 带分区的大规模LDAP介绍
带分区的大规模LDAP介绍
介绍
LDAP是一个常见的目录信息源;该协议的第一个版本是在1993年编纂的。它通常用于各种应用,包括管理Linux实例的用户/组信息,以及控制VPN和传统应用的认证。
传统上,公司的LDAP服务器是在内部运行的;通常是微软的ActiveDirectory的一部分,或者是开放源码OpenLDAP项目的一个部署。现在,SaaS供应商可以提供LDAP支持;包括Foxpass,它是第一个从头开始建立一个多用户、以云为中心的LDAP实施的云LDAP供应商。
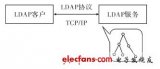
简单介绍一下:LDAP通常有以下基元:绑定、搜索、比较和添加。在创建一个TCP连接后,应用程序首先需要通过发送一个用户名和密码进行绑定。一旦绑定成功,客户端将向LDAP服务器发出命令;通常是与过滤器一起的搜索命令。TCP连接一直保持到客户端或服务器断开连接。
Foxpass的LDAP
在Foxpass,我们的LDAP服务是在Twisted之上编写的,Twisted是一种流行的基于事件的Python服务框架。该服务托管在 AWS的ECS平台上,运行在数十个容器(节点)上。由于 LDAP连接是持久的,因此集群必须能够同时维护数十万个TCP会话。
我们将客户的数据保存在RAM中。这样做的原因是多方面的。首先,数据集相对较小,即使对于大客户也是如此。其次,LDAP查询语言允许搜索任意字段(这很重要,因为Foxpass允许自定义字段)。这意味着传统的 RDBMS系统将无法构建有效的索引,我们必须将数据转换为不同的内存表示形式。第三,将数据保存在 RAM中可以实现最快的响应时间:延迟通常在100毫秒左右(见图a)。
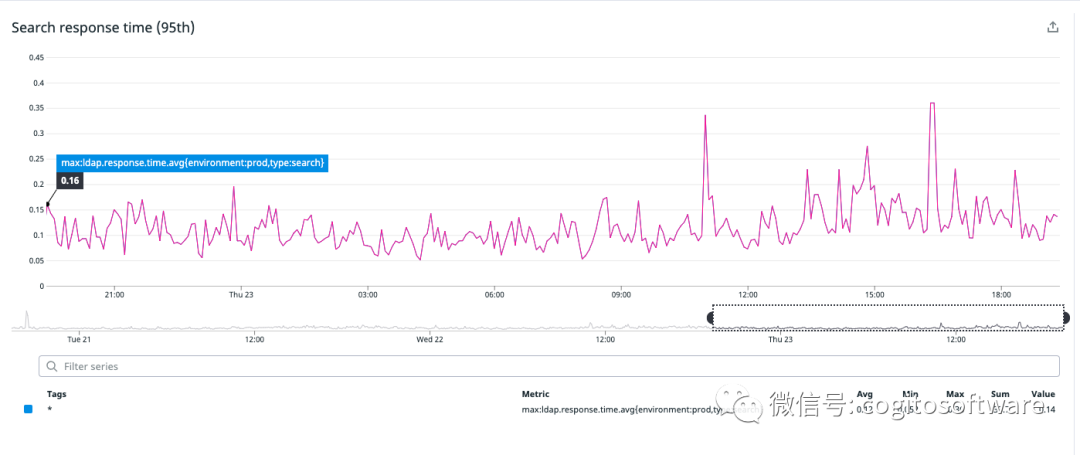 |
| 图a:“搜索”命令的第95个百分位响应时间 |
这种方法的一个缺点是缓存失效。当客户的数据发生变化时(例如,添加或删除用户),LDAP节点必须从我们的主RDBMS刷新它们的数据。在我们之前的架构中,这是一个相对昂贵的操作;当每个节点刷新同一家公司的数据时,它可能会导致LDAP延迟和后备存储负载出现明显的峰值。
延迟敏感性挑战
如上所述,由于延迟要求,每个容器都将所有客户的数据存储在内存中(见图a)。当请求到达一个节点时(如果它尚未存在),数据将按需获取,然后只要来自该客户的至少一个连接存在,数据就会一直存在。
