 NVIDIA 第九届 Sky Hackathon 优秀作品展示 | 静语画韵:艺术中的无声诗篇
NVIDIA 第九届 Sky Hackathon 优秀作品展示 | 静语画韵:艺术中的无声诗篇
NVIDIA 第九届Sky Hackathon 大赛旨在通过 NVIDIA Jetson 平台和 Microsoft Azure OpenAI 平台,由 NVIDIA 和 Microsoft 导师精心设计的大模型应用场景,引领参与者领略大模型的应用潜力,以及如何运用人工智能技术构建智能化解决方案。
本次 Hackathon 聚焦在如何在物联网设备上构建基于大模型的应用解决方案。参与者通过使用 NVIDIA Jetson 平台,亲身体验了大模型在图像识别和生成式模型调用方面的应用。从 Resnet50 模型的优化到 TensorRT 推理引擎的生成,每一步都呈现了 NVIDIA Jetson 在深度学习加速方面的卓越性能。
下文供稿自 NVIDIA 第九届 Sky Hackathon 大赛的冠军团队,通过本官方微信公众号推荐给开发者朋友们,希望开发者朋友们能够积极交流,碰撞出更多创新的火花!
在当前时代,数字化与人工智能正不断推动艺术与技术的深度融合,开创了全新的创作与体验方式。来自山东科技大学的团队(指导老师:王鲁昆老师,团队成员:许金浩、李振宇、王俊丰、纪中华)在最近的NVIDIA 第九届 Sky Hackathon中以其杰出的作品 Narrative Canvas 夺得冠军,成为这一趋势的杰出代表。本文旨在深入分析这个项目的核心理念、技术创新之处,以及它为艺术体验带来的革命性改变,展示了这个团队如何在艺术与技术交汇的边界上探索新领域。
项目仓库:https://github.com/1438802682/NarrativeCanvas
演示视频:https://www.bilibili.com/video/BV1rc411D7pP/
项目概览:图文互动的新纪元
项目介绍
Narrative Canvas 项目的核心,在于“图生文,文生图”的相互作用。画作激发文字的创作,文字又给画作赋予了新的生命。这种互动不仅增强了艺术作品的表现力,也为观者提供了一种全新的艺术体验。在这个过程中,观者可以看到一个故事从视觉形象转化为文字叙述,再从文字中重新想象出视觉画面,这是一场视觉与文字的双重旅行。
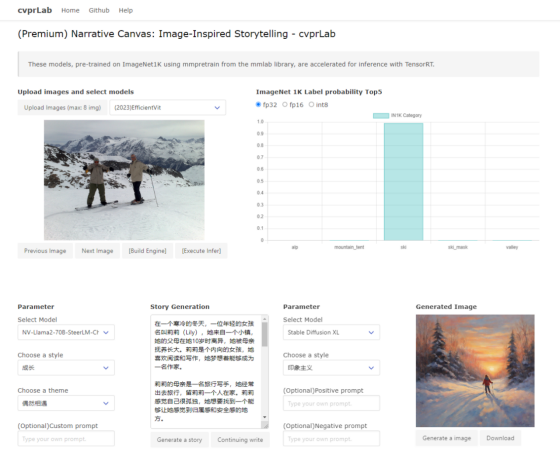
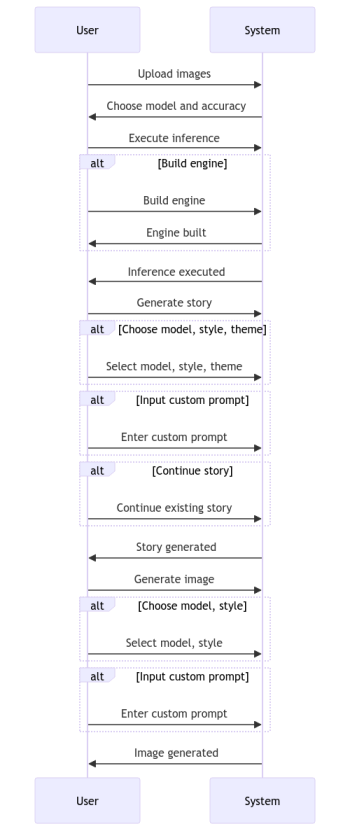
项目流程简述
-
图像推理:用户上传图片、选择模型和精度、执行推断,推断完成后得到处理过的图片。
-
生成故事:基于处理过的图片,用户选择模型、风格、主题和输入自定义提示词,完成故事生成。
-
生成图片:根据故事内容,用户再次选择模型、风格并输入自定义提示词,完成图像生成。
