 一个用于6D姿态估计和跟踪的统一基础模型
一个用于6D姿态估计和跟踪的统一基础模型
0. 笔者个人体会
今天笔者将为大家分享NVIDIA的最新开源方案FoundationPose,是一个用于 6D 姿态估计和跟踪的统一基础模型。只要给出CAD模型或少量参考图像,FoundationPose就可以在测试时立即应用于新物体,无需任何微调,关键是各项指标明显优于专为每个任务设计的SOTA方案。
下面一起来阅读一下这项工作,文末附论文和代码链接~
1. 效果展示
FoundationPose实现了新物体的6D姿态估计和跟踪,支持基于模型和无模型设置。在这四个任务中的每一个上,FoundationPose都优于专用任务的SOTA方案。(·表示仅RGB,×表示RGBD)。这里也推荐工坊推出的新课程《单目深度估计方法:算法梳理与代码实现》。
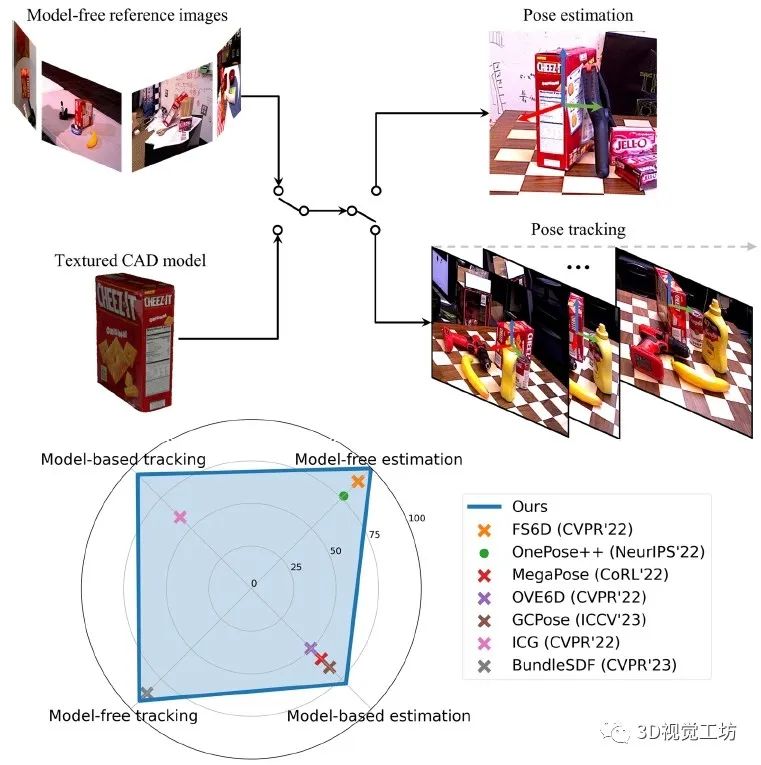
2. 具体原理是什么?
