 大语言模型推断中的批处理效应
大语言模型推断中的批处理效应
作者 | 陈乐群
单位 | 华盛顿大学博士生
方向 | 机器学习系统及分布式系统
来自 | PaperWeekly
随着开源预训练大型语言模型(Large Language Model, LLM )变得更加强大和开放,越来越多的开发者将大语言模型纳入到他们的项目中。其中一个关键的适应步骤是将领域特定的文档集成到预训练模型中,这被称为微调。
通常情况下,来自领域特定文档的额外知识与预训练模型已经知道的相比微不足道。在这种情况下,低秩适应(Low-Rank Adaptation,LoRA )技术证明是有价值的。
通过 LoRA,微调模型仅向预训练模型添加不到 0.1% 的参数。具体来说,这意味着 LoRA 微调模型仅增加了10~200MB 的存储,具体取决于配置。从计算角度来看,考虑到与预训练模型相比参数的增加极少,额外的计算负载相对较小。
基于存储和计算的额外开销都很小这一点,我相信构建一个多租户的大语言微调模型的推断服务具有很大潜力。这个服务可以托管成千上万个 LoRA 模型,它们都共享相同的预训练大语言模型。在每个批次的执行中,每个用户请求都会调用一个独立的微调模型,从而分摊存储和计算成本到各种不同的模型中。
在我的上一篇文章中,我深入探讨了大语言模型推断中的批处理效应。在这篇文章中,我将详细介绍为什么多租户 LoRA 推断服务具有巨大的潜力。
背景知识:文本生成
文本生成服务,如 ChatGPT,接受用户文本输入并提供文本响应。这个输入被称为“提示”(prompt)。在内部,当大语言模型处理文本时,它在一系列“词元”(token)上操作。我们可以大致将词元视为几个字符或一个单词。文本生成过程有两个主要阶段:
预填充阶段(或称“编码”,“初始化”)接受整个提示并生成随后的词元以及一个“键值缓存”(KV Cache)。
解码阶段处理新生成的词元和键值缓存,然后生成下一个词元,同时更新键值缓存。这个阶段不断重复,直到模型完成其输出。
有趣的是,尽管预填充阶段处理的词元数量比解码阶段多 100 倍,但它们的计算延迟是在同一数量级的。由于解码阶段会重复执行上百次,因此在这篇文章中,我将集中讨论如何优化解码阶段。
背景知识:大语言模型的架构和批处理
在其核心,大语言模型的架构非常简单。它主要包括多个 Transformer 层,所有层都共享相同的架构。每一层包括四个计算密集型组件:QKV 投影、自注意力、输出投影和前馈网络(Feed-Forward Network, FFN )。

▲ Transformer 层在解码阶段的运算图示
概括地说,其中包含了两种算子:
自注意力(Self-Attention,黄色标出)涉及矩阵-矩阵乘法。
密集投影(Dense Projection,绿色标出)涉及向量-矩阵乘法。
考虑到每个批次中每个序列只有一个词元,密集投影计算也非常微小,不足以充分利用 GPU 。因此,扩大批处理大小几乎不会影响密集投影的延迟,这使得大批处理大小对于构建高吞吐、低延迟的推断服务至关重要。
