 如何通过DLP FPGA实现低延时高性能的深度学习处理器设计呢?
如何通过DLP FPGA实现低延时高性能的深度学习处理器设计呢?
图像识别和分析对于产品创新至关重要,但需要高工作负载,对服务质量要求严格。解决方案如GPU无法满足低延迟和高性能要求。DLP FPGA是一种可行的选择,本文将探讨如何实现这种技术。
图像识别和分析在各种产品创新中具有重要作用。然而,这些应用通常涉及高工作负载,对服务质量有严格要求。目前的解决方案,如GPU,无法同时兼顾低延迟和高性能要求。
为了在应用深度学习的同时提供良好的用户体验,可以在FPGA上架构一个超低延迟和高性能的DLP(深度学习处理器)。
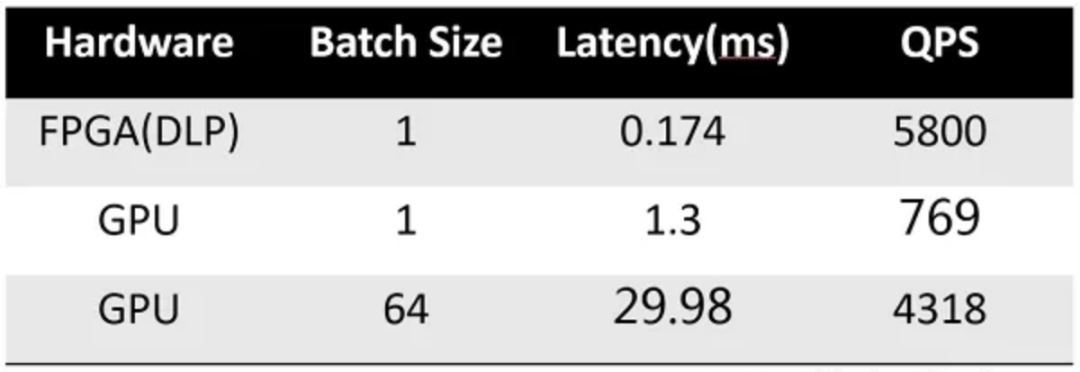
DLP FPGA可以同时支持稀疏卷积和低精度数据计算,同时定义了一个定制的ISA(指令集架构),以满足对灵活性和用户体验的要求。使用Resnet18(稀疏内核)的延迟测试结果显示,FPGA的延迟只有0.174ms。
在本文中,我们将简要讨论如何通过新的DLP FPGA实现这样的结果。
1 架构
新开发的DLP有4种模块,根据其功能进行分类:
计算:卷积、批量归一化、激活和其他计算
数据路径:数据存储、移动和重塑
参数:存储权重和其他参数,解码
指令:指令单元和全局控制
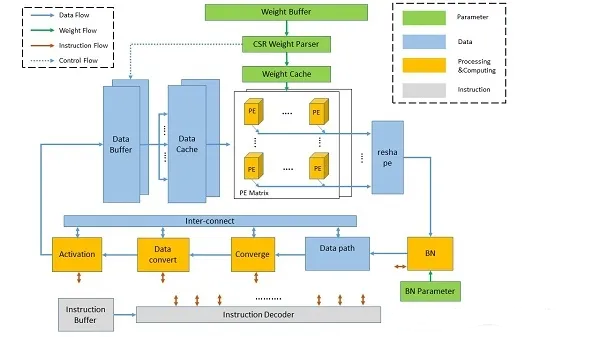
DLP中的Protocal Engine(PE)可以支持:
Int4数据类型输入。
Int32数据类型输出。
Int16量化
这种PE能提供超过90%的效率。此外,DLP的重量加载支持CSR解码器和数据预取。
