 SRAM存算一体芯片的研究现状和发展趋势
SRAM存算一体芯片的研究现状和发展趋势
人工智能时代对计算芯片的算力和能效都提出了极高要求。存算一体芯片技术被认为是有望解决处理器芯片“存储墙”瓶颈,大幅提升人工智能算力能效和算力密度的关键技术和重要解决方案。SRAM存算一体芯片技术由于其在兼容性、鲁棒性、灵活性等方面的优势,已经得到多个旗舰公司的认可和相关领域的产业布局。本文回顾SRAM存算一体芯片领域近年来的研究现状和发展趋势,分析并总结了该领域未来的研究需求,凝练关键科学问题并进一步探讨前沿研究方向。
01. 引言
近年来人工智能算法不断发展,以ChatGPT为代表的大模型更是进一步为科学、技术和社会带来令人振奋的机遇。人工智能作为战略性通用技术,催生了诸多的新兴行业与应用,如自然语言处理、视频智能处理、人脸识别、无人驾驶等,吸引了众多研究机构及产业界的高度关注和广泛参与。人工智能的成功不仅得益于算法理论的创新,更依赖于处理器芯片飞速提升的运算和存储能力,从而使得在更大规模的数据集上设计更复杂、更精准的神经网络成为可能。今年10月17日,美国商务部工业安全局(BIS)公布最新半导体管制规则,在“计算性能”限制的基础上新增对芯片“性能密度”的参数限制,将芯片总体算力和算力密度的重要性提升到新的高度。高算力和高算力密度芯片作为数字经济时代新的核心生产力,对推动科技进步、行业数字化转型以及经济社会发展发挥重要作用。
根据计算架构区分,人工智能芯片的技术路线主要有传统的冯诺依曼架构和新兴非冯计算架构。基于冯诺依曼架构的人工智能处理器又分为通用计算架构和专用计算架构两类。通用计算架构是指采用传统通用计算芯片实现人工智能算法,如CPU、GPU等。大量实验和测试结果已表明传统的通用芯片已无法满足应用场景对高能效和高有效算力的严苛要求。专用计算架构是指专门针对神经网络等人工智能算法定制的专用处理器,其典型代表如 美国麻省理工Eyeriss芯片、谷歌张量处理器TPU芯片等。然而,目前的人工智能芯片的发展仍面临着一系列挑战和限制。人工智能模型的推理和训练均需要大量的计算和数据移动,大量的数据需要在计算单元和存储单元之间频繁流动,传统冯诺依曼架构的“存储墙”问题日益成为该计算架构的发展瓶颈。随着神经网络应用规模快速增长,最先进的AI芯片使用近存计算技术以缓解“存储墙”瓶颈。例如采用三维堆叠的HBM和2.5D的Chiplet集成方式以提升芯片外部至芯片内部的数据带宽,同时节约数据搬运的能量消耗。NorthPole采用分布式片上存储的近存计算,将片上存储均等分布于所有计算阵列中,依靠庞大的片上存储系统部署整个网络,避免芯片外部与芯片内部的数据交互。然而220MB的片上存储依然无法满足大模型需求,同时庞大的片上存储将会产生额外的芯片面积代价。
针对传统冯诺依曼计算架构面临的“存储墙”瓶颈,存算一体这种新兴计算架构旨在把传统以计算为中心的架构转变为以数据为中心的架构,减少或避免数据搬移,从而消除传统冯·诺依曼结构架构面临的“存储墙”瓶颈。存算一体作为一种新兴计算范式,其核心思想就是将计算操作与数据访存过程结合在一起,从而提高计算性能和效率。根据存储墙的介质不同,常见用于存算一体架构的存储技术路线包括RRAM、SRAM、Flash等,各条技术路线均有各自独特的优势和待解决问题。目前,多个国际芯片产业巨头已经在存算一体计算芯片领域进行研发布局,并且在ISSCC等旗舰会议发表多个标志性芯片,并逐渐形成有望解决人工智能计算能效的重要解决方案。基于国产工艺的SRAM存算一体芯片设计技术,有望在同等工艺上可大幅提升计算芯片的“性能密度”,从而大幅提升单位面积下的有效计算性能。
