 深入了解RDMA技术
深入了解RDMA技术
作者简介
Explorer,专注于高性能网络、虚拟化网络及网卡的测试方案研究。熟悉dpdk,rdma,sdn等技术的应用与解决方案。
01深入了解RDMA技术
背景概述
随着互联网的普及和数字化转型的加速,大量数据被生成和传输。在AI训练和推理、大数据分析以及存储应用中,处理这些海量数据变得至关重要。因此,高性能网络对于快速而可靠的数据传输至关重要。
RDMA(Remote Direct Memory Access,远程直接内存访问)是一种高效的数据传输技术,它使得两台计算机之间可以直接从对方的内存中读取或写入数据,而不需要CPU的介入。通过RDMA,计算机之间的数据传输速度更快,延迟更低,传输效率更高,而且可以减少CPU的负载。
应用场景
RDMA技术在各个领域都有广泛的应用,其高性能和低延迟的特点使其成为许多应用的关键组成部分,以下是当前RDMA技术的一些应用场景介绍:
高性能计算(HPC)
RDMA技术在HPC领域得到广泛应用,用于大规模科学计算、气象模拟、分子建模等任务。RDMA可以实现节点之间的快速数据共享,从而加速复杂计算任务的完成,降低了整体计算时间。
云计算和虚拟化
公有云和私有云服务提供商采用RDMA技术来改善虚拟机之间的通信性能。这在云环境中特别重要,因为它可以提高虚拟机之间的网络吞吐量,从而提高了云计算资源的利用率。
存储系统
RDMA技术在高性能存储系统中发挥重要作用,如分布式文件系统、SAN存储、块存储等。它提供了低延迟、高带宽的数据传输,有助于加速数据读写操作,提高存储性能。
金融交易
在金融领域,时间和性能至关重要。RDMA技术用于构建低延迟的交易系统,确保交易数据能够实时传输和处理,从而降低了交易风险。
训练深度学习模型需要大量数据传输和计算资源。RDMA技术可用于加速大规模深度学习任务,减少模型训练时间。
实时数据分析
对于需要实时数据分析的应用,如广告投放、市场分析和网络安全监控,RDMA技术可以确保数据能够实时传输和分析,提供即时决策支持。
远程备份和复制
在数据备份和复制中,RDMA技术可以加速数据传输,降低备份时间,同时提供数据完整性和可靠性。
高性能数据库
RDMA技术可用于构建高性能数据库系统,实现快速数据访问和查询操作,从而加速数据处理。
RDMA技术在各种领域中都有重要应用,特别是在需要高性能、低延迟和大规模数据传输的场景中。它为这些应用提供了关键的网络通信支持,加速了各种计算和数据处理任务,有助于提高系统性能和效率。随着技术的不断发展,RDMA技术的应用前景将继续扩展。
技术特点
内核 Bypass:RDMA允许数据直接在内存之间传输,而不需要通过操作系统内核。传统的Socket通信在数据传输时需要将数据从用户空间复制到内核空间,然后再从内核空间复制到另一个用户空间。而RDMA通过绕过内核,使数据可以直接在用户空间之间传输,从而减少了数据复制的开销,提高了数据传输效率。
零拷贝:RDMA支持零拷贝操作,意味着数据可以直接在应用程序的内存空间中传输,而无需中间的数据拷贝操作。这减少了CPU的负担和数据传输的延迟,提高了系统性能。
协议卸载:RDMA技术允许网络适配器卸载协议的处理任务,将网络协议的处理从主机CPU转移到网络适配器上。这样可以减轻主机CPU的负担,提高系统整体性能。
低延迟和高吞吐量:RDMA的直接内存访问和零拷贝特性导致了低延迟和高吞吐量。数据可以直接在内存之间传输,而不需要中间的数据复制,从而减少了通信的延迟并提高了数据传输的速率。
支持远程直接内存访问:RDMA允许应用程序直接访问远程主机的内存,而无需通过中间服务器进行数据传输。这使得在分布式系统中进行高效的数据共享成为可能,同时减少了通信的开销。
支持协议
RDMA技术支持三类协议,分别为InfiniBand(IB),RDMA over Converged Ethernet(RoCE)和internet Wide Area RDMA Protocol(iWARP),三类协议使用相同的RDMA标准。
>InfiniBand
