 基于高光谱成像技术的高粱农药残留种类检测研究
基于高光谱成像技术的高粱农药残留种类检测研究
1、引言
高粱在发展中国家作为食粮作物,在田间种植过程中需要喷撒农药以减少病虫害对于产量和品质的影响。当出现严重的病虫害时,农户们会多次喷洒高浓度的农药溶液,这导致高粱中存在过量的农药残留。研究表明,长期食用农药残留超标的食物对人体危害巨大,会造成癌症、心脏病、神经性疾病等严重后果。因此,如何无损、快速、准确检测高粱中的农药残留是亟待解决的问题。现阶段农药检测方法包括气相色谱法、气相色谱-串联质谱法、高效液相色谱法等,这些方法虽然具备较高的检测准确性和精密度,但存在制样复杂、价格昂贵、检测耗时长、破坏样品和操作难度高的缺点。近些年来,研究者们已经开始利用光谱技术来检测农药残留,常用的方法有拉曼光谱检测方法、近红外光谱检测方法和高光谱成像(HSI)检测方法。其中,拉曼光谱法和近红外光谱法的检测精度和灵敏度受环境影响较大。高光谱技术相比于传统的光谱技术,可以同时获得检测样品的图像信息和光谱信息,可以实现对农药残留的准确检测。许多研究表明高光谱技术可以用于农产品农药残留种类的快速无损鉴别,但只使用单一的分类模型,没有考虑集成学习模型。本研究结合HIS技术与机器学习算法快速检测高粱中残留的农药种类,可以帮助农产品生产者和食品加工厂快速识别高粱中的农药残留种类,从而保证生产农产品的质量。
2、实验方法
2.1 样品制备
本研究所使用的高粱品种为红缨子,农药选择高粱种植过程中常用的农药种类,分别为苯醚甲环唑、马拉硫磷、氯虫苯甲酰胺、莠去津,分别表示为B、M、L、Y。4种农药分别用蒸馏水稀释400、700、700、200倍,配制实验所需的农药溶液。用4个喷壶将农药溶液均匀喷洒在4组高粱样品上,并设置一组喷洒清水(Q)样品的对照组。每组样品包含2880颗高粱籽粒,共计14400颗。将高粱样品放置于室内通风处,自然干燥12h后采集高粱样品的高光谱图像。
2.2 数据处理方法
2.2.1高光谱数据提取
采集的高光谱图像中包含高粱样品信息与背景信息,并且相邻的高粱籽粒之间存在粘连现象,因此,需要对高光谱图像进行图像处理。图像处理包括灰度变换、二值化和分水岭分割。分水岭利用图像中的梯度灰度信息,将梯度较大的区域视为山脊,将梯度较小的区域当作盆地,通过模拟水充满盆地的过程,实现高粱粘连籽粒的分割。将每颗高粱籽粒所在区域作为感兴趣区域(ROI),提取ROI内的光谱信息。
2.2.2异常光谱值的剔除
在高光谱图像采集过程中,由于环境变化、噪声以及仪器稳定性的影响,所提取的高粱籽粒光谱信息中往往会出现异常值。异常值的存在会影响后续的分析结果,因此,本研究使用IF剔除数据集中的异常数据。孤立森林由众多的孤立树构成,高光谱数据被不断地划分到每棵树的左右两个子节点,其划分的路径长度对应的数据异常得分,通过设置异常得分阈值实现异常数据的剔除。
2.2.3光谱预处理及样品划分