关于大语言模型推断中的批处理的更详细分析,请查看我的以前的博客文章。
背景知识:LoRA
给定形状为 [H1, H2] 的预训练参数矩阵 W ,LoRA 微调训练一个形状为。 [H1, R] 的小矩阵 A 和形状为 [R, H2] 的 B 。我们使用(W+AB)作为微调模型的权重。这里的 R 是 LoRA 微调指定的秩,通常远小于原始维度(>= 4096),通常在 8~32 之间。
这种方法背后的逻辑是,与原始权重相比,新增加的知识只占一小部分,因此 LoRA 将增量压缩成两个低秩矩阵。
与完全微调相比,LoRA 预训练显著降低了微调模型的存储和内存需求。
在大语言模型中,由于所有参数都位于密集投影中,LoRA 可以集成到 Transformer 层中的任何位置。虽然 HuggingFace PEFT 库仅将 LoRA 加到 q_proj 和 v_proj ,但一些研究,如 QLoRA,主张将其包含在所有的密集投影中。
LoRA 延迟和批处理效应
尽管在存储方面,LoRA 矩阵明显小于原始权重矩阵,但计算的延迟并不成比例地减少。我们可以使用以下代码对骨干模型和 LoRA 增量的延迟进行基准测试:
h1=4096 h2=11008 r=16 forbsinrange(1,33): w=torch.randn(h1,h2,dtype=torch.float16,device="cuda:0") a=torch.randn(bs,h1,r,dtype=torch.float16,device="cuda:0") b=torch.randn(bs,r,h2,dtype=torch.float16,device="cuda:0") x=torch.randn(bs,1,h1,dtype=torch.float16,device="cuda:0") bench(lambda:x@w) bench(lambda:x@a@b)
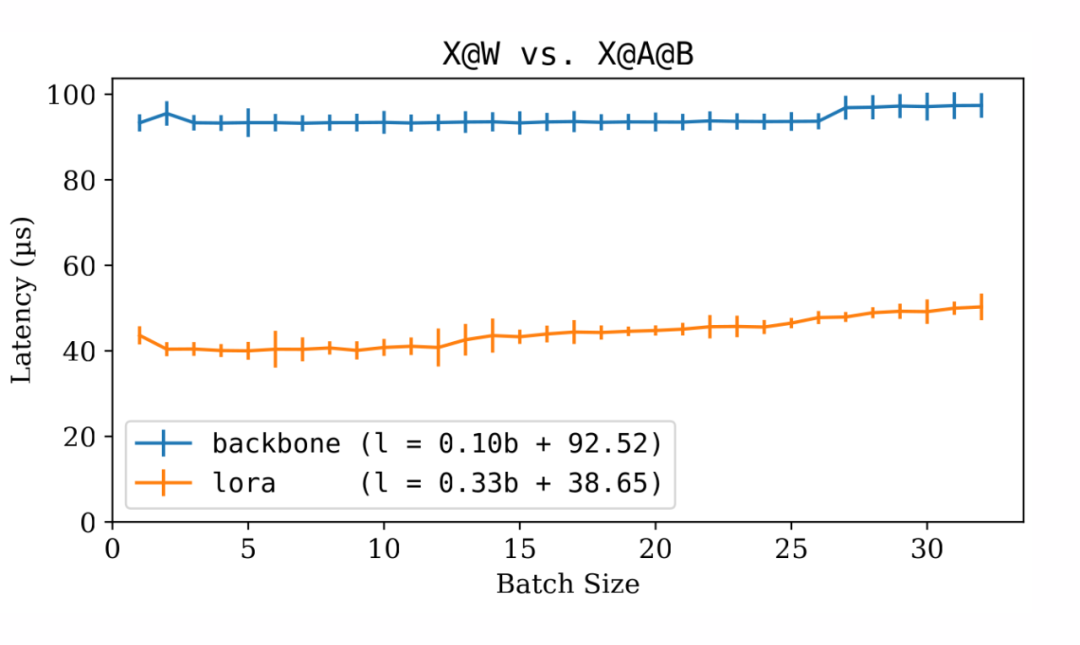
▲ 骨干大语言模型和 LoRA 微调模型的推断延迟比较
上图表明,LoRA 增量仅比骨干模型快 2.5 倍。
然而,显然 LoRA 批处理效应与骨干模型的效应相似。批处理大小的增加仅在较小程度上影响延迟。这个特性使得多租户 LoRA 非常可行。
在骨干模型中,所有一个批次中的所有请求都针对同一模型。而在多租户 LoRA 服务中,一个批次中的请求可能会调用不同的 LoRA 微调模型。数学表达如下:
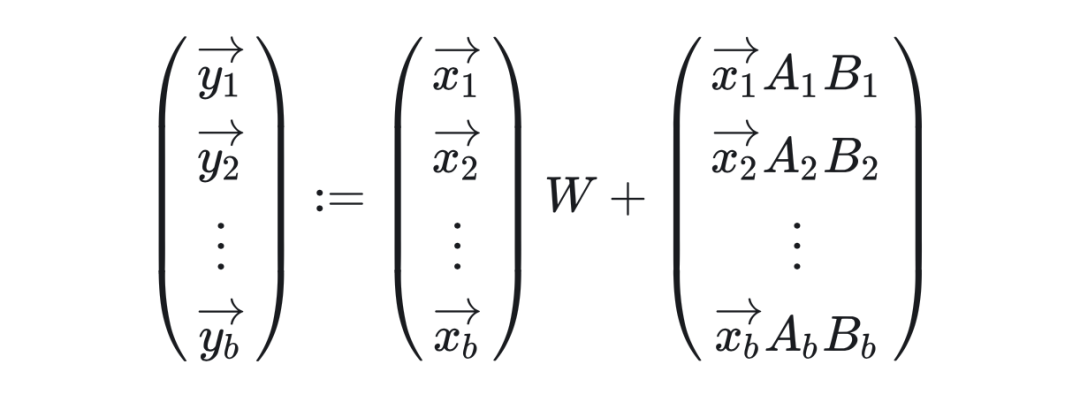
挑战在于以批处理的方式将不同的 LoRA 增量应用于一个批处理中的各个输入,与此同时还要维持“白吃的午餐”式的批处理效应。
批处理 LoRA 算子
我们想要的批处理 LoRA 算子具有以下函数签名:
