 一种创新的面积和能效AI存储器设计—MCAIMem
一种创新的面积和能效AI存储器设计—MCAIMem

摘要
人工智能芯片通常使用 SRAM 存储器作为缓冲器(buffers),其可靠性和速度有助于实现高性能。然而,SRAM 价格昂贵,需要大量的面积和能耗。以前的研究曾探讨过用非易失性存储器等新兴技术取代 SRAM,因为非易失性存储器具有快速读取内存和单元面积小的特点。尽管有这些优势,但非易失性存储器的写入内存访问速度慢、写入能耗高,因此在需要大量内存访问的人工智能应用中,非易失性存储器的性能无法超越 SRAM。一些研究还将 eDRAM 作为一种面积效率高的片上存储器进行了研究,其存取时间与 SRAM 相似。但是,刷新功耗仍然是一个令人担忧的问题,性能、面积和功耗之间的权衡尚未解决。
为了解决这个问题,在本文中我们提出了一种新型混合 CMOS 单元存储器设计,通过结合 SRAM 和 eDRAM 单元,平衡了人工智能存储器的性能、面积和能效。我们考虑了存储器中一个 SRAM 和七个 eDRAM 单元的比例,以利用混合 CMOS 单元存储器实现面积缩减。
此外,我们还利用 DNN 数据表示的特点,集成了非对称 eDRAM 单元,以降低能耗。为了验证我们提出的 MCAIMem 解决方案,我们进行了大量仿真,并对传统 SRAM 进行了基准测试。结果表明,MCAIMem 在面积和能效方面明显优于这些替代方案。具体来说,与 SRAM 设计相比,我们的 MCAIMem 可以减少 48% 的面积和 3.4 倍的能耗,而且不会造成任何精度损失。
引言
深度神经网络(DNN)加速器已成为各种机器学习系统的重要组成部分。DNN 需要存储大量参数才能实现高精度,因此对内存的要求很高。DNN 已在图像识别、物体检测、语言翻译和自动驾驶等广泛应用中证明了其有效性。最先进的 DNNs 需要数十亿次运算和巨大的内存来存储激活和权重,transformer的大小在两年内增加了 240 倍就是证明 。专用内存导致尖端 DNN 加速器更多地使用较大的片上内存。例如,在 Eyeriss(如图 1.(a) 所示)中,SRAM 占芯片面积的 79.2%,占功耗的 42.5%;在 Simba 等芯片设计中,SRAM 占芯片面积的 67%;而最新的晶圆级芯片可容纳高达 18 GB 的片上存储器。由此可见,使用片上 SRAM 存储器需要更高的功耗和面积。
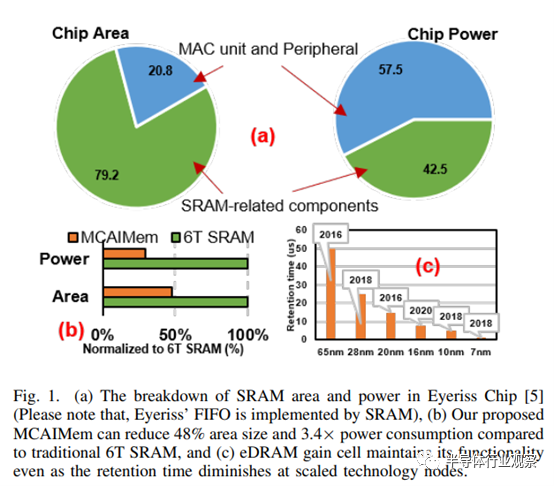
6T SRAM 长期以来一直是嵌入式存储器的首选,因为它具有逻辑兼容的位单元、快速差分读取和静态数据保持能力。然而,由于其相对较大的单元尺寸以及在低工作电压下读写的竞争要求,使得 6T SRAM 难以在先进的 CMOS 技术中扩展。
最近,非易失性存储器因其单元尺寸小、单元泄漏低和快速读取访问操作而引起了研究界的兴趣。早期的研究试图用 ReRAM、FeFET 等非易失性存储器取代片上 SRAM。然而,非易失性存储器的写入操作比读取操作更慢,能耗更高。这会对 DNN 应用中的人工智能芯片性能产生负面影响,例如片上学习,片上读取和写入操作都是必须的。
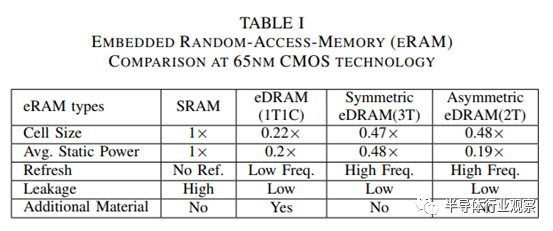
片上 SRAM 的另一个替代品是嵌入式动态随机存取存储器 (eDRAM)。表 I 比较了采用相同 65 纳米低功耗 CMOS 工艺的不同嵌入式存储器。我们发现,与 6T SRAM 相比,1T1C eDRAM(1 个晶体管和 1 个电容器)的位元密度高 4.5 倍,静态功耗低 5.0 倍,甚至包括刷新功耗。这使得芯片尺寸更小、存储器访问速度更快、存储器密度更高,这是在给定功耗限制条件下提高微处理器性能的最有效方法。
然而,非易失性存储器和传统 eDRAM(1T1C)需要复杂的制造工艺,因为它们需要专门的材料才能在晶圆上部署。
3T(三晶体管)和 2T(双晶体管)CMOS eDRAM 增益单元设计是嵌入式动态随机存取存储器电路,与传统 SRAM 相比,每个存储单元使用的晶体管数量更少。因此密度更高,面积更小。3T/2T eDRAM 单元使用逻辑器件制造,因此只需进行极少的修改即可在标准 CMOS 工艺中构建。工业设计表明,使用三个晶体管可实现比 SRAM 高约 2 倍的位元密度。为此,eDRAM 增益单元(3T 和 2T)可在不改变制造技术的情况下减少片上 SRAM 面积。
如表 I 所示,与片上 SRAM 相比,eDRAM 增益单元在面积和能耗方面都有优势。具体来说,与 SRAM 相比,2T eDRAM 的静态功耗降低了 5.26 倍。然而,由于保持时间较短,使用 eDRAM 增益单元会导致大量刷新功耗,从而限制了 eDRAM 增益单元相对于片上 SRAM 的功耗优势。因此,在人工智能芯片中实施 eDRAM 增益单元仍然是一个可行的考虑因素。
在深度学习应用中,INT8 已成为理想的数值表示方法,可在各种任务中保持精度。在作为 DNN 量化标准的 8 位整数格式中,发生在最重要位(MSB:Most Significant Bits)上的错误比发生在最不重要位(LSB:Least Significant Bits)上的错误权重更大。根据量化后 DNN 的 8 位整数数据往往聚集在零点附近的观察。对于这种接近零的小整数,正值的 MSB 通常为 0,负值的 MSB 通常为 1。这种模式提供了通过位翻转来增加正整数中 1 的数量的机会,从而在 DNN 数据中形成 1 的优势。零位较多的 LSB 由于重要性较低,可以承受误差,对最终精度的影响很小。
最近的一项研究提出了一种非对称 DNN 数据编码器,在保持 DNN 性能的同时,提高了 INT8 表示法中 0 位的频率。这一想法可与使用 2T eDRAM 的片上数据存储结合起来进一步利用,2T eDRAM 显示了位-1 和位-0 之间数据保留的不对称性,其中位-1 比位-0 提供更少的静态和访问能量。
