 跑分没输过,体验没赢过,大模型刷分何时休?
跑分没输过,体验没赢过,大模型刷分何时休?
作者:一号
编辑:美美
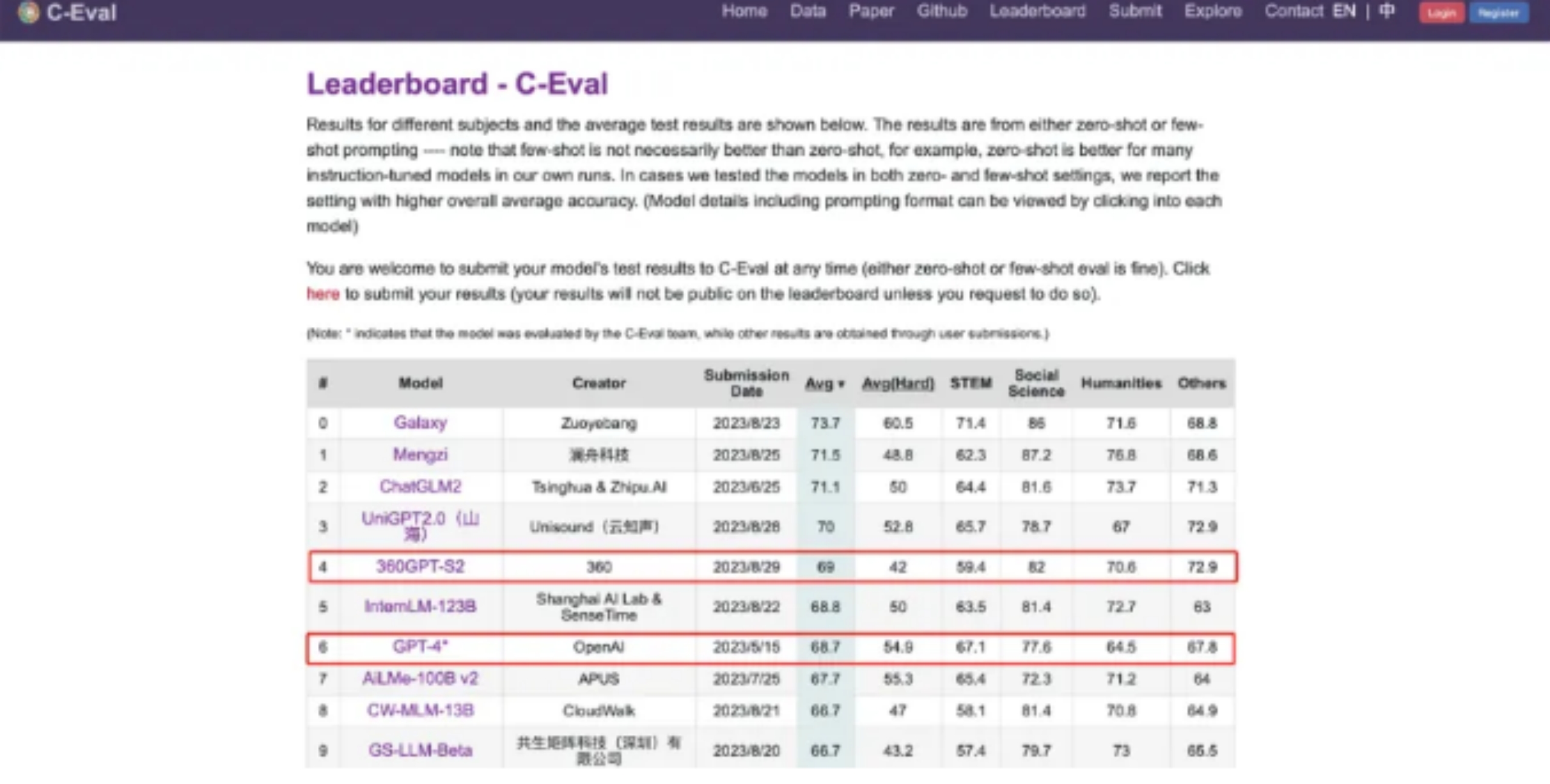
IDCAI大模型技术能力评估,12项指标,7项满分,文心大模型3.5“大满贯”;360智脑在SuperCLUE评测中多项能力位列国产大模型第一,某些方面甚至跑赢了GPT-4;夸克大模型在C-Eval和CMMLU两大权威评测榜单中名列第一,显示出其在写作、考试等部分场景中甚至优于GPT-4......

今年以来,国产AI大模型发展趋势之迅猛,不得不让人感慨。截至目前,国产大模型数量已经超过了200个,而且,这些大模型纷纷表现不俗,从百度文心一言到阿里巴巴的夸克大模型,国产AI在各类评测榜单上的表现引人注目。有人对此评价,“跑分没输过,体验没赢过”。
这种似曾相识的“跑分”现象,不禁让人想到手机市场里类似的做法。这种在评测中名列前茅、表现出色,但实际用户体验一言难尽的情况,究竟意味着什么?
为何跑分与体验不符?
回顾手机市场,“跑分没输过,体验没赢过”这句话最开始就是从手机圈中兴起的,各大厂商通过不断叠加定语,来让自己获得第一;还有的手机会自动识别跑分软件,针对性地开启性能模式,让自己的跑分数据好看些,从而实现“作弊”。用户买到跑分高的手机后,实际体验并不是那么回事。
而在AI大模型领域,评估标准则相对公平,并且是同意的,其中包括MMLU(用于衡量多任务语言理解能力)、Big-Bench(用于量化和外推LLMs的能力),以及AGIEval(用于评估人类级任务的能力)。

