 谁说MySQL单表行数不要超过2000W?
谁说MySQL单表行数不要超过2000W?
背景
网上看了一篇文章《为什么说MySQL单表行数不要超过2000w》,亲自实践了一下,跟原作者有不同的结论。原文的结论是2000W左右性能会成指数级的下降,而我的结论是:随着数据量成倍地增加,查询的时间也刚好是成倍增加,是成正比的。
我并不会直接搬运网上的文章和结论,下边的实践过程是参考文章的实践方式进行优化的。原文的理论感觉是正确的,但为啥我实践的结果不支持他的理论?动手能力强的小伙伴,可以照的我的实践过程试试。
前置条件
查看sql语句执行时间和效率
showprofiles;#是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用来SQL的调优测量。 select@@have_profiling;#查看是否支持profiling setprofiling=1;#设置MySQL支持profile selectcount(*)fromtmp.person;#执行自己的sql语句; showprofiles;就可以查到sql语句的执行时间;
效果如下
mysql>setprofiling=1; QueryOK,0rowsaffected,1warning(0.00sec) mysql>selectcount(*)fromtmp.person; +----------+ |count(*)| +----------+ |2| +----------+ 1rowinset(0.00sec) mysql>showprofiles; +----------+------------+---------------------------------+ |Query_ID|Duration|Query| +----------+------------+---------------------------------+ |1|0.00017775|selectcount(*)fromtmp.person| +----------+------------+---------------------------------+ 1rowinset,1warning(0.00sec)
实验
建一张表
dropdatabaseifexiststmp; createdatabasetmp; usetmp; CREATETABLEperson( idintNOTNULLAUTO_INCREMENTPRIMARYKEYcomment'主键', person_idtinyintnotnullcomment'用户id', person_nameVARCHAR(200)comment'用户名称', gmt_createdatetimecomment'创建时间', gmt_modifieddatetimecomment'修改时间' )comment'人员信息表';
插入一条数据
insertintopersonvalues(1,1,'user_1',NOW(),now());
利用 mysql 伪列 rownum 设置伪列起始点为 1