这个循环过程创造了一个从视觉到文本再回到视觉的独特旅程。
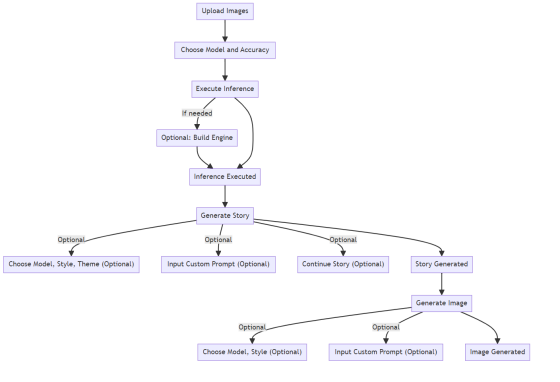
技术创新点
使用 NVIDIA Polygraphy
对 ONNX 模型预处理优化
该项目的图片推理部分基于 mmlab 算法库中的 mmpretrain 预训练模型,精选了25 个经典主干网络进行图像分类任务。
(2014)VGG 11
(2015)Inception v3
(2015)ResNet 50
(2017)ResNeXt 50
(2018)SE-ResNet 50
(2018)ShuffleNet v1
(2018)ShuffleNet v2
(2019)Res2Net 50
(2018)MobileNet v2
(2019)MobileNet v3
(2020)RegNet
(2019)EfficientNet
(2021)EfficientNet v2
(2021)Vision Transformer
(2021)Swin Transformer
(2021)Conformer
(2021)Twins
(2021)MobileViT
(2021)CLIP
(2021)DeiT
(2022)DeiT3
(2022)MViT V2
(2022)MobileOne
(2022)EdgeNeXt
(2023)EfficientVit
上下滑动查看更多↑↓
项目团队使用了 NVIDIA 的 Polygraphy 工具对 ONNX 模型进行了优化,移除和合并了多余节点,如多余的 Transpose 节点等,这些节点原本阻碍了 TensorRT 的优化。这使得 TensorRT 引擎构建更加高效。该团队将优化前后的 ONNX 模型和原始的 pt 权重都上传到 Hugging Face。
ONNX 模型优化文件下载地址:https://huggingface.co/CtrlX/ModelReady-pretrain/tree/main
优化过程包括:
-
移除无用节点:删除对输出无影响的节点。
-
合并冗余节点:将执行相似功能的节点合并。
-
优化图结构:通过节点合并和折叠,简化模型结构。
-
提高 TensorRT 兼容性:转换或减少特殊处理的节点。
-
加速推理性能:优化后的模型在 TensorRT 中运行更高效。
示例:以 2023 年的最新工作 EfficientVit 为例:
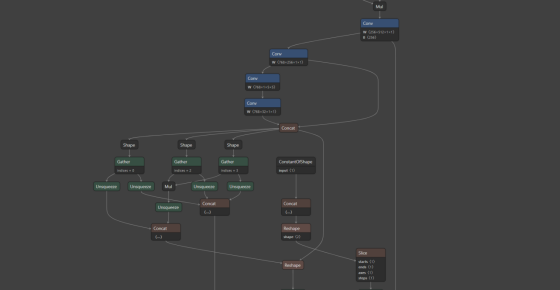
优化前的 ONNX 模型:
优化后的 ONNX 模型:
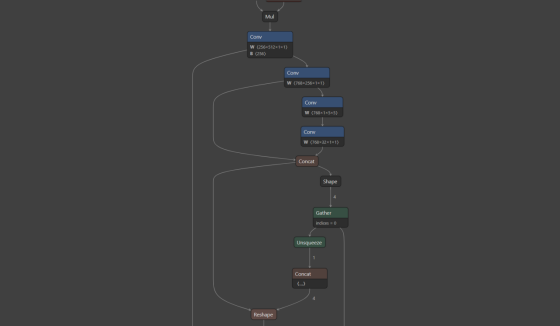
通过优化的日志文件可以看出优化后的模型去除了一半以上的冗余节点,节点数量由原来的 1440 减少到了 673,经过测试后没有发现明显的精度损失,但是大大提高了引擎的构建速度:

Note:提供 Jetson Xavier NX 平台的 TensorRT 引擎序列化文件
该项目团队提供了针对 Jetson Xavier NX 8G 平台的 TensorRT 引擎序列化文件,以便用户能够一键下载并在 Jetson Xavier NX 上直接进行推理,从而快速启动项目。
Jetson Xavier NX 平台序列化引擎文件下载地址:https://huggingface.co/CtrlX/ModelReady-TRT/tree/main/Jetson-Xavier-NX-8G/engine
NVIDIA TensorRT Dynamic Shape
模式在多图推理中的应用
在构建引擎过程中,该团队在项目中利用 NVIDIA 的 TensorRT 工具启用了 Dynamic Shape 功能于批处理维度,支持一次最多处理 8 张图片,显著提升了推理效率。
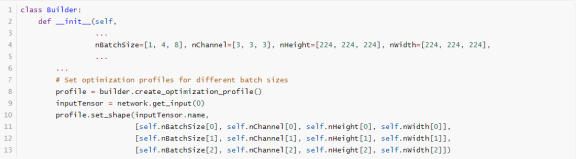
NVIDIA TensorRT实现
推理精度多元选择机制:fp32/fp16/int8
该项目提供了构建不同精度引擎的代码,允许用户根据需要在精度和速度之间做出选择。
默认情况下,TensorRT 以 32 位精度 (fp32) 工作,但也支持 16 位浮点 (fp16) 和 8 位量化浮点 (int8) 执行操作。使用较低精度能减少内存需求并加快计算速度。尽管 fp16 和 fp32 的使用相对简单,使用 int8 则涉及更多复杂性。有关 int8 的更多详情,请参见 INT8 章节。
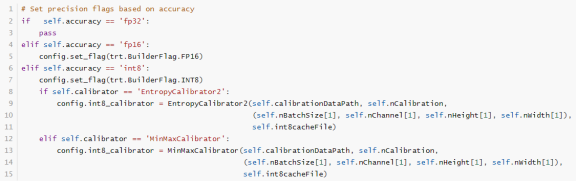
NVIDIA TensorRT:
启用 INT8 PTQ 量化加速推理机制
该项目通过使用 NVIDIA TensorRT 实现了 INT8 精度量化 (Post-Training Quantization, PTQ) 来加速推理。构建 INT8 引擎的步骤包括:
-
构建 32 位引擎,运行校准集,记录每个张量激活值分布的直方图。
-
根据直方图创建校准表,为每个张量提供标度值。
-
使用校准表和网络定义构建 INT8 引擎。
校准过程可能较慢,因此校准表的输出可以被缓存并重复使用,尤其适用于同一平台上重复构建相同网络的情况。
该项目提供了基于 ImageNet 1K val 数据集中 510 张图片的 INT8 Cache(校准表),使用 dynamic shape([batch, 3, 224, 224],batch 维度 1-8,opt=4)模式迭代 120 次。
针对 Xavier NX8G 平台,该团队测试了 10 种主流模型的 INT8 Cache 文件,由于时间限制未能覆盖全部 25 个模型,但提供了优化后的 ONNX 模型文件,可供后续测试。
ImageNet1k INT8 Cache 文件下载地址:https://huggingface.co/CtrlX/ModelReady-TRT/tree/main/Jetson-Xavier-NX-8G/int8Cache
Note:Dynamic Shape 模式与 INT8 PTQ
要在具有动态形状的网络上运行 INT8 校准,需设置校准优化配置文件,使用配置文件的 kOPT 值进行校准,且校准输入数据大小必须与配置文件匹配。
创建校准优化配置文件的示例代码如下:
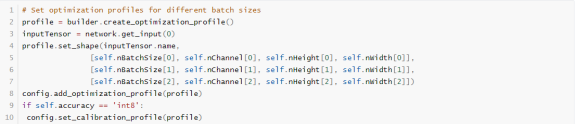
Note:双模式 INT8 量化策略
该项目为不同类型的主干网络提供了两种 INT8 量化策略:
-
trt.IInt8MinMaxCalibrator
这种方法选择张量的比例因子以优化量化张量的信息论内容,通常会抑制分布中的异常值。这是目前推荐的熵校准器,也是 DLA 所必需的。校准通常在层融合之前进行,校准批量大小可能会影响结果。推荐用于基于 CNN 的网络。
-
trt.IInt8EntropyCalibrator2
这个校准器使用激活分布的整个范围来确定比例因子,似乎更适合于 NLP 任务。校准一般在层融合之前进行。推荐用于 NVIDIA BERT(Google 官方实现的优化版本)等网络。
NVIDIA TensorRT:
Timing Cache 优化加速引擎构建
项目团队通过在 NVIDIA TensorRT 中开启 Timing Cache 优化了神经网络模型的引擎构建过程。这种方法利用了模型中重复的 layer,记录下算子的优化结果。当再次遇到相同的算子时,系统会直接使用优选结果,而非重新评估所有可行的 kernel,从而加速构建过程。
Timing Cache 文件下载地址:
https://huggingface.co/CtrlX/ModelReady-TRT/tree/main/Jetson-Xavier-NX-8G/int8Cache
下面借用了 TensorRT cookbook 中的一个示例展示 Timing Cache 的加速效果:
开启了 Timing Cache 前的日志信息:
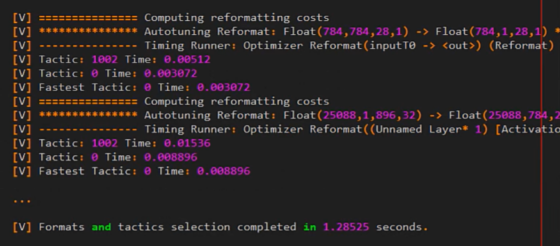
开启了 Timing Cache 后的日志信息:
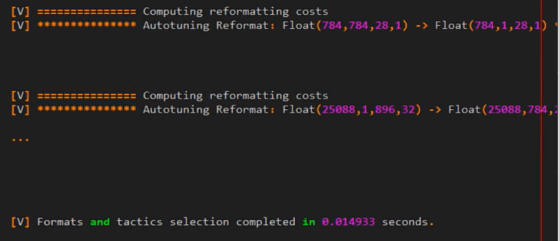
日志信息显示,通过 Timing Cache,多次测试被跳过,TensorRT 直接在 Cache 中找到了最快的算法。经过测试的时间显示:
-
未启用 Timing Cache:1707.987785 ms
-
初次启用 Timing Cache:774.889298 ms
-
后续使用 Timing Cache:32.098293 ms
以下是该项目中与 Timing Cache 相关的 Build 代码(models/Build.py)部分,团队还提供了 Timing Cache 融合接口的多种优化方式:

NVIDIA NeMo Guardrails:
增强 LLM 应用的可编程护栏工具
项目在生成故事部分使用了 NeMo Guardrails,以防止大模型输出的敏感内容被用户接收。这为 LLM 服务提供了多种护栏类型,如输入护栏、对话护栏、检索护栏等。同时,项目提供了使用 Colang 编写的 NeMo Guardrails 示例。
(位于 models/configurations.py )
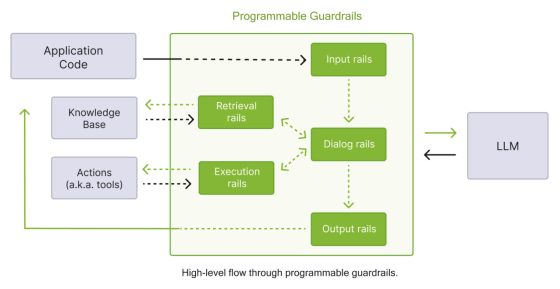
NeMo Guardrails 为 LLM 服务提供五种主要护栏类型:
-
输入护栏(Input Rails):应用于用户输入,可能拒绝或更改输入。
-
对话护栏(Dialog Rails):影响 LLM 的提示方式,操作规范消息并决定是否执行某些操作。
-
检索护栏(Retrieval Rails):应用于 RAG 场景下检索的内容,可能拒绝或更改相关块。
-
执行护栏(Execution Rails):应用于需要自定义操作的输入/输出。
-
输出护栏(Output Rails):应用于 LLM 生成的输出,可能拒绝或更改输出。

