 AI时代的计算,是不是GPU一家通吃呢?
AI时代的计算,是不是GPU一家通吃呢?
今天这篇文章,我们继续来聊聊芯片。
在之前的文章里,小枣君说过,行业里通常会把半导体芯片分为数字芯片和模拟芯片。其中,数字芯片的市场规模占比较大,达到70%左右。
数字芯片,还可以进一步细分,分为:逻辑芯片、存储芯片以及微控制单元(MCU)。
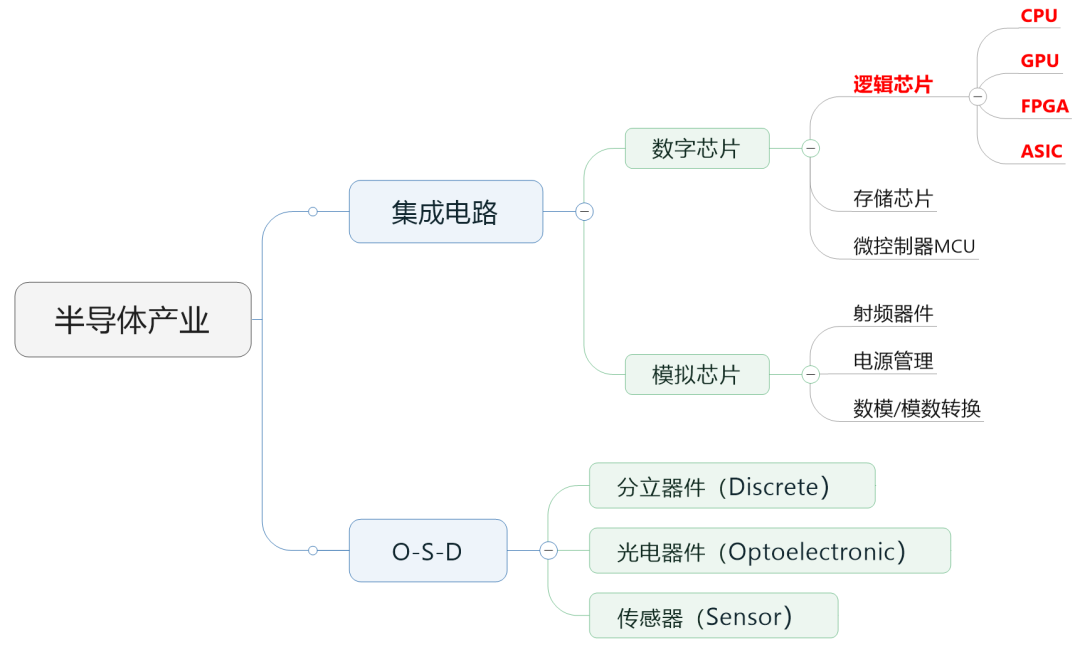
存储芯片和MCU以后再介绍,今天小枣君重点讲讲逻辑芯片。
逻辑芯片,其实说白了就是计算芯片。它包含了各种逻辑门电路,可以实现运算与逻辑判断功能,是最常见的芯片之一。
大家经常听说的CPU、GPU、FPGA、ASIC,全部都属于逻辑芯片。而现在特别火爆的AI,用到的所谓“AI芯片”,也主要是指它们。
█** CPU(中央处理器)**
先说说大家最熟悉的CPU,英文全称Central Processing Unit,中央处理器。
但凡是个人都知道,CPU是计算机的心脏。
现代计算机,都是基于1940年代诞生的冯·诺依曼架构。在这个架构中,包括了运算器(也叫逻辑运算单元,ALU)、控制器(CU)、存储器、输入设备、输出设备等组成部分。
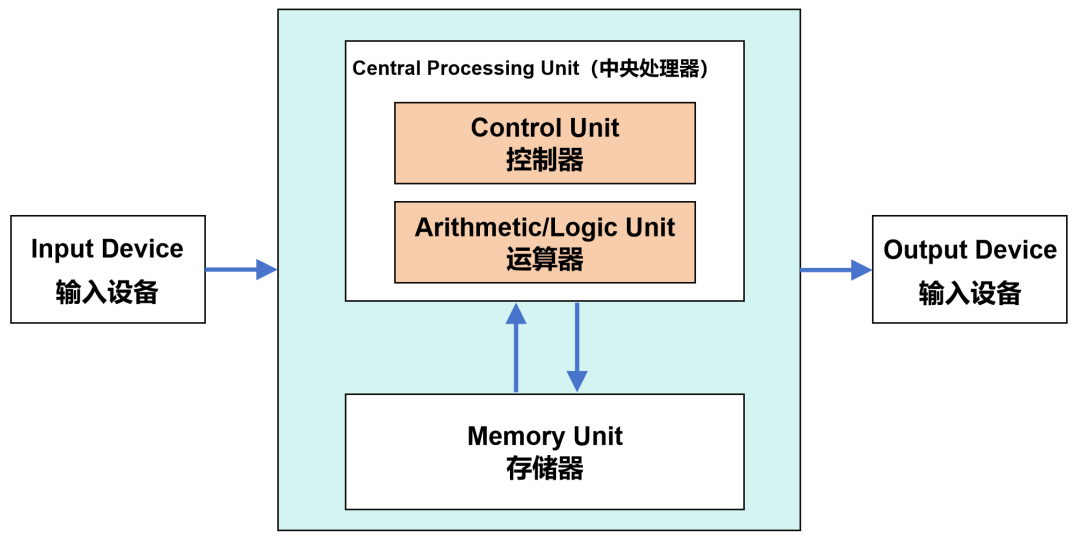
冯·诺依曼架构
数据来了,会先放到存储器。然后,控制器会从存储器拿到相应数据,再交给运算器进行运算。运算完成后,再把结果返回到存储器。
这个流程,还有一个更有逼格的叫法:“Fetch(取指)-Decode(译码)- Execute(执行)-Memory Access(访存)-Write Back(写回)”。
大家看到了,运算器和控制器这两个核心功能,都是由CPU负责承担的。
具体来说,运算器(包括加法器、减法器、乘法器、除法器),负责执行算术和逻辑运算,是真正干活的。控制器,负责从内存中读取指令、解码指令、执行指令,是指手画脚的。
除了运算器和控制器之外,CPU还包括时钟模块和寄存器(高速缓存)等组件。
