 【飞腾派4G版免费试用】 第三章:抓取图像,手动标注并完成自定义目标检测模型训练和测试
【飞腾派4G版免费试用】 第三章:抓取图像,手动标注并完成自定义目标检测模型训练和测试
抓取图像,手动标注并完成自定义目标检测模型训练和测试
在第二章中,我介绍了模型训练的一般过程,其中关键的过程是带有标注信息的数据集获取。训练过程中可以已有的数据集合不能满足自己的要求,这时候就需要自己获取素材并进行标注然后完成模型的训练,本章就介绍下,如何从网络抓取素材并完成佩奇的目标检测。整个过程由如下几个部分:
- 抓取素材,这里我使用下面的python脚本完成
#!/bin/python3
# 支持根据关键词抓取百度图片搜索的图片
import requests
import os
import re
def get_images_from_baidu(keyword, page_num, save_dir):
# UA 伪装:当前爬取信息伪装成浏览器
# 将 User-Agent 封装到一个字典中
# 【(网页右键 → 审查元素)或者 F12】 → 【Network】 → 【Ctrl+R】 → 左边选一项,右边在 【Response Hearders】 里查找
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
# 请求的 url
url = 'https://image.baidu.com/search/acjson?'
n = 0
for pn in range(0, 30 * page_num, 30):
# 请求参数
param = {'tn': 'resultjson_com',
# 'logid': '7603311155072595725',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': '', # 这个参数没公开,但是不可少
'pn': pn, # 显示:30-60-90
'rn': '30', # 每页显示 30 条
'gsm': '1e',
'1618827096642': ''
}
request = requests.get(url=url, headers=header, params=param)
if request.status_code == 200:
print('Request success.')
request.encoding = 'utf-8'
# 正则方式提取图片链接
html = request.text
image_url_list = re.findall('"thumbURL":"(.*?)",', html, re.S)
print(image_url_list)
# # 换一种方式
# request_dict = request.json()
# info_list = request_dict['data']
# # 看它的值最后多了一个,删除掉
# info_list.pop()
# image_url_list = []
# for info in info_list:
# image_url_list.append(info['thumbURL'])
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for image_url in image_url_list:
image_data = requests.get(url=image_url, headers=header).content
with open(os.path.join(save_dir, f'{n:06d}.jpg'), 'wb') as fp:
fp.write(image_data)
n = n + 1
if __name__ == '__main__':
keyword = '佩奇'
save_dir = keyword
page_num = 3
get_images_from_baidu(keyword, page_num, save_dir)
print('Get images finished.')
将抓取的图片,筛选以后(剔除没有佩奇的图片)分为两组数据,训练集和检验集。结构是类似这样的:
▸ tree peppa_jpg/ | head -n 10
peppa_jpg/
├── 000000.jpg
├── 000001.jpg
├── 000002.jpg
├── 000003.jpg
├── 000004.jpg
├── 000005.jpg
├── 000006.jpg
├── 000007.jpg
├── 000008.jpg
┏─╼[red]╾─╼[22:07:44]╾─╼[0]
┗─╼[~/Projects/ai_track_feiteng/demo3]
▸ tree peppa_valid_jpg/ | head -n 10
peppa_valid_jpg/
├── 000067.jpg
├── 000072.jpg
├── 000077.jpg
├── 000078.jpg
├── 000079.jpg
├── 000083.jpg
├── 000088.jpg
├── 000089.jpg
├── 000090.jpg
- 手工标注素材,这里我使用的是 labelImg ,标注的过程类似这样:
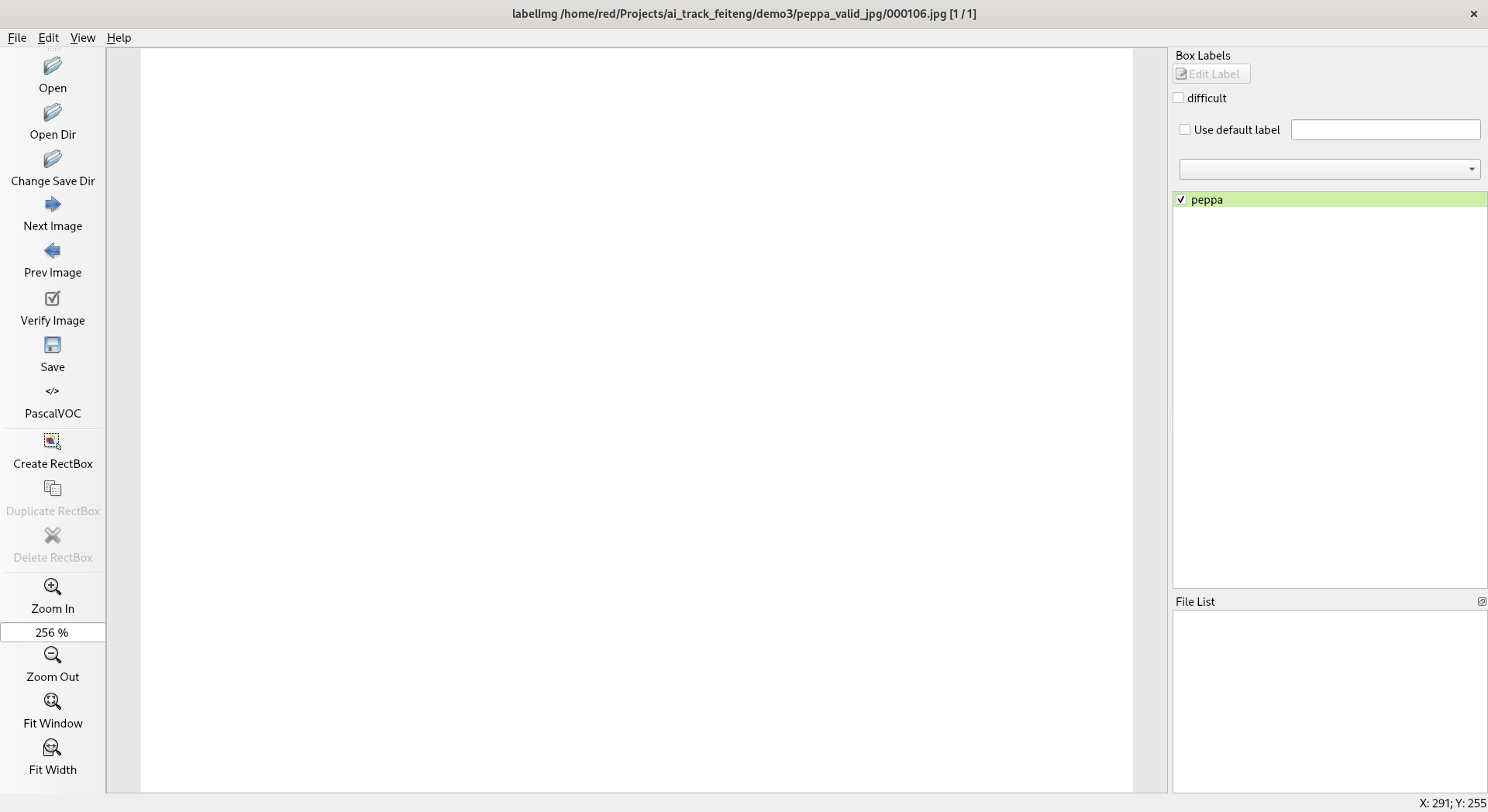

然后存储为 PascalVOC 的 xml 文件。这里转存之后是这样的:
▸ tree peppa_xml/ | head -n 10
peppa_xml/
├── 000000.xml
├── 000001.xml
├── 000002.xml
├── 000004.xml
├── 000006.xml
├── 000007.xml
├── 000008.xml
├── 000010.xml
├── 000011.xml
┏─╼[red]╾─╼[09:27:00]╾─╼[0]
┗─╼[~/Projects/ai_track_feiteng/demo3]
▸ tree peppa_valid_xml/ | head -n 10
peppa_valid_xml/
├── 000067.xml
├── 000072.xml
├── 000077.xml
├── 000078.xml
├── 000079.xml
├── 000083.xml
├── 000088.xml
├── 000089.xml
├── 000090.xml
- 格式转换为TFRecord 格式,这里我参考raccoon_dataset使用了两个步骤,首先转换为csv文件,然后再转换为TFRecord 格式文件。这里我对其中涉及到的脚本进行了微调,其中 xml_to_csv.py 文件我改成下下面的内容:
#!/bin/python3.8
import os
import sys
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main(xml_path, csv_file):
image_path = os.path.join(os.getcwd(), xml_path)
xml_df = xml_to_csv(image_path)
xml_df.to_csv(csv_file, index=None)
print('Successfully converted xml to csv.')
