 1-2B参数规模大模型的使用心得
1-2B参数规模大模型的使用心得

来自:刘聪NLP
写在前面
大模型时代,根据大模型缩放定律,大家通常都在追求模型的参数规模更大、训练的数据更多,从而使得大模型涌现出更多的智能。但是,模型参数越大部署压力就越大。即使有gptq、fastllm、vllm等推理加速方法,但如果GPU资源不够也很难保证高并发。
那么如何在模型变小的同时,模型效果不明显下降,在指定任务上也可以媲美大模型的效果呢?
Google前几天发布的Gemini,在移动端采用1.8B参数模型面向低端手机,3.25B参数模型面向高端手机。
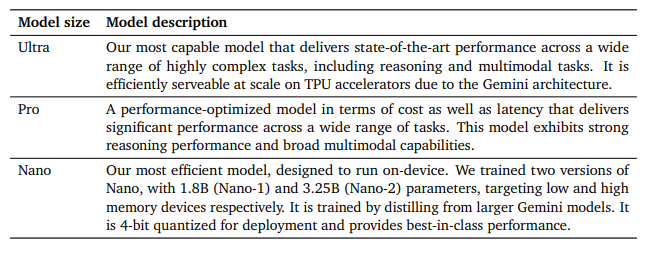
An overview of the Gemini 1.0 model family
而微软最近也是推出了2.7B的Phi-2模型,评测效果绝群。
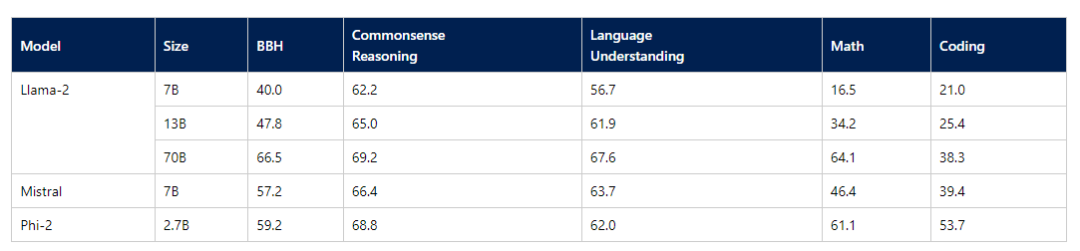
Averaged performance on grouped benchmarks compared to popular open-source SLMs

Comparison between Phi-2 and Gemini Nano 2 Model on Gemini’s reported benchmarks
恰好笔者前段时间也在研究1-2B参数量左右的模型,因此写写心得体会;并汇总了一下现在市面上开源的1-2B参数量的大模型。
这波反向操作,佛曰:不可说。
如何使大模型变小
模型压缩的方法包括:用更多的数据硬训练小模型、通过大模型对小模型进行蒸馏、通过大模型对小模型进行剪枝、对大模型进行量化、对大模型进行低秩分解。
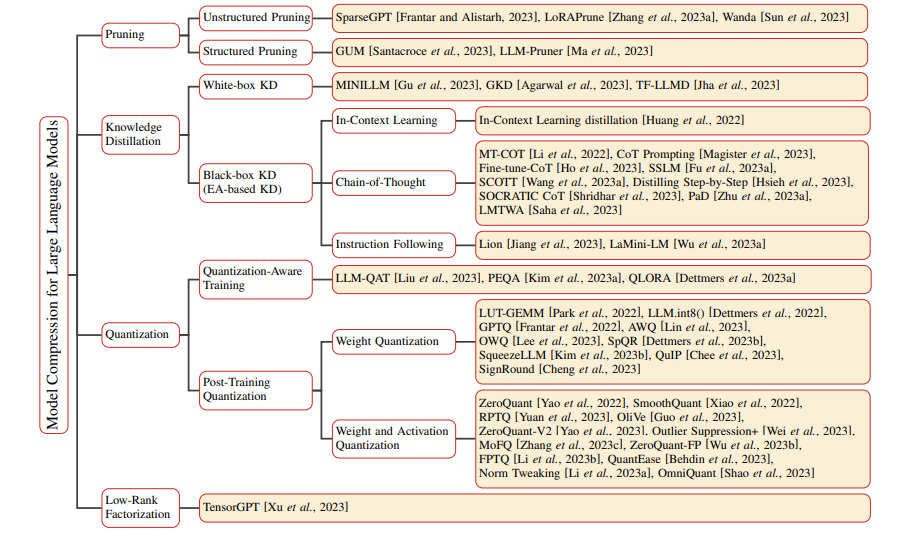
Taxonomy of Model Compression methods for Large Language Models
但是模型参数量变小还是硬训练或蒸馏一个参数量小的模型,剪枝和量化只是对模型进行推理加速,本质上参数量没有变少。
对于预训练阶段来说,往往需要更多的数据硬训练。参数规模不够,只能数据质量和数据数量来凑。