2 训练
需要重新训练来开发一个高精确度的模型。下面有4个主要步骤来获得稀疏权重和低精度数据特征图。
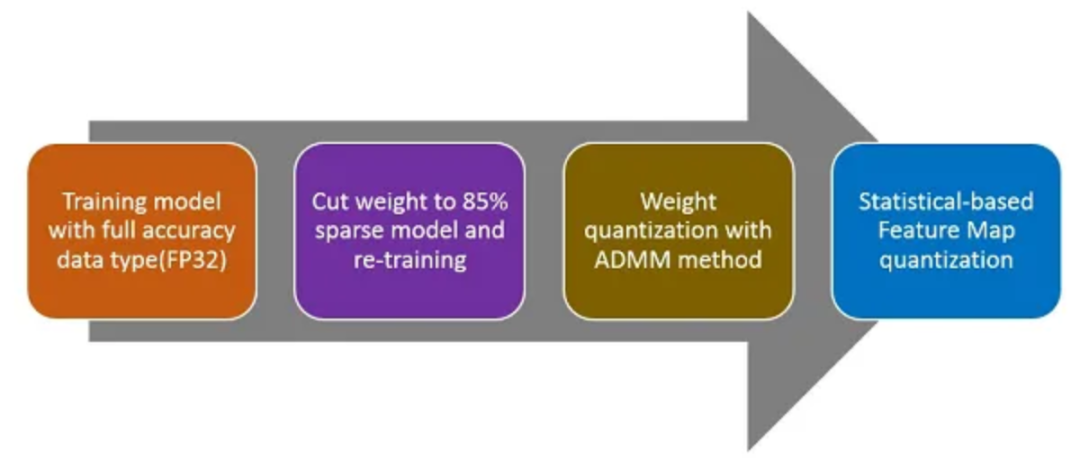
我们用一种有效的方法将Resnet18模型训练到稀疏和低精度(1707.09870)。我们方法中的关键部分是离散化。我们专注于压缩和加速深度模型,其网络权重由非常小的比特数表示,被称为极低比特神经网络。然后我们将这个问题建模为一个离散约束的优化问题。
借用乘法交替方向法(ADMM)的思想,我们将连续参数与网络的离散约束解耦,并将原来的硬问题铸成几个子问题。我们建议使用梯度外算法和迭代量化算法来解决这些子问题,与传统的优化方法相比,这些算法会导致更快的收敛。
在图像识别和物体检测方面的大量实验证明,当涉及到极低比特的神经网络时,所提出的算法比最先进的方法更有效。
3 ISA/编译器
如前所述,对于大多数在线服务和使用场景,仅有低延迟是不够的,因为算法模型会经常变化。正如我们所知,FPGA的开发周期非常长;通常需要几周或几个月的时间来完成一个定制的设计。为了解决这一挑战,我们设计了工业标准架构(ISA)和编译器,以减少模型升级的时间,使之仅为几分钟。
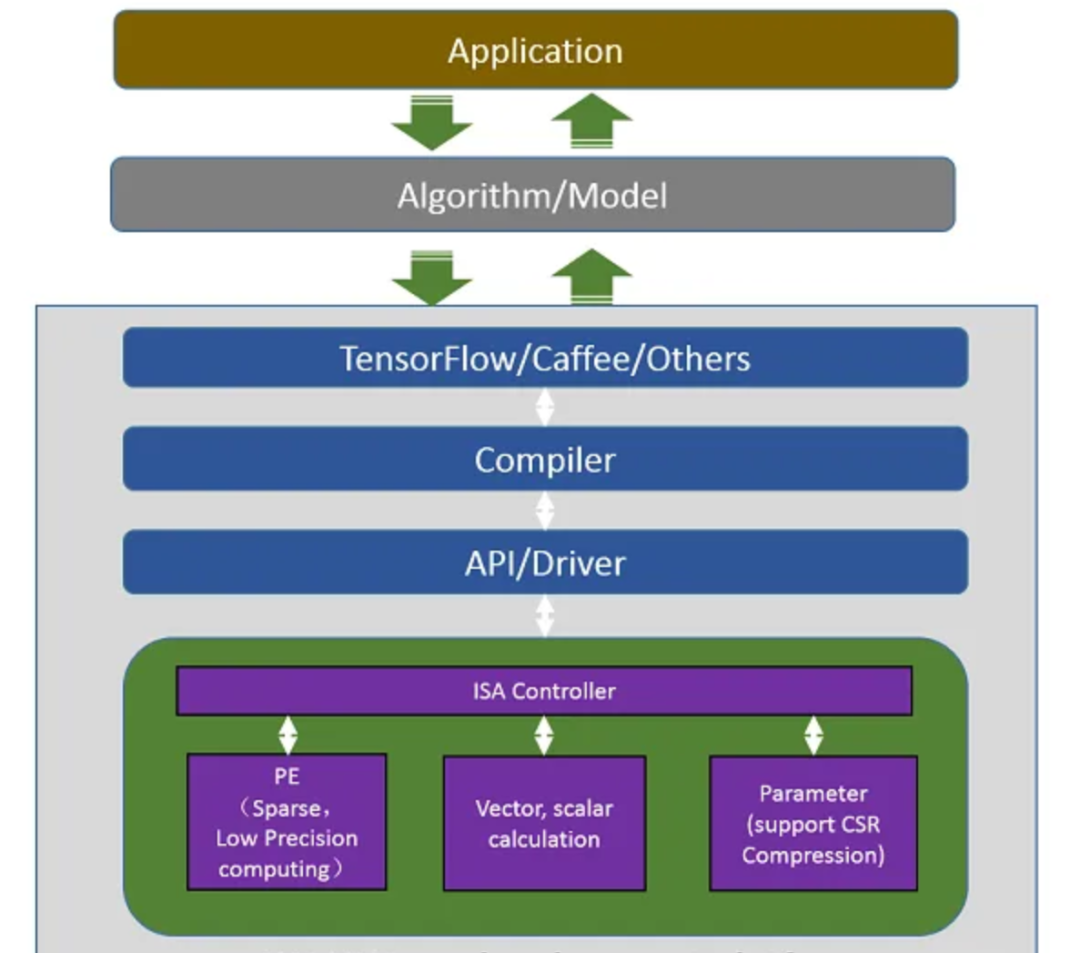
SW-HW共同开发平台由以下项目组成:
编译器:模型图分析和指令生成。
ISA控制器:指令解码、任务调度、多线程流水线管理。
4 硬件卡
DLP是在FPGA卡上实现的,它有PCIe和DDR4内存。DLP与该FPGA卡相结合,可以使在线图片搜索等应用场景更高效用户体验更好。
5 结果