defadd_lora( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) A:torch.Tensor,#(num_loras,in_features,lora_rank) B:torch.Tensor,#(num_loras,lora_rank,out_features) I:torch.LongTensor,#(batch_size,) ): """Semantics:y[i]+=x[i]@A[I[i]]@B[I[i]]""" raiseNotImplementedError()
一个最简单的实现方法是在批处理维度上进行循环:
deflora_loop( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) A:torch.Tensor,#(num_loras,in_features,lora_rank) B:torch.Tensor,#(num_loras,lora_rank,out_features) I:torch.LongTensor,#(batch_size,) ): fori,idxinenumerate(I.cpu().numpy()): y[i]+=x[i]@A[idx]@B[idx]
让我们对循环版本进行基准测试。为了进行比较,我们可以包括一个“作弊”实现,其中我们假设批处理中每个请求的 LoRA 矩阵已经被合并在一起。这样,我们只测量批量矩阵乘法(Batched Matrix Multiplication, bmm)的延迟。
deflora_cheat_bmm( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) cheat_A:torch.Tensor,#(batch_size,in_features,lora_rank) cheat_B:torch.Tensor,#(batch_size,lora_rank,out_features) ): y+=x@cheat_A@cheat_B num_loras=50 h1=4096 h2=11008 r=16 A=torch.randn(num_loras,h1,r,dtype=torch.float16,device="cuda:0") B=torch.randn(num_loras,r,h2,dtype=torch.float16,device="cuda:0") forbsinrange(1,33): x=torch.randn(bs,1,h1,dtype=torch.float16,device="cuda:0") y=torch.randn(bs,1,h2,dtype=torch.float16,device="cuda:0") I=torch.randint(num_loras,(bs,),dtype=torch.long,device="cuda:0") cheat_A=A[I,:,:] cheat_B=B[I,:,:] bench(lambda:lora_loop(y,x,A,B,I)) bench(lambda:lora_cheat_bmm(y,x,cheat_A,cheat_B))