2023年9月,国家自然科学基金委员会组织第347期双清论坛(青年)组织集成电路领域青年专家学者探讨我国集成电路领域存在的关键问题和未来发展方向。存算一体芯片技术作为人工智能芯片的重要技术路线,已得到国内外工业界和学术界的广泛关注和重视。本文结合国家重大战略需求和学科发展前沿,总结当前存算一体芯片的发展情况,凝练SRAM存算一体芯片的关键科学问题,进而提出创新技术路线,支撑我国的人工智能发展战略,为基于国产现有先进工艺的人工智能芯片突破“性能密度(算力密度)”瓶颈,提供一整套创新解决方案。
02. 研究背景与意义
人工智能是未来信息技术领域的国家战略竞争焦点。随着计算机技术的飞速发展和计算能力的提高,人工智能开始取得突破性的进展。特别是在机器学习和深度学习领域,通过利用大数据和强大的算法,使得计算机可以从数据中学习和自主推理。同时,云计算和大数据技术的兴起为人工智能的应用提供了强大的支持。在应用层面,人工智能技术已经在多个领域取得了重大突破,在无人驾驶、智慧安防、人脸识别、智能制造等多个领域带来了颠覆性的进步。此外,通用大模型和行业大模型成为了目前人工智能算法的一个重要发展趋势。硬件技术的进步是人工智能发展的重要推动力,人工智能芯片是人工智能产业物理基础和关键核心技术。图形处理器GPU和专用人工智能芯片极大地提高了计算速度和效率,加速了深度学习和人工智能算法的应用。而大模型对数据量、硬件算力极高的要求,更是给人工智能芯片提出了新的挑战。
传统技术路线带来的算力提升,与智能应用需求之间的算力缺口鸿沟呈指数扩大态势。以数据中心算力需求为例,IDC预测未来五年全球算力规模将以超过50%的速度增长,到2025年整体规模将达到3300EFlops。2025年全球物联网设备数将超过400亿台,产生数据量接近80ZB,数据中心处理量超过50%以上。此外,大模型的算力需求更是呈指数增长,而芯片算力则是呈线性增长。根据目前的芯片算力和GPT-4的训练需求推算,最快的加速器单芯片运行GPT-4模型训练任务需要3.17年。
爆炸式指数增长的海量数据导致云端和边缘端处理的能量消耗呈爆炸式指数增长态势,传统计算芯片的功耗增长难以为继,难以满足大规模人工智能的计算需求。随着芯片集成度的提升和信息技术的发展,到2030年,数据量将达到612ZB,是2020年的13倍,对能耗的需求指数上升,按目前能耗需求推断,至2030年,能耗将占世界总电力能源的21%。基于原有技术路线的芯片面临着能效瓶颈,能耗成为未来增长的天花板。此外,高能耗带来的散热问题,大大提升了板级设计难度以及数据中心运营成本。因此,急需高能效的革新技术以应对智能应用的功耗瓶颈问题。
03. SRAM存算一体芯片研究现状与发展趋势
3.1技术原理
以神经网络为代表的人工智能算法涉及到各种张量和向量计算,其中最具代表性的算子为矩阵向量乘法,这些算子通常具有数据量大、计算量大、并行度要求高的特点。传统处理器在执行人工智能算法时,由于存储和计算分离,在存储器与运算器之间存在大量的数据搬运,造成巨大的功耗和延时开销,导致数据搬运的功耗远远高于计算功耗,成为了冯诺依曼架构加速器的发展瓶颈。如图1所示,存算一体技术的核心思想是将存储器与运算器融合在一起,通过将相对固定的权重数据存放在存储器中,把输入特征向量广播输入到阵列中,实现在存储器内部执行矩阵向量乘法计算,在完成高并行数据访问和计算的同时有效避免了大量权重数据的搬运,从而达到提高运算速度与能量效率的目的,因此存算一体非常适合用来加速人工智能算法中的矩阵和向量运算。
