 目前主流的深度学习算法模型和应用案例
目前主流的深度学习算法模型和应用案例
来源:英码智能百科
深度学习在科学计算中获得了广泛的普及,其算法被广泛用于解决复杂问题的行业。所有深度学习算法都使用不同类型的神经网络来执行特定任务。
什么是深度学习?
深度学习是机器学习领域的新研究方向,旨在使机器更接近于人工智能。它通过学习样本数据的内在规律和表示层次,对文字、图像和声音等数据进行解释。深度学习的目标是让机器像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习模仿人类视听和思考等活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
虽然深度学习算法具有自学习表示,但它们依赖于反映大脑计算信息方式的人工神经网络。在训练过程中,算法使用输入分布中的未知元素来提取特征、对对象进行分组并发现有用的数据模式。就像训练机器进行自学一样,这发生在多个层次上,使用算法来构建模型。
下面介绍一下目前主流的深度学习算法模型和应用案例。
目前主流的深度学习算法模型
01RNN(循环神经网络)
循环神经网络(Recurrent Neural Network,RNN)它模拟了神经网络中的记忆能力,并能够处理具有时间序列特性的数据。它可以在给定序列数据上进行序列预测,具有一定的记忆能力,这得益于其隐藏层间的节点的连接。这种结构使其能够处理时间序列数据,记忆过去的输入,并通过时间反向传播训练。此外,RNN可以使用不同的架构变体来解决特定的问题。比如,LSTM(长短期记忆)和GRU(门控循环单元)是改进的算法,能够解决RNN中常见的梯度消失或爆炸问题。在处理时间序列数据上,RNN具有强大的优势,能够有效捕捉数据中复杂的时间依赖关系,准确预测未来,因此它被广泛应用于自然语言处理、语音识别、股票价格预测等领域。
关键技术:循环结构和记忆单元
处理数据:适合处理时间序列数据
应用场景:自然语言处理、语音识别、时间序列预测等

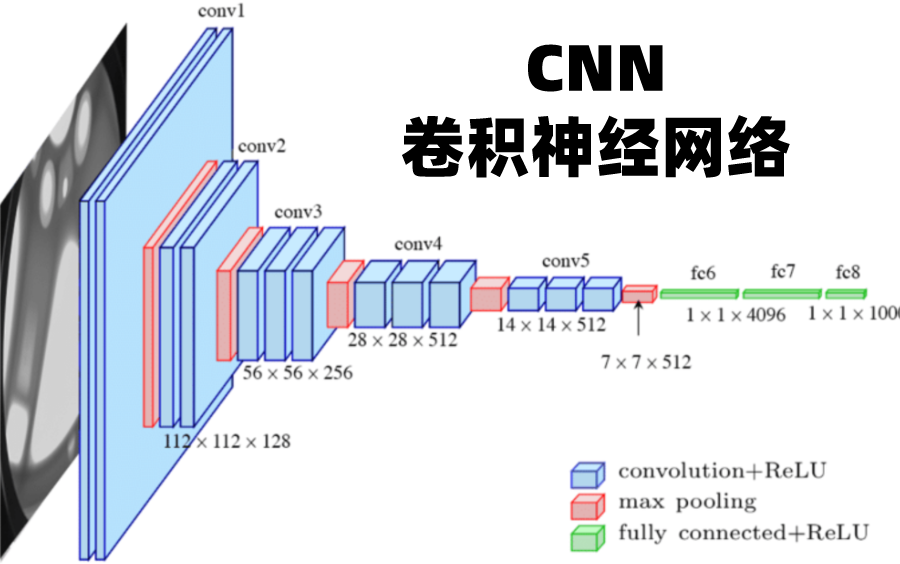
02CNN(卷积神经网络)
CNN基本原理是利用卷积运算,提取数据的局部特征。这种网络架构由一个输入层、一个输出层和中间的多个隐藏层组成,使用卷积层、ReLU层和池化层来学习特定于数据的特征。其中,卷积层用于提取图像中不同位置的特征,ReLU层用于将数值化的特征转换为非线性形式,池化层用于减少特征的数量,同时保持特征的整体特征。在训练过程中,CNN会通过反向传播算法计算模型参数的梯度,并通过优化算法更新模型参数,使得损失函数达到最小值。CNN在图像识别、人脸识别、自动驾驶、语音处理、自然语言处理等领域有广泛的应用。
关键技术:卷积运算和池化操作
处理数据:适合处理图像数据
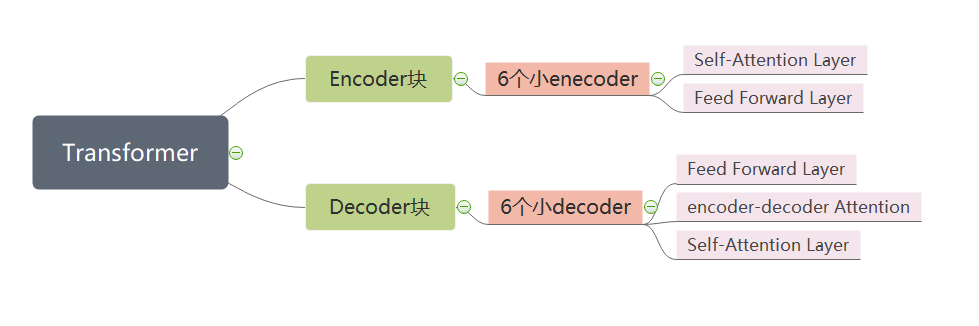
03Transformer