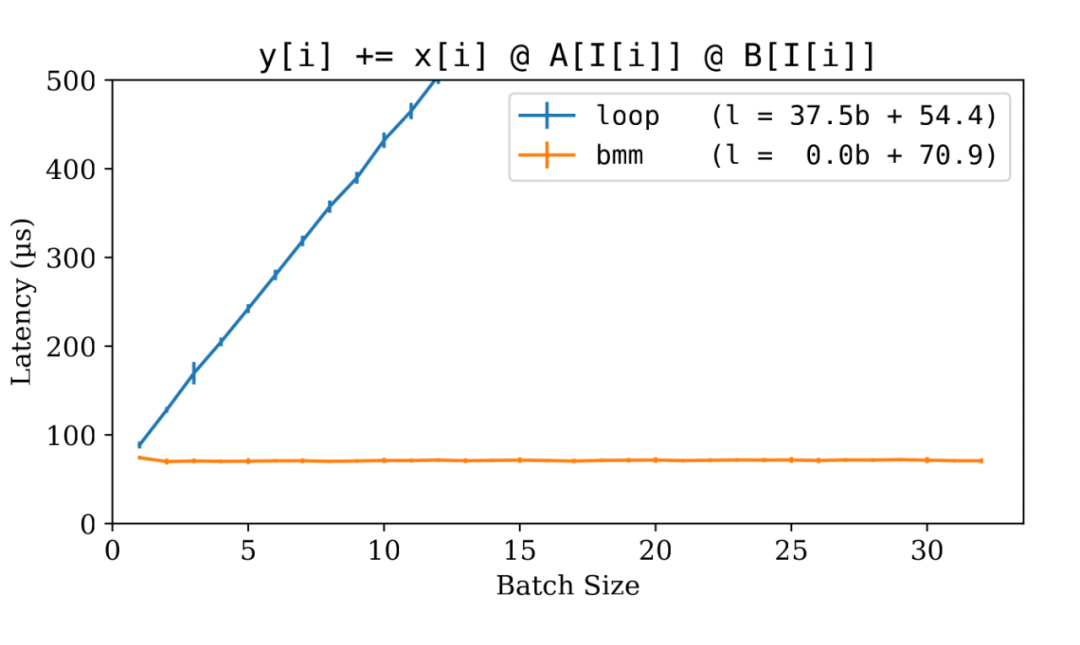
▲ LoRA 实现:for-loop vs bmm
可预见的是,循环版本明显较慢,并且失去了批处理效应。这是因为它逐个处理输入,而不是利用为批处理数据设计的高效 CUDA 核心。
然而, bmm 方法提供了一个很好的启发。我们的目标变得清晰起来:首先将所有 LoRA 矩阵汇总到一个临时的张量中,然后使用 bmm 。经过一番挖掘,我发现了 torch.index_select() 函数,它可以高效地执行批量汇总(Batched Gather)。于是我们可以如下一个 gbmm( gather-bmm )实现:
deflora_gbmm( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) A:torch.Tensor,#(num_loras,in_features,lora_rank) B:torch.Tensor,#(num_loras,lora_rank,out_features) I:torch.LongTensor,#(batch_size,) ): a=torch.index_select(A,0,I)#(batch_size,in_features,lora_rank) b=torch.index_select(B,0,I)#(batch_size,lora_rank,out_features) y+=x@a@b
BGMV 算子
虽然 gbmm 非常有效,但它并不是最终解决方案。我们没有必要仅仅是因为 bmm 需要连续的存储而将 LoRA 增量而汇总到一个连续的空间中。理想情况下,聚合可以在 CUDA 核心内部进行,于 bmm 操作同事进行。如果可能的话,这将消除与 torch.index_select() 相关的 GPU 内存读写操作。
我请叶子豪大牛帮忙,他是精通高性能 CUDA 核心的编写。经过几轮迭代,子豪开发了一个非常快的 CUDA 程序,把 LoRA 所需的计算分成两半。我们将这个算子命名为 BGMV(Batched Gather Matrix-Vector Multiplication):
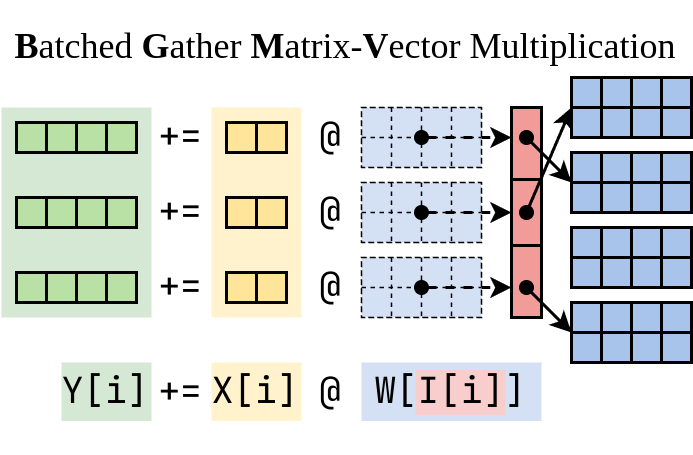
▲ Batched Gather Matrix-Vector Multiplication (BGMV)