Textbooks Are All You Need
而在指令微调阶段,往往是蒸馏更优秀的大模型,来让小模型效果更好。利用GPT3.5、GPT4的数据直接指令微调是对闭源大模型蒸馏的方法之一,也是目前大家主流的做法。但也可以在蒸馏过程中,利用闭源大模型充当一个裁判来判别教师模型回答和学生模型回答的差异,让学生模型向老师模型(闭源)进行反馈,重点是找到困难数据让学生模型进行更好的学习。
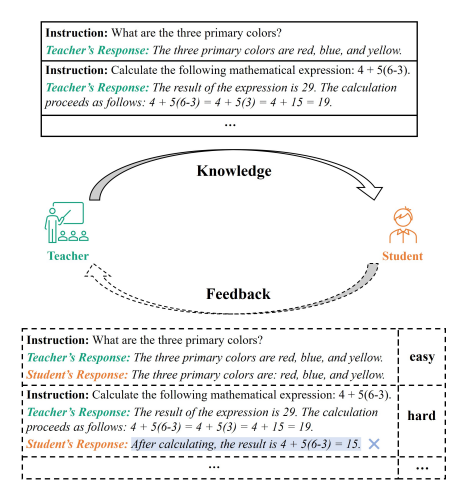
Lion: Adversarial Distillation of Proprietary Large Language Models
当然如果你本身拥有更大更好的大模型,那么就可以用标准的知识蒸馏来进行模型蒸馏,利用KL散度,对教师模型和学生模型输出概率分布之间的差异进行训练学习。
将更大模型的效果蒸馏到小模型上,会比硬训练的效果要理想,但首先要有一个可获取网络各层logits的大&好&强的模型。
训练1-2B参数规模使我痛并快乐
训练1-2B模型让我又找到了全量调参的快乐,之前受显卡限制,都是Lora、QLora等方法训练。
模型部署阶段,再也不用为显存发愁,老卡也轻轻松松进行模型部署。对于2B模型,Float32进行参数部署也就8G、Float16就需要4G,如果再做量化的话更小,甚至CPU部署速度也可以接受。
同等数据情况下,效果确实不如更大的模型。以Qwen1.8B和7B为例,在自己任务上指标差了7-10个点。
在个人任务上,通过增加数据,将训练数据扩大2-4倍并提高数据质量之后,效果基本上可以媲美。
小模型在没有定制优化的任务上,就一言难尽了,泛化能力等都远不如更大的模型。
用了小模型之后,再也没被吐槽过速度了。
主流1-2B参数规模的大模型汇总
共整理了14个1-2B参数规模的大模型,按照参数量从大到小排序,如下所示。
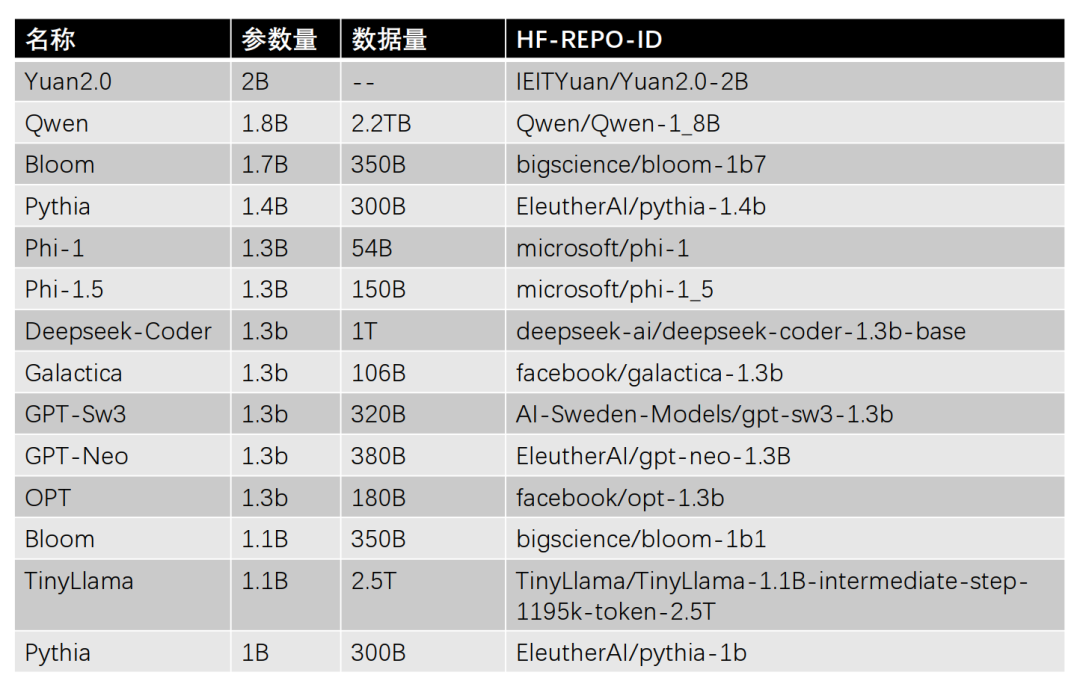
PS: HF访问不了的小伙伴,可以看一下《大模型下载使我痛苦》。
Yuan2.0-2B
Yuan2.0-2B是浪潮发布的Yuan2.0大模型的2B版本,采用中英文的高质量资料,包括书籍、百科、论文等。Yuan2.0-2B模型层数24层,隐藏层维度2048,支持最大长度8192。
Qwen-1.8B
Qwen-1.8B是阿里发布的Qwen大模型的1.8B版本,采用2.2TB Token的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。Yuan2.0-2B模型层数24层,隐藏层维度2048,支持最大长度8192,并且开源了对应的Chat模型。
Bloom-1.7B&1.1B
Bloom-1.7B&1.1B是Hugging Face牵头组织的BigScience项目开源的Bloom大模型的1.7B和1.1B版本。训练数据涉及46种自然语言和13种编程语言,共计1.6TB的文本数据。Bloom-1.7B模型层数24层,隐藏层维度2048,支持最大长度2048。Bloom-1.1B模型层数24层,隐藏层维度1536,支持最大长度2048。
Pythia-1.4B&1B