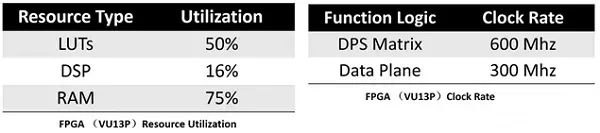
使用Resnet18的FPGA测试结果表明,我们的设计实现了超低水平的延迟,同时在低于70W的芯片功率下保持了非常高的性能。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19492浏览量
231576 -
FPGA
+关注
关注
1634文章
21818浏览量
607292 -
图像识别
+关注
关注
9文章
524浏览量
38482 -
dlp
+关注
关注
6文章
382浏览量
61412 -
深度学习
+关注
关注
73文章
5523浏览量
121737
原文标题:使用FPGA制作低延时高性能的深度学习处理器
文章出处:【微信号:FPGA研究院,微信公众号:FPGA研究院】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA做深度学习能走多远?
FPGA构建高性能DSP
【FPGA干货分享六】基于FPGA协处理器的算法加速的实现
用FPGA 嵌入式处理器实现高性能浮点元算
【详解】FPGA:深度学习的未来?
采用Sitara处理器PRU-ICSS的高性能脉冲序列输出 (PTO)
飞思卡尔高性能ColdFire微处理器简介
什么是深度学习?使用FPGA进行深度学习的好处?
FPGA是如何实现30倍速度的云加速的?
通过利用FPGA协处理器实现对汽车娱乐系统进行优化设计
在FPGA和DSP两种处理器之间实现SRIO协议的方法
中科亿海微推出高性能FPGA加速卡系列产品






 工商网监
工商网监
评论