InfiniBand是一种基于InfiniBand架构的RDMA技术,它提供了一种基于通道的点对点消息队列转发模型,每个应用都可通过创建的虚拟通道直接获取本应用的数据消息,无需其他操作系统及协议栈的介入。InfiniBand架构的应用层采用了RDMA技术,可以提供远程节点间RDMA读写访问,完全卸载CPU工作负载;网络传输采用了高带宽的传输;链路层设置特定的重传机制保证服务质量,不需要数据缓冲。
InfiniBand必须运行在InfiniBand网络环境下,必须使用IB交换机及IB网卡才可实现。
>RoCE
RoCE技术支持在以太网上承载IB协议,实现RDMA over Ethernet。RoCE与InfiniBand技术有相同的软件应用层及传输控制层,仅网络层及以太网链路层存在差异。
RoCE v1协议:基于以太网承载RDMA,只能部署于二层网络,它的报文结构是在原有的IB架构的报文上增加二层以太网的报文头,通过Ethertype 0x8915标识RoCE报文。
RoCE v2协议:基于UDP/IP协议承载RDMA,可部署于三层网络,它的报文结构是在原有的IB架构的报文上增加UDP头、IP头和二层以太网报文头,通过UDP目的端口号4791标识RoCE报文。RoCE v2支持基于源端口号hash,采用ECMP实现负载分担,提高了网络的利用率。
下图为RoCE的协议栈:
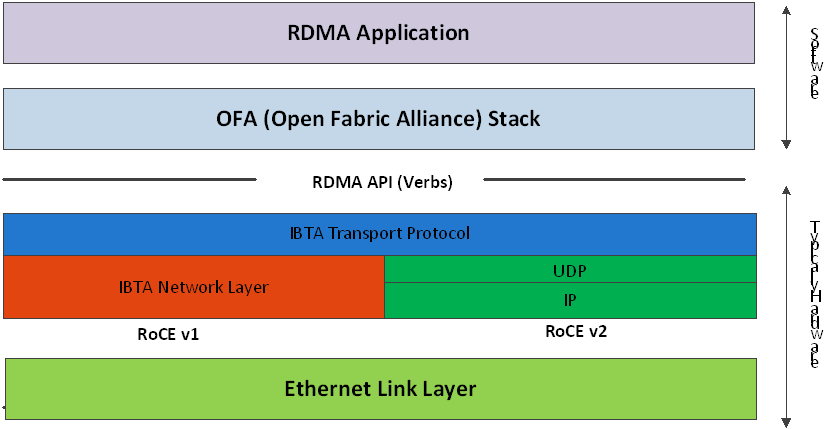
| RoCE协议栈
>iWARP
iWARP协议是IETF基于TCP提出的,因为TCP是面向连接的可靠协议,这使得iWARP在面对有损网络场景(可以理解为网络环境中可能经常出现丢包)时相比于RoCE v2和IB具有更好的可靠性,在大规模组网时也有明显的优势。但是大量的TCP连接会耗费很多的内存资源,另外TCP复杂的流控等机制会导致性能问题,所以从性能上看iWARP要比UDP的RoCE v2和IB差。
>网络设备
在实际的生产环境中,无论是何种协议支持的RDMA技术,都需要硬件的支撑。
支持iWARP和RoCEv2的Intel E810系列网卡:https://www.intel.cn/content/www/cn/zh/products/sku/192558/intel-ethernet-network-adapter-e810cqda2/specifications.html
支持InfiniBand的Mellanox CX-7系列网卡:https://nvdam.widen.net/s/csf8rmnqwl/infiniband-ethernet-datasheet-connectx-7-ds-nv-us-2544471
支持InfiniBand的NVIDIA Quantum-2 InfiniBand系列交换机:
https://nvdam.widen.net/s/k8sqcr6gzb/infiniband-quantum-2-qm9700-series-datasheet-us-nvidia-1751454-r8-web

02构建RDMA环境
使用2张Mellanox CX-4对接测试RoCEv2功能及性能
Mellanox官网下载CX-4的OFED驱动
下载基础软件包
yum install libusbx lsof tcl gcc-gfortran fuse-libs tcsh tk perl pcituiles
解压驱动后安装
./mlnxofedinstall
安装完成后,载入新驱动
[root@localhost MLNX_OFED_LINUX-5.8-2.0.3.0-rhel7.9-x86_64]# /etc/init.d/openibd restart
Unloading HCA driver: [ OK ]
Loading HCA driver and Access Layer: [ OK ]
查看节点上RDMA设备,node GUID对应的是网卡的mac地址
[root@localhost ~]# ibv_devices
device node GUID
------ ----------------
mlx5_0 b8cef60300ed9572
mlx5_1 b8cef60300ed9573
查看device mlx5_0的port状态,这里rate为25Gb/sec