光谱曲线中存在由外部环境、基线变化以及采集过程中随机噪声所造成的波动。高粱籽粒在培养皿中分布不均,高粱籽粒大小不一,因此光谱曲线中也包含散射成分。光谱特征提取方法为降低高光谱数据维度,建立简洁的高粱农药残留分类模型,采用类型提升算法(CatBoost)、梯度提升树(GBDT)、竞争性自适应重加权采样法(CARS)和主成分分析法(PCA)提取高粱光谱数据中的特征波长。CatBoost和GBDT是基于决策树的集成学习方法,可以通过统计不同特征在构建模型时被选择的次数衡量特征的重要性,实现特征波长的筛选。CARS可以通过偏最小二乘(PLS)模型选择出权重大的波长点,并利用交叉验证选择出均方根误差最低的波长子集。PCA可以将代表性强且关联性强的成分,转化为代表性强而无相关性的新成分,消除光谱数据之间存在复杂的关联。
3、实验方法
3.1 图像处理与光谱提取
为提取高粱样品的光谱数据,对高光谱图像进行了图像处理。高粱原始RGB图像如图2a所示,为区分背景与高粱籽粒,对图像进行了灰度变换,改变图像的灰度值,灰度图像(图2b)中背景与高粱籽粒区分更加明显。对灰度图像进行二值化处理,可以分离背景与高粱样品,二值化图像(图2c)中的高粱籽粒之间存在粘连现象。使用分水岭算法可以获得高粱样品之间的分水岭脊线,实现对粘连的高粱籽粒的分割,分割之后的二值化图像如图2d所示。将每颗高粱对应的区域作为ROI,提取ROI每个像素点的光谱数据,对每个ROI内的光谱值求平均作为高粱农药残留籽粒的光谱信息。对于不同农药残留类别的平均光谱曲线,通过计算同类别农药残留的高粱籽粒光谱值的平均得到。


注: a: 原始图像; b: 灰度图像; c: 二值化图像; d 分割图像。
图2 高粱样品的图像处理
3.2 异常光谱值的剔除
采用IF算法剔除光谱数据中存在的异常值,消除异棒性较低,因此,本研究使用了PCA降低高光谱数据的维度,通过原始数据标准化、求解相关系数矩阵、计算矩阵特征值、计算特征向量、变换标准化后的向量为主成分以及主成分贡献率计算,计算高粱农药残留样品光谱数据前3个成分的累计贡献率
表1样品PCA累计贡献率(%)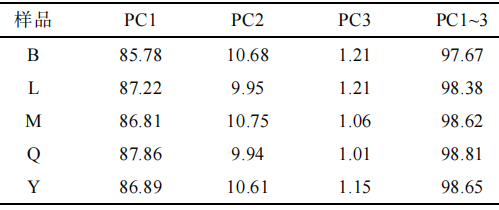
如表1所示,B、L、M、Q、Y的累计贡献率分别为97.67%、98.38%、98.62%、98.81%、98.65%。5种样品的累计贡献率均超过97.5%,这说明前3个成分对应的主成分得分矩阵可以很好地代表高粱样品的光谱数据,因此,将前3个成分带入IF算法中剔除异常值。以B和M为例,图3中黑点为正常值,呈簇状集中分布,红点为异常值,离散分布在正常值的四周。
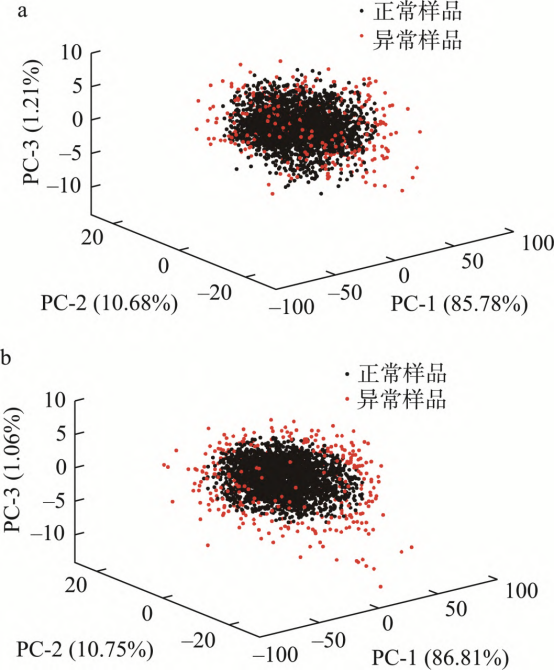
注: a: B 类高粱样品; b: M 类高粱样品
图3 异常数据可视化
3.3 光谱特征分析
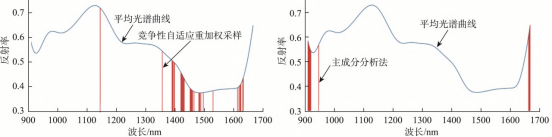
为显示不同种类农药残留高粱样品光谱曲线的差异,计算每类高粱样品的光谱曲线的平均值得到平均光谱曲线,如图4所示。
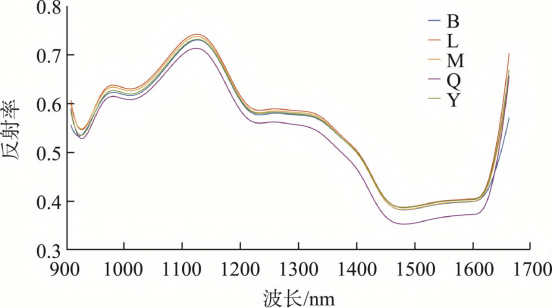
图 4 高粱农药残留样品平均光谱曲线