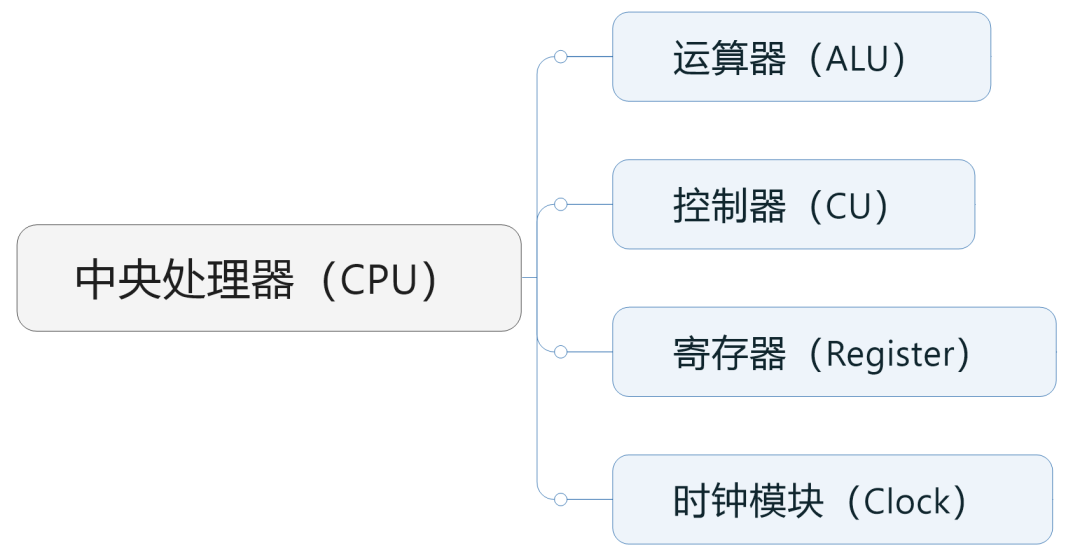
时钟模块负责管理CPU的时间,为CPU提供稳定的时基。它通过周期性地发出信号,驱动CPU中的所有操作,调度各个模块的工作。
寄存器是CPU中的高速存储器,用于暂时保存指令和数据。它的CPU与内存(RAM)之间的“缓冲”,速度比一般的内存更快,避免内存“拖累”CPU的工作。
寄存器的容量和存取性能,可以影响CPU到对内存的访问次数,进而影响整个系统的效率。后面我们讲存储芯片的时候,还会提到它。
CPU一般会基于指令集架构进行分类,包括x86架构和非x86架构。x86基本上都是复杂指令集(CISC),而非x86基本为精简指令集(RISC)。
PC和大部分服务器用的是x86架构,英特尔和AMD公司占据主导地位。非x86架构的类型比较多,这些年崛起速度很快,主要有ARM、MIPS、Power、RISC-V、Alpha等。以后会专门介绍。
█** GPU(图形处理器)**
再来看看GPU。
GPU是显卡的核心部件,英文全名叫Graphics Processing Unit,图形处理单元(图形处理器)。
GPU并不能和显卡划等号。显卡除了GPU之外,还包括显存、VRM稳压模块、MRAM芯片、总线、风扇、外围设备接口等。
1999年,英伟达(NVIDIA)公司率先提出了GPU的概念。
之所以要提出GPU,是因为90年代游戏和多媒体业务高速发展。这些业务给计算机的3D图形处理和渲染能力提出了更高的要求。传统CPU搞不定,所以引入了GPU,分担这方面的工作。
根据形态,GPU可分为独立GPU(dGPU,discrete/dedicated GPU)和集成GPU(iGPU,integrated GPU),也就是常说的独显、集显。
GPU也是计算芯片。所以,它和CPU一样,包括了运算器、控制器和寄存器等组件。
但是,因为GPU主要负责图形处理任务,所以,它的内部架构和CPU存在很大的不同。
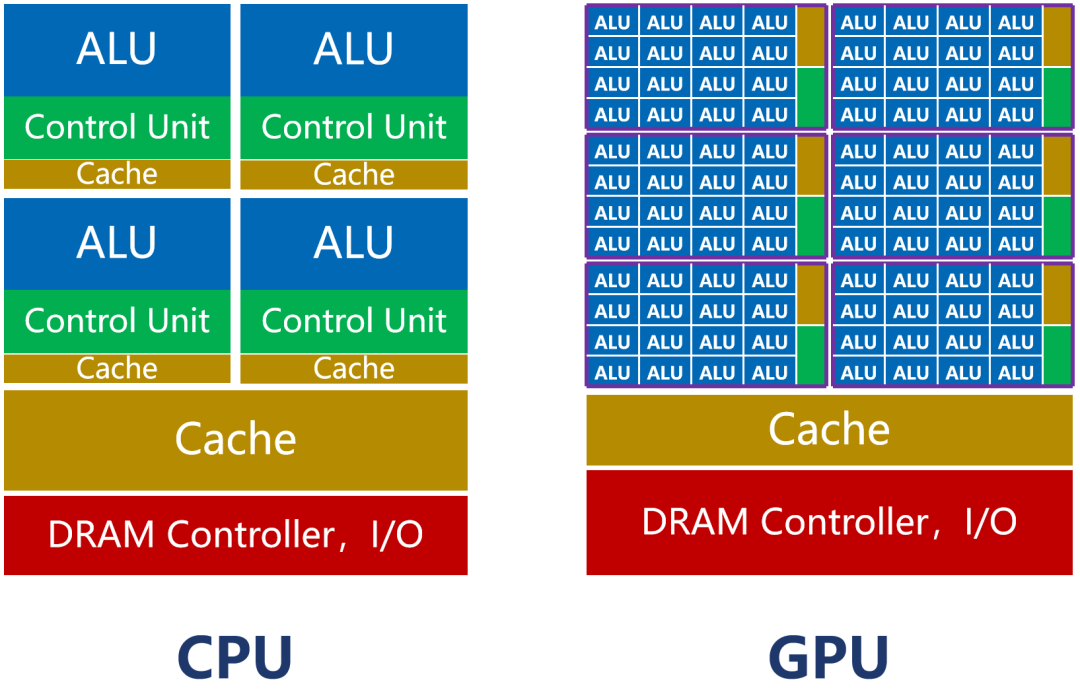
