 语言模型的弱监督视频异常检测方法
语言模型的弱监督视频异常检测方法
引言
近年来,弱监督视频异常检测(WSVAD,VAD)因其广阔的应用前景而受到越来越多的关注,在WSVAD任务中,期望异常检测器在仅提供视频级注释的情况下生成的精细化帧级异常置信度。然而当前该领域的大多数研究遵循一个系统性的框架,即,首先是使用预先训练的视觉模型来提取帧级特征,例如C3D、I3D和ViT等,然后将这些特征输入到基于多实例学习(MIL)的二分类器中进行训练,最后一步是用预测的异常置信度检测异常事件。尽管这类方案很简单,分类效果也很有效,但这种基于分类的范式未能充分利用跨模态关系,例如视觉语言关联。
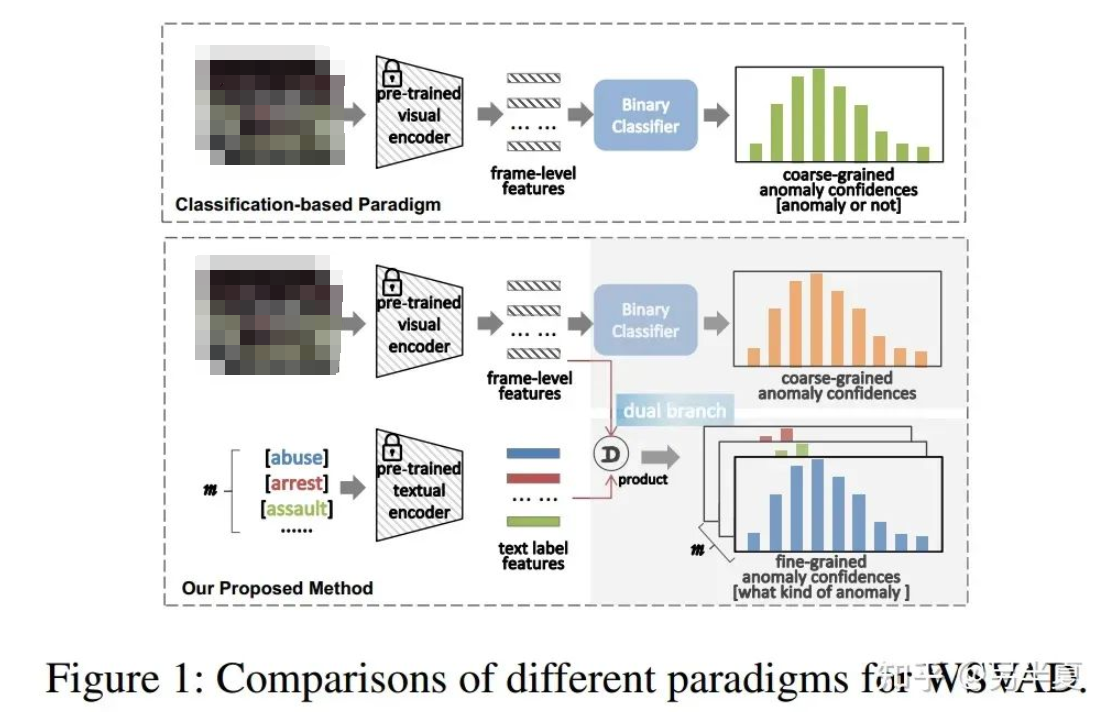
在过去的两年里,我们见证了视觉语言预训练(VLP)模型取得了巨大进展,例如CLIP,用于学习具有语义概念的广义视觉表示。CLIP的主要思想是通过对比学习来对齐图像和文本,即将图像和匹配的文本描述在联合特征空间拉近,同时分离不匹配的图文对。鉴于CLIP的突破性的潜力,在CLIP之上构建任务专用模型正成为新兴的研究课题,并应用于广泛的视觉任务,这些模型取得了前所未有的性能。最近,越来越多的视频理解领域的工作利用CLIP构建专用模型并解决各种视频理解任务。基于此,我们认为CLIP对于WSVAD任务同样有巨大的潜力。
为了有效利用广义知识,使CLIP在WSVAD任务中充分发挥其潜力,基于WSVAD的特点,有几个关键的挑战需要解决。(1)首先,如何进行时序关系建模,捕获上下文的依赖关系;(2)其次,如何利用视觉信息和文本信息联系;(3)第三,如何在弱监督下优化基于CLIP的模型。
针对上述的问题,我们提出了一种基于CLIP的WSVAD新范式,称为VadCLIP。VadCLIP由几个组件组成,包括一个局部-全局时序关系适配器(LGT Adapter),一个由视觉分类器和视觉语言对齐模块组成的双分支异常检测器(Dual Branch)。我们的方法既可以利用传统WSVAD的分类范式,又可以利用CLIP提供的视觉语言对齐功能,从而基于CLIP语义信息和两个分支共同优化以获得更高的异常检测性能。