select(@i:=@i+1)asrownum,person_namefromperson,(select@i:=100)asinit; set@i=1;
运行下面的 sql,连续执行 20 次,就是 2 的 20 次方约等于 100w 的数据;执行 23 次就是 2 的 23 次方约等于 800w , 如此下去即可实现千万测试数据的插入,如果不想翻倍翻倍的增加数据,而是想少量,少量的增加,有个技巧,就是在 SQL 的后面增加limit条件,如limit 100控制将要新增的数据量。
insertintoperson(id,person_id,person_name,gmt_create,gmt_modified)
select@i:=@i+1,
left(rand()*10,10)asperson_id,
concat('user_',@i%2048),
date_add(gmt_create,interval+@i*cast(rand()*100assigned)SECOND),
date_add(date_add(gmt_modified,interval+@i*cast(rand()*100assigned)SECOND),interval+cast(rand()*1000000assigned)SECOND)
fromperson;
此处需要注意的是,也许你在执行到近 800w 或者 1000w 数据的时候,会报错:The total number of locks exceeds the lock table size,这是由于你的临时表内存设置的不够大,只需要扩大一下设置参数即可。
SETGLOBALtmp_table_size=512*1024*1024;#(512M) SETglobalinnodb_buffer_pool_size=1*1024*1024*1024;#(1G);
验证
selectcount(1)fromperson; selectcount(1)frompersonwhereperson_id=6; showprofiles;
优化测试
MySQL函数
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (youmightwant to use the less safe log_bin_trust_function_creators variable)
这是因为mysql 默认不允许创建自定义函数(安全性的考虑),此时我们需要将参数 log_bin_trust_function_creators 设置为开启状态
showvariableslike'log_bin_trust_function_creators';
setgloballog_bin_trust_function_creators=1;
但这样只是临时设置,重启终端后该设置即会失效。如果要配置永久的,需要在配置文件的 [mysqld] 上配置以下属性: log_bin_trust_function_creators=1