将 6T SRAM/2T eDRAM 混合设计与一个增强型数据编码器(增强 INT8 表示法中位-1 的普遍性)相结合,可以优化芯片的面积和能耗。因此,我们推出了 MCAIMem,一种基于 SRAM 和非对称 eDRAM 的混合存储单元,设计用于节省面积和能耗的片上人工智能存储器。MCAIMem 适应性强,能够满足各种内存容量和性能需求,因此适用于从紧凑型边缘设备到大型数据中心等各种人工智能应用。我们的贡献如下:
据我们所知,我们首次提出了用于片上人工智能存储器的 6T SRAM 和 2T eDRAM 混合单元。我们对 2T eDRAM 单元进行了修改,使其与 SRAM 单元保持一致,并提高了容量以延长保留时间。我们的混合存储器单元大大减少了人工智能加速器的片上存储器占用空间
我们提出的共电压检测放大器(CVSA:common voltage sense amplifier)可同时用于 SRAM 和 2T eDRAM 单元。通过控制 CVSA 的参考电压,我们可以延长 2T eDRAM 的刷新周期,从而降低 MCAIMem 的动态刷新能耗。
我们利用了非对称 2T eDRAM,其中存储 bit-1 比 bit-0 消耗更少的能量。结合 DNN 数据的单增强编码器/解码器解决了 eDRAM 的可靠性问题,如刷新率和保持时间,从而显著降低了 MCAIMem 的静态功耗。
如图 1.(b) 所示,我们的 MCAIMem 通过融合 6T SRAM 和 2T eDRAM 的优势,创建了高性能、高能效和紧凑型混合存储器解决方案,从而将片上人工智能存储器系统的面积消耗减少了 48%,能效提高了 3.4 倍。
在第二节,我们介绍了增益单元 eDRAM、外围电路以及 DNN 数据表示中使用的二乘法的背景信息。第三节详细介绍了人工智能存储器的综合设计和运行机制。第四节讨论了 MCAIMem 对人工智能应用的影响。第五节介绍了 45 纳米工艺技术的硬件评估结果,包括电路和系统两个层面。第六节探讨了在人工智能应用中采用 eDRAM 的最新研究成果。最后,第七节得出结论。
背景
本节介绍了采用全 CMOS 技术和操作的 2T/3T eDRAM 增益单元电路设计的背景,回顾了 DNN 中的二乘表示法,并总结了为 AI 芯片设计混合 SRAM 和 eDRAM 单元存储器所面临的挑战和要求。
1
嵌入式 DRAM 单元和传感设计
3T 和 2T eDRAM:
与传统 SRAM 相比,3T 和 2T eDRAM 设计每个存储单元使用的晶体管更少,因此面积更小,密度更高,位元密度大约提高了 2 倍。最近的研究表明,eDRAM 的增益单元目前正在积极开发中,最新的实现采用了 7-10 纳米 FinFET 技术。如图 1.c 所示,在休眠模式下,eDRAM 单元的漏电流低于 SRAM,从而降低了静态功耗,包括漏电功耗和刷新功耗。
eDRAM 单元的单元写入边际优于 SRAM,因为在增益单元(gain cell)中,存取器件(access device)和交叉耦合锁存器(cross-coupled latch)之间不存在竞争。然而,传统增益单元的存储电容较小,漏电流在工艺-电压-温度(PVT:Process-Voltage-Temperature)变化下呈指数变化,导致刷新功耗较高和/或读取电流较小,因而保持时间较短。前者源于更频繁的刷新操作,后者则源于更快的单元电压损耗。
要理解 eDRAM 增益单元,可以考虑传统 3T 增益单元的基本保持特性。在图 2.(a) 所示的 3T NMOS 单元中,PW 代表写入访问器件,PS 代表存储器件,PR 代表读取访问器件。在 3T eDRAM 中,PS 的栅极电容用于存储比特-1 或比特-0 表示的电荷电压。与 1T1C eDRAM 相比,PS 的容量较小。因此,3T 增益单元采用解耦读写结构,读取数据时使用独立的读字线(RWL)和读位线(RBL),写入数据时使用写字线(WWL)和写位线(WBL)。这提高了位元设计中的读写边际和灵活性,使增益单元在未来的技术节点中能够很好地扩展。
在数据保留模式下,PW 和 PR 将被停用,使存储节点处于浮动状态。周围器件的次阈值、栅极和结漏会导致浮动电压随时间变化。数据保留时间取决于进入存储节点的总漏电流。在 SPICE 中进行的蒙特卡洛仿真,显示了采用低功耗 CMOS 45nm 技术的 1 Mb 存储器宏中单元与单元之间的变化,如图 2.(a) 所示。当读取参考偏置电平为 0.65 V 时,位 1 电压和位 0 电压会在相同的保持时间内接近读取参考偏置电平。
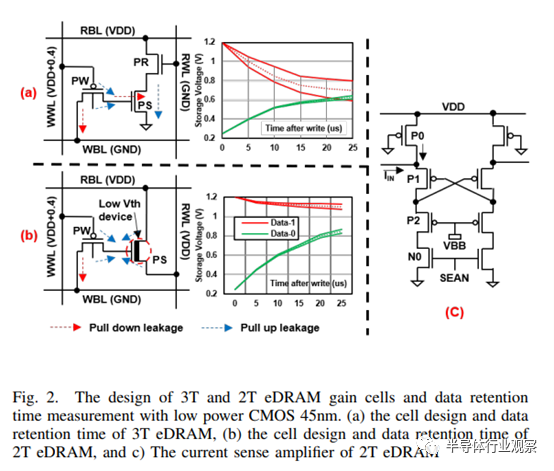
创新的 2T 增益单元设计采用了更少的晶体管,其特点是由 RWL 驱动的单个高驱动电流 NMOS 读取器件和一个 PMOS 写入器件,可保持临界 bit-1 电压在 VDD 附近。图 2.(b) 展示了 2T eDRAM 单元,其结构和工作原理与 3T eDRAM 有很大不同。之前的 3T eDRAM 单元使用 PMOS 器件作为写入访问晶体管,通过 PMOS 栅极重叠和结点泄漏来抵消 NMOS 栅极泄漏,从而延长单元保持时间。
然而,在 PVT 变化下,漏电补偿证明是不够的,因为 NMOS 存储设备的反相沟道栅极漏电在比特-1 中占主导地位,如图 2(a)所示。
在图 2.(b) 所示的 2T eDRAM 单元中,读取访问晶体管由 RWL 信号取代,预充电电平设置为 VDD。存储晶体管基本上处于关闭状态,因此其栅极漏电流微不足道。由于读取路径不存在阈值下漏电,因此建议采用低 Vth 晶体管,以进一步提高读取速度。在 0.65V 读取参考偏置下,存储单元表现出不对称性,位-1 不会改变,而位-0 容易翻转为位-1。均衡的 P 和 N 扩散密度是所提出的 2T 不对称单元的另一个优点。本文旨在利用这一特性最大限度地减少静态和动态能耗,因为位-0 的翻转需要更多的能量。