deflora_bgmv( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) A:torch.Tensor,#(num_loras,in_features,lora_rank) B:torch.Tensor,#(num_loras,lora_rank,out_features) I:torch.LongTensor,#(batch_size,) ): tmp=torch.zeros((x.size(0),A.size(-1)),dtype=x.dtype,device=x.device) bgmv(tmp,x,A,I) bgmv(y,tmp,B,I)
这是 gbmm 和 bgmv 的基准结果:
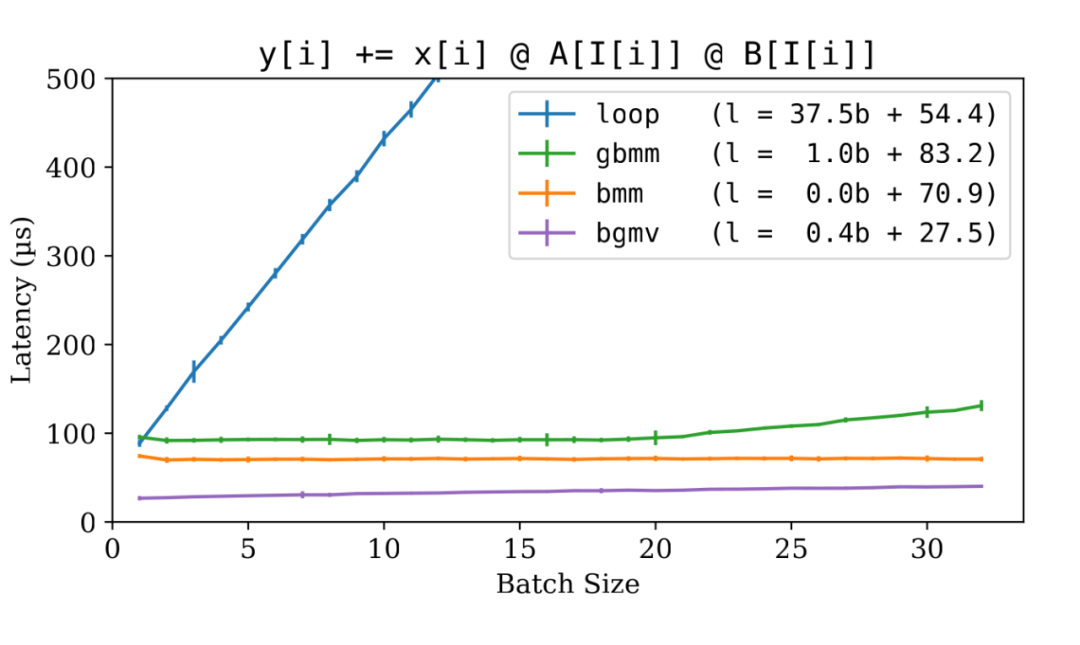
▲ LoRA 实现: for-loop vs bmm vs gbmm vs bgmv
如图所示, gbmm 非常有效。聚合过程相对于 bmm 增加了约 20% 的延迟,但保持了令人满意的批处理效应。而子豪编写的 bgmv 算子更加高效,甚至超过了 bmm 。
多租户 LoRA 文本生成性能
在 bgmv 算子的基础上,我开发了一个名为Punica的实验项目,支持多个 LoRA 模型。Punica 的独特能力是能把不同 LoRA 模型的请求合并在一个批处理中。我对比了 Punica 和一系列知名系统的性能,包括 HuggingFace Transformers、DeepSpeed、Faster Transformer 和 vLLM。
在测试中,每个请求都针对不同的 LoRA 模型。鉴于其他系统没有明确针对多租户 LoRA 服务进行优化,它们的批处理大小为 1。我使用了 HuggingFace PEFT库来把 LoRA 加到 HuggingFace Transformers 和 DeepSpeed 中。我尚未调整 vLLM 和 Faster Transformer,所以它们在没有 LoRA 的情况下运行。以下是结果:
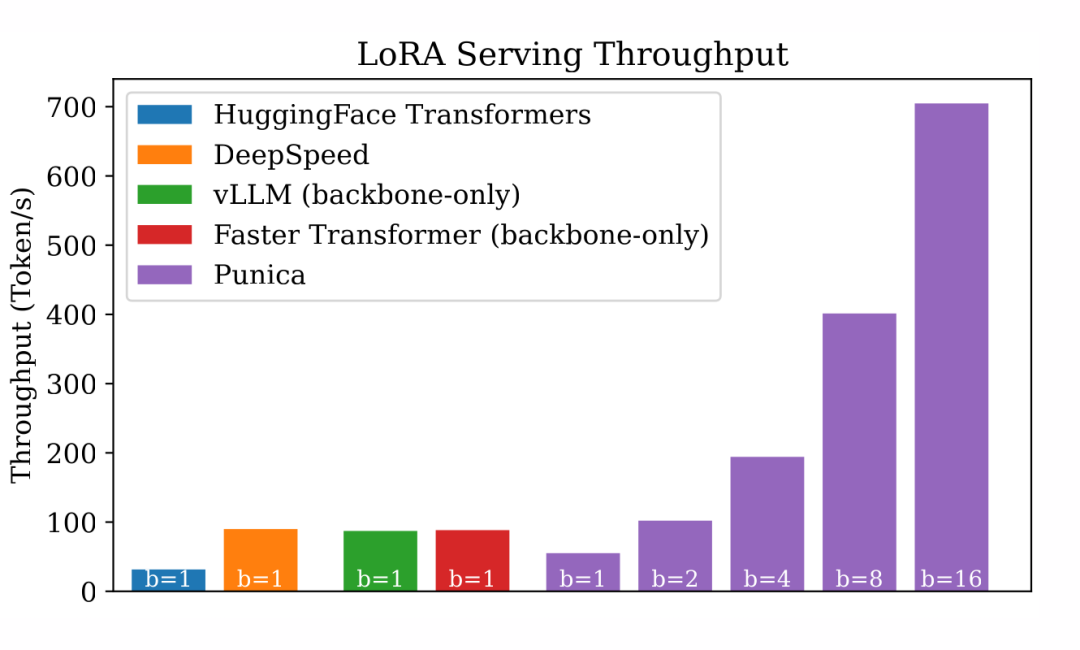
▲ 多租户 LoRA 文本生成的吞吐量
DeepSpeed、vLLM 和 Faster Transformers 都有高度优化的 Transformer 实现,这些系统的吞吐量比标准的 HuggingFace Transformers 高出 3 倍。但由于批处理大小被限制在 1,它们在多租户 LoRA 服务效率方面表现不佳。
相反,Punica 在批处理大小为 16 时比这些系统高出 8 倍,与普通的 HuggingFace Transformers 相比,甚至高达 23 倍。值得注意的是,Punica 的吞吐量几乎与批处理大小呈线性关系。
值得注意的是,Punica 仍然是一个早期的研究原型。它目前使用与普通的 HuggingFace Transformers 相同的 Transformer 实现,除了 LoRA 和自注意力运算符。一些已知的 Transformer 层的优化在 Punica 中尚未实现。这解释了在批处理大小为 1 时 Punica 与其他高度优化的系统之间的性能差距。
吞吐量不错,那么从延迟方面表现如何?