由于传入的连接请求可以到达任何容器(通过负载均衡器),因此提供查询的容器也会加载和存储客户的所有数据。随后,容器向 redispubsub 服务注册以接收失效消息。当公司数据发生更新时,将广播无效信号,接收节点会清除该公司的数据缓存,并转到数据库重新获取公司数据。随着我们不断发展并将新客户添加到我们的系统中,这对扩展我们的LDAP服务提出了以下挑战:
跨所有节点(N)的客户(M)的所有数据都需要在失效时重新加载。尽管实际上并非每个节点都承载来自每个客户的连接,但在最坏的情况下,会对数据库进行MxN次调用以刷新数据。随着更多客户的添加 (M),数据库提取的数量会增加N倍。这也意味着,为了不让数据库机器不堪重负,需要额外的数据库读取器实例来处理请求的激增。
由于跨客户(M)的所有数据都存储在跨多个节点(N)的内存中,因此所有节点的内存继续增加,并与客户数量(M)成比例。这也意味着容器的内存需求必须增长以容纳内存中的所有数据,这反过来又增加了整体基础设施成本。
上述挑战非常明显,让我们倾向于跨节点分布客户数据,而不是在每个节点上复制所有客户的数据。这使我们找到了分布式缓存管理解决方案。
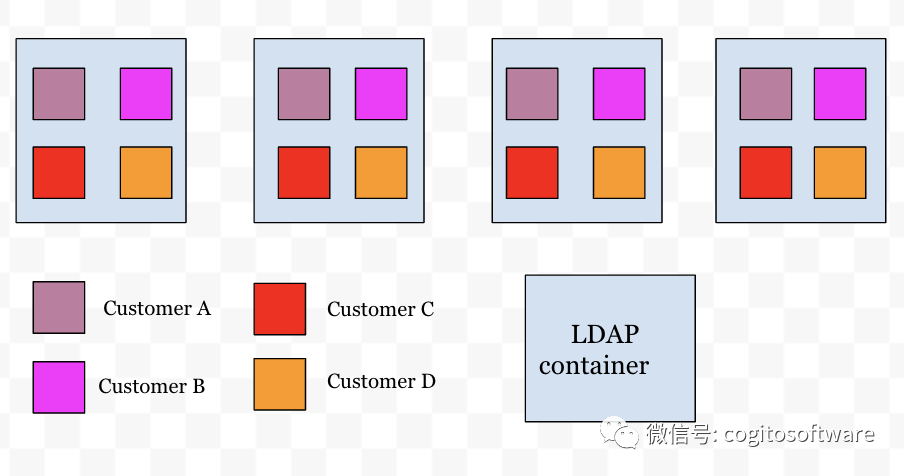 |
| 图a |
分布式缓存管理
我们在LDAP服务中引入了一个智能路由层,如果连接所在的容器未托管数据,该层会将请求转发到托管客户数据的节点。为实现这一目标,我们缩小了路由层的以下设计要求:
客户需要在添加时动态分布在节点之间。
客户的数据需要随着节点收缩、扩展和节点故障而动态分布
能够增加和减少特定客户的分区数量,以便流量不平衡不会压倒任何单个节点。
我们引入了ApacheHelix,它可以跨实例分配资源。Helix控制器是helix生态系统的大脑。当添加或删除节点或客户时,它会跨节点做出资源分配决策。我们对 ApacheHelix 控制器、Rest服务器进行了docker化,并将其部署在ECS上。Helix控制器依赖于Zookeeper来监听集群的变化。我们实施了一种在 ECS上部署Zookeeper的可靠方法。Helix和Zookeeper的整个基础架构都运行在ECS上。
每个LDAP节点都与Zookeeper交互以注册自己以加入集群。每个 LDAP实例作为Helix参与者出现,参与集群以由Helix控制器进行客户到节点的分配。当 LDAP节点动态创建新客户时,该客户的分区数(每个分区代表一个托管数据的节点)根据用户数确定。通过这种集成,我们的 LDAP节点可以了解集群中发生的事件,即添加新客户或可用节点集发生变化时。