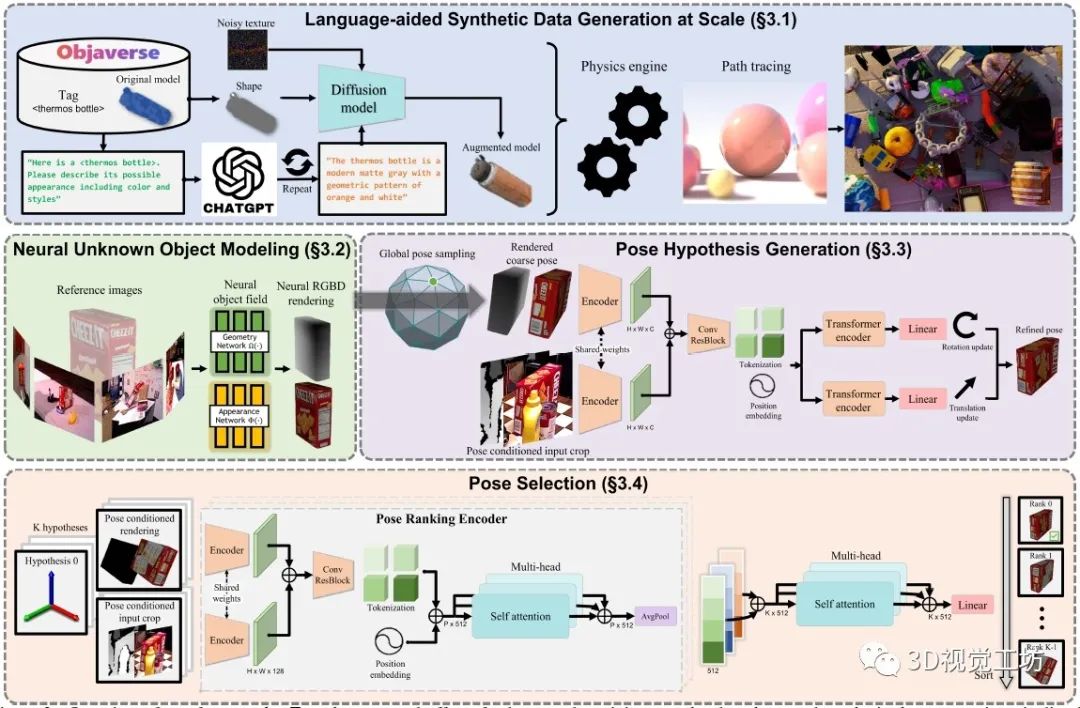
为减少大规模训练的人工工作,FoundationPose利用3D模型数据库、大型语言模型和扩散模型等新技术,开发了一种新的合成数据生成Pipeline。为了弥补无模型和基于模型的设置之间的差距,FoundationPose利用以对象为中心的神经场来进行随后的渲染和新视图RGBD渲染。
对于姿态估计,首先在物体周围均匀地初始化全局姿态,然后通过细化网络对其进行细化。最后将改进的位姿转发给姿态选择模块,预测位姿的分数,输出得分最高的位姿。
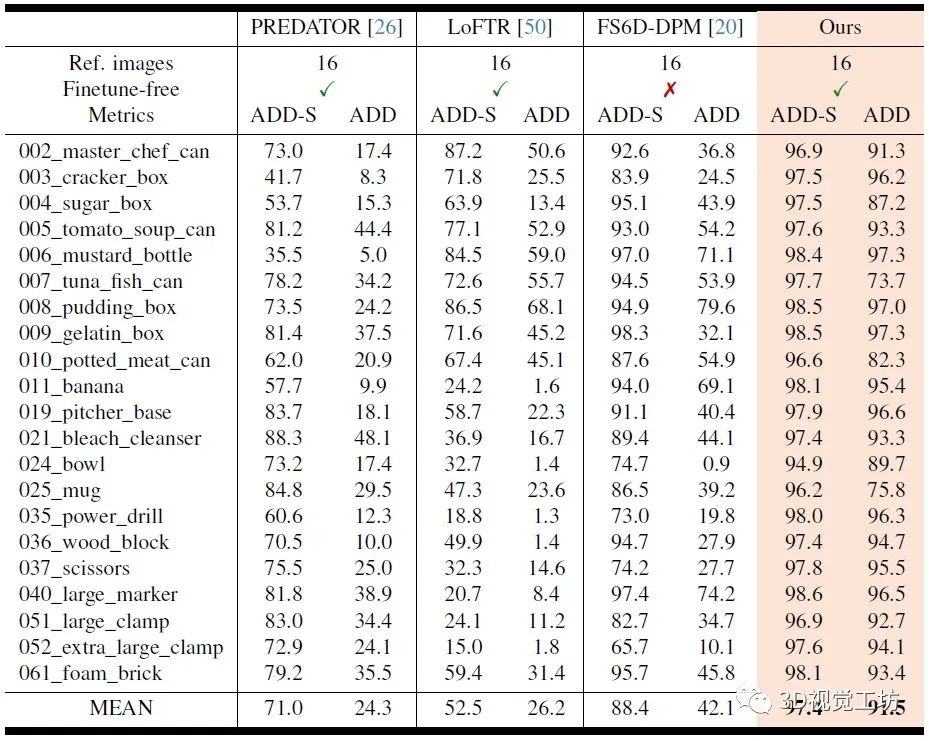
3. 和其他SOTA方法对比如何?