--随机产生字符串 dropfunctionifexistsrand_string;--先判断是否已存在同名函数,如果已存在则先删除 DELIMITER$$--两个$$表示结束 createfunctionrand_string(nint)returnsvarchar(255) begin declarechars_strvarchar(100)default'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'; declarereturn_strvarchar(255)default''; declareiintdefault0; whilei< n do set return_str = concat(return_str, substring(chars_str, floor(1+rand()*52), 1)); set i=i+1; end while; return return_str; end $$ DELIMITER ;
--随机生成编号 dropfunctionifexistsrand_num; DELIMITER$$ createfunctionrand_num() returnsint(5) begin declareiintdefault0; seti=floor(100+rand()*10); returni; end$$ DELIMITER;
自定义函数的调用和其他普通函数的调用一样,示例如下:
selectrand_string(5); selectrand_num();
一键测试
dropdatabaseifexiststmp; createdatabasetmp; usetmp; CREATETABLEperson( idintNOTNULLAUTO_INCREMENTPRIMARYKEYcomment'主键', person_idtinyintnotnullcomment'用户id', person_nameVARCHAR(200)comment'用户名称', gmt_createdatetimecomment'创建时间', gmt_modifieddatetimecomment'修改时间' )comment'userinfo'; SET@@profiling=0; SET@@profiling_history_size=0; SET@@profiling_history_size=100; SET@@profiling=1; insertintopersonvalues(1,1,'user_1',NOW(),now()); showprofiles; set@i=1; dropfunctionifexiststest_performance; DELIMITER$$#设置结束符 createfunctiontest_performance(numint)returnsvarchar(255) begin declarereturn_strvarchar(255)default''; if(num>0)then