如上图所示,CPU的内核(包括了ALU)数量比较少,最多只有几十个。但是,CPU有大量的缓存(Cache)和复杂的控制器(CU)。
这样设计的原因,是因为CPU是一个通用处理器。作为计算机的主核心,它的任务非常复杂,既要应对不同类型的数据计算,还要响应人机交互。
复杂的条件和分支,还有任务之间的同步协调,会带来大量的分支跳转和中断处理工作。它需要更大的缓存,保存各种任务状态,以降低任务切换时的时延。它也需要更复杂的控制器,进行逻辑控制和调度。
CPU的强项是管理和调度。真正干活的功能,反而不强(ALU占比大约5%~20%)。
如果我们把处理器看成是一个餐厅的话,CPU就像一个拥有几十名高级厨师的全能型餐厅。这个餐厅什么菜系都能做,但是,因为菜系多,所以需要花费大量的时间协调、配菜,上菜的速度相对比较慢。
而GPU则完全不同。
GPU为图形处理而生,任务非常明确且单一。它要做的,就是图形渲染。图形是由海量像素点组成的,属于类型高度统一、相互无依赖的大规模数据。
所以,GPU的任务,是在最短的时间里,完成大量同质化数据的并行运算。所谓调度和协调的“杂活”,反而很少。
并行计算,当然需要更多的核啊。
GPU的内核数,远远超过CPU,可以达到几千个甚至上万个(也因此被称为“众核”)。
RTX4090有16384个流处理器
GPU的核,称为流式多处理器(Stream Multi-processor,SM),是一个独立的任务处理单元。
在整个GPU中,会划分为多个流式处理区。每个处理区,包含数百个内核。每个内核,相当于一颗简化版的CPU,具备整数运算和浮点运算的功能,以及排队和结果收集功能。
GPU的控制器功能简单,缓存也比较少。它的ALU占比,可以达到80%以上。
虽然GPU单核的处理能力弱于CPU,但是数量庞大,非常适合高强度并行计算。同等晶体管规模条件下,它的算力,反而比CPU更强。
还是以餐厅为例。GPU就像一个拥有成千上万名初级厨师的单一型餐厅。它只适合做某种指定菜系。但是,因为厨师多,配菜简单,所以大家一起炒,上菜速度反而快。
CPU vs GPU