总的来说,我们工作的主要贡献是:
(1)我们提出了一个新的WSVAD检测方法,即VadCLIP,它涉及双分支网络,分别以视觉分类和语言-视觉对齐的方式检测视频异常。借助双分支的优势,VadCLIP实现了粗粒度(二分类)和细粒度(异常类别多分类)的WSVAD。据我们所知,VadCLIP是第一个将预先训练的语言视觉知识有效地转移到WSVAD的工作。
(2) 我们提出的方法包括三个重要的组成部分,以应对新范式带来的新挑战。LGT适配器用于从不同的角度捕获时间依赖关系;设计了两种提示机制来有效地使冻结的预训练模型适应WSVAD任务;MIL对齐实现了在弱监督下对视觉文本对齐范式的优化,从而尽可能地保留预先训练好的知识。
(3) 我们在两个大规模公共基准上展示了VadCLIP的性能和有效性,VadCLIP均实现了最先进的性能。例如,它在XD Violence和UCFCrime上分别获得了84.51%的AP和88.02%的AUC分数,大大超过了当前基于分类的方法。
方法
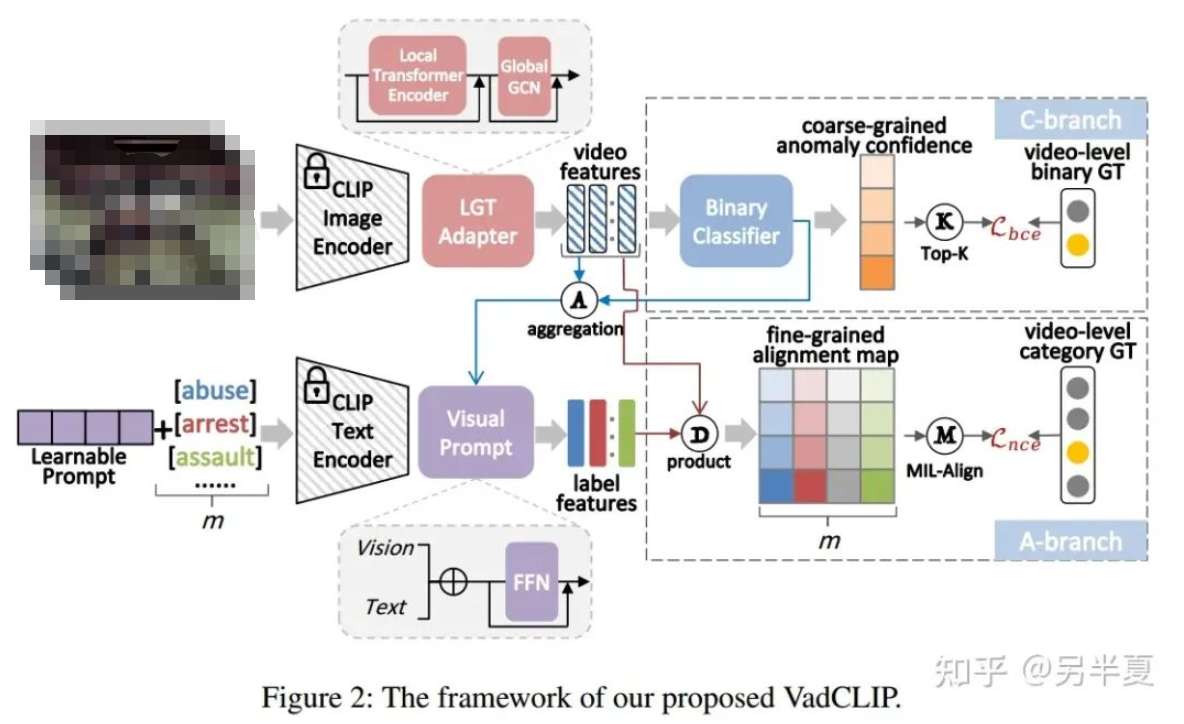
VadCLIP的模型结构如图所示,主要包括了三个部分,分别为局部全局时序关系适配器(LGT Adapter)、视觉二分类分支和视觉文本对齐细粒度分类分支。
LGT Adapter
LGT Adapter由局部关系Transformer和全局关系图卷积串联组成。考虑到常规的Transformer在长时视频时序关系建模时冗余信息较多、计算复杂度较高,我们改进了局部Transformer的mask,从时序上将输入视频帧特征分割为多个等长块,令自注意力计算局限于块内,减少了冗余信息建模,降低计算复杂度。
为了进一步捕获全局时间依赖性,我们在局部模块之后引入了一个轻量级的图卷积模块,由于其在WSVAD任务中得到广泛采用,性能已经被证明,我们采用GCN来捕获全局时间依赖关系。根据之前的工作,我们使用GCN从特征相似性和相对距离的角度对全局时间依赖性进行建模,可以总结如下:
特征相似性分支通过计算两帧之间的特征的余弦相似度生成GCN邻接矩阵:

双分支结构
与之前的其他WSVAD工作不同,我们的VadCLIP包含双分支,除了传统的异常二分类分支之外,我们还引入了一种新颖的视觉-文本对齐分支。二分类分支和传统的WSVAD工作类似,使用一个带有残差连接的FFN和二分类器,直接计算经过时序关系建模的视觉特征的帧级别异常置信度。
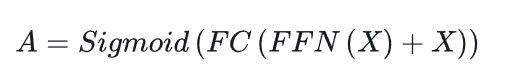
而在视觉文本对齐分支中,文本标签,例如虐待、暴乱、打架等,不再被编码为一个one-hot向量,相反,它们被冻结参数的CLIP文本编码器编码为一个类嵌入向量,因为文本编码器可以为视频异常检测提供语言知识。然后,我们计算类嵌入和帧级视觉特征之间的匹配余弦相似度,这类似于CLIP。在视觉文本对齐分支中,每个输入文本标签代表一类异常事件,从而自然地实现了细粒度的WSVAD。

损失函数

实验结果
对比结果
表1和表2展示了在两个常用的WSVAD数据集UCF-Crime和XD-Violence中,我们的方法和之前的工作的对比结果,为了保证公平,上述列出结果的工作均使用CLIP特征进行重新训练,可以看出我们的方法在两个数据集中相较之前的工作有较大的提升。
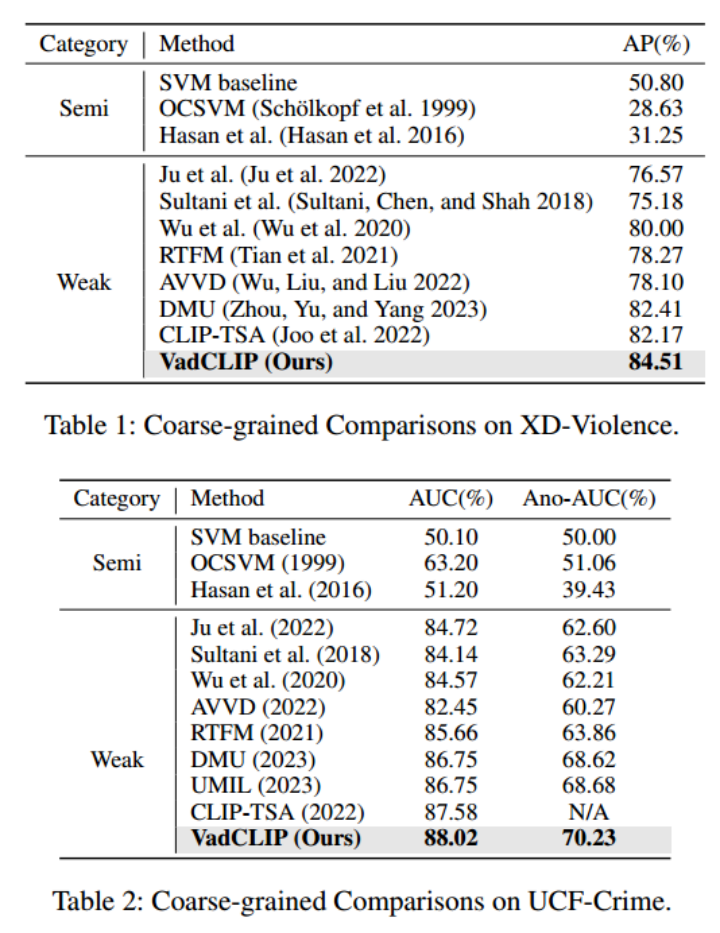
表3和表4展示了使用了细粒度多类别标签进行异常检测,且计算帧mAP@IOU结果的情况,可以看出我们的方法在进行细粒度多分类异常检测时也有明显的提升。
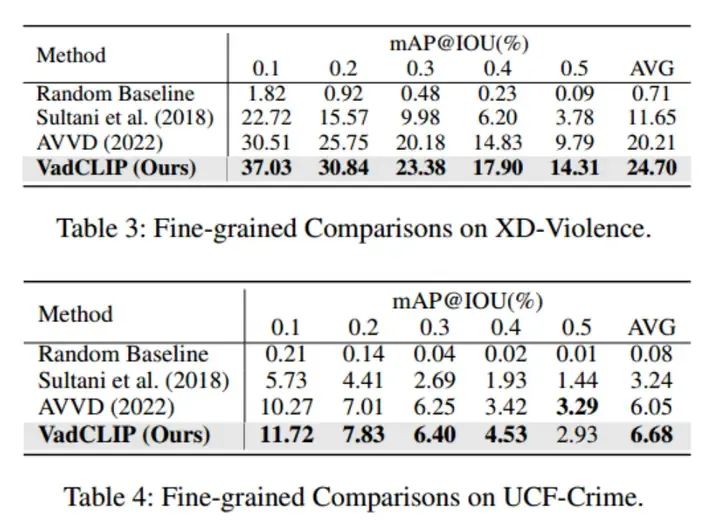
上图分别展示了帧级别粗粒度异常检测可视化结果和细粒度多分类异常检测结果。
总结