基于当前不同的存储器件类型,存在多种存算一体技术路线,包括易失性存储器SRAM、DRAM,以及非易失性存储器MRAM、PCM、RRAM、Flash等。SRAM与CMOS逻辑工艺兼容,操作电压低,读写速度快,没有耐久性限制,DRAM利用电容存储电荷的方式如1T1C结构来保存数据,能够获得较高的存储密度。非易失性存储器技术方案由于具有存储密度较高且掉电数据不丢失的特点,在对待机功耗或成本更为敏感的应用场景中具备较大的发展潜力,其中MRAM和PCM的耐久性较好,可擦写次数分别超过了百万亿次和十亿次,MRAM与RRAM的制备能够兼容CMOS后道工艺,工艺可演进性较好,目前在台积电等工艺厂商的40nm、22nm等先进节点已经逐步开始研发和量产,NAND Flash则可以通过三维堆叠的方式不断增加堆叠层数来提高存储密度。从计算方式的角度看,由于MRAM、PCM和RRAM的开关比较低,导致本征计算精度不高,因此在对计算精度要求较高的场景下不适合采用模拟计算方案;而SRAM、DRAM和Flash可以实现较高的开关比,因此计算方式的选择较为灵活。
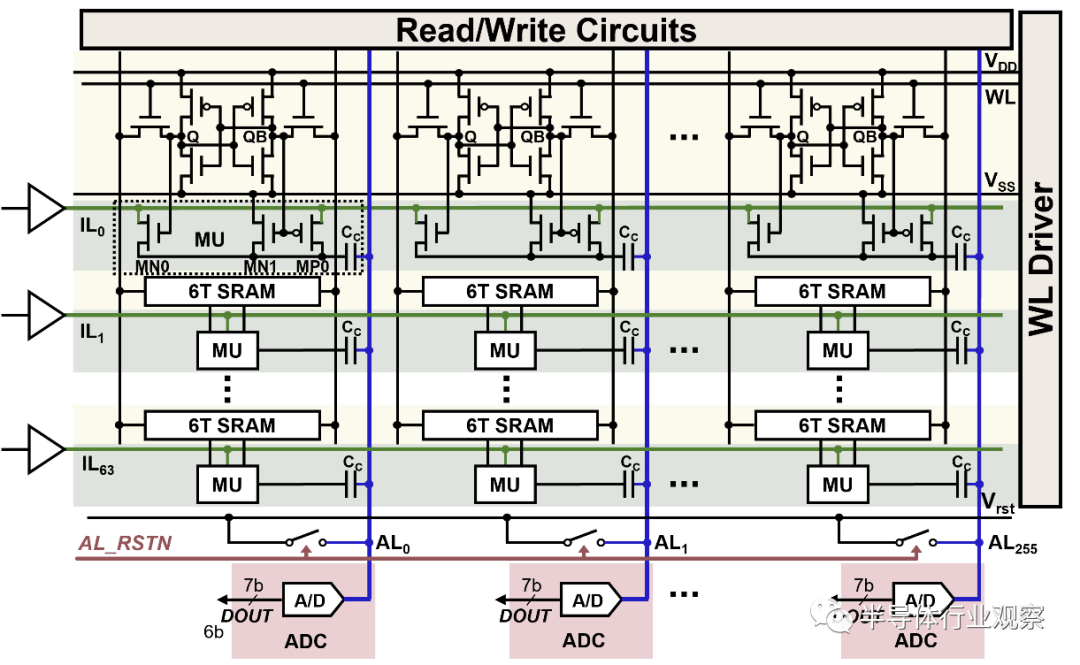
图1 SRAM存算一体电路示意图
3.2SRAM存算一体芯片研究现状
基于SRAM的存算一体技术起步相对较晚,密歇根大学和北海道大学分别于2017年在VLSI会议上,发表了基于SRAM的存算一体芯片,这也是最早一批在集成电路方向发表的基于SRAM的存算一体芯片论文。此后,基于SRAM的存算一体芯片发展迅猛,从2018年开始,ISSCC会议开始设立存算一体相关的会议议题,投稿与发表数逐年增长,计算方式从模拟计算转向数字与模拟计算并存,所支持的计算精度也从一开始只能支持二值化精度到现在能支持浮点精度。
近年来,国内外学术界和工业界已经有多个单位在集成电路领域旗舰会议发表了基于SRAM的存算一体芯片的相关研究成果。台积电在2021年至2023年的ISSCC会议上分别展示了他们在22nm、5nm以及4nm工艺节点上设计的数字域存算一体宏,在加法器树的面积和性能优化、存储和计算单元设计、阵列版图的布线规划和改进、基于多阈值电压平衡漏电和延迟的设计等方面取得了重要进展。在2023年的ISSCC和VLSI会议上,联发科分别介绍了他们在12nm工艺节点上的模拟域和数字域存算一体宏设计,分别实现了对PVT不敏感的高鲁棒性和高识别率的电容型存算一体阵列,以及基于紧凑型SRAM单元的无能效损失和低峰值电流的高性能数字域存算一体阵列。此外,英特尔实验室和意法半导体也在SRAM存算一体领域的研究做出了一些探索和尝试,表明各大国际芯片设计和制造厂商已经开始布局基于SRAM的存算一体计算IP的技术研发。
相较于工业界偏向稳定性、鲁棒性和灵活性的实用性探索,学术界关于SRAM存算一体技术的研究更加注重于尝试针对各种不同应用需求提出新的可能的解决思路和方案。在2023年ISSCC会议上,北京大学介绍了在22nm工艺节点上设计的差值求和的模拟域存算一体芯片,目的是解决边缘端AI场景中存在大量不变的冗余数据信息所导致的计算功耗浪费问题;东南大学则针对高精度、片上训练等需求以及边缘端深度可分离卷积神经网络的加速效率问题,在28nm工艺节点上分别设计了两款数字域浮点存算一体芯片和基于水平权重移位与垂直输入移位的模拟域存算一体芯片;此外,北京清华大学和台湾清华大学等高校也在该领域深耕多年,在国际会议上持续发表了一系列研究成果。
综上所述,相较于其他新型非易失性存储器,基于SRAM的存算一体技术路线尽管起步较晚,但凭借其工艺兼容性、设计灵活性、电路可靠性等优势,近五年发展十分迅猛,在学术界不断尝试和探索的过程中逐渐引起工业界的重点关注,在AI算法愈发向更大模型演进使得硬件算力和功耗愈发受到重视的今天,基于SRAM的存算一体技术展现出了强劲的性能优势和应用潜力,使得多个国际芯片巨头开始在该领域进行研发和产业布局。