由图4中可以看出,在近红外波段范围内,光谱曲线出现3处较为明显的吸收峰,分别位于925、1230、1470nm左右。925nm位置处的吸收峰与O-H的第一拉伸泛频有关,1230nm位置处的吸收峰与C-H的第二拉伸泛频有关,1470nm位置处的吸收峰与N-H的第一拉伸泛频有关。在近红外波段范围内,各类农药残留高粱样品的光谱反射率不同,但总体变化趋势相似。无农药残留高粱样品的反射率最低,与不同类型农药残留样品的光谱曲线差异最明显。此外,B与Y的平均光谱反射率非常接近,L的平均光谱反射率最高。在1000~1100nm范围内,各类高粱样品的反射率差距最大,由高到低分别是L、M、Y、B、Q。这些平均光谱的差异为鉴别高粱样品农药残留种类提供了依据。
3.4 光谱数据的预处理
高粱农药残留样品的光谱曲线在900nm和1700nm处出现了异常波动,这说明这两个位置处的光谱数据受到的干扰较大,数据存在严重失真的情况。为消除数据失真对后期建模分类效果的影响,本研究截去了光谱数据开始处前15个和末尾处后41个波段信息,保留456个波段用于建模分析。利用SG、DWT、SNV预处理方法对高粱农药残留样品的光谱数据进行预处理。建立预处理光谱数据的SVM农药残留分类模型识别农药残留种类,识别结果如表2所示。
表2****光谱数据预处理后的建模效果(%)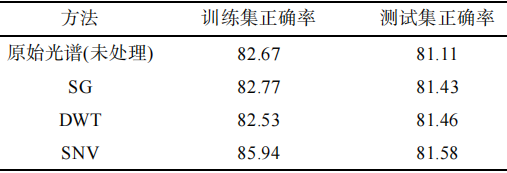
结果显示,使用SNV预处理的光谱数据建立的分类模型识别效果最好,训练正确率和测试集正确率分别为85.94%和81.58%。这可能是SNV预处理可以同时减少噪声和散射成分对光谱数据的影响。因此,将SNV预处理后的光谱数据用于后续的研究分析中。原始光谱曲线如图5a所示,SNV预处理之后的高粱农药残留样品光谱曲线如图5b所示。
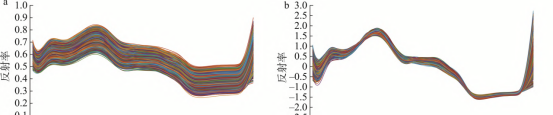
注: a: 原始光谱曲线; b: SNV 预处理后的光谱曲线
图5 高粱农药残留样品光谱曲线
3.5 特征光谱提取
虽然全波段内的光谱数据可以用于识别高粱样品农药残留的类别,但数据中包含的冗余信息会降低模型的运算速度和识别精度。为消除光谱数据中冗余信息,提升高粱农药残留识别模型的识别精度,需要选择具有代表性的波长。本研究使用了CatBoost、GBDT、CARS、PCA特征选择方法,CatBoost和GBDT通过设置特征重要性得分阈值(0.2)选择特征波长,PCA通过设置载荷系数阈值(0.1)选择特征波长,CARS选择建立最小交叉验证均方根误差(RMSECV)值PLS模型的波长为特征波长,分别选择了132、147、35、12个特征波长。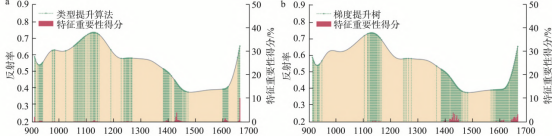
注: a: CatBoost; b: GBDT; c: CARS; d: PCA
图 6 特征波长分布位置
图6为特征波长的具体位置分布图,在图6a和图6b中,绿色线条代表特征波长的具体位置,红色线条代表所选择特征波长对应的特征重要性得分,特征波长大致分布在900、1100、1400、1650nm范围内。其中,CatBoost提取的最大贡献率波长分布在1600nm左右,特征重要性得分为10.23%,GBDT提取的最大贡献率波长分布在1400nm左右,特征重要性得分为4.11%。在图6c和图6d中,红色线条代表特征波长的具体位置。