if len(sys.argv) < 2:
print("please input xml_path and out csv file")
else:
main(sys.argv[1], sys.argv[2])
这里通过命令:
▸ ./red_xml2csv.py peppa_xml/ peppa_jpg/pegga_train_labels.csv
Successfully converted xml to csv.
▸ ./red_xml2csv.py peppa_valid_xml/ peppa_valid_jpg/peppa_valid_labels.csv
Successfully converted xml to csv.
就可以分别将训练集和校验集转换为相应的 csv 文件并存储到图像数据集的目录中,因为后续会分别在对应的目录中执行转换为TFRecord格式的操作进行。
执行的命令分别是:
▸python3.8 ../generate_tfrecord.py --csv_input=pegga_train_labels.csv --output_path=pegga_train.record
▸python3.8 ../generate_tfrecord.py --csv_input=pegga_valid_labels.csv --output_path=pegga_valid.record
至此,就完成了从原始的图像数据,到含有标注信息的TFRecord格式数据集的转换。接下来就是训练和校验了。
- 训练和校验的过程和第二章一样,只是数据集变了,这里只是展示下训练过程和模型导出过程的截图。
模型训练:
模型导出:
模型到处完成后,我们会看到模型在如下目录,以及其中的文件和从网上下载的TensorFlow2的模型压缩包里面的结构一样。
我们可以对比看看,我从网上下载的efficientdet_d0_coco17_tpu-32模型中的内容结构:
- 模型导出之后就是测试过程了,测试方法和第二章的方法一样,我就直接附上我从网上下载的测试图片和标注以后的图片:
希望本章可以为想上手通过机器学习进行目标检测的伙伴提供一点帮助,下一章,我就准备将模型部署到飞腾派进行测试了,敬请期待。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
模型
+关注
关注
1文章
3158浏览量
48700 -
目标检测
+关注
关注
0文章
204浏览量
15589 -
飞腾派
+关注
关注
2文章
9浏览量
204
发布评论请先 登录
相关推荐
【飞腾派4G版免费试用】飞腾派开发板运行Ubuntu系统
飞腾派4G版开发板是一款做工精细,布线合理的开发板,今天给大家介绍一下如何运行Ubuntu系统,下面是网上的资料,帮助大家快速认识飞腾派
发表于 01-08 22:40
【飞腾派4G版免费试用】飞腾派4G版开发板套装测试及环境搭建
先简单介绍一下这款飞腾派4G版开发板套装;
飞腾派是由中电港萤火工场研发的一款面向行业工程师、学生和爱好者的开源硬件。主板处理器采用
发表于 01-22 00:47
【飞腾派4G版免费试用】4.手把手玩转QT界面设计
完成了使用Qt Designer进行界面设计的全部流程!是不是觉得像魔法一样神奇呢?赶紧试试吧!
接上三篇:
【飞腾派4G版
发表于 01-27 12:49
【新品体验】飞腾派4G版基础套装免费试用
飞腾派是由飞腾携手中电港萤火工场研发的一款面向行业工程师、学生和爱好者的开源硬件,采用飞腾嵌入式四核处理器,兼容ARM V8架构,板载64位 DDR
发表于 10-25 11:44







 工商网监
工商网监
评论