Pythia-1.4B&1B是EleutherAI开源的Pythia的1.4B和1B版本。主要使用300B Token的The Pile数据集进行训练。Pythia-1.4B模型层数24层,隐藏层维度2048。Pythia-1B模型层数16层,隐藏层维度2048。
Phi-1&Phi-1.5
Phi-1&Phi-1.5是微软开源的Phi大模型的两个不同版本,均有1.3B参数,模型层数24层,隐藏层维度2048。Phi-1模型训练54B Token的数据,而Phi-1.5模型训练150B Token的数据。
Deepseek-Coder-1.3B
Deepseek-Coder-1.3B是深度求索发布开源的Deepseek-Coder的1.3B版本,采用1TB Token的数据进行预训练,数据由87%的代码和13%的中英文自然语言组成,模型层数24层,隐藏层维度2048。
Galactica-1.3b是MetaAI开源的Galactica大模型的1.3B版本,采用106B Token数据进行训练,数据主要来自论文、参考资料、百科全书和其他科学来源等。模型层数24层,隐藏层维度2048。
GPT-Sw3-1.3B
GPT-Sw3-1.3B是AI Sweden开源的GPT-SW3大模型的1.3B版本,采用320B Token数据进行训练,数据主要由瑞典语、挪威语、丹麦语、冰岛语、英语和编程代码数据集组成。模型层数24层,隐藏层维度2048。
GPT-Neo-1.3B
GPT-Neo-1.3B是EleutherAI开源的GPT-Neo大模型的1.3B版本,GPT-Neo模型主要为了复现的GPT-3模型,采用380B Token数据进行训练,模型层数24层,隐藏层维度2048。
OPT-1.3B
OPT-1.3B模型是由MetaAI开源的OPT大模型的1.3B版本,采用180B Token数据进行训练,模型层数24层,隐藏层维度2048。
TinyLlama-1.1B
TinyLlama模型是一个1.1B参数的Llama模型,旨在3TB Token的数据上进行训练,目前训练到2.5TB Token数据,模型层数22层,隐藏层维度2048。
写到最后
如果领导非要部署大模型,但对效果要求没有那么高,又没有资源支持,那么选择一个1-2B的模型也是不错的呦。
审核编辑:汤梓红
-
手机
+关注
关注
36文章
7006浏览量
161254 -
gpu
+关注
关注
28文章
5313浏览量
136169 -
参数
+关注
关注
11文章
1870浏览量
34060 -
开源
+关注
关注
3文章
4414浏览量
46558 -
大模型
+关注
关注
2文章
3854浏览量
5289
原文标题:1-2B参数规模大模型使用心得及模型汇总
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【MATLAB使用心得汇总——Tips6 】
NE555关于计数器的使用心得
TFT LCD使用心得
详细谈谈TFT LCD 的使用心得
CAD使用心得之五:图层控制、视图调整、图形选择
无线蓝牙模块CC2540使用心得
内核调试利器printk的使用心得

Aultium Designer 的使用心得和基本电路图的搭建

智慧服装工厂电子看板试用心得
HT for Web (Hightopo) 使用心得(5)- 动画的实现




评论