2T eDRAM 检测放大器:
在增益单元中,NMOS 栅极电容用于存储电荷,使其对电压变化非常敏感。直接访问 NMOS 可能会导致存储位翻转。因此,传统增益单元需要一个电流检测放大器来检测存储节点。对于 2T 单元设计,RBL 必须表现出有限的摆幅,以避免因未选择单元的漏电流而导致读取失败。
然而,较小的电压摆幅会导致较差的读取感应裕度。非对称 2T 增益单元利用低 Vth 读取器件实现更快的读取速度,同时将速度关键的第 1 位电压保持在 VDD 附近,从而使情况更加复杂。为解决这一问题,在 2T eDRAM 设计中采用了电流模式检测放大器 (C-S/A),在检测期间将 RBL 电压保持在 VDD 附近,并允许将多个低 Vth 单元连接到单个 RBL。
如图 2.(c) 所示,C-S/A 由一个交叉耦合 PMOS 锁存器 (P1) 和一个伪 PMOS 二极管 (P2) 组成,伪 PMOS 二极管由负电源 VBB 驱动,而 VBB 在芯片上很容易获得,可用于欠驱动 WWL。负 WWL 是 PMOS 器件向单元写入比特-1 而不产生阈值电压损耗的必要条件。两个 PMOS 对(P1 和 P2)都在饱和模式下工作,从而提高了匹配度。不过,这种 C-S/A 设计仅用于读取 2T eDRAM 单元中的存储位,因为位-0 仍需要定期回写以避免位翻转。
因此,写操作需要一个额外的写电路,由于 2T eDRAM 单元尺寸小,读/写电路需要大量的开销,因此导致效率低下。在这种 2T eDRAM 中。传统的 2T eDRAM 只能利用 2T eDRAM 的非对称特性,通过 C-S/A 在较小的电压摆幅下进行感应,而我们的方法则不同,它通过电压感应扩展了读取过程。在我们的方案中,存储电荷的电压裕量更大,位 0 为 0 至 0.8V,位 1 为 0.8 至 1.0V。更深入的讨论见第 III-B 节。
2
DNN 表示中的二乘补法和一增强法
在深度神经网络(DNN)中,数据表示法的选择对精度、计算复杂性和功耗有很大影响。二进制表示法是 DNN 中符号整数值的常用格式,因为它简化了算术运算,尤其是乘法和加法运算。这种格式将负数表示为相应正数二进制表示的二进制补码,从而简化了硬件实现,降低了电路复杂度。
目前,INT8 被认为是 DNN 推理的最佳表示形式,能保持精确的结果。8 位二进制量化技术已被广泛采用,并优于其他量化技术。在这项工作中,我们选择 8 位二进制作为设计片上缓冲器的基准。
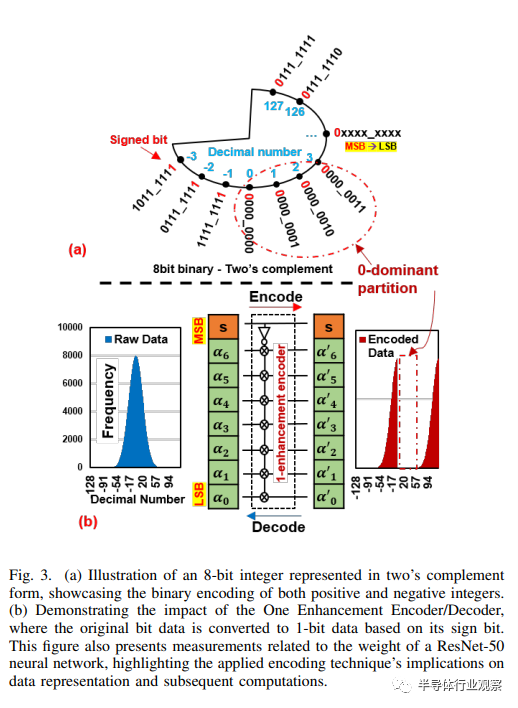
如图 3.(a)所示,第一位(即有符号位:signed bit)决定数字是正数还是负数。正如 ZEM 所指出的,DNN 数据的范围通常很窄(例如 [-50,50])。接近零的负值具有 1 主导位,而相应的正数则表现为 0 主导位。转换 0 主位时,需要根据带符号位翻转所有数据位。如图 3.(b) 所示,构建编码器只需要一个 INV 和七个 XOR 门,就能将原始数据转换为 1 主位数据。单增强编码器将 DNN 数据编码为 1 主位数据。解码器根据签名比特翻转编码数据,从而重建原始数据。
与 ZEM 不同的是,我们的工作旨在创建 1 主导数据,以减少混合单元存储器设计在存储 DNN 数据时的刷新和静态能耗。在本文中,存储在片上存储器中的 DNN 数据在计算前要经过编码和解码。
3
设计挑战和要求概述
我们在考虑单增强编码器/解码器的要求时,有符号位充当控制位,决定何时执行编码或解码操作。保护签名位不受错误影响至关重要。在本文中,我们利用 2T eDRAM 来提高面积和能效。然而,由于单元电压损耗加快,2T eDRAM 需要更频繁的刷新操作。为了确保签名位的安全,我们将其分配到 6T SRAM,并将其余位映射到 2T eDRAM。因此,在设计混合 SRAM 和 eDRAM 单元时,我们需要应对以下挑战:
兼容性:确保在单一存储器架构中无缝集成 SRAM 和 eDRAM 单元,并保持与现有制造工艺的兼容性。
密度和面积效率:在不牺牲性能或增加芯片复杂性的情况下,实现高存储器密度和面积效率。
保持时间和刷新率:解决 eDRAM 单元固有的保持时间限制,优化刷新率,在不影响数据完整性的前提下最大限度地降低功耗。
可扩展性:开发可轻松扩展的存储器架构,以适应从边缘设备到数据中心的各种人工智能应用对存储器容量和性能的不同要求。
可靠性:保证混合内存设计在不同运行条件下的稳健性和可靠性,尤其是在涉及频繁读写操作的人工智能工作负载中。
在本文中,我们将解决上述问题,并介绍适合人工智能应用的高效片上存储器设计。更多详情将在后续章节中介绍。
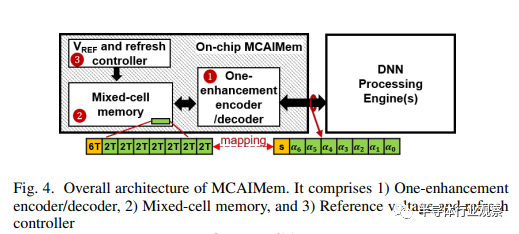
我们的MCAIMEM
本节将介绍 MCAIMem,这是我们专为人工智能芯片开发的创新型片上混合单元存储器设计。如图 4 所示,MCAIMem 由三个关键部分组成:
混合 SRAM/eDRAM 单元存储器,包括映射方案和电路相关设计;
一个增强编码器/解码器;
负责延长刷新操作时间的参考电压控制器。
片上 MCAIMem 是人工智能加速器的缓冲器,用于存储计算过程中的权重和激活。从片外 DRAM 传输过来的数据保留在 MCAIMem 中,随后由 DNN 处理引擎使用,该引擎可以是传统的 CPU/GPU,也可以是合成阵列或内存计算(CIM)架构。
入站/出站(Inbound/outbound)数据必须通过一个增强编码器模块进行编码/解码,这将在第 III-A1 节中讨论。编码后的数据将保存在我们的混合单元存储器设计中,这是 6T SRAM 和 2T eDRAM 的组合,旨在最大限度地减少片上存储器的面积占用。有关混合单元存储器设计的更多细节将在第 III-B 节中介绍。由于包含 2T eDRAM,因此需要进行定期刷新操作。刷新控制器将在第 III-C 节中讨论。
