 SegRefiner:通过扩散模型实现高精度图像分割
SegRefiner:通过扩散模型实现高精度图像分割
背景介绍
尽管图像分割在过去得到了广泛研究和快速发展,但获得细节上非常准确的分割 mask 始终十分具有挑战性。因为达成高精度的分割既需要高级语义信息,也需要细粒度的纹理信息,这将导致较大的计算复杂性和内存使用。而对于分辨率达到2K甚至更高的图像,这一挑战尤为突出。
由于直接预测高质量分割 mask 具有挑战性,因此一些研究开始集中于 refine 已有分割模型输出的粗糙 mask。为了实现高精度的图像分割,来自北京交大、南洋理工、字节跳动等的研究者们引入了一种基于扩散模型Diffusion去逐步提高mask质量的方法。
现有方法
Model-Specific
一类常见的 Refinement 方法是 Model-Specific 的,其通过在已有分割模型中引入一些新模块,从而为预测 Mask 补充了更多额外信息,从而增强了已有模型对于细节的感知能力。这一类方法中代表性的工作有 PointRend,RefineMask,MaskTransfiner等。然而,这些方法是基于特定模型的改进,因此不能直接用于 refine 其他分割模型输出的粗糙 mask。
Model-Agnostic
另一类 Refinement 方法是 Model-Agnostic 的,其只使用原始图像和粗糙mask作为输入信息,如 BPR,SegFix,CascadePSP,CRM 等。由于这类方法在 Refinement 过程中未使用已有模型的中间特征,因此不依赖于特定分割模型,可以用于不同分割模型的 Refinement。然而,尽管这类方法能够有效地提升分割准确度,但由于粗糙 mask 中存在多种多样的错误预测(如下图所示),导致模型无法稳定地修正粗糙 mask 中的全部预测错误。

实现目标
相比于 Model-Specific 的方法,Model-Agnostic 的方法能够直接应用于不同分割模型的 Refinement,从而有着更高的实用价值。更进一步地,由于不同分割任务(语义分割,实例分割等)的结果都可以被表示为一系列 binary mask,具有相同的表征形式,在同一个模型中统一实现不同分割任务的 Refinement 同样是可能的。因此,我们希望实现能够应用于不同分割模型和分割任务的通用 Refinement 模型。
如前所述,已有分割模型产生的错误预测是多种多样的,而想要通过一个通用模型一次性地更正这些多样性的错误十分困难。面对这一问题,在图像生成任务中取得巨大成功的扩散概率模型给予了我们启发:扩散概率模型的迭代策略使得模型可以在每一个时间步中仅仅消除一部分噪声,并通过多步迭代来不断接近真实图像的分布。这大大降低了一次性拟合出目标数据分布的难度,从而赋予了扩散模型生成高质量图像的能力。
直观地,如果将扩散概率模型的策略迁移到 Refinement 任务中,可以使得模型在进行 Refinement 时每一步仅关注一些“最明显的错误”,这将降低一次性修正所有错误预测的难度,并可以通过不断迭代来逐渐接近精细分割结果,从而使得模型能够应对更具挑战性的实例并持续纠正错误,产生精确分割结果。