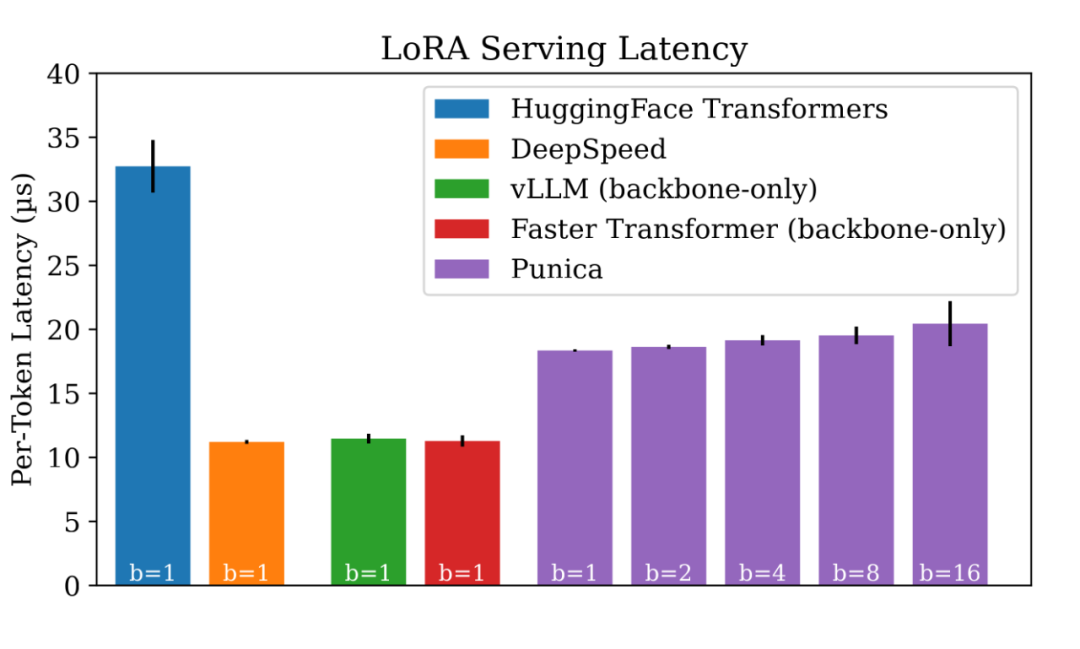
▲ 多租户 LoRA 文本生成的延迟
如图所示,Punica 中的批处理不会引入显著的延迟。
示例用途
在展示了多租户 LoRA 服务的高效性后,让我们设想一些潜在的应用场景:
用一本新的小说对 LoRA 模型进行细调,以帮助读者总结每个角色的旅程。
针对迅速发展的新闻对 LoRA 模型进行调整,以让读者了解最新动态。
基于网页内容对 LoRA 模型进行优化,提高读者的理解能力。
我将这种方法称为“即时细调”(Just-in-time Fine-tuning),因为 LoRA 的训练速度非常快(在我的试验中,每个训练周期不到一秒)。
总结
本文展示了用批处理加速多个 LoRA 微调模型并行推断的可行性。我实现的 Punica 项目展现出了关于批处理大小几乎线性的吞吐量扩展,并且增加批处理大小并不显著增加延迟。
这项研究仍然在进行中。我正在积极开展这项研究项目,预计很快会发布一个在线演示。我欢迎任何反馈或想法,请随时在评论部分中分享。
最近这几个月出来了很多非常棒的开源大语言模型。要让开源预训练模型能更好的跑在我们要做的事情上,我们可以对这些预训练模型进行微调。LoRA 是一种非常高效的微调技术,哪怕预训练模型要占好几百 GB 空间,用 LoRA 进行微调也只需要增加 1% 左右的空间。
这里我先简单概括一下 LoRA 是怎么做的。假设预训练模型有一个形状是 [H1, H2] 的参数矩阵 W ,用 LoRA 进行微调的时候,我们会增加两个小矩阵, [H1, r] 的的矩阵 A ,以及 [r, H2] 的矩阵 B, H1 和 H2 远大于 r 。