insertintoperson(id,person_id,person_name,gmt_create,gmt_modified) select@i:=@i+1, left(rand()*10,10)asperson_id, concat('user_',@i%2048), date_add(gmt_create,interval+@i*cast(rand()*100assigned)SECOND), date_add(date_add(gmt_modified,interval+@i*cast(rand()*100assigned)SECOND),interval+cast(rand()*1000000assigned)SECOND) frompersonlimitnum; else insertintoperson(id,person_id,person_name,gmt_create,gmt_modified) select@i:=@i+1, left(rand()*10,10)asperson_id, concat('user_',@i%2048), date_add(gmt_create,interval+@i*cast(rand()*100assigned)SECOND), date_add(date_add(gmt_modified,interval+@i*cast(rand()*100assigned)SECOND),interval+cast(rand()*1000000assigned)SECOND) fromperson; endif; selectcount(1)intoreturn_strfrompersonwhereperson_id="9"; selectcount(1)intoreturn_strfromperson; returnreturn_str; end$$ DELIMITER; selecttest_performance(0);#2^1 selecttest_performance(0);#2^2 selecttest_performance(0);#2^3 selecttest_performance(0);#2^4 selecttest_performance(0);#2^5 selecttest_performance(0);#2^6 selecttest_performance(0);#2^7 selecttest_performance(0);#2^8 selecttest_performance(0);#2^9 selecttest_performance(0);#2^10 selecttest_performance(0);#2^11 selecttest_performance(0);#2^12 selecttest_performance(0);#2^13 selecttest_performance(0);#2^14 selecttest_performance(0);#2^15 selecttest_performance(0);#2^16 selecttest_performance(0);#2^17 selecttest_performance(0);#2^18 selecttest_performance(0);#2^19次方=524288 selecttest_performance(475712);#补上475712凑够100w selecttest_performance(250000);#125w