YCB-Video数据集上Model-free方案的位姿估计定量结果对比。
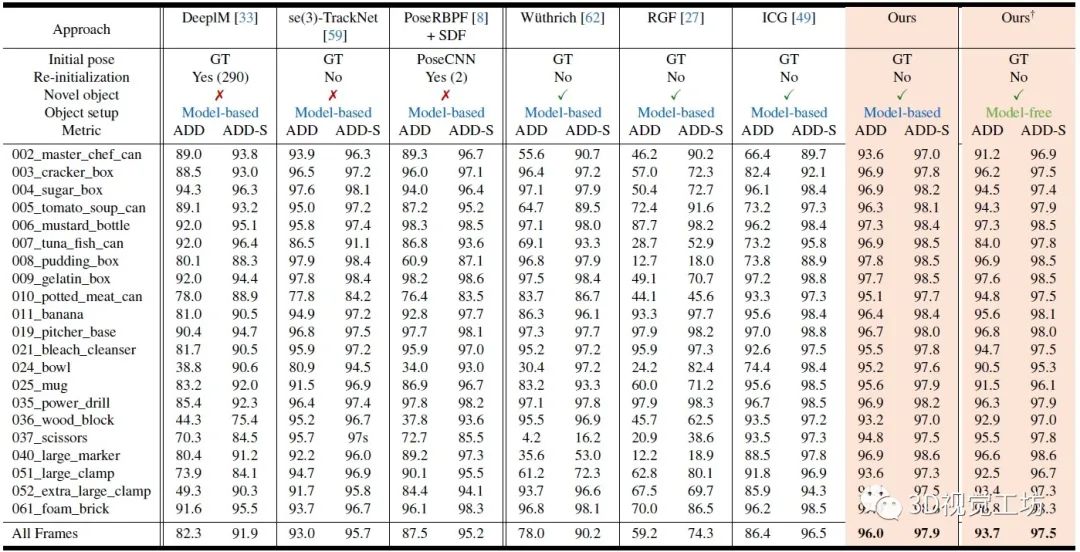
YCB-Video数据集上位姿跟踪的定量对比。这里也推荐工坊推出的新课程《单目深度估计方法:算法梳理与代码实现》。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
4. 论文信息
标题:FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
作者:Bowen Wen, Wei Yang, Jan Kautz, Stan Birchfield
机构:NVIDIA
原文链接:https://arxiv.org/abs/2312.08344
代码链接:https://github.com/NVlabs/FoundationPose
审核编辑:刘清
-
NVIDIA
+关注
关注
14文章
4986浏览量
103065 -
RGB
+关注
关注
4文章
798浏览量
58509
原文标题:通用性超强!同时实现6D位姿估计和跟踪!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
KerasHub统一、全面的预训练模型库
CNN, RNN, GNN和Transformer模型的统一表示和泛化误差理论分析
光学跟踪测量系统如何工作的
意法半导体新款MEMS IMU LSM6DSV32X实现精确姿态识别应用
包含具有多种类型信息的3D模型
Franka Robotics推出“Franka AI Companion”助力机器人领域研究创新

国产6D激光跟踪仪测量大尺寸空间姿态
激光跟踪仪|国产6D跟踪仪测量大尺寸空间姿态

高分工作!Uni3D:3D基础大模型,刷新多个SOTA!

【先楫HPM5361EVK开发板试用体验】06-基于MPU9250的姿态解算
陀螺仪LSM6DSV16X与AI集成(5)----6D方向检测功能







 工商网监
工商网监
评论