开放的无线信道经常会受到外界的扰动,这个网络拓扑可能还会发生变动,更别说因为用户后期追加设备或者临时对某些设备二次上电所导致的拓扑结构发生改变了。
从自组织网络的基本工作原理,我们可以看出,网络跳数的深浅是由部署环境和一些其他因素综合决定的,存在较大的偶然性和不确定性。在网络的某些物理分支,其网络跳数必定比其他区域更深,这个区域的丢包率,通讯延迟也必然比其他的区域更大,带来的可靠性和实时性也自然更差。这一点我们可以通过数学上的概率论予以解释。
3、概率分析
在特定的电磁环境中,每种配置参数的无线通讯系统有一个大致确定的比特误码率 BER(Bit Error Rate) 和包误码率PER(Packet Error Rate),二者之间有下述关系:
PER=1 - ( 1 – BER )ⁿ
其中n是这个数据包的长度,也就是总的比特数量。
考虑到无线自组网系统都是基于数据包作为基本的收发单元,因此本文选定 PER作为分析的依据。为了叙述方便,我们假定丢包率PER为p,那么通讯成功的概率P1,也就是不丢包概率为100% - p,也就是 1-p;对于一个两跳的无线网络,要想实现端到端的成功传输,那么这连续两跳都必须传输成功,依据概率论的知识,其成功的概率P2应该等于两跳成功概率的乘积,也就是
P₂ = P₁ * P₁ = P₁² = ( 1 – p )₂
同理,对于一个由n+1个节点组成 n跳的多跳无线链路,最终的目标节点要想正确地接收到源节点发出来的数据,要求从2号节点到n+1号节点的每一个中间节点都必须正确地收到上一跳发过来的数据,只要有一个环节失败了,最终的目标节点就无法正确地收到源节点发出来的数据,因此其总的通讯成功率Pn,按照概率论的知识应该有下述关系:
Pn= ( P₁ * P₁ …. * P₁) = P₁ⁿ = ( 1 – p )ⁿ
为了更加直观的说明真实的通讯效果,我们以包误码率 PER为10%,也就是 p=0.1的电磁环境为例,计算出不同网络跳数下的链路通讯成功率,具体如下表所示:
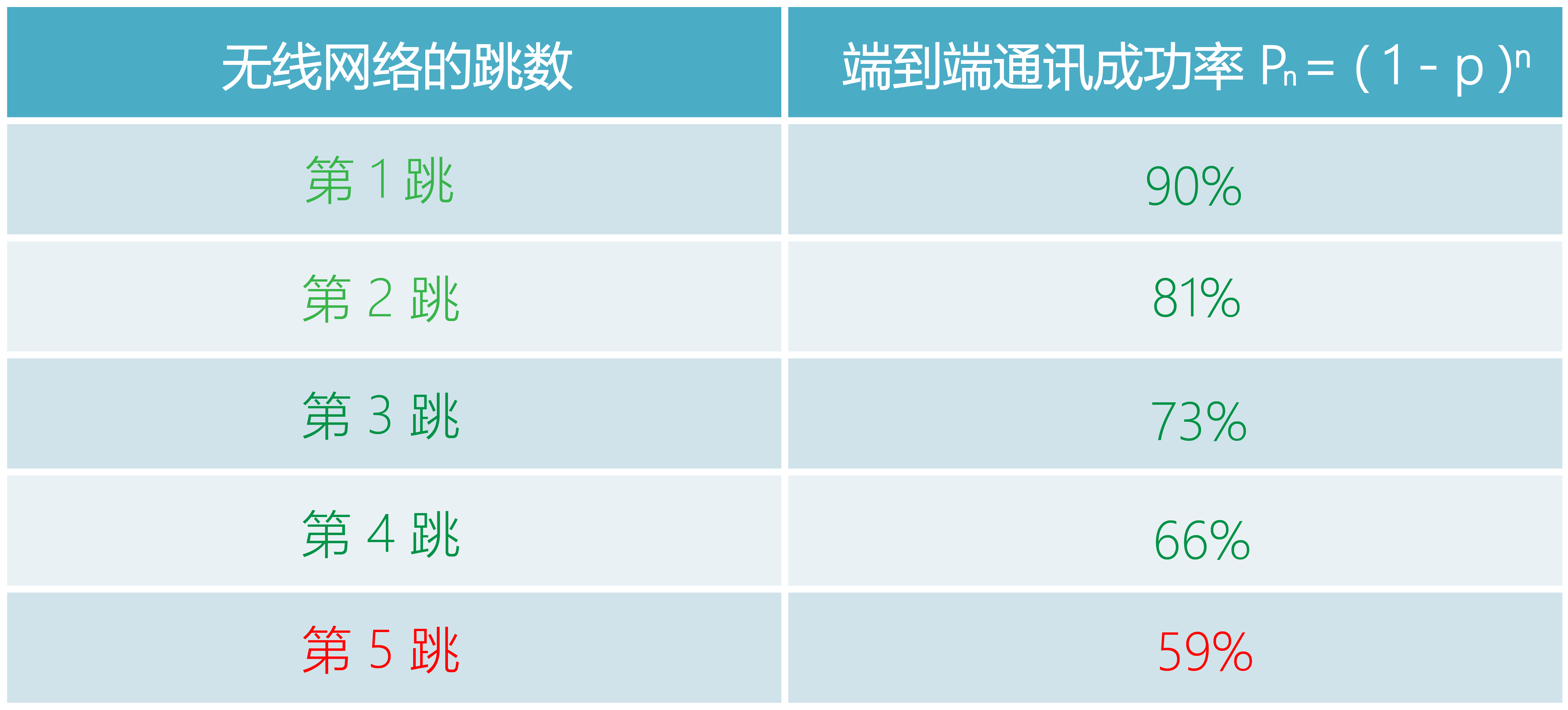
从上表我们看出,随着网络的跳数逐步增加,通讯成功率是明显逐步降低的,到了第五跳 n=5,也就是第六个链路节点的时候,其成功率已经低于人们的心理“及格线”60%了。很多人在这种情况已经判定链路不稳定了。事实上有不少的工程师朋友在现场调试ZigBee网络的时候,就发现了这个现象,但很少有人思考其背后的数学原理。
4、总结
通过上文的分析,我们可以看出,在室外长距离的无线自组织网络中,由于节点之间的链路损耗较大,其链路预算相对不足,因此其包误码率PER会相应升高,也就是丢包概率 p会比较大;而在一个大规模网络中,某些分支节点的通讯链路又会比较深,也就是网络跳数 n比较大,在这种情况下其通讯成功率Pn自然也就显著下降了,人们的切身感受就是这个链路不太稳定。
说到这里,有的读者朋友心里可能会想,这还不简单,给我上 TCP算法!加入端到端的数据重传机制,那问题还不是立马搞定?
效果果真如此么?请看后续文章分解!
-
无线网络
+关注
关注
6文章
1431浏览量
65924 -
TCP
+关注
关注
8文章
1353浏览量
79051 -
无线通讯
+关注
关注
5文章
580浏览量
40031
发布评论请先 登录
相关推荐
Poe供电与无线网络的结合
无线网解码器怎么用
无线网解码器哪个好用

无线测试是什么意思?无线网络测试仪使用方法
如何减少无线网络在同一信道内的干扰?
综合无线网络覆盖解决方案

无线网桥的工作原理 无线网桥的安装注意事项
无线网卡驱动怎么安装 无线网卡怎么连接台式电脑
无线网络开始进入WiFi 7全新时代
如何将以太网连接转换为无线网络连接
WiMinet 评说1.1:多跳无线网络的现状





 工商网监
工商网监
评论