1
一次增强编码器/解码器和数据映射
1) 一次增强编码器/解码器模块:要在片上 MCAIMem 中存储数据,首先需要使用一次性增强编码器/解码器模块对数据进行编码。在 45 纳米技术节点上进行合成后,我们对一次增强编码/解码模块进行了实验评估。经测量,该模块的功耗为 1.35×10-2mW,仅占内存总功耗的 0.007%,因此其影响可以忽略不计。在面积方面,该模块仅占 35.2um2 的面积,与 108KB 的内存大小相比,仅占 0.004%。这些指标表明,该模块对功耗和空间需求的影响微乎其微,尤其是与大量的存储单元相比。此外,与编码器/解码器相关的延迟仅为 0.23ns。即使时钟周期为 1ns(对应于 1GHz 的时钟频率),也有 0.67ns 的宽裕延迟,可确保不会出现违反时序的情况。因此,编码器/解码器的延迟不会对系统的整体性能构成威胁。
如第 II-B 节所述,输入数据在存储到我们的混合单元存储器之前,会根据其符号位进行翻转。通过将原始比特数据增强为通常为 1 位的值,可以降低存储器的总体能耗,因为单元经过优化,可以更高效地存储和访问 1 位数据。可以利用二进制表示法中的带符号位来进行这种增强,因为根据数字的符号,带符号位要么是 0,要么是 1。编码器对输入数据进行修改,使其出现更多的 1 位,而解码器则逆转这一过程以恢复原始数据。例如,剪枝会导致 20-80% 的数据为 0 。由于大部分数据接近于 0,因此在不牺牲数据完整性或准确性的情况下,增强表示以产生更多比特-1 值,可以提高内存系统的能效。
如图 5 所示,第 6 位、第 5 位和第 4 位大多转换为位-1,因此将它们映射到 2T eDRAM 单元的效率很高。第 0 位、第 1 位、第 2 位和第 3 位继续保持相当数量的位-0。使用 2T eDRAM 存储这些比特时,可能会出现保留错误。不过,由于 2T eDRAM 的非对称性质,只有从 0 到 1 的翻转错误才被视为保留错误。这些错误可能会影响 DNN 应用的输出。为确保这些错误不会对 DNN 应用结果产生不利影响,我们将在第 IV-A 节评估其影响。

2) 混合单元映射方案:如第 II-A 节所述,使用 2T eDRAM 可能会因保留时间短而导致错误。基于单增强编码器/解码器,控制位至关重要,因为控制位出错会导致其余所有位出错。因此,在 2T eDRAM 中存储 DNN 数据时,我们需要确保控制位受到良好保护,同时允许其余位近似。建议的位映射如下:
将控制位映射到 6T SRAM,
将 7 个最小有效位 (LSB) 映射到 2T eDRAM。
如图 6 所示,一个 6T SRAM 单元分配给带符号/控制位,而下面的 7 个位则映射到 2T eDRAM 单元。输入的 DNN 数据首先由单增强编码器编码,然后存储在混合单元阵列中。签名位/控制位安全地存储在 6T SRAM 中,而其余位则根据签名位翻转并存储在 2T eDRAM 中,如图 6 所示。
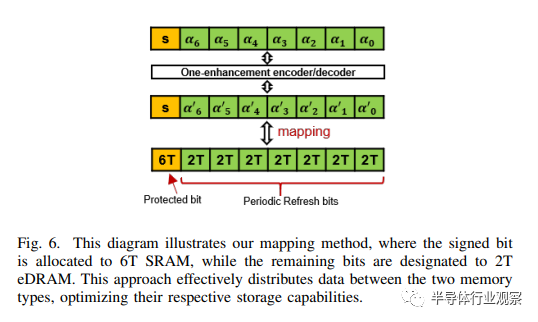
这种存储器映射方法确保了 6T SRAM 中签名/控制位的安全性,同时要求对其余位进行定期刷新操作,以防止数据翻转 ping。这一机制对于保持比特-1 在大多数 DNN 数据(约 80%)中的主导地位至关重要。由于 2T eDRAM 的特性,存储比特-1 比存储比特-0 消耗更少的能量。因此,通过将单增强编码器与非对称 2T eDRAM 结合使用,可以实现静态节能。
2
混合单元(mixed-cell)存储器设计
如映射方法所述,我们的混合单元存储器设计由一个 6T SRAM 单元和七个 2T eDRAM 单元组成。为了集成这些单元,我们需要修改 6T SRAM 和 2T eDRAM 的电路设计。在这项工作中,我们建议对 2T eDRAM 进行修改,并对 6T SRAM 稍作改动。此外,我们还提出了一种可同时用于 6T SRAM 和 2T eDRAM 的电压检测放大器。这些调整的细节将在下面的小节中讨论。
1) 增强非对称 2T eDRAM 单元的保持时间:在结合 6T SRAM 和 2T eDRAM 的设计时,我们遇到了间距通道不匹配的挑战,并且需要同时适用于 6T SRAM 和 2T eDRAM 的混合感应放大器。这是因为与 6T SRAM 相比,2T eDRAM 的尺寸要小得多。为了解决间距通道问题,我们调整了 2T eDRAM 存储晶体管的尺寸。如图 7.(c) 所示,在设计 6T SRAM 和 2T eDRAM 的单元布局时,可能会出现间距通道不匹配的情况。与 SRAM 单元相比,2T eDRAM 单元仅占 60% 的面积。因此,我们可以将 2T eDRAM 的宽度增加到 4 倍,以便与 6T SRAM 单元的设计保持一致。
如第 II-A 节所述,2T eDRAM 由两个主要部分组成:存取晶体管和存储节点。如图 7(a)所示,存储节点中的栅极电容(Cg)存储代表比特-1 或比特-0 的电荷电压。NMOS 栅极的容量定义为 Cg ∝ W LCox。通过增加 NMOS 栅极的宽度,我们不仅提高了存储节点的容量,还改善了 2T eDRA 的保持时间。图 7.(b) 展示了使用 CMOS 45 纳米技术设计的 eDRAM 的 SPICE 仿真;当存储位 0 时,保持时间显著延长。例如,当存储节点宽度增加 4 倍时,电荷从 0.18V 变为 0.8V 所需的时间增加了一倍。
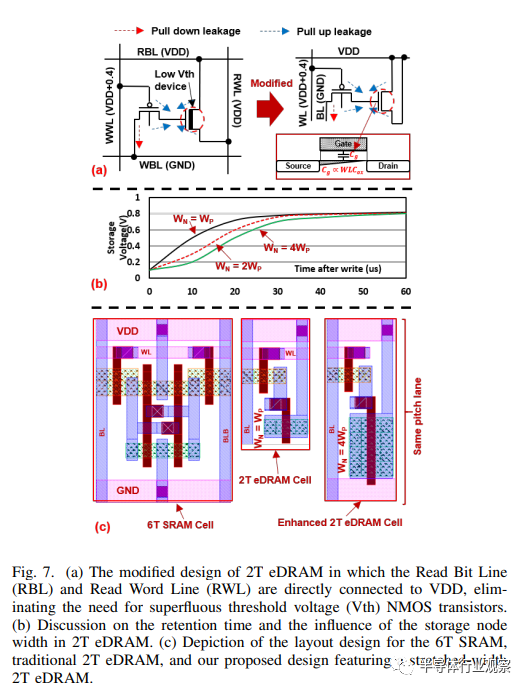
