 访问寄存器代替内存引用
访问寄存器代替内存引用
我们先看一个例子:
有这么两个程序:它们的目的就是将数组x中的数,按照下标累加到数组y中,最后在把数组y中的数据累加到一个数dest里面。为了验证效果,我们将这个过程重复10000遍。

Prog 1 Prog2
这两个程序的区别就在Prog2中红框里面的内容。那么哪个程序运行的更快呢?
话不多说,我们看实际的结果:


这里为了说明效果,我们编译的时候,并没有采用优化(编译优化,确实可以提高程序运行的效率,但是过高的编译优化等级会有一定的副作用,另外编译器优化也具有一定的局限性,高效的代码仍然应该是我们追求的目标)。可以看到,Prog2要明显比Prog1快。
要想理解上面的例子,我们必须先介绍一下寄存器和汇编代码的相关知识:
寄存器
CPU内部用来存放数据的一些小型存储区域, 注意寄存器是在CPU内部,受限于CPU的物理尺寸,寄存器数量不会太多。我们只需要记住两点:
1) 寄存器和CPU的L1 cache相比,速度虽然还在一个数量级,但是L1 cache的访问速度还是要慢几倍。具体的数据见下文表2
2) CPU只能从寄存器直接取数据或者指令,如果取不到,获取的顺序是L1-》L2-》L3-》主存-》磁盘。
从下文表2中可以看出,如果cpu的cache访问miss了,性能损失还是很大的。如果内存里面再miss了,那对性能来说不亚于一场灾难了。
计算机访问速度分级:
表1 时间单位

以3.3GHz的CPU为例:
表2 系统的各种延时

正如你所见,CPU周期的时间非常短,这段时间,光的速度大约只能走0.5米。想象一下,是不是非常震撼?
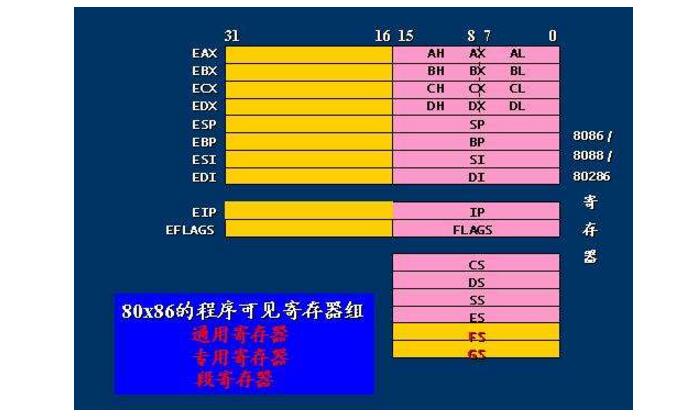
x86-64 CPU的整数寄存器:

我们无需刻意去记住这些寄存器的名称,不同架构的寄存器的数量和名称也不一样,我们只要知道他们是cpu内部的效率极高的存储单元即可。
回到前面的例子,为什么Prog2要比Prog1快,是因为Prog2里面用DEST这个局部变量代替了dest。DEST是一个局部变量,在汇编指令里是直接访问寄存器,而dest则需要去访问内存cache。
-
寄存器
+关注
关注
31文章
5336浏览量
120224 -
cpu
+关注
关注
68文章
10854浏览量
211563 -
内存
+关注
关注
8文章
3019浏览量
74000 -
程序
+关注
关注
117文章
3785浏览量
80999
发布评论请先 登录
相关推荐
为什么寄存器比内存快_原因是这个
逆向基础之寄存器和内存详解
寄存器变量
寄存器与内存的区别
C语言访问MCU寄存器

Cortex-M3 内部寄存器
访问CXL 2.0设备中的内存映射寄存器





 工商网监
工商网监
评论