有了这种集群意识,我们LDAP服务中的路由层提供了节点和客户之间的映射。现在每个传入连接都将通过路由层来决定连接必须路由到哪个节点。这样,客户的数据就会分配给特定的节点(见图 b)。
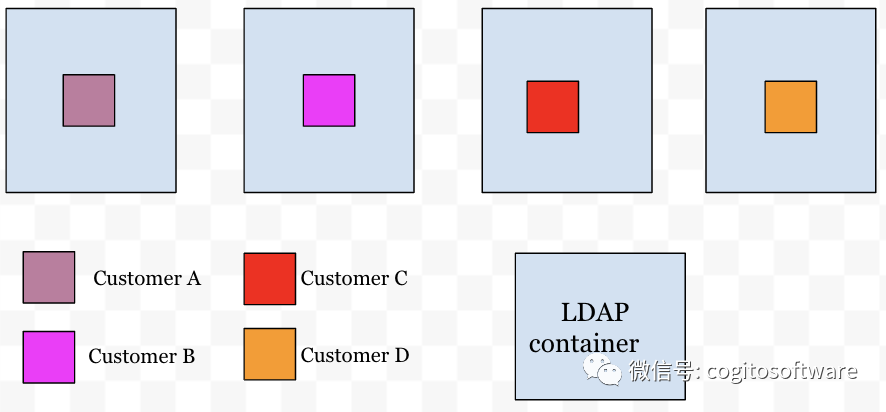 |
| 图b |
路由层托管一个缓存,其中包含客户和节点的路由信息。路由层监视任何客户到节点的分配更改,并在检测到更改时立即更新。这样,每个 LDAP节点都会在客户到节点的更改发生时立即意识到它们。通过上述缓存管理解决方案,解决了延迟敏感性挑战部分中提到的可扩展性挑战:
我们现在的客户分布在各个节点上。每个节点将仅托管一部分客户,并负责在收到 pubsub无效时仅获取一部分客户数据。这显着减少了对数据库的读取次数,无需添加数据库读取器节点来处理大量数据库读取。LDAP集群现在比以前减少了75%的数据库读取。
我们还提高了内存效率,因为我们没有将所有客户(M)数据存储在所有节点(N)的内存中。这种架构提供了水平扩展的能力,而无需增加实例大小。每个 LDAP节点现在消耗的内存比以前减少了40%。
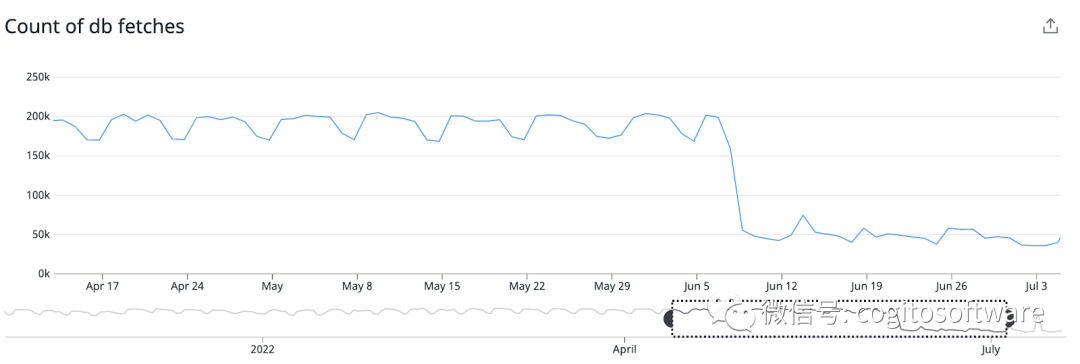 |
 |
当前的挑战
对于上述实现,挑战之一是节点接收到不相等数量的TCP连接。与其他节点相比,这种分布不平衡会导致某些节点(热节点)上的CPU使用率更高。但是与以前相比,节点间的平均整体 CPU利用率仍然保持不变。
审核编辑:刘清
-
TCP
+关注
关注
8文章
1383浏览量
79375 -
过滤器
+关注
关注
1文章
433浏览量
19770 -
python
+关注
关注
56文章
4811浏览量
85102 -
RDBMS
+关注
关注
0文章
9浏览量
5866 -
LDAP
+关注
关注
0文章
10浏览量
7683
原文标题:LDAP:带分区的大规模LDAP
文章出处:【微信号:哲想软件,微信公众号:哲想软件】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Veloce平台在大规模SOC仿真验证中的应用
大规模天线技术商用测试
大规模MIMO的利弊
大规模MIMO的性能
5G毫米波终端大规模天线技术及测试方案介绍
基于LDAP认证的相关资料下载
LDAP认证实现与性能分析





 工商网监
工商网监
评论