[root@localhost ~]# ibstatus mlx5_0
Infiniband device 'mlx5_0' port 1 status:
default gid: fe800000bacefeed:9572
base lid: 0x0
sm lid: 0x0
state: 4: ACTIVE
phys state: 5: LinkUp
rate: 25 Gb/sec (1X EDR)
link_layer: Ethernet
到这里,最简单的RDMA环境搭建完成,如果需要测试高阶功能,例如PFC,ECN或者ECMP则需要更复杂的组网,也需要引入相应的交换机来支持功能的验证。
03RDMA测试实验
CM建链测试
实验目的:Communication Management Protocol,通信管理协议。指的是一种建立于Infiniband/RoCE协议基础之上的建链方式。以下实验通过抓取CM建链过程中数据包交互的过程,来验证是否符合IB协议所定义的建链流程。
以RC建链过程测试为例:
服务端启动# ib_send_bw -F -d mlx5_0 -s 100 -n 5 -R
客户端启动#ib_send_bw -F -d mlx5_0 -s 100 -n 5 192.168.100.9 -R
通过抓包分析RC CM建链的过程:
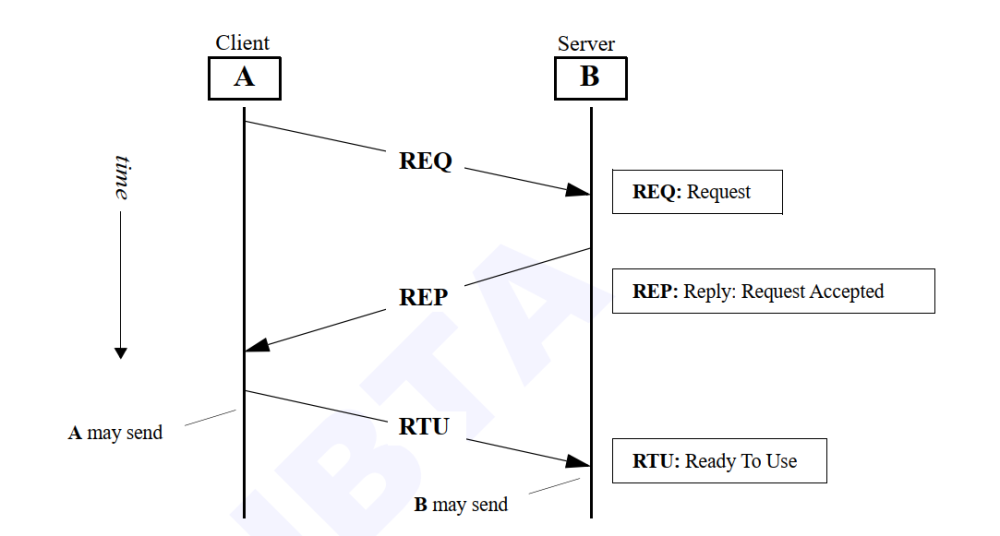
| CM RC建链过程
client和server端交互的数据报文如下:
RC CM建链的过程一共有3个数据包,分别是ConnectRequest,ConnectReply和ReadToUse。建链完成后,就开始按照交换好的QP信息进行数据发送。

REQ用于启动CM建链,client端发送请求,提供端口地址(GID/LID),以及本端的QPN信息。
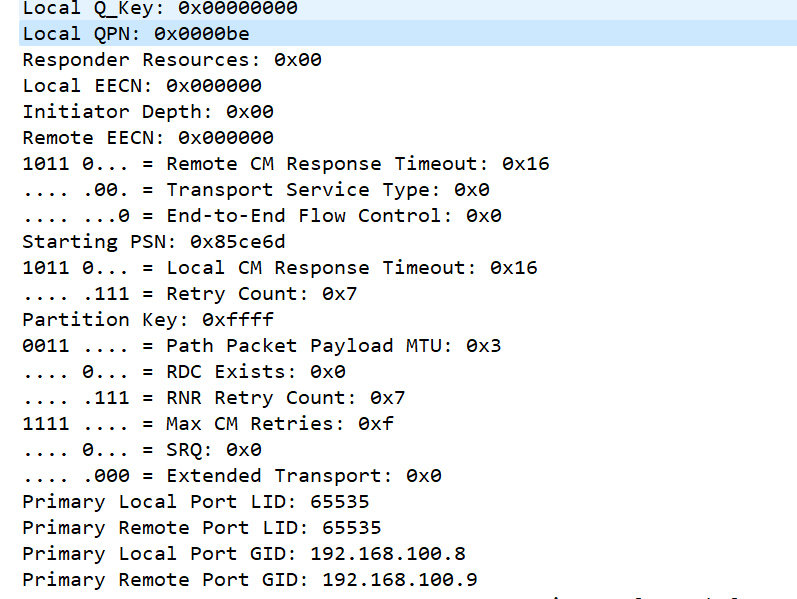
REP用于server端在接收到REQ后,验证了serviceid,primary以及private data里面的数据后,接收了client端的连接请求,并且发送了REP消息,携带了本端的QPN,起始PSN等信息。
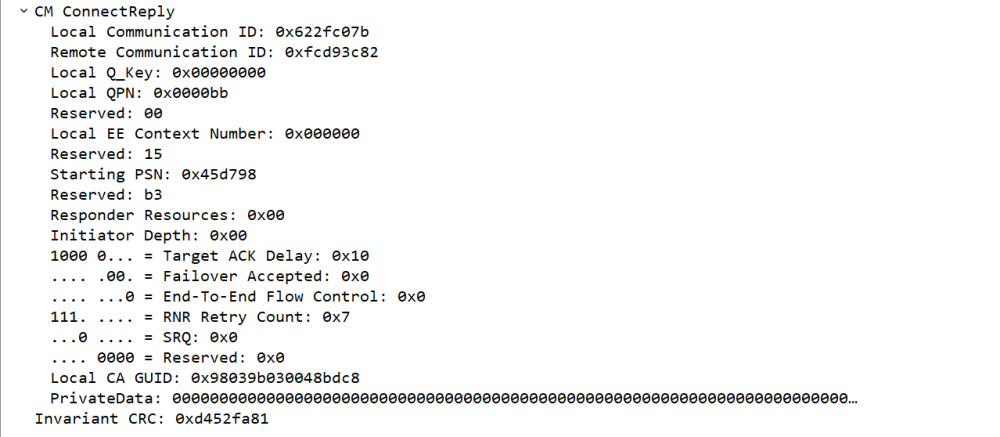
RTU消息则表示client端接收到REP后,根据双方约定好后的QP进行数据交互。
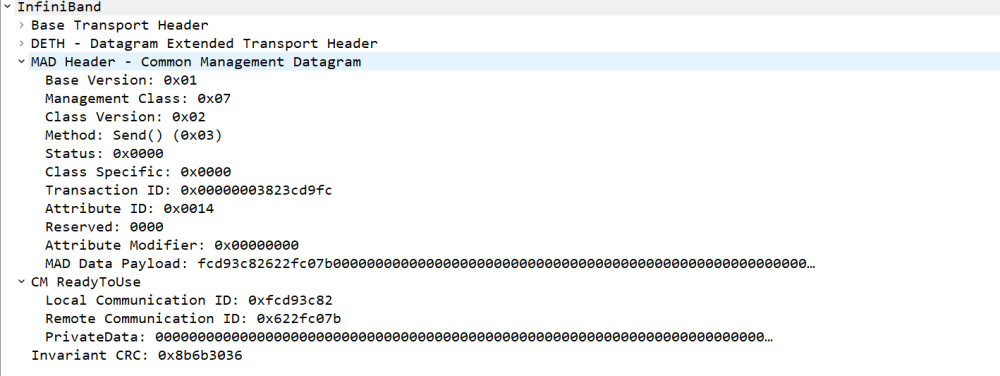
回过头来查看perftest执行后的结果,本端的QP 190(0x00be)和对端的QP187 (0x00bb)建立连接并发送数据。
[root@localhost ~]# ib_send_bw -F -d mlx5_0 -s 100 -n 5 -R 192.168.100.9
---------------------------------------------------------------------------------------
Send BW Test
Dual-port : OFF Device : mlx5_0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : ON
TX depth : 5
CQ Moderation : 5
Mtu : 1024[B]
Link type : Ethernet
GID index : 3
Max inline data : 0[B]
rdma_cm QPs : ON
Data ex. method : rdma_cm
---------------------------------------------------------------------------------------
local address: LID 0000 QPN 0x00be PSN 0x524880
GID: 0000000000255192100:08
remote address: LID 0000 QPN 0x00bb PSN 0x429476
GID: 0000000000255192100:09