此外,增加存储节点的容量还能带来额外的好处。它使 2T eDRAM 更能抵御读取干扰效应。这样,我们就可以移除 2T eDRAM 中的 RWL 和 RBL,将它们直接连接到 VDD。现在,NMOS 晶体管只起到存储电容器的作用。来自存储节点 VDD 的栅极漏电以及写入晶体管的栅极漏电和结漏电将存储节点的电荷补充到位 1。因此,2T eDRAM 的非对称特性保持不变。
通过这种设计,我们预计位 1 的存储无需保留时间,而位 0 则需要定期刷新操作来保持其放电状态。因此,我们可以将存储节点的漏极和源极直接连接到 VDD,如图 7.(a) 所示。在本研究中,我们利用上拉漏电流来维持 "1 "位并存储 "0 "位,因此无需改变低电压阈值 (LVT) 器件通常需要的掺杂和栅极氧化物厚度。这种方法使此类修改变得没有必要。
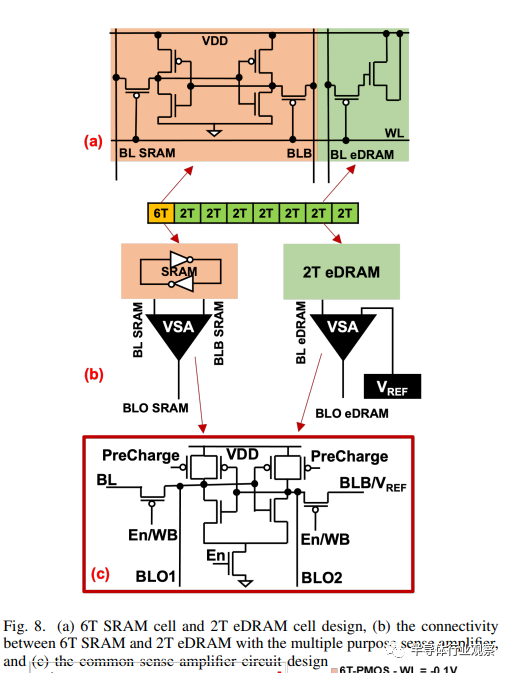
2) 混合存储单元中 SRAM 单元设计的调整:我们对 2T eDRAM 的存储节点进行了重大修改,但保留了传统 2T eDRAM 设计中的 PMOS 接入晶体管。做出这一决定是为了确保只有第 0 位发生变化,而第 1 位保持不变。为了尽量减少 PMOS 的阈下漏电,并确保下拉漏电路径始终低于上拉漏电路径,我们采用了 VDD+0.4V 电压。不过,使用 PMOS 晶体管作为存取晶体管可能与 6T SRAM 中存取晶体管的设计相冲突。
为解决这一问题,我们对 SRAM 单元设计进行了细微修改,如图 8.(a) 所示,将 SRAM 中的访问晶体管也改为 PMOS。通过调整两个存储单元中的访问晶体管类型,我们促进了 6T SRAM 和 2T eDRAM 设计的整合,同时保持了所需的功能和性能。
通过修改 6T SRAM 位单元中的存取晶体管(参见图 9.a),我们发现使用 pMOS 存取晶体管(红线)时,读取静态噪声裕度 (SNM) 为 100mV,而使用 nMOS 晶体管(黑线)时为 90mV。不过,pMOS 晶体管的写入能力较低。随着节点 QB 放电和 Vgs 下降,当 QB 降到阈值电压以下时,晶体管会减弱并关闭,从而导致 FS 角的写入裕量受限为 30mV(绿线)。如图 9.b 所示,在字线 (WL) 上施加 -0.1V 电压时,pMOS 存取晶体管的写入良率会增加,达到 nMOS 晶体管的写入良率。
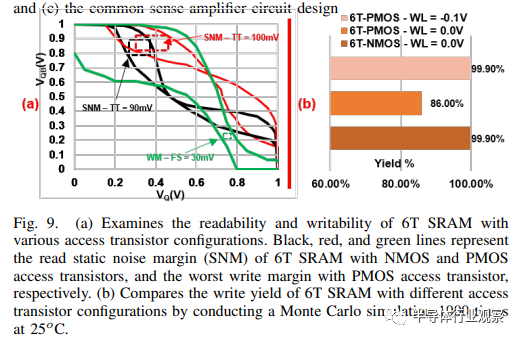
3) 用于 SRAM 和 2T eDRAM 的电压检测放大器电路(Voltage sense amplifier circuit):如第 II-A 节所述,2T eDRAM 取消了读写路径,这意味着读写操作需要单独的电路。此外,2T eDRAM 的保留时间较短,需要定期刷新操作来维护数据。设计混合单元的主要挑战之一是提供同时满足 6T SRAM 和 2T eDRAM 的混合感应放大器。
在 2T eDRAM 中,需要一个电流检测放大器来检测读取路径中的微小增益,而不会干扰存储节点中的数据。但是,刷新操作要求将读取的数据写回存储节点,从而导致大量的外围电路开销。如第 III-B1 节所述,通过将 2T eDRAM 的宽度尺寸增加 4 倍,该设计可以抵御读取干扰。因此,我们建议为 6T SRAM 和 2T eDRAM 安装一个电压检测放大器,如图 8(c)所示。这使得 2T eDRAM 和 6T SRAM 的读写操作完全相同。6T SRAM 和 2T eDRAM 连接到电压检测放大器时的主要区别在于,6T SRAM 的 BL 和 BLB 都是连接的。相反,对于 2T eDRAM,只有一个 BL 连接到感应放大器,而感应放大器的 BLB 连接到参考电压 (VREF),如图 8(b)所示。
这不仅简化了读写操作,而且使用电压检测放大器还能在读取操作过程中将数据写回 2T eDRAM 存储节点。这就简化了刷新过程,因为只需要一次读操作就能完成刷新,而不是标准 2T eDRAM 设计中传统的一连串读和写操作。
4) 电压检测放大器的读写操作:图 10.(a) 展示了使用电压检测放大器 (VSA) 的写操作。写入过程首先是向位线输出端 (BLO1) 施加电压,然后通过使能信号 (EN) 启用电压检测放大器。这一操作会导致位线充电或放电。当字线 (WL) 被激活时,位线电压会改变 6T SRAM 或 2T eDRAM 中的数据。对于 SRAM,6T SRAM 中的 PMOS 存取晶体管必须弱于存储节点,写入操作才能成功。对于 2T eDRAM,存储节点的充放电过程与 SRAM 类似。
图 10.(b) 显示了 VSA 的读操作。为初始化读取操作的感测放大器,启用了预充电,将 BLO1 和 BLO2 充至 1。对于 2T eDRAM,可将参考电压施加到位线栅 (BLB)。该参考电压 (VREF ) 用于比较存储节点的电压,并确定 BLO1 的数据输出。一旦感测放大器中的 WL 和 EN 启用,存储节点将对位线进行充电或放电。如果位线(BL)电压大于检测放大器内的 VREF,BLO1 将被设置为 1;如果 BL 电压小于 VREF,BLO1 将被设置为 0。因此,必须禁用感测放大器中的 WB,以便为 2T eDRAM 中的存储节点充电。对于 6T SRAM,VSA 的 BLB 连接到 SRAM 单元的 BLB。
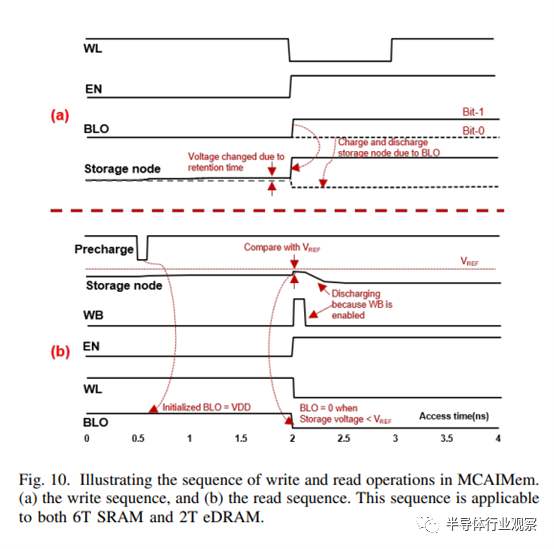
基准电压和刷新控制器
如图 10(b)所示,我们改进的 2T eDRAM 的读操作允许停用回写(WB:write-back)信号。由于位线电压的存在,存储节点可以充电或再充电,因此 MCAIMem 的刷新操作与执行读操作一样简单。