在这一想法下,我们提出了一个新的视角:将粗糙 mask 视作 ground truth 的带噪版本,并通过一个去噪扩散过程来实现粗糙 mask 的 Refinement,从而将 Refinement 任务表示为一个以图像为条件,目标为精细 mask 的数据生成过程。
算法方案
扩散概率模型是一种由前向和反向过程表示的生成模型,其中前向过程通过不断加入高斯噪声得到不同程度的带噪图像,并训练模型预测噪声;而反向过程则从纯高斯噪声开始逐步迭代去噪,最终采样出图像。而将扩散概率模型迁移到 Refinement 任务中,数据形式的不同带来了以下两个问题:
(1) 由于自然图像往往被视作高维高斯变量,将图像生成的过程建模为一系列高斯过程是十分自然的,因此已有的扩散概率模型大多基于高斯假设建立;而我们的目标数据是 binary mask,通过高斯过程拟合这样一个离散变量的分布并不合理。
(2) 作为一种分割 Refinement 方法,我们的核心思想是将粗糙 mask 视为带有噪声的 ground truth,并通过消除这种噪声来恢复高质量的分割结果。这意味着我们扩散过程的结尾应当收敛到确定性的粗糙 mask(而非纯噪声),这也与已有的扩散概率模型不同。
针对上述问题,我们建立了如下图所示的基于“随机状态转移”的离散扩散过程。其中,前向过程将 ground truth 转换为“不同粗糙程度”的 mask,并用于训练;而反向过程用于模型推理,SegRefiner 从给出的粗糙 mask 开始,通过逐步迭代修正粗糙 mask 中的错误预测区域。以下将详细介绍前向和反向过程。
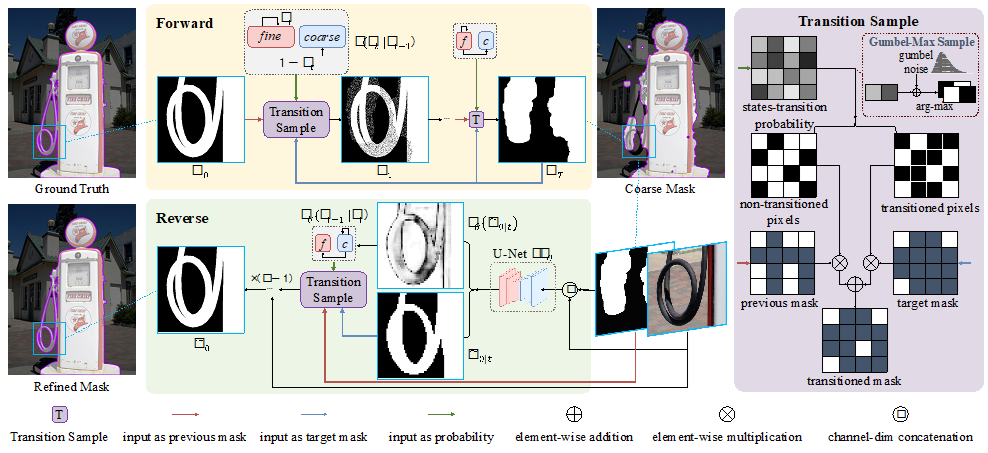
前向过程
前向过程的目标是将 ground truth 提供的精细 mask 逐步消融为粗糙的 mask,记前向过程每一步的变量为  ,则前向过程应当满足:
,则前向过程应当满足:
(1)  为 ground truth
为 ground truth
(2)  为粗糙 mask
为粗糙 mask
(3) 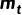 介于和之间,随 t 增大逐渐向粗糙 mask 演变
介于和之间,随 t 增大逐渐向粗糙 mask 演变
基于这些限制条件,我们用随机状态转移来表述前向过程:假设变量中的每一个像素都有两种可能的状态:精细和粗糙,处于精细状态的像素值与保持一致,处于粗糙状态的像素则取 的值(即使二者一致)。我们提出了一个“转移采样”模块来进行这一过程,如上图右侧所示。在每一个时间步,其以当前 mask ,粗糙 mask 以及状态转移概率作为输入。