3.3SRAM存算一体芯片发展趋势与挑战
SRAM存算一体技术由于具备工艺成熟度高和强鲁棒性的优势,已经成为当前主流存算一体解决方案之一。SRAM存算一体从早期的模拟域计算,逐渐发展到现在的能够支持无精度损失的数字域计算,支持更复杂的算法模型和与算法一致的量化方案,提供更高的鲁棒性和更低的设计复杂度;从早期较为落后的工艺节点,发展到现在能够采用先进的5nm及以下的设计方案,使得算力密度和能效享受到极大的工艺微缩带来的性能红利;从早期只能支持低精度数据格式,逐步发展为支持INT8/INT16以及BF16等更高精度的数据格式;从早期的只能支持神经网络推断功能,发展至同时支持网络训练和推断的训推一体化;从单存算一体宏阵列IP设计发展至多阵列集成的SoC实现;以及从支持简单全连接、卷积等单一算子,逐渐演变为支持多种、多类型的张量计算算子,SRAM存算一体技术正向着更高精度、更高性能、更低功耗、更高的系统复杂度发展。
SRAM存算一体尽管具有工艺成熟度高、易于集成等优势,但目前仍旧面临着包括单元电路设计、可靠性、利用率、计算架构、计算完备性、软件生态等关键问题和挑战。
单元电路设计:以往的存算分离架构使得单元设计可以针对各自不同的需求,分别采用面向高密度存储单元的push rule和面向逻辑单元的logic rule指导其电路设计和工艺制造;而存算融合的新型电路架构使得存储单元和计算单元紧密结合,如何兼顾存储效率和计算效率对存算单元电路设计提出了新的挑战。
可靠性:大规模高密度高并行计算使得电路可靠性和鲁棒性问题进一步凸显,成为走向应用的一大障碍。例如,由于较高的计算密度和并行度,阵列在运行过程中会出现较高的瞬态峰值电流,对IR-drop、电源串扰、响应速度等电源稳定性问题提出了挑战;此外,兼顾存储和计算的可测性设计目前也欠缺较为成熟的解决方案。
利用率:算子种类和大小各不相同,面对真实应用中灵活多变的算子需求,在一个固定大小的存算一体阵列上部署神经网络计算可能会造成计算资源利用率显著降低,导致无法充分发挥SRAM存算一体技术在算力密度、能效等方面带来的性能优势。
计算架构:由于在执行神经网络计算时,尽管权重数据已经被存放在存算一体阵列中,但输入数据、输出数据以及中间计算结果的存储仍然需要依赖片上缓存,使得有限的片上缓存容量可能会成为新的系统瓶颈,导致片外访存开销显著增加。
计算完备性:尽管存算一体针对张量运算能够显著提高算力密度和能效,但真实应用场景中一个完整的AI业务依然需要标量和矢量计算以及非线性计算,这对基于SRAM存算一体的AI加速器的计算完备性提出了新的需求。
软件生态:NVIDIA公司的CUDA 生态主导着目前绝大部分的AI应用开发,使得GPU占据了大部分AI加速器市场。因此除了底层电路的优化和性能提升以外,为了实现存算一体技术落地同样需要与之配套的编译器及工具链,从而打破以CUDA为主导的软件生态,构建出新的能够兼容基于SRAM存算一体异构处理器的软件开发环境。
04. SRAM存算一体芯片的创新路线
SRAM存算一体技术的发展涉及电路、架构、系统、软硬件协同以及生态系统等多个层级。开展跨层级深入研究和全面布局,对于探索SRAM存算一体技术发展路线,实现引领性突破至关重要。在该领域的研究不仅是为人工智能大模型、科学计算等战略性新应用提供足够的计算能力,还旨在突破硬件算力和能效方面的瓶颈,为未来的科技创新提供坚实的基础支撑。基于前沿SRAM存算一体技术的相关进展,本文总结SRAM存算一体芯片在电路、架构、系统、软硬件协同、生态等各个层级的创新技术路线。
