 如何帮助提高CPU分支跳转的正确率
如何帮助提高CPU分支跳转的正确率

我们还是先看一个例子:
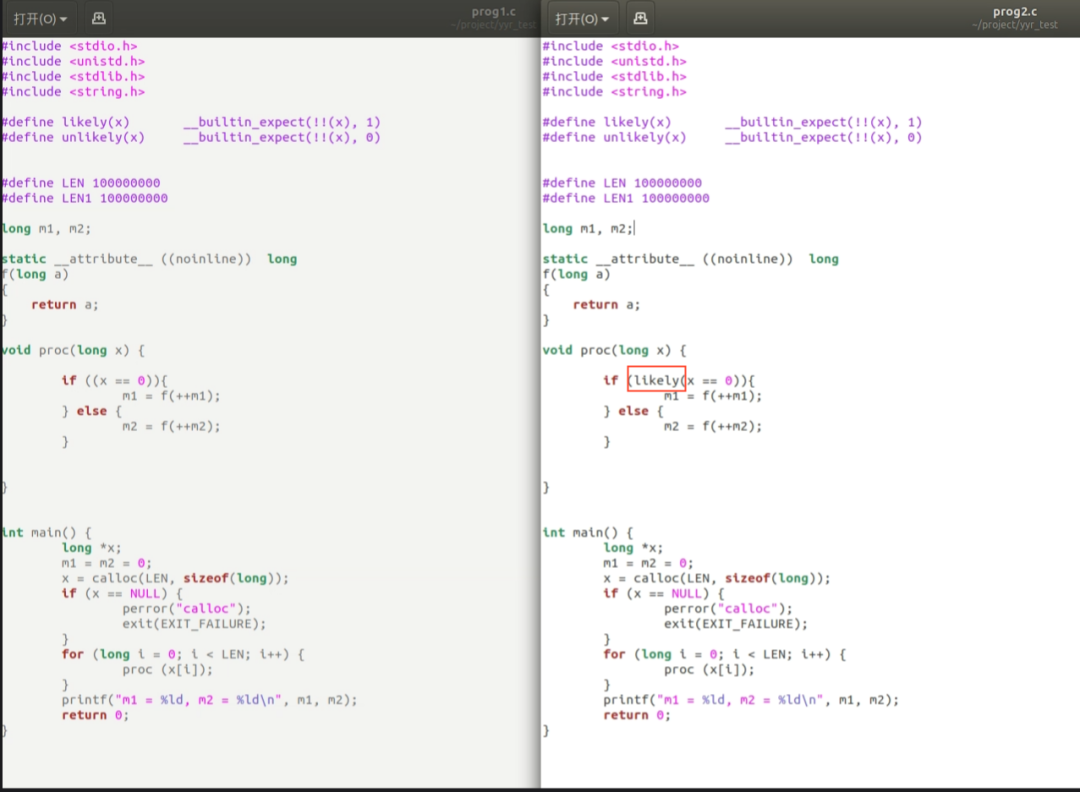
看上面的两个函数,它们都是calloc一个全零数组x(这里不能直接用数组赋值,否则编译器会足够聪明进行自动的优化),遍历x中的每个数,如果等于0,执行分支A,否则执行分支B。
唯一的不同就是在分支判断的时候,prog2.c加了likely。我们先看下实际的结果如何:

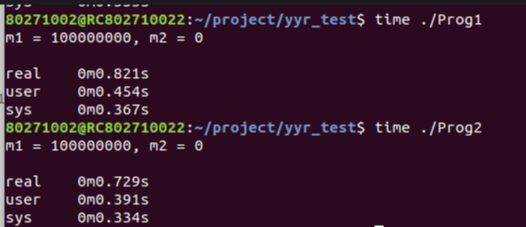
可以看出,加了likely的prog2,明显用时变短。原因何在?
为了理解上面的例子,我们先介绍CPU流水线相关知识:
3.1. CPU流水线简介
CPU流水线是一种使用多级缓存来提高处理器性能的技术。它是指将CPU操作分为多个阶段,每个阶段单独完成一个操作,然后将结果传递给下一个阶段,以此类推。每个阶段都有一个独立的部件,并且所有部件都能同时处理不同的指令。现代CPU都会采用这种技术来提高CPU的运行效率。
CPU流水线通常包括以下五个阶段:
1)取指令(Instruction fetch):从存储器中读取指令。
2)指令译码(Instruction decode):将指令转换为可执行的指令。
3)执行指令(Instruction execute):执行指令的操作。
4)写回(Write back):将执行指令得到的结果写回内存中。
5)更新程序计数器(Update program counter):将程序计数器加1,使它指向下一个指令。
举个简单的例子:
我们假设每一个步骤执行时间都是一个时钟周期,那么一条指令执行需要3个时钟周期