█** GPU与AI计算**
大家都知道,现在的AI计算,都在抢购GPU。英伟达也因此赚得盆满钵满。为什么会这样呢?
原因很简单,因为AI计算和图形计算一样,也包含了大量的高强度并行计算任务。
深度学习是目前最主流的人工智能算法。从过程来看,包括训练(training)和推理(inference)两个环节。
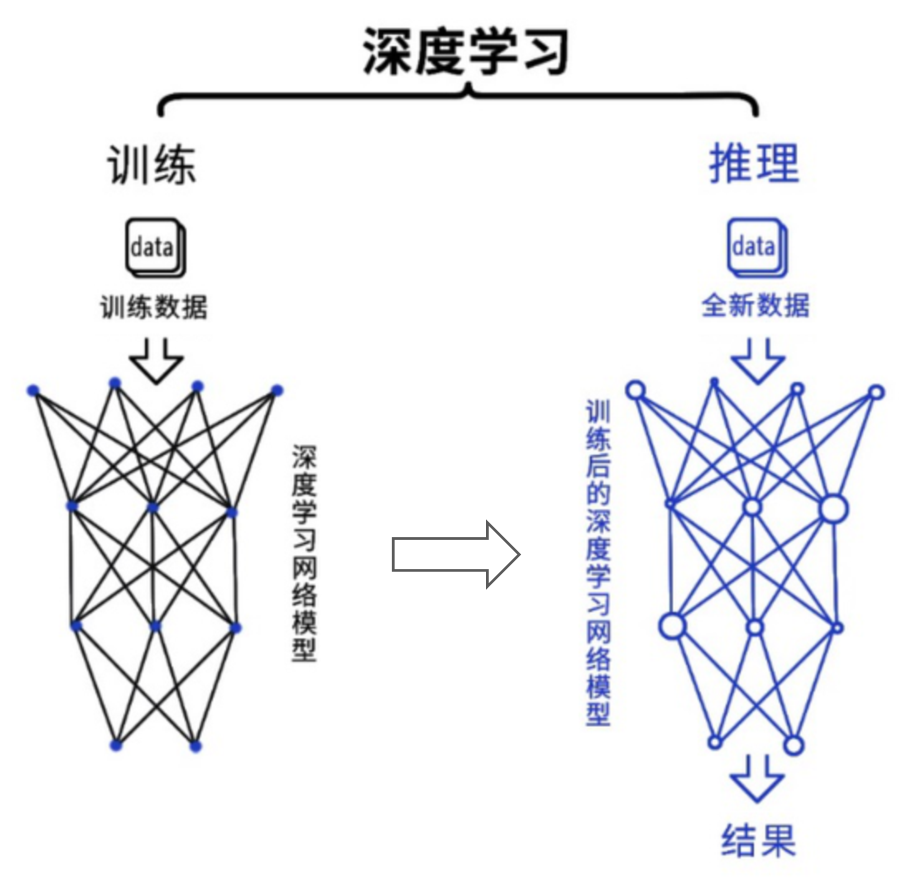
在训练环节,通过投喂大量的数据,训练出一个复杂的神经网络模型。在推理环节,利用训练好的模型,使用大量数据推理出各种结论。
训练环节由于涉及海量的训练数据,以及复杂的深度神经网络结构,所以需要的计算规模非常庞大,对芯片的算力性能要求比较高。而推理环节,对简单指定的重复计算和低延迟的要求很高。
它们所采用的具体算法,包括矩阵相乘、卷积、循环层、梯度运算等,分解为大量并行任务,可以有效缩短任务完成的时间。
GPU凭借自身强悍的并行计算能力以及内存带宽,可以很好地应对训练和推理任务,已经成为业界在深度学习领域的首选解决方案。
目前,大部分企业的AI训练,采用的是英伟达的GPU集群。如果进行合理优化,一块GPU卡,可以提供相当于数十其至上百台CPU服务器的算力。
不过,在推理环节,GPU的市场份额占比并没有那么高。具体原因我们后面会讲。
将GPU应用于图形之外的计算,最早源于2003年。
那一年,GPGPU(General Purpose computing on GPU,基于GPU的通用计算)的概念首次被提出。意指利用GPU的计算能力,在非图形处理领域进行更通用、更广泛的科学计算。
GPGPU在传统GPU的基础上,进行了进一步的优化设计,使之更适合高性能并行计算。
2009年,斯坦福的几位学者,首次展示了利用GPU训练深度神经网络的成果,引起了轰动。
几年后,2012年,神经网络之父杰弗里·辛顿(Geoffrey Hinton)的两个学生——亚历克斯·克里切夫斯基(Alex Krizhevsky)、伊利亚·苏茨克沃(Ilya Sutskever),利用“深度学习+GPU”的方案,提出了深度神经网络AlexNet,将识别成功率从74%提升到85%,一举赢得Image Net挑战赛的冠军。