示例 Colang 配置:

在项目的 models/Generater 中的 AzureChatBot 类中,护栏被用作 Azure OpenAI gpt-3.5-turbo 服务的一部分。

项目架构
UI 设计原型图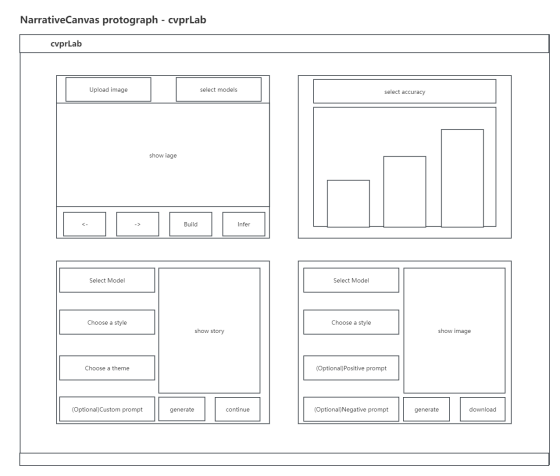
项目结构图
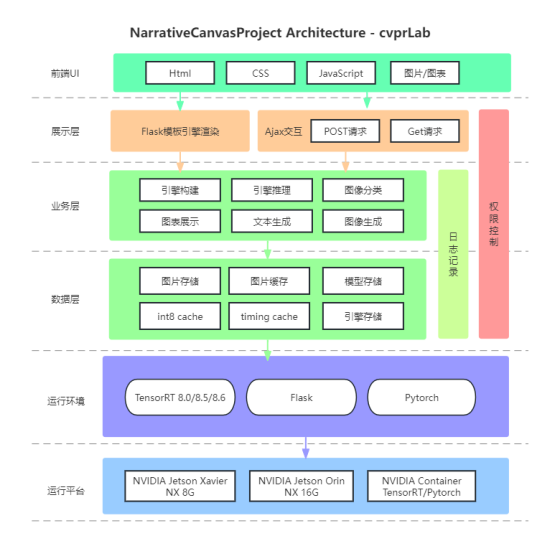
项目流程图
*本文中图片来源于山东科技大学的团队,若您有任何疑问或需要使用本文中图片,请联系山东科技大学的团队。
点击“阅读原文”或扫描海报二维码,锁定北京时间 1 月 9 日 (星期二) 凌晨 0 点举行的线上 NVIDIA CES 2024 特别演讲。
原文标题:NVIDIA 第九届 Sky Hackathon 优秀作品展示 | 静语画韵:艺术中的无声诗篇
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3872浏览量
92403
原文标题:NVIDIA 第九届 Sky Hackathon 优秀作品展示 | 静语画韵:艺术中的无声诗篇
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
联想全栈AI保障第九届亚冬会顺利举办
OFweek2024 第九届物联网产业大会圆满收官!

亿纬锂能亮相第九届动力电池应用国际峰会
博泰车联网荣获第九届铃轩奖两项大奖
东软斩获第九届铃轩奖两项大奖
保隆科技荣获第九届铃轩奖智能驾驶类优秀奖
地平线荣获第九届铃轩奖前瞻类智能驾驶金奖
紫光同芯第二代汽车域控芯片THA6荣膺第九届铃轩奖 | 贞光科技代理品牌

极海半导体GALT61120斩获第九届铃轩奖
简仪科技与您相约第九届开源测控开发者大会
天合智慧能源亮相2024第九届光伏产业大会
思必驰亮相第九届华为全联接大会
CET中电技术邀您参加2024第九届中国新型煤化工国际研讨会

研华荣获信通院工业数字孪生大赛优秀作品奖






 工商网监
工商网监
评论