表****3 特征方法的建模结果(%)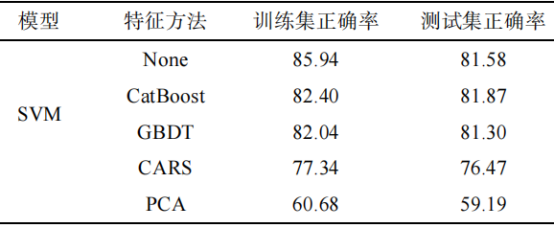
表3为不同特征选择方法筛选的特征波长建立的分类模型结果。全波长模型测试集分类正确率为81.58%,CatBoost-SVM模型测试集分类正确率为81.87%,GBDTSVM模型测试集分类正确率为81.30%,CARS-SVM模型测确率为59.19%。特征波长选择方法效果由高到低分别是CatBoost、GBDT、CARS、PCA,使用CARS和PCA选择的特征波长所建立模型的分类正确率有所下降,这可能是在特征波长的选择过程中,减少冗余信息的同时,也删除了对建立农药残留分类模型有贡献的光谱数据。研究表明,CatBoost选择的特征波长不仅可以减少模型的训练时间,还能提高模型的分类正确率,因此,使用CatBoost选择的光谱数据用于后续分析。
4、结论
高光谱成像技术作为一种新兴的食品检测技术,已经广泛应用于农药残留种类的快速检测。本研究结合高光谱成像技术与BP-Adaboost集成学习模型,与此前的相关研究相比,在多个方面取得了显著的进展,相比于姜荣昌等对于大白菜农药残留种类的研究,在单类农药残留样品和无农药残留样品识别正确率方面都有着较大的提升。相比于沈兵兵等对于花椰菜中农药残留的研究在识别更多农药残留种类的情况下,也得到了良好的分类正确率。与HU等结合1D-CNN与高光谱成像技术识别哈密瓜表面的农药残留种类相比,使用了CatBoost特征选择方法,降低了模型的训练时间。本研究利用F算法剔除了高梁光谱数据集中的异常值,减少了异常样品对干建模结果的影响;使用SNV预处理方法对光谱数据进行预处理,减少了噪声和散射成分对于光谱信息的干扰:在特征波长选择方面,使用CatBoost特征选择方法,通过计算波长的特征重要性选择特征波长,降低了几余信息对于分类结果的影响,加快了模型的训练速度,特征波长建模效果优于PCA、CARS和GBDT选择的特征波长,最重要的是使用BP-Adaboost集成学习模型,结合BPNN与AdaBoost方法,对多个弱分类器的结果进行集成,提高了模型的分类下确率,成功地识别出4组不同农药残留的高梁样品和一组无农药残留的高梁样品,其中B和Q的分类正确率均为99.80%,与XGBoost、LGBM、SVM模型相比分别高出了12.66%、13.47%、13.30%,充分体现出集成学习模型的优势。综上所述,本研究提出了一种新高梁农药残留识别方法,融合高光谱成像技术、CatBoost特征选择方法和BP-Adaboost集成学习模型,成功的实现了高梁农药残留的快速、无损识别,模型训练集平均分类正确率为95.68%,模型测试集平均分类正确率为95.17%,为农产品中的农药残留种类提供了一种高效、准确的分类解决方案。
审核编辑 黄宇
-
成像技术
+关注
关注
4文章
290浏览量
31456 -
检测
+关注
关注
5文章
4484浏览量
91445 -
高光谱
+关注
关注
0文章
330浏览量
9934
发布评论请先 登录
相关推荐

高光谱成像技术鉴别菠菜叶片农药残留种类
高光谱成像技术有哪些显著的优势?




高光谱成像技术在肤检测、植被遥感与环境检测中的应用





 工商网监
工商网监
评论