目前国内厂商经常饮用的榜单就是SuperCLUE、CMMLU和C-Eval,其中C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的综合性考试评测集,CMMLU则是MBZUAI、上海交通大学、微软亚洲研究院共同推出,至于SuperCLUE,则是由各大高校的AI专业人士设立的。
尽管大模型的评测标准相对公平,但其仍有一定的局限性,实际的测评之中总会出现问题,其中一个最大的问题就是“考题泄露”。
大模型评测的一个主要方法就是做题。为了让评测相对透明公开,避免暗箱操作,评测机构通常会将评测的方法、标准甚至是题库对外公开。例如C-Eval榜单在上线之初就有13948道题目,由于题库有限,并且更新频率不是特别高,这就给了一些大模型刷题“钻空子”的机会。
我们都知道,如果在考试之前知道会考哪些题目,那考生完全可以做针对性的学习,大模型也一样,并且大模型最擅长的就是记忆。在评测之前,把题库直接加入大模型的训练集,训练之后的大模型就能在评测中表现得比实际能力更好,甚至跑出一些夸张的成绩,例如1.3B的模型在某些任务上超越了10倍体量的大模型。
那么这样的评测结果,跟实际体验一定会很不相符。
为何热衷于跑分?
无论是国产手机厂商还是AI大模型公司,他们对跑分的热衷,本质上是一种营销策略。跑分成绩容易被量化、对比,因此成为了向公众展示技术实力的便捷手段。这种做法在短期内可能会吸引消费者和投资者的注意,但它也可能引起误导,使人们过分关注理论性能,而忽视了实际应用中的体验和效能。
这种营销策略的问题在于,它可能导致公司本末倒置,过分投入于提高特定测试的分数,而非真正的技术创新。在手机行业,这可能意味着优化设备性能以提升特定跑分软件的测试成绩;在AI领域,则可能表现为优化模型以应对评测榜单的特定题目。这种做法虽然能在短期内提高产品在评测榜单上的排名,但却可能忽视了产品在真实使用环境中的性能和用户体验。
这种以跑分为核心的营销策略需要被重新审视。尽管高分成绩在营销中具有吸引力,但它们并不总是反映产品的真实价值。对于消费者而言,理论上的高性能与日常使用中的实际体验之间往往存在差距。因此,无论是手机行业还是AI领域,公众和行业都应该更加关注产品在真实世界中的表现。
要放弃跑分吗?
从隋唐的科举到今天的高考,从国内的四六级到国外的托福雅思,考试在时间和空间的维度上,都是一种相对公平的衡量机制。因此,大模型评测作为大模型的“考试”,同样不能被轻易抛弃。
倘若评测相对准确、靠谱、权威,那么对于所有的大模型公司来说都是好事。研发者可以通过评测结果了解自家大模型的优缺点,查漏补缺,找到正确的方向钻研算法、提升技术、加强训练,不断攻克,进行优化迭代,从而让产品更具有竞争力。
对于AI大模型开发者而言,榜单的排名不应该成为最终目的,真正的挑战在于如何将先进的技术转化为实际应用中的有效工具,这不仅仅是一场分数的竞赛,更是对技术创新和实用性的追求。我们期待一个更加全面和科学的评测体系的出现,这不仅能正确评估AI模型的实际能力,还能促进整个行业向着更加健康、理性的方向发展。
审核编辑 黄宇
-
AI
+关注
关注
87文章
31158浏览量
269505 -
大模型
+关注
关注
2文章
2491浏览量
2876
发布评论请先 登录
相关推荐
小米新机成为再次跑分王!小米6跑分达到了21万!
不服跑个分! 小米6搭载高通835跑分高达110万
不服来跑分,小米占安兔兔跑分TOP10近半席

三星Exynos 9815处理器跑分曝光?跑分超过苹果A11?
新版iPhone跑分现身Geekbench
都2019年了为什么还需要跑分
魅族16s Pro的Geekbench跑分曝光单核成绩为3570分多核成绩为9493分
三星Note10 Lite跑分曝光单核跑分为667分多核跑分为2030分
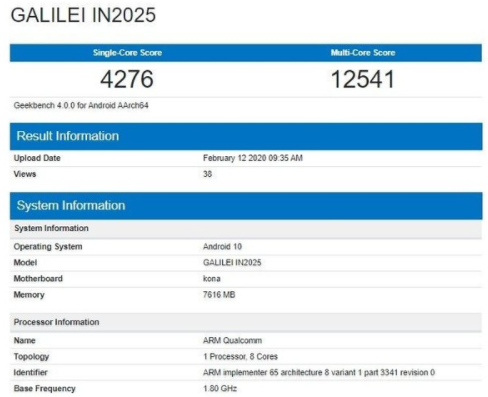
一加8跑分曝光该机单核跑分为4276分多核跑分达12541分
一加8 Pro 5G跑分曝光 多核跑分达12686





 工商网监
工商网监
评论