CPU 执行指令的3个时钟周期里,取值单元只在第一个时钟周期里工作,其余两个时钟周期都处于空闲状态,其它两个执行单元也是如此,效率太低了。
解决方法就是引入流水线,引入流水线工作模式后可以看到,除了刚开始第一个时钟周期大家还可以偷懒外,其余的时间都不会闲着
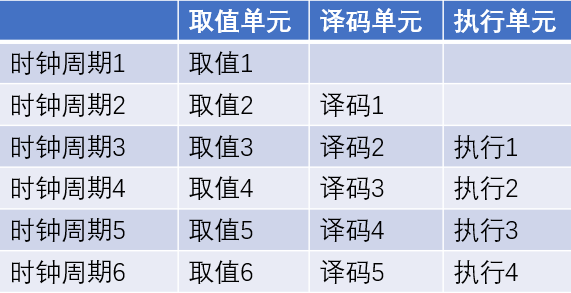
CPU流水线的优点是可以同时执行多个指令,从而提高了处理器的效率。但它也存在一些问题,例如数据相关性(Data dependency)和控制相关性(Control dependency),这些问题可能导致流水线停滞,降低CPU的性能。
执行的程序指令如果是顺序结构,没有中断或跳转,流水线确实可以提高执行效率。但是当程序指令中存在跳转、分支结构时,下面预取的指令可能就要全部丢掉了,需要到要跳转的地方重新取指令执行。一般来说分支预测错误的处罚大约是19个时钟周期。(具体计算方法这里不做详细介绍了)。
我们看下前面提到的例子汇编出来的结果:
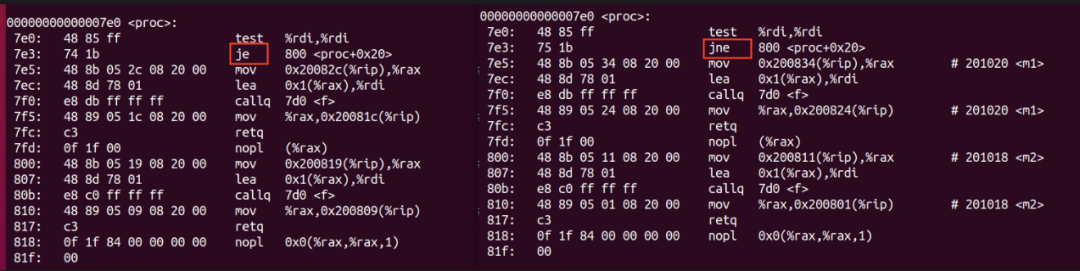
prog2,这里汇编是”jne”,意思是如果判断结果不为0,就跳转到地址 800的地方执行。我们知道这里的判断一直是0。所以,cpu指令顺序向下执行,并不会发生预判错误,预取的指令也不会丢弃。这样就不会遭到分支预测错误的惩罚,效率会提高。
所以有些情况下,当我们根据实际的情况可以判断出哪条分支的可能性更高的时候,我们就可以站在上帝视角给予一定的提示,这样就可以降低分支预测错误,减少CPU的无用功了,从而可以有效的提高性能,同时也节省了功耗。
-
cpu
+关注
关注
68文章
11332浏览量
225949 -
代码
+关注
关注
30文章
4977浏览量
74404
发布评论请先 登录
CPU分支预测对程序的影响
基于全局预测历史的gshare分支预测器的实现细节
提高条件分支指令预测正确率的方法
蜂鸟E203简单分支预测的改进
提高继电保护动作正确率的策略
labview如何立即退出当前事件分支
优化技巧:提前if判断帮助CPU分支预测
使用智能外设提高CPU效率

Thumb指令集之Thumb跳转指令

搜狗推“唇语识别”正确率达90%
如何使用蝙蝠优化算法的网络入侵检测模型提高入侵检测的正确率
如何才能解决图像匹配算法的光照变化敏感和匹配正确率低的问题
cpu和gpu的结构区别



评论