---------------------------------------------------------------------------------------
#bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps]
100 5 49.75 49.74 0.521597
---------------------------------------------------------------------------------------
也可以通过后续交换的数据包来查看QP信息,发给远端QPN 187(0x00bb)的send数据:
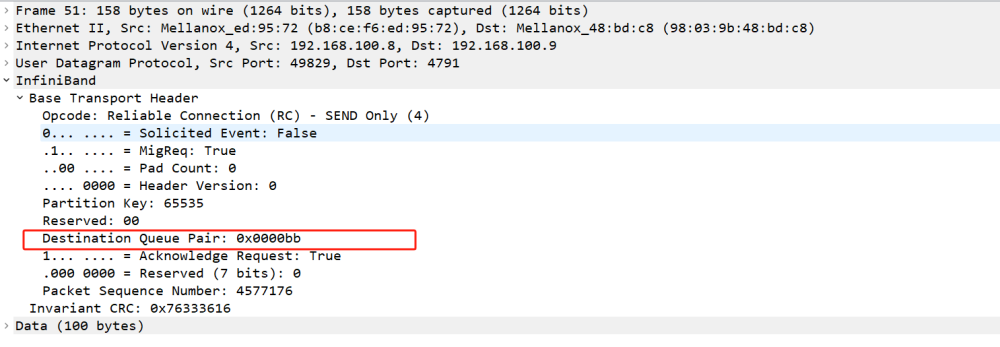
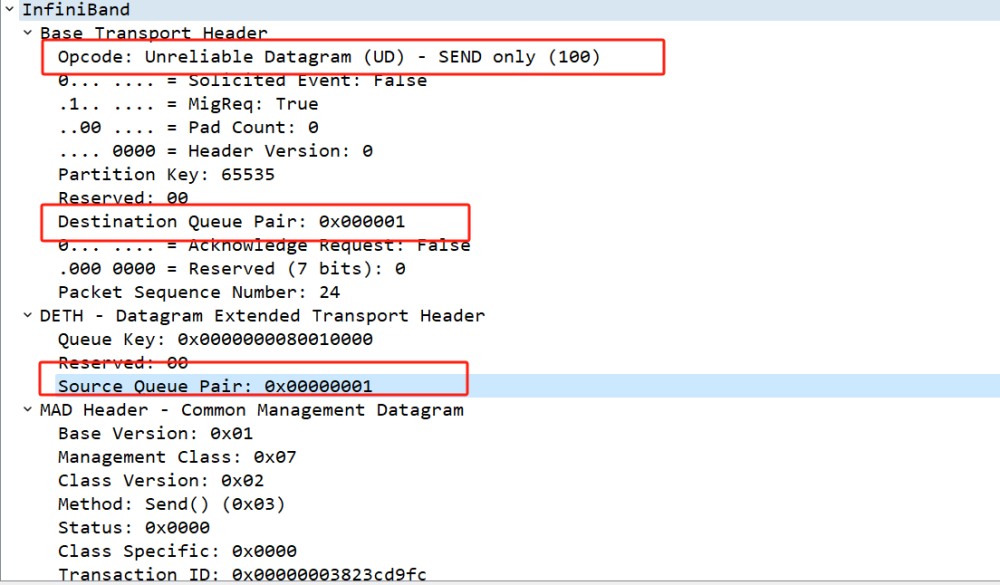
在CM建链测试的最后,我们需要关注在建链的过程中,client端和server端其实是通过send ud消息来交互建链过程,这个过程中所使用的QP为QP1。
这里顺便提一句,在RDMA中,有几个QP是预留的,QP0用于处理子网管理消息,QP1用于处理 SA(Subnet Administrator)或 GS(Generic Services)的消息。
RC(Reliable Connection)测试
实验目的:在RC服务类型中,通信的两端建立了一个可靠的连接。这种连接模型提供了类似于TCP的可靠性,确保数据的按序传递和可靠传输。在RDMA的RC模型中,数据传输的顺序是有保障的,且通信的两端可以进行错误检测和重传。以下实验验证client端和server端是否可以建立正常的RC连接,并进行数据包的传输。
RC的测试通常使用write或者read类型的消息来进行验证,通过设置数据包长度与pmtu的组合来验证各类消息报文。
服务端测试指令
[root@localhost ~]# ib_write_bw -F -d mlx5_0 -s 64 -p 1024 -n 100 -c RC
客户端测试指令
[root@localhost ~]# ib_write_bw -F -d mlx5_0 -s 64 -p 1024 -n 100 -c RC 192.168.100.9
---------------------------------------------------------------------------------------
RDMA_Write BW Test
Dual-port : OFF Device : mlx5_0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : ON
TX depth : 100
CQ Moderation : 100
Mtu : 1024[B]
Link type : Ethernet
GID index : 3
Max inline data : 0[B]
rdma_cm QPs : OFF
Data ex. method : Ethernet
---------------------------------------------------------------------------------------
local address: LID 0000 QPN 0x00eb PSN 0x76710c RKey 0x1fcffc VAddr 0x000000021a2000
GID: 0000000000255192100:08
remote address: LID 0000 QPN 0x00e8 PSN 0xcc230d RKey 0x1fcef8 VAddr 0x00000000f68000
GID: 0000000000255192100:09
---------------------------------------------------------------------------------------
#bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps]