在前向过程中,状态转移概率描述了当前 mask 中每个像素转移到中的状态的概率。根据状态转移概率进行采样,可以得到后一个时间步 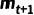 每个像素的状态,从而确定其取值。这一模块确定了一个“单向”过程,即只会发生“转移到目标状态”的情况。这一单向性质确保了前向过程会收敛到(尽管每一步都是完全随机的),从而满足了上述限制 条件(2),(3)。
每个像素的状态,从而确定其取值。这一模块确定了一个“单向”过程,即只会发生“转移到目标状态”的情况。这一单向性质确保了前向过程会收敛到(尽管每一步都是完全随机的),从而满足了上述限制 条件(2),(3)。
通过重参数技巧,我们引入了一个二元随机变量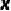 来描述上述过程:我们将
来描述上述过程:我们将 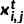 表示为一个 one-hot 向量,用来表示中间掩模 中像素
表示为一个 one-hot 向量,用来表示中间掩模 中像素 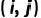 的状态,同时设置
的状态,同时设置 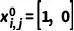 和
和 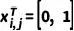 来表示精细状态和粗糙状态。因此,前向过程可以被表示为:
来表示精细状态和粗糙状态。因此,前向过程可以被表示为:
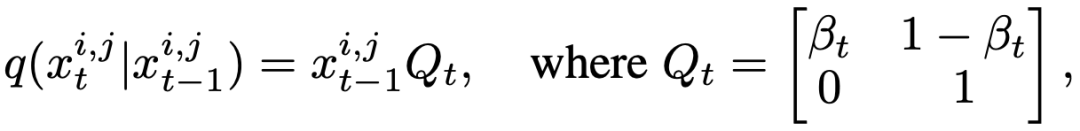
其中 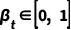 为超参数,而
为超参数,而 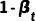 对应了上述的状态转移概率,
对应了上述的状态转移概率,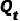 是状态转移矩阵。则前向过程的边缘分布可以表示为:
是状态转移矩阵。则前向过程的边缘分布可以表示为:
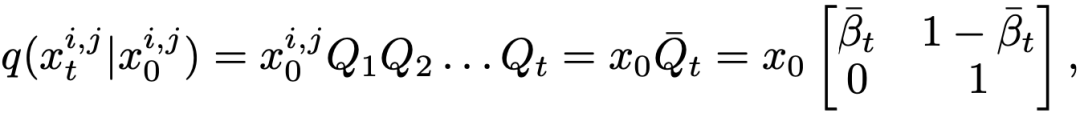
其中 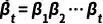 。从而我们可以直接获取任何中间时间步
。从而我们可以直接获取任何中间时间步 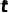 的 mask 并用于训练,而无需逐步采样
的 mask 并用于训练,而无需逐步采样 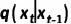 。
。
反向过程
反向扩散过程用于模型推理,目标是将粗糙 mask 逐渐修正为精细 mask 。由于此时精细 mask 和状态转移概率未知,类似 DDPM 的做法,我们训练一个神经网络 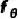 ,来预测精细 mask
,来预测精细 mask 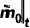 ,表示为:
,表示为:
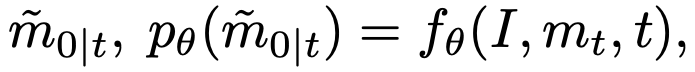
其中  是相应的图像。
是相应的图像。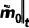 和
和 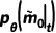 分别表示预测的精细 mask 和其置信度分数。这里表示了网络对于预测准确与否的置信度,故同样可以被视作中每个像素处于“精细状态”的概率。为了获得反向状态转移概率,根据前向过程的设定和贝叶斯定理,延续 DDPM 的做法,我们可以由前向过程的后验概率和预测的得到反向过程的概率分布,为:
分别表示预测的精细 mask 和其置信度分数。这里表示了网络对于预测准确与否的置信度,故同样可以被视作中每个像素处于“精细状态”的概率。为了获得反向状态转移概率,根据前向过程的设定和贝叶斯定理,延续 DDPM 的做法,我们可以由前向过程的后验概率和预测的得到反向过程的概率分布,为:
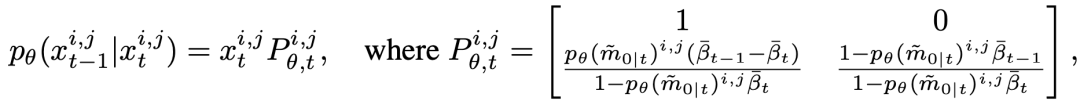
其中 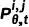 为反向过程的状态转移概率。给定粗糙 mask 以及相应的图像,我们首先将所有像素初始化为粗糙状态
为反向过程的状态转移概率。给定粗糙 mask 以及相应的图像,我们首先将所有像素初始化为粗糙状态 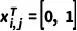 ,然后通过不断迭代地状态转移,逐渐修正 中预测值。下图为一个推理过程的可视化展示。
,然后通过不断迭代地状态转移,逐渐修正 中预测值。下图为一个推理过程的可视化展示。

模型结构
任意满足  形式的网络均可满足我们的要求,这里我们延续了之前工作的做法,采用 U-Net 作为我们的去噪网络,将其输入通道数修改为4(图像和 在通道维度上串联),并输出1通道的改进掩模。
形式的网络均可满足我们的要求,这里我们延续了之前工作的做法,采用 U-Net 作为我们的去噪网络,将其输入通道数修改为4(图像和 在通道维度上串联),并输出1通道的改进掩模。
算法评估
由于 Refinement 任务的核心是获取细节精确的分割结果,在实验中我们选取了三个代表性的高质量分割数据集,分别对应Semantic Segmentation,Instance Segmentation 和 Dichotomous Image Segmentation。
Semantic Segmentation
如表1所示,我们在 BIG 数据集上将提出的 SegRefiner 与四种已有方法:SegFix,CascadePSP,CRM 以及 MGMatting 进行了对比。其中前三个为语义分割的 Refinement 方法,而 MGMatting 使用图像和 mask 进行 Matting 任务,也可以用于 Refinement 任务。结果表明,我们提出的 SegRefiner 在 refine 四个不同语义分割模型的粗糙 mask 时,都在 IoU 和 mBA 两项指标上获得了明显提升,且超越了之前的方法。