我们的混合单元存储器设计采用了 2T eDRAM,它需要周期性刷新操作。我们选择了 [3] 中所述的标准定期刷新方法,也称为全局刷新操作。在这种方法中,必须在 12.57us 内对 MCAIMem 的每一行执行刷新操作。详细地说,普通刷新周期间隔是用刷新时间除以行数计算得出的。由于采用了单增强编码器,用于存储 DNN 数据的静态功耗大大降低,但 bit-0 仍需要频繁刷新操作,以确保 DNN 数据的安全。该模块负责确定 2T eDRAM 检测放大器的参考电压,这有助于延长刷新周期,降低 DNN 数据中 0 位的动态刷新能量。参考电压的决定及其详细讨论见第 IV-B 节。
减轻 MCAIMEM下的DNN精度损失
在本节中,我们将探讨 MCAIMem 对 DNN 应用结果的影响。首先,我们将研究保留误差对 DNN 性能的影响。其次,我们将讨论为人工智能芯片上的节能 DNN 应用延长刷新周期的方法。
1
保留误差对人工智能芯片结果的影响
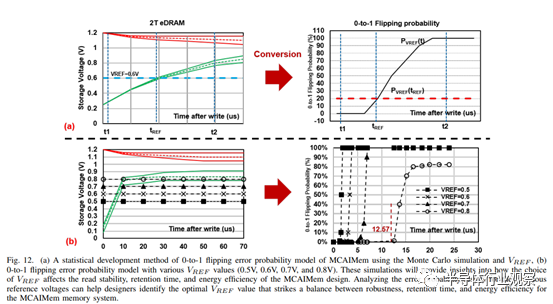
DNN 以其鲁棒性而著称,其误差通常较小,且仅发生在 LSB 中。在 MCAIMem 中,我们的内存配置由一个 SRAM 和七个 2T eDRAM 混合组成。在混合单元存储器设计中,潜在错误主要来自 2T eDRAM 的保持错误,因此有必要探讨其对 DNN 应用的影响。如图 12(b)所示,在 12.57µs 之前,2T eDRAM 在不到 1%的情况下会发生位-0 到位-1 的翻转,而在 13µs 之后,超过 25%的情况下会发生位-0 到位-1 的翻转,没有观察到位-1 的错误。因此,我们采用了错误注入方法来评估翻转错误率,并确定其对 DNN 应用准确性的影响,进而影响 MCAIMem 的刷新周期。
值得注意的是,在本研究中,保留时间问题仅限于 2T eDRAM,不影响 SRAM。因此,我们故意在每次计算之前,将误差注入 DNN 数据的权重和激活中,使误差产生累积效应。我们设计了两种方法:首先,我们将误差注入 DNN(不包括单增强编码器/解码器),在这种情况下,只有 0 位会按照预定的误差率翻转。或者,在应用一次增强编码器后、解码数据前,向第 0 位注入错误,翻转错误率从 1%到 25%不等。
我们利用 MNIST、CIFAR10、CIFAR100 和 ImageNet 等数据集,对 LeNet、VGG11、VGG16、AlexNet 和 ResNet50 等多个 CNN 进行了模拟。在语言建模方面,我们使用了 I-BERT(BERT 的整数版本)和 GLUE 数据集 。在生成建模方面,我们使用了 CycleGAN 的量化版本和 horse2zebra 数据集。这种综合评估可以揭示不同的保留误差水平对 DNN 准确性的影响程度以及 One-enhancement 方法的有效性。对于指定的每个误差率,可以比较使用 MCAIMem 和不使用 One 增强编码时 DNN 的准确性。
值得注意的是,就 GAN 而言,输出的准确性无法直接测量。因此,我们依靠平均相对误差来量化我们的 GAN 与原始模型之间的差异。这种比较有助于评估 "一个增强 "技术在多大程度上减少了保留误差对 DNN 精度的影响。
图 11 显示,如果不应用 "一个增强 "编码器/解码器,各种网络的 DNN 精度都会骤降为零。造成精度下降的原因是,SRAM 中只有签名位受到保护,而其他主位仍然容易受到保留误差的影响。然而,在实施单增强编码器/解码器后,绝大多数 MSB 位都变成了 1 位,不易发生翻转,而少量保留 0 位的 LSB 位可能会遇到保留错误。因此,AlexNet/ResNet50 上的 ImageNet、I-BERT 上的 GLUE 和 CycleGAN 上的 horse2zebra 可以容忍高达 1% 的注入误差。此外,MNIST 和 CIFAR10/100 数据集的抗错能力更强,可容许高达 25% 的保留误差。当采用一次增强技术时,MSB 中的显著位错误会被引入权值和激活值,这明显降低了推理任务的准确性。不过,事实证明这种方法有利于延长 eDRAM 的保留时间。虽然会引入位错误,但这些错误主要影响 LSB,因此不会明显影响推理过程的准确性。

在 DNN 应用中,结果是决定人工智能性能的关键。与硬件性能和能耗相比,保持 DNN 输出的准确性是一个更重要的因素。因此,我们的 MCAIMem 应符合这些要求,并在混合单元设计中考虑最多 1% 的最大保留误差。
2
利用自适应 VREF 延长刷新周期
在第 II-A 节中,我们解释了随着时间的推移,比特-0 趋向于翻转为比特-1,只有比特-0 会出现保留误差。为了使用单增强编码器保持 DNN 输出的准确性,允许的最大保持误差为 1%。因此,我们需要根据比特-0 的保持时间建立误差模型,从而确定一个能保持 DNN 输出精度的刷新时间。
在 2T eDRAM 中,泄漏电流会导致比特-0 在特定持续时间后倾向于翻转到比特-1。根据 2T eDRAM 的访问时间,这将导致位 0 读数的变化。为了计算 0 到 1 的翻转概率,我们执行了蒙特卡罗模拟,生成了大量存储 bit-0 的 2T eDRAM 的变化样本。然后,考虑到访问时间和特定参考电压 (VREF),我们计算与 2T eDRAM 样本总数相关的翻转比特数,如图 12(a)所示。这一错误翻转模型有助于确定最佳 VREF,从而在 MCAIMem 中实现稳健性、保持时间和能效之间的平衡。
我们在 85℃ 的温度下进行了 100,000 次蒙特卡罗模拟,这反映了典型的台式机和服务器工作环境,温度范围在 25-85℃ 之间 [24]。这包括评估存储节点中的数据移动,并在 0 到 20 微秒之间改变访问时间,同时读取数据。图 12.(b) 显示,当 VREF 为 0.5 时,1% 的翻转概率在 1.3 微秒时启动。相反,当 VREF 为 0.8 时,1% 的翻转概率在 12.57 微秒时开始。从图中可以看出,翻转概率斜率很陡,这意味着根据特定的 VREF 来延长刷新周期所能降低的刷新功耗微乎其微。不过,调整 VREF 可以延长所需的刷新周期。因此,我们选择 0.8V 的 VREF 来最大限度地延长比特-0 的刷新周期,并最大限度地减少混合单元存储器中的动态刷新操作。