selecttest_performance(0);#250w selecttest_performance(0);#500w selecttest_performance(0);#1kw selecttest_performance(0);#2kw selecttest_performance(0);#4kw selecttest_performance(0);#8kw selecttest_performance(0);#16kw selecttest_performance(0);#32kw
实验结果
| 数据量 | 有查询条件 | 无查询条件 |
| 125w | 0.1309075 | 0.08538975 |
| 250w | 0.25213025 | 0.18290725 |
| 500w | 0.4816255 | 0.35839375 |
| 1kw | 0.94493875 | 0.6809015 |
| 2kw | 1.878788 | 1.44631675 |
| 4kw | 5.40815725 | 3.05356825 |
| 8kw | 11.074242 | 6.6517985 |
| 16kw | 22.753852 | 17.94861325 |
| 2kw | 46.36041225 | 36.5971315 |
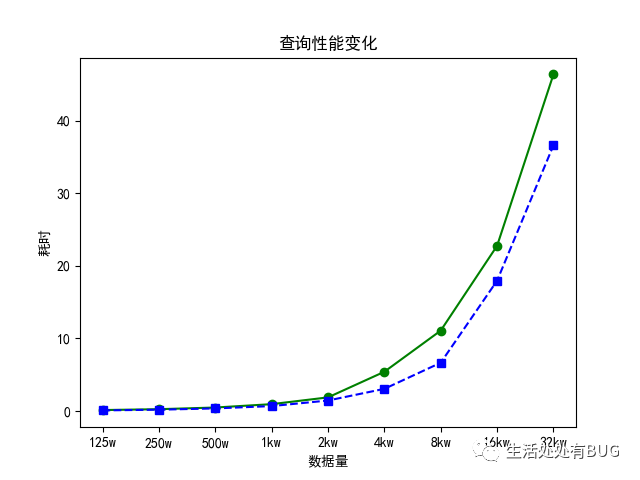 Figure_1
Figure_1
理论
单表数量限制
首先我们先想想数据库单表行数最大多大?
CREATETABLEperson( idint(10)NOTNULLAUTO_INCREMENTPRIMARYKEYcomment'主键', person_idtinyintnotnullcomment'用户id', person_nameVARCHAR(200)comment'用户名称', gmt_createdatetimecomment'创建时间', gmt_modifieddatetimecomment'修改时间' )comment'人员信息表';
看看上面的建表 sql,id 是主键,本身就是唯一的,也就是说主键的大小可以限制表的上限,如果主键声明 int 大小,也就是 32 位,那么支持 2^32-1 ~~21 亿;如果是 bigint,那就是 2^62-1 ?(36893488147419103232),难以想象这个的多大了,一般还没有到这个限制之前,可能数据库已经爆满了!!
有人统计过,如果建表的时候,自增字段选择无符号的 bigint , 那么自增长最大值是 18446744073709551615,按照一秒新增一条记录的速度,大约什么时候能用完?
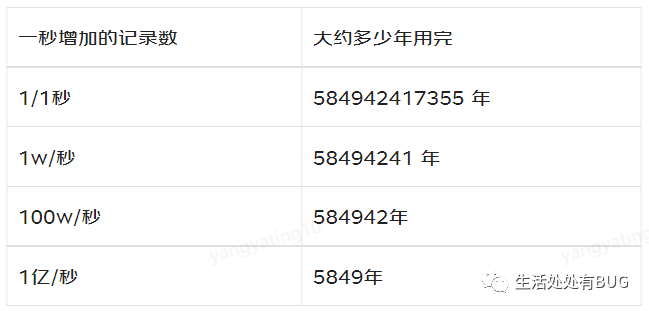 图片
图片
表空间
下面我们再来看看索引的结构,对了,我们下面讲内容都是基于 Innodb 引擎的,大家都知道 Innodb 的索引内部用的是 B+ 树
图片
这张表数据,在硬盘上存储也是类似如此的,它实际是放在一个叫 person.ibd (innodb data)的文件中,也叫做表空间;虽然数据表中,他们看起来是一条连着一条,但是实际上在文件中它被分成很多小份的数据页,而且每一份都是 16K。