64 100 243.35 190.55 3.121944
---------------------------------------------------------------------------------------
这里指定了数据包长度为64,pmtu长度为1024。当数据包长度小于pmtu时,则write的消息都为“write only"。

修改数据包长度进行再次测试,当数据包长度大于pmtu,且小于2*pmtu时,则wirte的消息为“write first”和“write last”。
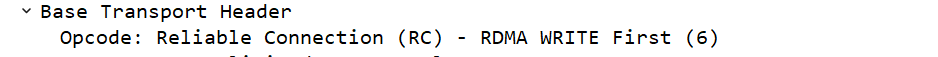
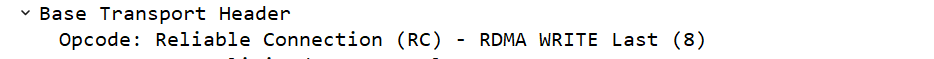
修改数据包长度进行再次测试,当数据包长度大于2*pmtu时,则write的消息为write first”,“write middle”和“write last”。
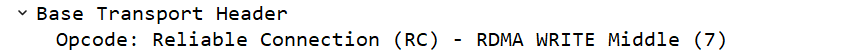
当然测试的时候也可以修改pmtu进行验证,pmtu有严格的长度要求,例如256,512,1024等。如下图虽然MTU为1500,但是实际的RDMA PMTU为1024。
[root@localhost /]# ibv_devinfo
hca_id: mlx5_0
transport: InfiniBand (0)
fw_ver: 14.32.1010
node_guid: b8ce00ed:9572
sys_image_guid: b8ce00ed:9572
vendor_id: 0x02c9
vendor_part_id: 4117
hw_ver: 0x0
board_id: MT_2420110034
phys_port_cnt: 1
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 1024 (3)
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet
UD(Unreliable Datagram)测试
实验目的:UD 连接更注重性能,适用于那些对数据传输的可靠性要求相对较低的场景。以下实验验证client端与server端是否可以建立正常的UD连接,并进行数据包的传输。
在RDMA的消息类型中,UD测试只支持send消息类型,不支持write和read,这里使用send消息进行测试。
客户端测试指令
[root@localhost ~]# ib_send_bw -F -d mlx5_0 -s 64 -p 1024 -n 100 -c UD
服务端测试指令
[root@localhost ~]# ib_send_bw -F -d mlx5_0 -n 100 -s 64 -p 1024 -c UD 192.168.100.9
---------------------------------------------------------------------------------------
Send BW Test
Dual-port : OFF Device : mlx5_0
Number of qps : 1 Transport type : IB
Connection type : UD Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : ON
TX depth : 100
CQ Moderation : 100
Mtu : 1024[B]
Link type : Ethernet
GID index : 3
Max inline data : 0[B]
rdma_cm QPs : OFF
Data ex. method : Ethernet
---------------------------------------------------------------------------------------
local address: LID 0000 QPN 0x1146 PSN 0x3def86