评估
我们的研究主要涉及用于服务器和台式机应用的人工智能芯片,工作温度范围为 25 摄氏度至 85 摄氏度。我们特别没有考虑电压变化,而是通过蒙特卡洛仿真集中研究工艺变化。在本节中,我们将讨论分为两个主要部分。首先是电路仿真,然后是系统仿真。后者特别探讨了由我们提出的 MCAImem 设计驱动的 DNN 应用。
1
电路评估
在电路评估中,我们使用 CMOS 45nm 技术创建了 1MB 6T SRAM、2T eDRAM 和混合单元存储器的布局。我们根据布局尺寸计算这些嵌入式 RAM 的芯片面积,并进行比较。此外,我们还提取了这些存储器的 SPICE 模型,并进行了后仿真,以分析每种存储器类型的静态功耗、读取和写入操作。表 II. 总结了特性分析结果。
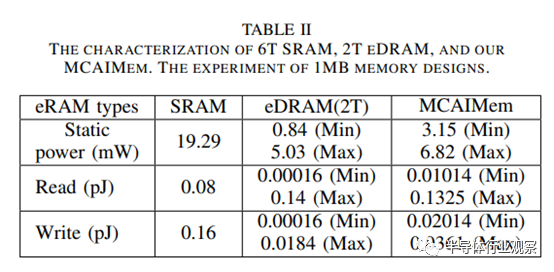
如图 13 所示,与单独的 SRAM 存储器相比,SRAM 和 eDRAM 混合设计的面积缩小了 48%。在电路仿真过程中,2T eDRAM 的非对称特性会影响存储数据值的静态功耗和访问功耗。当所有位数据都为 1 时,eDRAM 的功耗较低,因为当存储节点位于 VDD 时,漏电流大大降低。从 VDD 到存储节点的栅极漏电极小,现在的主要漏电是 PMOS 的次阈值电流。由于我们对 PMOS 存取晶体管的栅极施加了 0.4V 的三角电压,因此该电流很小。如果所有比特数据都为 0,则来自 VDD 的较高栅极漏电流会试图将存储节点充电到比特-1。因此,单增强技术增加了位-1 的位数,这对降低 2T eDRAM 的静态功耗至关重要。
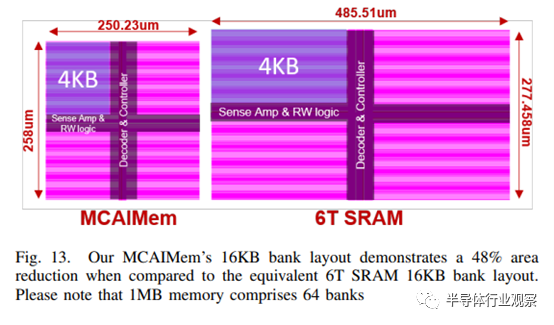
与 2T eDRAM 相比,我们的混合单元存储器包括一个 6T SRAM 和七个 2T eDRAM。静态功耗来自 SRAM 和 eDRAM,但与单独的 SRAM 相比,可降低 3-6 倍。在读写操作方面,6T SRAM 大部分是平衡的,而 2T eDRAM 仍然显示出不对称的特性。读取位-1 时,初始 BL 为 VDD,因此感应放大器没有变化,从而实现了低能耗。相反,当读取位-0 时,存储节点必须重新充电至 0,来自存储节点的电流是造成能耗的主要因素。
2
系统评估
本评估旨在通过模拟 LeNet、VGG11、VGG16、AlexNet 和 ResNet-50 等不同 CNN 网络,以及 MNIST、CIFAR10/100 和 ImageNet 等数据集,确定 MCAImem 对 DNN 应用的影响。此外,我们还对语言网络 I-BERT 和生成网络 CycleGAN 进行了模拟。考虑到 Eyeriss 和 Google TPUv1 的配置,我们修改了 SCALE-Sim ,以估算每个内存设备的静态和动态能耗。为了使我们的功耗模型适应各种设备配置,我们根据它们的内存要求进行了调整。具体来说,对于需要 108KB SRAM 的 Eyeriss,我们修改了嵌入式 RAM 功率模型,将其减少到原来 1MB 内存设备配置的十分之一。
相反,对于需要 8MB 的 Google TPUv1,我们将嵌入式 RAM 功率模型提高了 8 倍。关于 RRAM 模型,我们采用了 [34] 中的模型,假设权重和激活都利用 RRAM 作为片上缓冲区。这反映了与 Eyeriss 和 TPUv1 配置相关的内存大小调整。此外,考虑到 RRAM 的非易失性内存可以在不丢失数据的情况下切换开关,我们没有将静态功耗归因于 RRAM,而只考虑了每字节的读写能耗。
在这项以仿真为中心的研究中,我们提取了每种设备配置的计算时间,并假定其时钟频率为 100 MHz。在确定每种存储器类型的计算时间后,我们应用各自的功率模型计算最终的静态和动态能量。我们采用 6T SRAM 和传统 2T eDRAM(不含一个增强编码器/解码器)作为基准比较。我们的评估严格按照片上缓冲性能进行,有意忽略了与 MAC 操作相关的能耗。我们选择的时钟频率为 100MHz,与人工智能加速器中观察到的最慢运行时钟频率一致--以 100MHz 的 Eyeriss 和 700MHz 的 TPUv1 为例。所选的时钟频率不仅决定了跨层访问和保持内存的时间,而且由于我们使用的是 eDRAM,必须进行刷新操作以保护数据,因此这一时钟频率也是必不可少的。因此,时钟频率对于估算人工智能加速器计算过程中所需的刷新操作次数至关重要。
利用 SCALE-SIM 技术,我们可以量化时钟周期的数量。由于采用了合成阵列设计,每个时钟周期都能同时促进 MAC 和内存访问,从而简化了片上内存访问的统计。图 15 描述了可实现的最小功耗节省。有趣的是,由于采用了更快的时钟频率,每层的数据保留时间被截断,这可能会导致计算进行时刷新操作的次数减少,从而导致功耗降低。
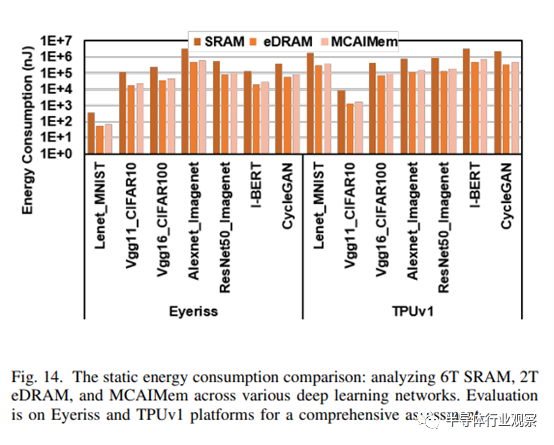
在静态功耗方面,SRAM 的能耗高于 2T eDRAM 和我们的混合电池存储器。虽然我们的混合电池存储器的静态能耗高于 2T eDRAM,但其性能却优于 SRAM。在 SRAM/eDRAM 比例为 1/7 的情况下,混合单元存储器中 SRAM 的固定能源开销占总能耗的 76.5%。更多详情可参见图 14。
至于刷新功耗,SRAM 不需要刷新操作,而 2T eDRAM 和我们的混合单元存储器则需要。如第 IV-B 节所述,调整参考电压 (VREF ) 可以帮助延长刷新周期,减少刷新操作。我们选择了带有电流模式检测放大器的传统 2T eDRAM,并对混合单元存储器中电压模式检测放大器的 VREF 值[0.5、0.6、0.7、0.8]进行了实验。图 15.(a) 表明,适当的 VREF 值可显著降低刷新能量。因此,我们选择的 0.8 VREF 值产生了最低的刷新操作,因为它将刷新周期延长了近 10 倍,从 1.3us 延长到 12.57us。