在电路层级,我们提出研究发展先进工艺的SRAM存算一体以及可靠性与可测性设计,充分挖掘先进节点工艺所带来的性能红利。通过探索现代工艺技术潜力并基于DTCO(Design Technology Co-optimization)的设计工艺协同优化设计思想,实现存储和计算的高度集成,为计算领域带来重大突破。在先进工艺的基础上,研究人员基于更小的晶体管尺寸和更高的集成度,设计并改进能够实现存储单元与逻辑单元紧凑堆叠的更高密度的SRAM存算单元。这种紧凑性带来的优势在于可以在更小的空间内容纳更多的存储和计算资源,从而大幅度提升芯片的整体性能。同时,先进工艺所带来的低功耗特性也可以有效降低设备的能耗。其次,可靠性和可测性的设计是确保存算单元工作强鲁棒的关键。通过引入先进的自诊断和错误校正技术,在硬件层面实现对存算单元的实时监测和修复,提高了计算系统的稳定性,增加设备寿命。
在架构层级,我们提出基于异构SRAM存算一体的前沿处理器架构。探索通过异构架构设计满足多样的算子计算需求,通过紧耦合不同类型的计算引擎,包括基于ALU的标量计算单元、基于PE的向量计算单元、基于SRAM存算一体的张量计算单元等。标量计算单元适用于处理单一数据元素的计算,向量计算单元则擅长处理大规模数据的并行计算,而张量计算单元则专门用于高维度数据的复杂运算。这种多样性的计算引擎紧密结合,为各种复杂任务提供高效灵活的计算支持,从而提高了计算系统的适应性和性能。此外,异构SRAM存算一体架构还具有较高的能效和节能优势,由不同类型的计算引擎在同一芯片上协同工作,减少了数据传输和处理过程中的能量损耗,提高了整体的能源利用率。
在系统层级,我们提出研究发展基于3D堆叠集成的SRAM存内计算与DRAM近存计算混合的前沿计算系统。基于硅通孔、铜铜混合键合等先进封装技术,可实现高密度、大容量DRAM存储芯片和高算力SRAM存内计算芯片之间的垂直多层 3D异质集成,能有效缓解计算芯片与片外存储之间的数据带宽瓶颈,解决当前SRAM存算一体芯片片上存储容量有限的问题,满足AI大模型对高带宽通信和大容量存储的需求。3D堆叠技术还可以使得不同层级的存储,特别是大容量的片外HBM DRAM,和SRAM存算一体计算引擎之间的数据通路大幅缩短,从而实现近存计算系统,有效降低路径上的负载电容,加速数据的读写速度。此外,减少负载电容也可以降低数据传输过程中的能耗,从而使得系统在执行计算任务时能够更高效地利用能源。
在软硬件协同层级,我们提出研究发展基于多层次抽象建模的跨层次联合仿真、基于STCO(System Technology Co-optimization)的系统工艺协同优化和验证的新方法及SRAM存算一体自动化编译EDA工具。通过跨层次联合仿真与优化,设计者可以在早期阶段就发现系统层面的问题,提前进行优化和调整,从而节省了后期修复问题的成本和时间。通过全面考虑硬件和软件之间的相互影响,设计者可以更好地平衡系统的性能、功耗和面积等PPA指标。研发SRAM存算一体宏的硬件编译器EDA工具,用户可以根据应用需求配置SRAM存算一体宏的阵列尺寸、计算精度、存储计算资源比例等关键参数,在给定工艺下自动化生成所需的SRAM存算一体宏的行为级模型、电路原理图和物理版图等,从而实现SRAM存算一体宏的快速开发和应用部署。在验证方面,跨层次的验证方法允许设计者同时验证硬件和软件之间的交互,确保它们在系统层面的一致性。通过联合验证,可以提前发现硬件和软件之间的兼容性问题,提高系统的可靠性和稳定性。为了支持跨层次设计方法,相关的EDA工具也需要不断创新,这些工具旨在提供全面的性能分析和优化功能,帮助设计者快速找到系统的性能瓶颈,并提供自动化的优化建议。