Transformer是一种基于自注意力机制的神经网络模型,由Google在2017年提出,具有高效的并行计算能力和强大的表示能力。它是一种基于自注意力机制的神经网络模型,使用注意力机制处理输入序列和输出序列之间的关系,因此可以实现长序列的并行处理。它的核心部分是注意力模块,用于对输入序列中的每个元素与输出序列中的每个元素之间的相似性进行量化。这种模式在处理序列数据时表现出强大的性能,特别是在处理自然语言处理等序列数据任务时。因此,Transformer模型在自然语言处理领域得到了广泛的应用,比如BERT、GPT和Transformer-XL等著名模型。但是,也存在一些限制,例如数据要求高、解释性差和学习长距离依赖关系的能力有限等缺点,因此在应用时需要根据任务需求和数据特点进行选择和优化。
关键技术:自注意力机制和多头注意力机制
处理数据:适合处理长序列数据
应用场景:自然语言处理、机器翻译、文本生成
04BERT
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer双向编码器的预训练语言表征模型,BERT模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的Representation,即文本的语义表示,然后将文本的语义表示在特定NLP任务中作微调,最终应用于该NLP任务。BERT模型强调不再采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。
关键技术:双向Transformer编码器和预训练微调
处理数据:适合处理双向上下文信息
应用场景:自然语言处理、文本分类、情感分析等
05GPT(生成式预训练Transformer模型)
GPT(Generative Pre-trained Transformer)是一种基于互联网的、可用数据来训练的、文本生成的深度学习模型。GPT模型的设计也是基于Transformer模型,这是一种用于序列建模的神经网络结构。与传统的循环神经网络(RNN)不同,Transformer模型使用了自注意力机制,可以更好地处理长序列和并行计算,因此具有更好的效率和性能。GPT模型通过在大规模文本语料库上进行无监督的预训练来学习自然语言的语法、语义和语用等知识。
预训练过程分为两个阶段:在第一个阶段,模型需要学习填充掩码语言模型(Masked Language Modeling,MLM)任务,即在输入的句子中随机掩盖一些单词,然后让模型预测这些单词;在第二个阶段,模型需要学习连续文本预测(Next Sentence Prediction,NSP)任务,即输入一对句子,模型需要判断它们是否是相邻的。GPT模型的性能已经接近或超越了一些人类专业领域的表现。
关键技术:单向Transformer编码器和预训练微调
处理数据:适合生成连贯的文本
应用场景:自然语言处理、文本生成、摘要等
审核编辑:汤梓红
-
人工神经网络
+关注
关注
1文章
120浏览量
14660 -
算法模型
+关注
关注
0文章
7浏览量
6747 -
机器学习
+关注
关注
66文章
8438浏览量
132976 -
深度学习
+关注
关注
73文章
5512浏览量
121445
原文标题:【技术科普】主流的深度学习模型有哪些?AI开发工程师必备!
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA上部署深度学习的算法模型的方法以及平台
Nanopi深度学习之路(1)深度学习框架分析
针对线性回归模型和深度学习模型,介绍了确定训练数据集规模的方法
深度学习模型压缩与加速综述







 工商网监
工商网监
评论