大概就像下面这样,当然这只是我们抽象出来的,在表空间中还有段、区、组等很多概念,但是我们需要跳出来看。
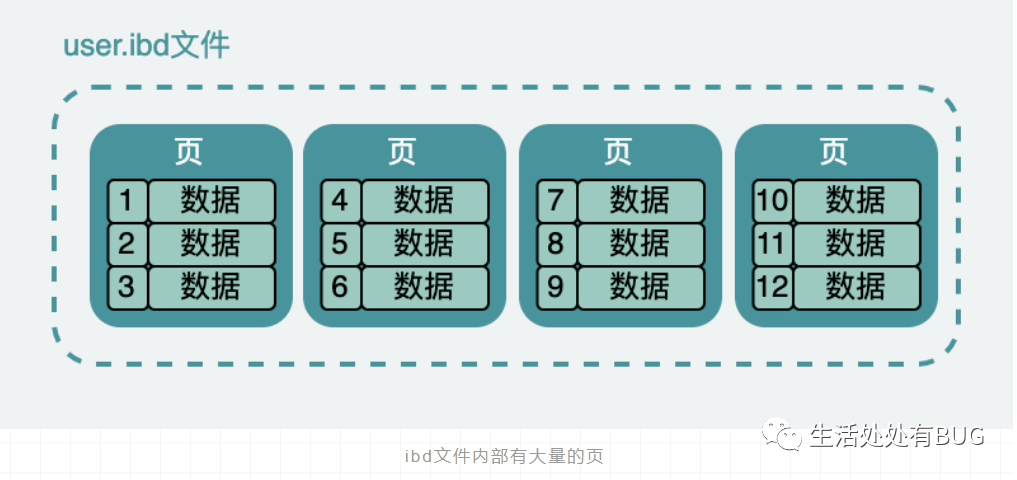
图片
页的数据结构
因为每个页只有 16K 的大小,但是如果数据很多,那一页肯定就放不下这些数据,那数据肯定就会被分到其他的页中,所以为了把这些页关联起来,肯定就会有记录前后页地址,方便找到对应页;同时每页都是唯一的,那就会需要有一个唯一标志来标记页,就是页号;
页中会记录数据所以会存在读写操作,读写操作会存在中断或者其他异常导致数据不全等,那就会需要有校验机制,所以里面还有会校验码,而读操作最重要的就是效率问题,如果按照记录一个个进行遍历,那肯定是很费劲的,所以这里面还会为数据生成对应的页目录(Page Directory); 所以实际页的内部结构像是下面这样的。
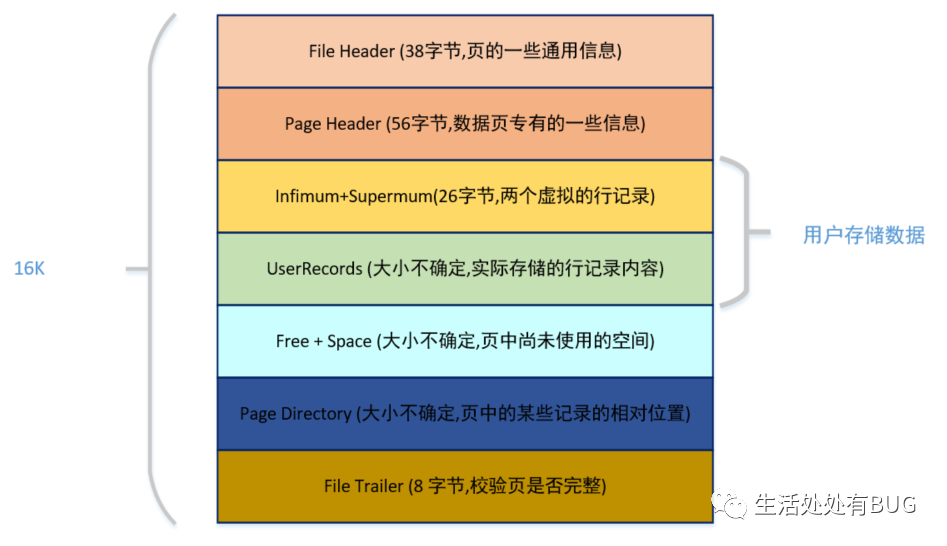
图片
从图中可以看出,一个 InnoDB 数据页的存储空间大致被划分成了 7 个部分,有的部分占用的字节数是确定的,有的部分占用的字节数是不确定的。
在页的 7 个组成部分中,我们自己存储的记录会按照我们指定的行格式存储到 User Records 部分。
但是在一开始生成页的时候,其实并没有 User Records 这个部分,每当我们插入一条记录,都会从 Free Space 部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到 User Records 部分,当 Free Space 部分的空间全部被 User Records 部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了。这个过程的图示如下。
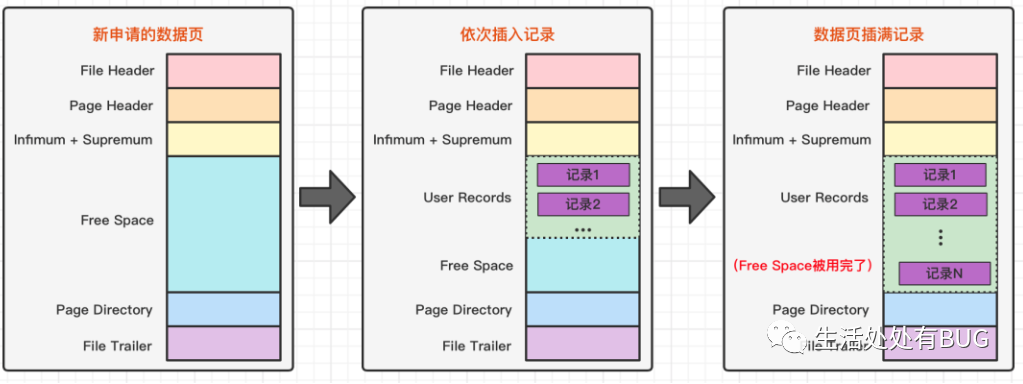
图片
刚刚上面说到了数据的新增的过程。
那下面就来说说,数据的查找过程,假如我们需要查找一条记录,我们可以把表空间中的每一页都加载到内存中,然后对记录挨个判断是不是我们想要的,在数据量小的时候,没啥问题,内存也可以撑;但是现实就是这么残酷,不会给你这个局面;为了解决这问题,mysql 中就有了索引的概念;大家都知道索引能够加快数据的查询,那到底是怎么个回事呢?下面我就来看看。
索引的数据结构
在 mysql 中索引的数据结构和刚刚描述的页几乎是一模一样的,而且大小也是 16K, 但是在索引页中记录的是页 (数据页,索引页) 的最小主键 id 和页号,以及在索引页中增加了层级的信息,从 0 开始往上算,所以页与页之间就有了上下层级的概念。
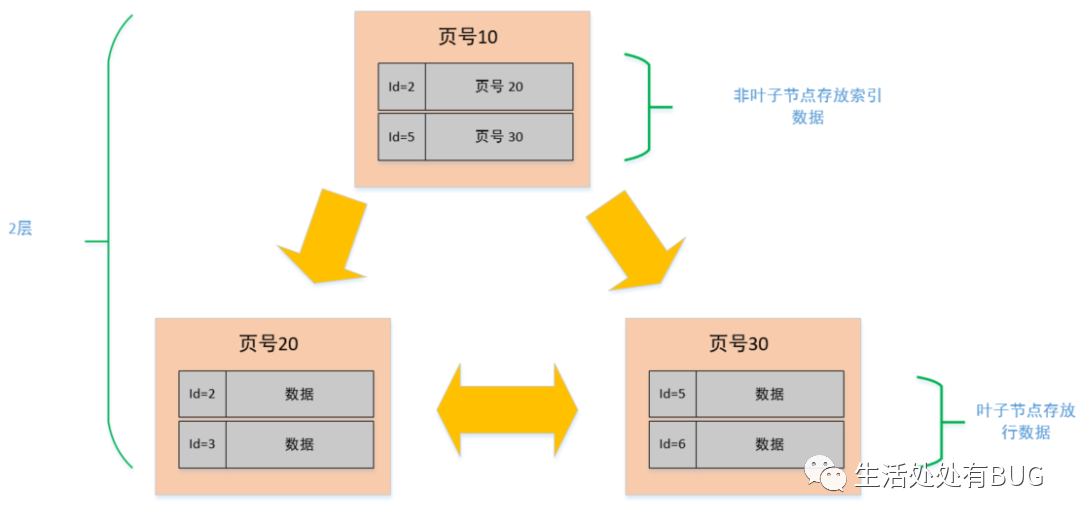
图片
看到这个图之后,是不是有点似曾相似的感觉,是不是像一棵二叉树啊,对,没错!它就是一棵树,只不过我们在这里只是简单画了三个节点,2 层结构的而已,如果数据多了,可能就会扩展到 3 层的树,这个就是我们常说的 B+ 树,最下面那一层的 page level =0, 也就是叶子节点,其余都是非叶子节点。