在这项工作中,我们提出了一种新的范式VadCLIP,用于弱监督视频异常检测。为了有效地将预训练的知识和视觉语言关联从冻结的CLIP迁移到WSVAD任务,我们首先设计了一个LGT适配器来增强时间建模的能力,然后设计了一系列提示机制来提高通用知识对特定任务的适应能力。最后,我们设计了MIL对齐操作,以便于在弱监督下优化视觉语言对齐。我们通过和最先进的工作对比和在两个WSVAD基准数据集上的充分消融,验证了VadCLIP的有效性。未来,我们将继续探索视觉语言预训练知识,并进一步致力于开放集VAD任务。
审核编辑:黄飞
-
适配器
+关注
关注
8文章
1978浏览量
68389 -
语言模型
+关注
关注
0文章
545浏览量
10356 -
Clip
+关注
关注
0文章
31浏览量
6733
原文标题:AAAI 2024 | VadCLIP: 首个基于视觉-语言模型的弱监督视频异常检测方法
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于transformer和自监督学习的路面异常检测方法分享

基于稀疏随机森林模型的用电侧异常行为检测
基于健壮多元概率校准模型的全网络异常检测
云模型的网络异常流量检测
智能监控视频异常事件检测
基于Greenshield模型的异常节点检测机制
实现强监督和弱监督学习网络的协同增强学习

集成流挖掘和图挖掘的内网异常检测方法

融合零样本学习和小样本学习的弱监督学习方法综述

如何缩小弱监督信号与密集预测之间的差距
基于视觉Transformer的监督视频异常检测架构进行肠息肉检测的研究
弱监督学习解锁医学影像洞察力





 工商网监
工商网监
评论