举个 Llama2-7B 的例子, H1=4096, H2=11008 ,而我们只需要设置 r=16 就能获得还不错的效果。在计算的时候,我们把 W+AB 作为微调后的参数。对于给定一个输入 x ,计算微调模型就是 y := x @ (W + A@B) ,等价于 y := x@W + x@A@B 。
当我们有 n 个 LoRA 微调模型的时候,我们就会有一堆小矩阵, A1, B1, A2, B2, ..., An, Bn 。对于一个输入 batch X := (x1,x2,..,xn) ,我们假设 batch 其中的每一个输入都对应一个 LoRA 微调模型,那么这个 batch 的计算结果就是 Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) 。
注意到这个加法的左边就是直接把这个 batch 输入给原来的预训练模型。我们知道预训练模型 batch 起来跑其实是很快的,因为大语言模型有很强的批处理效应(我之前有发过一篇知乎讲这个事情: 剖析 GPT 推断中的批处理效应。)所以这里的难题就是,右手边这一项 LoRA 要怎么高效的计算?
我们最近做了一个项目叫做 Punica,能够非常高效的计算右边这一项,延迟非常低,而且保留了和预训练模型一样的很强的批处理效应。我们实现了一个 CUDA kernel,叫做 SGMV,用来把 LoRA 这部分的计算 batch 起来算。下面这个图介绍了 SGMV 的语义:
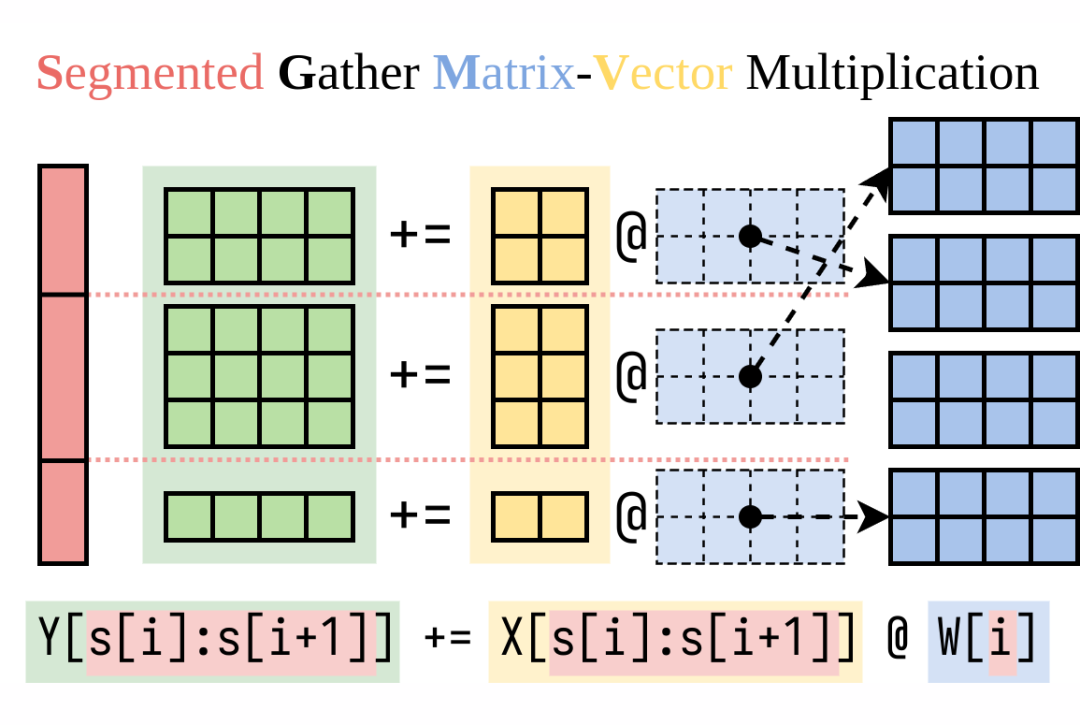
▲ SGMV 的语义
我们测了一下性能,从下面这张图可以看出来三个事情。(1)预训练模型有很强的批处理效应,增加批处理大小不会显著增加延迟。(2)用简单的方法计算 LoRA 跑起来非常慢,而且破坏了这个批处理效应。(3)我们用 SGMV 计算 LoRA 非常地快,而且保留了很强的批处理效应。
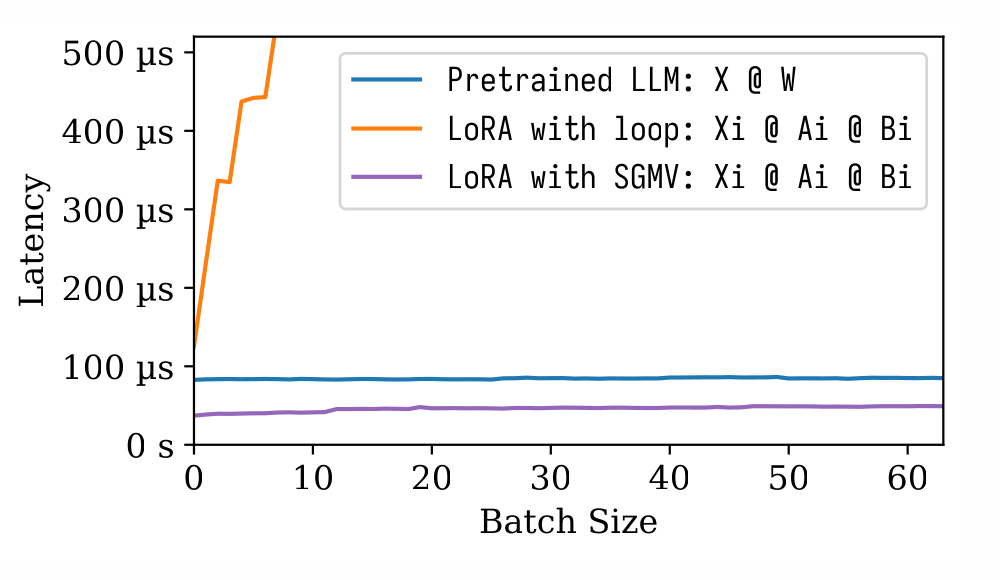