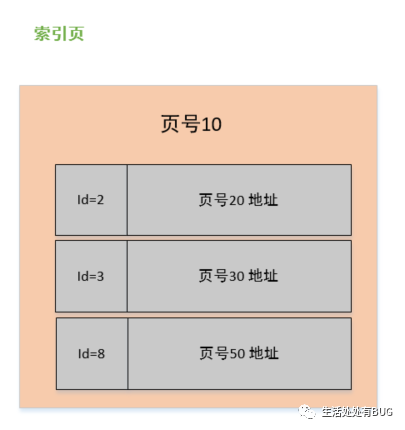
图片
看上图中,我们是单拿一个节点来看,首先它是一个非叶子节点(索引页),在它的内容区中有 id 和 页号地址两部分,这个 id 是对应页中记录的最小记录 id 值,页号地址是指向对应页的指针;而数据页与此几乎大同小异,区别在于数据页记录的是真实的行数据而不是页地址,而且 id 的也是顺序的。
单表建议值
下面我们就以 3 层,2 分叉(实际中是 M 分叉)的图例来说明一下查找一个行数据的过程。
比如说我们需要查找一个 id=6 的行数据,因为在非叶子节点中存放的是页号和该页最小的 id,所以我们从顶层开始对比,首先看页号 10 中的目录,有 [id=1, 页号 = 20],[id=5, 页号 = 30], 说明左侧节点最小 id 为 1,右侧节点最小 id 是 5;6>5, 那按照二分法查找的规则,肯定就往右侧节点继续查找,找到页号 30 的节点后,发现这个节点还有子节点(非叶子节点),那就继续比对,同理,6>5&&6<7, 所以找到了页号 60,找到页号 60 之后,发现此节点为叶子节点(数据节点),于是将此页数据加载至内存进行一一对比,结果找到了 id=6 的数据行。
从上述的过程中发现,我们为了查找 id=6 的数据,总共查询了三个页,如果三个页都在磁盘中(未提前加载至内存),那么最多需要经历三次的磁盘 IO。需要注意的是,图中的页号只是个示例,实际情况下并不是连续的,在磁盘中存储也不一定是顺序的。
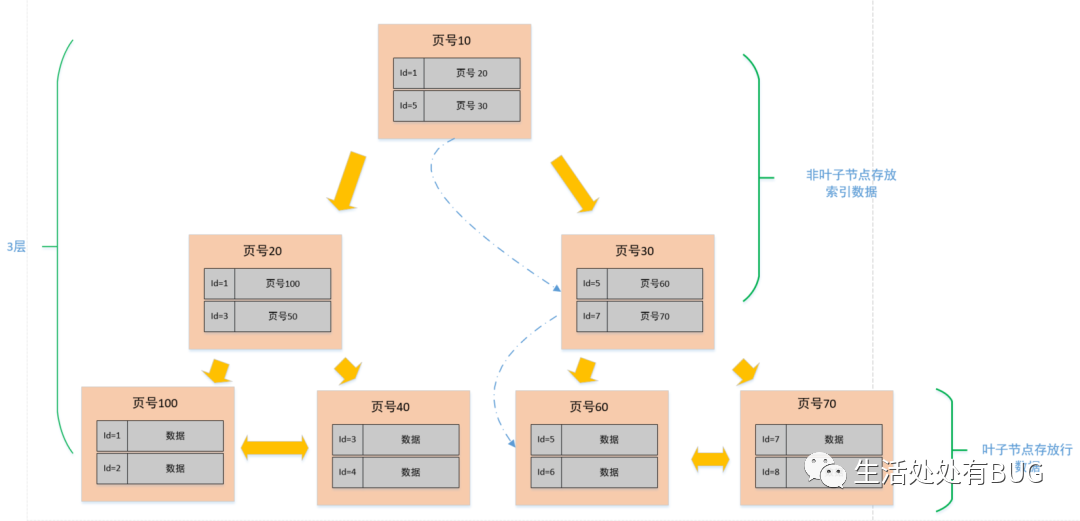
图片
至此,我们大概已经了解了表的数据是怎么个结构了,也大概知道查询数据是个怎么的过程了,这样我们也就能大概估算这样的结构能存放多少数据了。
从上面的图解我们知道 B+ 数的叶子节点才是存在数据的,而非叶子节点是用来存放索引数据的。
所以,同样一个 16K 的页,非叶子节点里的每条数据都指向新的页,而新的页有两种可能
• 如果是叶子节点,那么里面就是一行行的数据
• 如果是非叶子节点的话,那么就会继续指向新的页
假设
• 非叶子节点内指向其他页的数量为 x
• 叶子节点内能容纳的数据行数为 y
• B+ 数的层数为 z
如下图中所示 Total =x^(z-1) *y 也就是说总数会等于 x 的 z-1 次方 与 Y 的乘积。
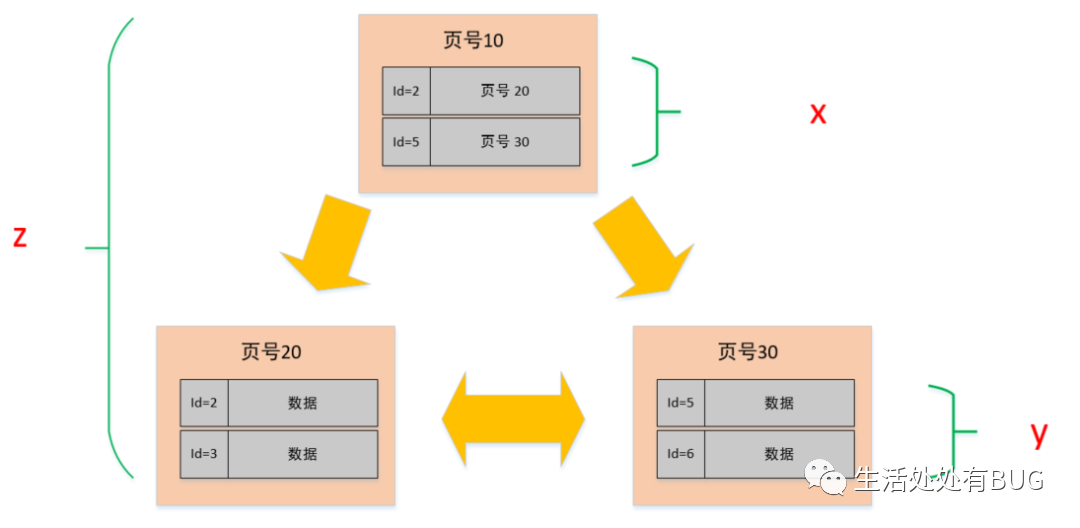
图片
X =?
在文章的开头已经介绍了页的结构,索引也也不例外,都会有 File Header (38 byte)、Page Header (56 Byte)、Infimum + Supermum(26 byte)、File Trailer(8byte), 再加上页目录,大概 1k 左右,我们就当做它就是 1K, 那整个页的大小是 16K, 剩下 15k 用于存数据,在索引页中主要记录的是主键与页号,主键我们假设是 Bigint (8 byte), 而页号也是固定的(4Byte), 那么索引页中的一条数据也就是 12byte; 所以 x=15*1024/12≈1280 行。
Y=?