GID: 0000000000255192100:08
remote address: LID 0000 QPN 0x1152 PSN 0x3c2738
GID: 0000000000255192100:09
---------------------------------------------------------------------------------------
#bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps]
64 100 152.03 98.70 1.617092
---------------------------------------------------------------------------------------
同RC测试一样,修改数据包长度与pmtu,可以验证不同的send消息报文,这不分测试不再赘述。
性能测试
RDMA 技术的设计目标之一是提供高性能、低延迟的远程数据访问,所以在RDMA的实验中,关于性能的实验尤为重要。性能测试项指标,一般关注各类型消息的带宽和延时。
ib_send_lat latency test with send transactions
ib_send_bw bandwidth test with send transactions
ib_write_lat latency test with RDMA write transactions
ib_write_bw bandwidth test with RDMA write transactions
ib_read_lat latency test with RDMA read transactions
ib_read_bw bandwidth test with RDMA read transactions
ib_atomic_lat latency test with atomic transactions
ib_atomic_bw bandwidth test with atomic transactions
>bw测试
这里带宽测试使用write消息来进行
write 服务端测试指令
[root@localhost ~]# ib_write_bw -F -d mlx5_0 -s 4096 -n 10000 --report_gbits -t 128 -q 4
write客户端测试指令
[root@localhost ~]# ib_write_bw -F -d mlx5_0 -s 4096 -n 10000 192.168.100.9 --report_gbits -t 128 -q 4
---------------------------------------------------------------------------------------
RDMA_Write BW Test
Dual-port : OFF Device : mlx5_0
Number of qps : 4 Transport type : IB
Connection type : RC Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : ON
TX depth : 128
CQ Moderation : 100
Mtu : 1024[B]
Link type : Ethernet
GID index : 3
Max inline data : 0[B]
rdma_cm QPs : OFF
Data ex. method : Ethernet
---------------------------------------------------------------------------------------
local address: LID 0000 QPN 0x00df PSN 0x5a67fc RKey 0x1fcff3 VAddr 0x00000000d54000
GID: 0000000000255192100:08