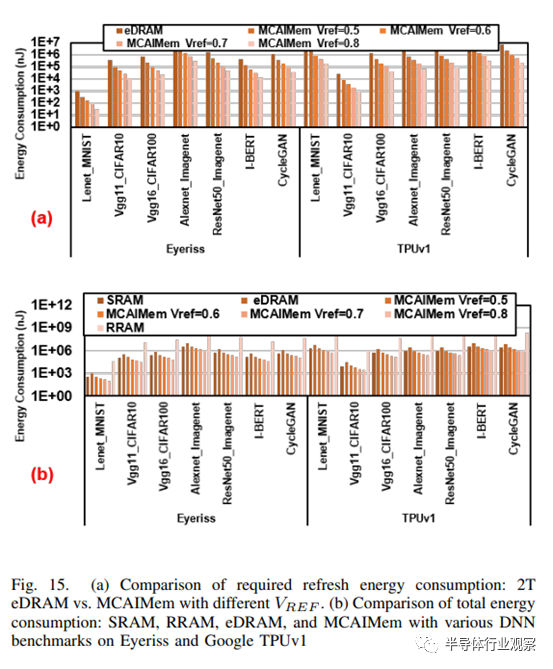
关于总能耗(包括整个推理过程中的静态和动态能耗),eDRAM 占地面积小,但由于其刷新能耗要求,在总体能耗方面并不突出。相反,我们的混合单元存储器在面积占用最小化和能耗降低方面都具有优势,能效比 6T SRAM 高出 3.4 倍,如图 15...(b)所示。不过,RRAM 的能效比 SRAM 低 100 多倍,这是因为它需要进行大量写入操作。
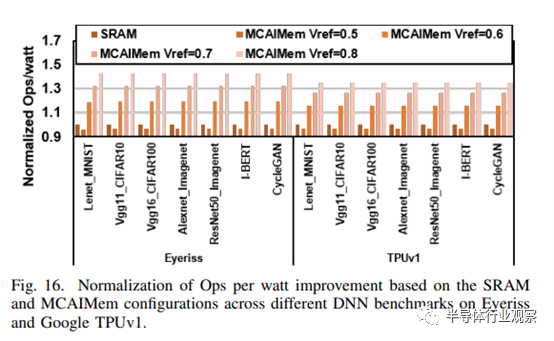
鉴于片上缓冲区在 Eyeriss 和 TPUv1中分别占 42.5% 和 37% 的功耗,使用 VREF =0.8 的 MCAIMem 配置可使每瓦性能提高 35.4% 到 43.2% 的峰值,超过采用 SRAM 的片上缓冲区的效率,如图 16 所示。因此,MCAIMem 是一种引人注目的解决方案,有可能为高效人工智能存储器设计的创新铺平道路。
相关工作
深度神经网络(DNN)需要大量内存才能实现卓越性能,这导致内存需求增加。解决对片上数据缓冲区和数据移动的更高要求对于提高 DNN 加速器性能至关重要。Chen 等人的研究表明,与 ALU 相比,片外 DRAM 访问的能耗高出 200 倍,访问时间也更长。因此,优化片上缓冲区已成为提高 DNN 加速器吞吐量的首要挑战。问题的关键在于如何最大限度地提高片上存储器容量,同时最小化片外访问,以提高 DNN 加速器的能效。
DaDianNao 建议在传统 DNN 加速器中用全 eDRAM(1T1C)取代 SRAM,以显著提高片上缓冲区容量。然而,这种方法需要定期刷新以维护 DNN 数据,从而导致大量能耗--占 DNN 加速器总能耗的 38.3%。RANA 是一种较新的技术,它利用了与 eDRAM 保留时间相比较短的激活数据寿命,从而消除了不必要的刷新操作。随着 DNN 应用的发展,这一观点可能会变得不那么适用,从而导致激活数据增加,并有可能违反激活数据生命周期约束。
为了提高吞吐量,有人提出了内存计算(CIM)来替代传统的 DNN 加速器。目前已开发出采用两个 2T eDRAM 的 4T Dual eDRAM 阵列和采用混合 SRAM 和 eDRAM 配置作为计算节点的 DualPIM [21]等技术。此外,最近的 eDRAM 节点优化侧重于减少泄漏和增强 CIM 的鲁棒性。虽然这些方法显示出显著的性能和节能效果,但对片上缓冲器的需求依然存在。
此外,一项名为 ZEM的研究探讨了 DNN 数据的异或度量特性,以延长 DNN 数据在片外 DRAM 中的保留时间,从而显著降低片外 DRAM 的功耗。然而,这项工作的主要目的是降低 DNN 应用程序处理过程中的片外 DRAM 功耗,而不是解决通过最小化片外 DRAM 访问来提高 DNN 加速器性能这一核心挑战。在本文中,我们提出了一种针对片上缓冲器的设计,通过创建混合 SRAM 和 eDRAM 单元设计,最大限度地减少片上缓冲器的面积和能耗。这种方法有望用于下一代 DNN 加速器的片上缓冲器设计。
结论
本文介绍了 MCAIMem,这是一种创新的面积和能效 AI 存储器设计,它采用混合 CMOS 存储器单元设计,包括 SRAM 和 eDRAM 单元。我们优化了 SRAM/eDRAM 单元的比例,以减少面积,并利用 DNN 的数据表示和非对称 eDRAM 单元降低能耗。实验结果表明,与传统的 SRAM 设计相比,我们的 MCAIMem 设计可将面积减少 48%,能耗降低 3.4 倍,而且不会牺牲精度。这项工作凸显了混合 CMOS 存储单元和非对称 2T eDRAM 单元在实现人工智能存储器设计的性能、面积和能耗优化平衡方面的潜力。总之,我们的混合 CMOS 单元存储器设计 MCAIMem 提供了一种前景广阔的解决方案,有望成为高效人工智能存储器设计的新标准。
致谢本文作者:Duy-Thanh Nguyen, Abhiroop Bhattacharjee, Abhishek Moitra, Priyadarshini Panda
原文链接
https://arxiv.org/abs/2312.03559
审核编辑:刘清
-
编码器
+关注
关注
45文章
4013浏览量
143414 -
存储器
+关注
关注
39文章
7758浏览量
172245 -
缓冲器
+关注
关注
6文章
2236浏览量
49059 -
sram
+关注
关注
6文章
834浏览量
117735 -
人工智能芯片
+关注
关注
1文章
124浏览量
31106
原文标题:替代昂贵的SRAM
文章出处:【微信号:光刻人的世界,微信公众号:光刻人的世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相变存储器 (PCM) 技术介绍
【案例5.1】存储器选型的考虑要点

ReRAM:AI时代的潜力存储技术
VTI低功耗SRAM存储器VTI508HB08
SK海力士在CES 2026展示面向AI的下一代存储器解决方案
FZH120 一种存储器交换LED显示控制的驱动芯片
芯源的片上存储器介绍
QSPI PSRAM伪静态随机存储器选型攻略
OTP存储器在AI时代的关键作用

AI驱动存储产业变革,GMIF2025峰会引领产业创新方向

AI应用,创新赋能!第四届GMIF2025创新峰会圆满落幕

【「AI芯片:科技探索与AGI愿景」阅读体验】+化学或生物方法实现AI
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
简单认识高带宽存储器
存储趋势前瞻:忆联如何以产品创新重塑AI时代存储价值版图



评论