叶子节点和非叶子节点的结构是一样的,同理,能放数据的空间也是 15k;但是叶子节点中存放的是真正的行数据,这个影响的因素就会多很多,比如,字段的类型,字段的数量;每行数据占用空间越大,页中所放的行数量就会越少;这边我们暂时按一条行数据 1k 来算,那一页就能存下 15 条,Y≈15。
算到这边了,是不是心里已经有谱了啊 根据上述的公式,Total =x^(z-1) y,已知 x=1280,y=15 假设 B+ 树是两层,那就是 Z =2, Total = (1280 ^1 )15 = 19200 假设 B+ 树是三层,那就是 Z =3, Total = (1280 ^2) *15 = 24576000 (约 2.45kw)
哎呀,妈呀!这不是正好就是文章开头说的最大行数建议值 2000w 嘛!对的,一般 B+ 数的层级最多也就是 3 层,你试想一下,如果是 4 层,除了查询的时候磁盘 IO 次数会增加,而且这个 Total 值会是多少,大概应该是 3 百多亿吧,也不太合理,所以,3 层应该是比较合理的一个值。
到这里难道就完了?
不我们刚刚在说 Y 的值时候假设的是 1K ,那比如我实际当行的数据占用空间不是 1K , 而是 5K, 那么单个数据页最多只能放下 3 条数据 同样,还是按照 Z=3 的值来计算,那 Total = (1280 ^2) *3 = 4915200 (近 500w)
所以,在保持相同的层级(相似查询性能)的情况下,在行数据大小不同的情况下,其实这个最大建议值也是不同的,而且影响查询性能的还有很多其他因素,比如,数据库版本,服务器配置,sql 的编写等等,MySQL 为了提高性能,会将表的索引装载到内存中。在 InnoDB buffer size 足够的情况下,其能完成全加载进内存,查询不会有问题。但是,当单表数据库到达某个量级的上限时,导致内存无法存储其索引,使得之后的 SQL 查询会产生磁盘 IO,从而导致性能下降,所以增加硬件配置(比如把内存当磁盘使),可能会带来立竿见影的性能提升哈。
总结
1.Mysql 的表数据是以页的形式存放的,页在磁盘中不一定是连续的。
2.页的空间是 16K, 并不是所有的空间都是用来存放数据的,会有一些固定的信息,如,页头,页尾,页码,校验码等等。
3.在 B+ 树中,叶子节点和非叶子节点的数据结构是一样的,区别在于,叶子节点存放的是实际的行数据,而非叶子节点存放的是主键和页号。
4.索引结构不会影响单表最大行数,2kw 也只是推荐值,超过了这个值可能会导致 B + 树层级更高,影响查询性能。
上边理论是原文的,我的实践结果是:随着数据量成倍地增加,查询的时间也刚好是成倍增加,是成正比的。
我感觉原作者的理论是对的,但我照着原作者的实践思路,得出的结果并不支持他的理论,有高手来评判一下吗?
审核编辑:汤梓红
-
数据
+关注
关注
8文章
7221浏览量
90068 -
内存
+关注
关注
8文章
3076浏览量
74522 -
SQL
+关注
关注
1文章
776浏览量
44363 -
MySQL
+关注
关注
1文章
835浏览量
26862
原文标题:理论
文章出处:【微信号:TheBigData1024,微信公众号:人工智能与大数据技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
2000W功率放大器

KHPA-0811W:500/1000/2000W X波段脉冲放大器废弃数据表

KHPA0608-XXXWP:500/1000/2000W C波段脉冲放大器数据表

为什么 MySQL 单表不能超过 2000 万行?

2000W手持激光焊接机价格镭拓这个配置才叫性价比







 工商网监
工商网监
评论