在生态层级,我们提出研究发展开源硬件与SRAM存算一体软件生态的融合,旨在解决计算完备性难题和突破CUDA生态。以RISC-V为代表的开源硬件设计方法,为开发者提供了一个开放、透明的硬件基础,根据具体需求定制指令集满足各种不同应用场景的需求。借助开源的硬件与软件开发生态,支撑SRAM存算一体架构依托全球开发者社区的力量,促进硬件设计和软件开发之间的紧密合作。此外,该软硬件生态的结合与探索也在CUDA之外提供了其他可能的路径,从而为计算生态系统带来了更大的多样性和创新性。
SRAM存算一体的创新技术路线和布局涉及多个关键层级,需要在电路、架构、系统、软硬件协同和生态层级上进行深入、细致的研究。只有在各个层级的协同下,SRAM存算一体芯片才能真正地实现性能优化、功耗控制、稳定性提升以及开放性拓展,为未来计算领域带来创新和突破。
05. 总结与建议
存算一体芯片技术是在人工智能时代的关键芯片技术之一。本文通过总结SRAM存算一体芯片研究的需求与现状、关键问题和挑战、创新技术路线等,认为SRAM存算一体芯片是符合国家战略需求的关键技术,有望在同等工艺上可大幅提升计算芯片的“性能密度”,提升单位面积下的有效计算性能。针对SRAM存算一体芯片的技术特点,需要从电路到生态等多层级的跨层次布局与发展,建议设立面向存算一体的研究计划,同时布局新型存储器和SRAM存算一体;在发展战略中覆盖器件、电路、阵列、架构、软硬件协同、生态等环节,纵向多环节协同创新,避免各环节之间的割裂;最后,以主流应用,牵引主流赛道的技术路线创新,为国家战略做支撑和服务。
作者团队介绍:
本文作者为北京大学集成电路学院叶乐教授,国家杰青。北京大学黄如院士-叶乐教授团队在AI及存算一体、高精度/高能效模拟信号链、低功耗电路及架构等方向上处于学科前沿水平,在有集成电路设计奥林匹克之称的ISSCC上连续发表了9篇ISSCC成果,近3年获得的荣誉包括2篇ISSCC论文被遴选为Highlight亮点论文、ISSCC 2021年度最佳芯片展示奖(国内首次)、2021年度中国半导体十大研究进展等。2023年ISSCC中,课题组首次提出了基于差值求和的SRAM存内计算(ΔΣCIM)阵列电路,大幅减少了对数值不变输入特征的冗余操作,可使存内计算阵列能耗减少35.8%,该工作已在22nm工艺下进行了流片验证。
审核编辑:汤梓红
-
处理器
+关注
关注
68文章
19259浏览量
229649 -
芯片
+关注
关注
455文章
50714浏览量
423136 -
cpu
+关注
关注
68文章
10854浏览量
211574 -
sram
+关注
关注
6文章
767浏览量
114675 -
人工智能
+关注
关注
1791文章
47183浏览量
238243
原文标题:SRAM存算一体芯片研究:发展与挑战
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
存算一体大算力AI芯片将逐渐走向落地应用
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究


谈谈机电一体化技术的现状及发展趋势
2023年存算一体是芯片设计的技术趋势
基于3DIC架构的存算一体芯片仿真解决方案
巨头纷纷布局存算一体,各种存储介质的优势分析

如何选择存储器类型 存算一体芯片发展趋势


存算一体芯片新突破!清华大学研制出首颗存算一体芯片
存算一体技术发展现状和未来趋势

乘用车一体化电池的发展现状和未来趋势






 工商网监
工商网监
评论