▲ 算子的性能测试
我们还跟主流的大语言模型系统做了比较了一下文本生成的性能,包括 HuggingFace Transformers, DeepSpeed, FasterTransformer, vLLM。我们考虑了 4 种不同的运行场景。
Distinct 是每一个输入对应一个不同的 LoRA 微调模型,Identical 是所有的输入都指向同一个 LoRA 微调模型(也就是整个系统只有一个模型),Uniform 和 Skewed 介于两者之间,也就是有的 LoRA 微调模型更热门一点,有的 LoRA 微调模型更冷门一点。从下面这个图中我们可以看出,Punica 可以达到 12 倍于现有系统的吞吐量。
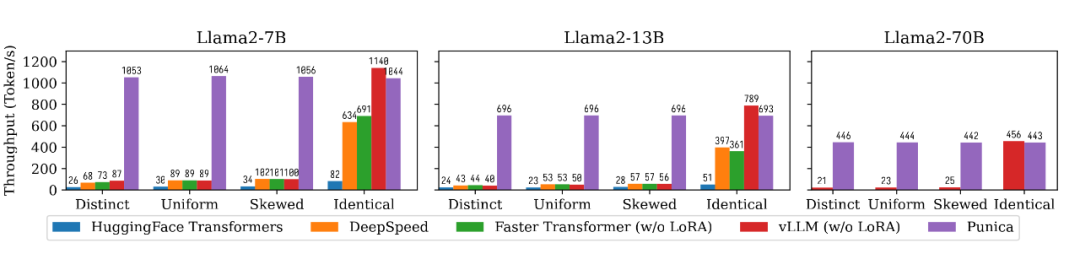
▲ 文本生成的性能比较
审核编辑:汤梓红
-
语言模型
+关注
关注
0文章
547浏览量
10385 -
机器学习
+关注
关注
66文章
8458浏览量
133295 -
LoRa
+关注
关注
349文章
1709浏览量
232840 -
ChatGPT
+关注
关注
29文章
1578浏览量
8216
原文标题:用跑1个LoRA微调大语言模型的延迟跑10个!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
GPT推断中的批处理(Batching)效应简析
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】大语言模型的评测
大语言模型:原理与工程时间+小白初识大语言模型
基于python的批处理方法
推断FP32模型格式的速度比CPU上的FP16模型格式快是为什么?
批处理常用命令大全






 工商网监
工商网监
评论