local address: LID 0000 QPN 0x00e0 PSN 0x788b6d RKey 0x1fcff3 VAddr 0x00000000d55000
GID: 0000000000255192100:08
local address: LID 0000 QPN 0x00e1 PSN 0xe597d RKey 0x1fcff3 VAddr 0x00000000d56000
GID: 0000000000255192100:08
local address: LID 0000 QPN 0x00e2 PSN 0x6e9451 RKey 0x1fcff3 VAddr 0x00000000d57000
GID: 0000000000255192100:08
remote address: LID 0000 QPN 0x00dc PSN 0xfe4945 RKey 0x1fceef VAddr 0x00000000a13000
GID: 0000000000255192100:09
remote address: LID 0000 QPN 0x00dd PSN 0xf30d82 RKey 0x1fceef VAddr 0x00000000a14000
GID: 0000000000255192100:09
remote address: LID 0000 QPN 0x00de PSN 0x729a6e RKey 0x1fceef VAddr 0x00000000a15000
GID: 0000000000255192100:09
remote address: LID 0000 QPN 0x00df PSN 0xa2c0ee RKey 0x1fceef VAddr 0x00000000a16000
GID: 0000000000255192100:09
---------------------------------------------------------------------------------------
#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]
4096 40000 23.05 23.05 0.703393
---------------------------------------------------------------------------------------
这里介绍一下几个性能相关参数:
s 4096:使用长度为4096字节的数据包进行测试,大包的性能会优于小包。
n 10000:测试数据包数,数量过小的话测试性能会有偏差。
t 128:tx队列深度。
q 4:使用qp数。
最后带宽结果为23.05Gb/sec,上文有描述本次测试使用的网卡带宽规格为25Gb/sec,这里RoCE的性能已经快要跑满网卡。
>lat测试
这里进行read消息的延时测试
read 服务端测试指令
[root@localhost ~]# ib_read_lat -F -d mlx5_0 -s 4096 -n 10000
read 客户端测试指令
测试延时的话是不能使用多QP的,只能使用1个QP进行测试
[root@localhost ~]# ib_read_lat -F -d mlx5_0 -s 4096 -n 10000 192.168.100.9 -t 128
---------------------------------------------------------------------------------------
RDMA_Read Latency Test
Dual-port : OFF Device : mlx5_0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : ON
TX depth : 128
Mtu : 1024[B]
Link type : Ethernet
GID index : 3
Outstand reads : 16
rdma_cm QPs : OFF
Data ex. method : Ethernet