这彻底引爆了“AI+GPU”的浪潮。英伟达公司迅速跟进,砸了大量的资源,在三年时间里,将GPU性能提升了65倍。
除了硬刚算力之外,他们还积极构建围绕GPU的开发生态。他们建立了基于自家GPU的CUDA(Compute Unified Device Architecture)生态系统,提供完善的开发环境和方案,帮助开发人员更容易地使用GPU进行深度学习开发或高性能运算。
这些早期的精心布局,最终帮助英伟达在AIGC爆发时收获了巨大的红利。目前,他们市值高达1.22万亿美元(英特尔的近6倍),是名副其实的“AI无冕之王”。
那么,AI时代的计算,是不是GPU一家通吃呢?我们经常听说的FPGA和ASIC,好像也是不错的计算芯片。它们的区别和优势在哪里呢?
审核编辑:刘清
-
处理器
+关注
关注
68文章
19158浏览量
229095 -
gpu
+关注
关注
28文章
4700浏览量
128688 -
门电路
+关注
关注
7文章
199浏览量
40123 -
逻辑芯片
+关注
关注
1文章
152浏览量
30539 -
半导体芯片
+关注
关注
60文章
915浏览量
70571
原文标题:AI计算,为什么要用GPU?
文章出处:【微信号:鲜枣课堂,微信公众号:鲜枣课堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA在深度学习应用中或将取代GPU
手机GPU大全
是不是应该专攻一个特长更靠谱呢?
即将到来的AI时代,谁将笑傲江湖
ai芯片和gpu的区别
MX6UL芯片上没有GPU是不是意味着不支持OpenGL呢
瑞芯微和英伟达的边缘计算盒子方案,你会选哪一家的?
是不是没有输出wrong answer就代表whetstone计算结果无误呢?
英特尔推出一家新的AI公司
为什么GPU对AI如此重要?






 工商网监
工商网监
评论