Instance Segmentation
实例分割中,我们选择了之前的工作广泛使用的 COCO 数据集进行测试,并使用了 LVIS 数据集的标注。与原始 COCO 标注相比,LVIS 标注提供了更高质量和更详细的结构,这使得 LVIS 标注更适合评估改进模型的性能。
首先,在表2中,我们将提出的SegRefiner与两种 Model-Agnostic 的实例分割 Refinement 方法 BPR 和 SegFix 进行了比较。结果表明我们的 SegRefiner 在性能上明显优于这两种方法。
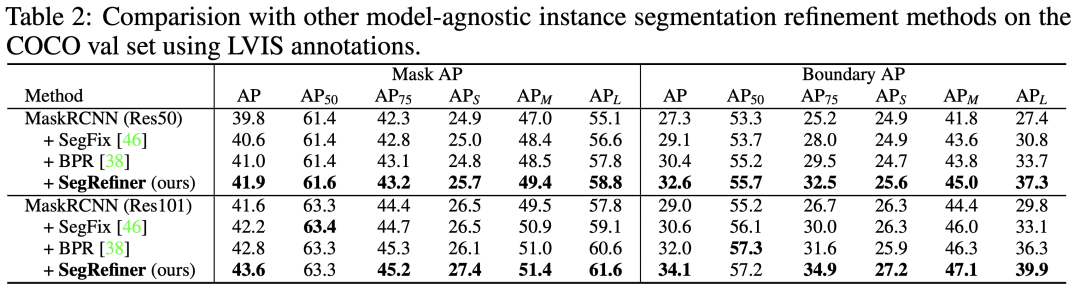
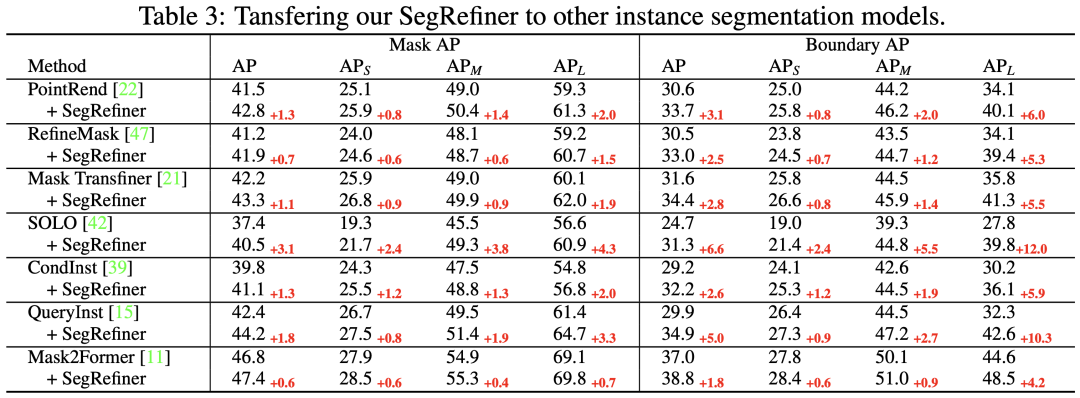
然后在表3中,我们将 SegRefiner 应用于其他7种实例分割模型。我们的方法在不同准确度水平的模型上都取得了显著的增强效果。值得注意的是,当应用于三种 Model-Specific 的实例分割 Refinement 模型(包括PointRend、RefineMask 和 Mask TransFiner)时,SegRefiner 依然能稳定提升它们的性能,这说明 SegRefiner 具有更强大的细节感知能力。
Dichotomous Image Segmentation
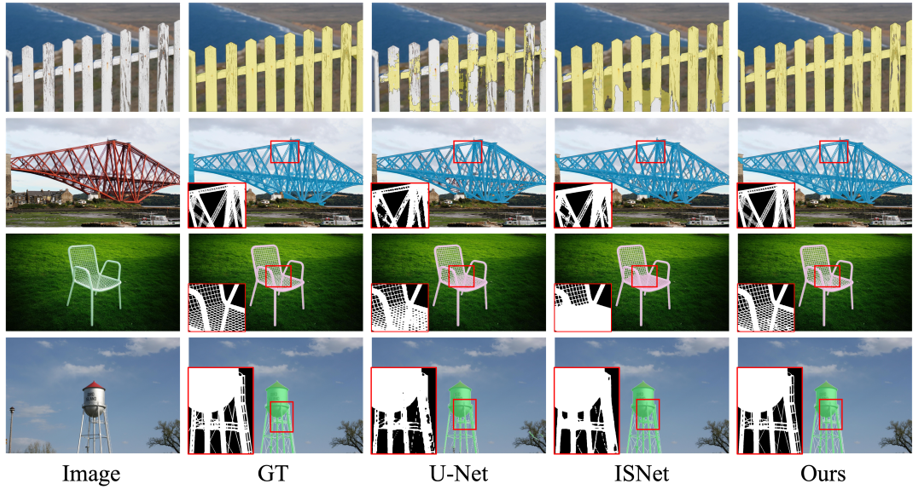
Dichotomous Image Segmentation 是一个较新提出的任务,如下图所示,其数据集包含大量具有复杂细节结构的对象,因此十分适合评估我们 SegRefiner 对细节的感知能力。

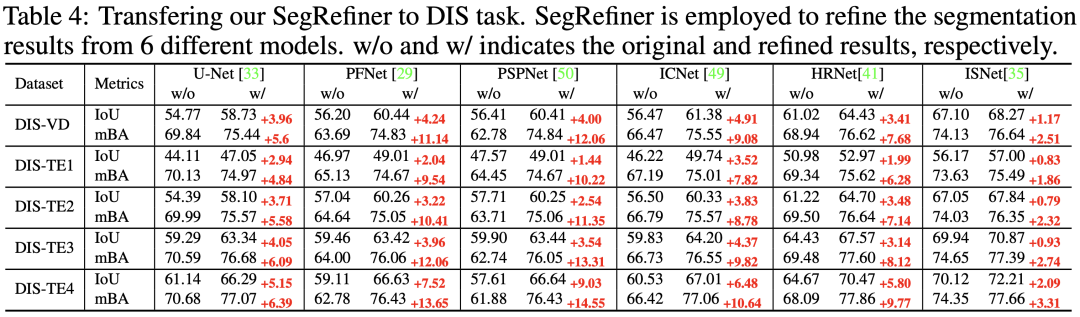
在本实验中,我们将 SegRefiner 应用于6种分割模型,结果如表4所示。可以看到,我们的SegRefiner在 IoU 和 mBA 两项指标上都明显提升了每个分割模型的准确度。
可视化展示

审核编辑:刘清
-
神经网络
+关注
关注
42文章
4774浏览量
100912 -
CRM
+关注
关注
1文章
145浏览量
21138 -
图像分割
+关注
关注
4文章
182浏览量
18020 -
高斯噪声
+关注
关注
0文章
11浏览量
8377
原文标题:NeruIPS 2023 | SegRefiner:通过扩散模型实现高精度图像分割
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于扩散模型的图像生成过程

如何在PyTorch中使用扩散模型生成图像

基于多级混合模型的图像分割方法
基于图像局部灰度差异的噪声图像分割模型
基于SEGNET模型的图像语义分割方法
一种高精度的肝脏图像自动分割算法
近期分割大模型发展情况






 工商网监
工商网监
评论