---------------------------------------------------------------------------------------
local address: LID 0000 QPN 0x00e9 PSN 0xf265e5 OUT 0x10 RKey 0x1fcffa VAddr 0x00000002090000
GID: 0000000000255192100:08
remote address: LID 0000 QPN 0x00e6 PSN 0x396d2b OUT 0x10 RKey 0x1fcef6 VAddr 0x000000013f0000
GID: 0000000000255192100:09
---------------------------------------------------------------------------------------
#bytes #iterations t_min[usec] t_max[usec] t_typical[usec] t_avg[usec] t_stdev[usec] 99% percentile[usec] 99.9% percentile[usec]
4096 10000 4.89 23.00 5.15 5.27 0.84 6.75 19.88
---------------------------------------------------------------------------------------
观察最后的延时结果,其中99.9%的延时实验数据为19.88usec。
04RDMA的抓包方式
抓取RDMA数据包流量的方式有多种,交换机配置端口镜像后,RDMA数据包通过镜像口抓取比较常见。
这里介绍一种通过容器中的tcpdump捕获Mellanox RDMA数据包的方式。
1)首先拉取tcpdump-rdma的镜像:
[root@localhost ~]# docker pull mellanox/tcpdump-rdma
Using default tag: latest
latest: Pulling from mellanox/tcpdump-rdma
74f0853ba93b: Pull complete
1f89d668986d: Pull complete
2d176f9a99da: Pull complete
Digest: sha256:3b7b1aa52cf8f9fe0e55845463fb4c4a4147eae1f6bddf5d82b8b08cf954b66c
Status: Downloaded newer image for mellanox/tcpdump-rdma:latest
docker.io/mellanox/tcpdump-rdma:latest
2)启动tcpdump-rdma容器,通过把主机上的/dev/infiniband设备映射到容器中,同时把主机上的/tmp/rdma目录也映射到容器中去:
[root@localhost ~]#docker run -it -v /dev/infiniband:/dev/infiniband -v /tmp/rdma:/tmp/rdma --net=host --privileged mellanox/tcpdump-rdma bash
3)进入容器后进行抓包,最后把pcap数据包导入到wireshark后就可以查看RoCE数据了:
[root@localhost /]# tcpdump -i mlx5_1 -s 0 -w /tmp/rdma/rdma_data1.pcap
4)打开wireshark查看数据包。
审核编辑:汤梓红
-
数据传输
+关注
关注
9文章
1872浏览量
64536 -
网卡
+关注
关注
4文章
307浏览量
27373 -
AI
+关注
关注
87文章
30643浏览量
268824 -
RDMA
+关注
关注
0文章
76浏览量
8945
原文标题:RDMA测试杂谈
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论