 8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。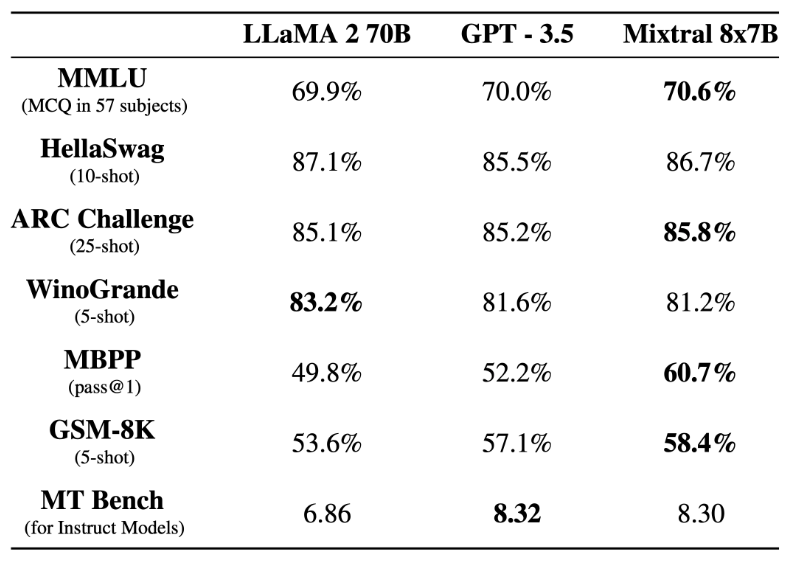
 ▲图源 https://mistral.ai/news/mixtral-of-experts/
▲图源 https://mistral.ai/news/mixtral-of-experts/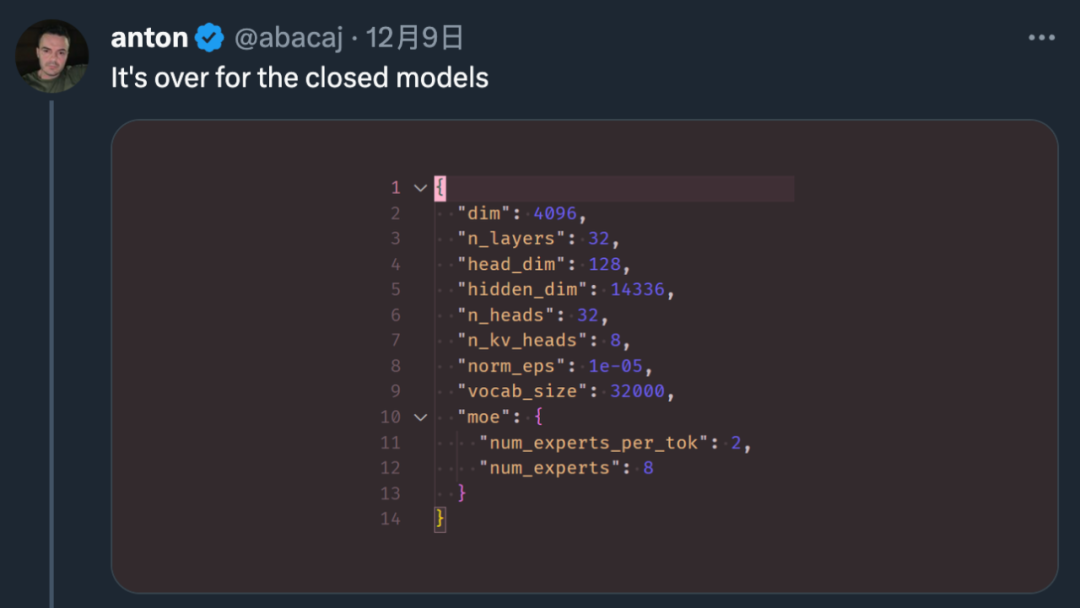
 ▲图源 https://twitter.com/reach_vb/status/1741175347821883502
▲图源 https://twitter.com/reach_vb/status/1741175347821883502 第三步是初始化 TextStreamer:
第三步是初始化 TextStreamer:
 第四步对输入进行 Token 化:
第四步对输入进行 Token 化:
 第五步生成:
第五步生成:
 当你配置好项目后,就可以与 Mixtral 进行对话,例如对于用户要求「如何做出最好的美式咖啡?通过简单的步骤完成」,Mixtral 会按照 1、2、3 等步骤进行回答。
当你配置好项目后,就可以与 Mixtral 进行对话,例如对于用户要求「如何做出最好的美式咖啡?通过简单的步骤完成」,Mixtral 会按照 1、2、3 等步骤进行回答。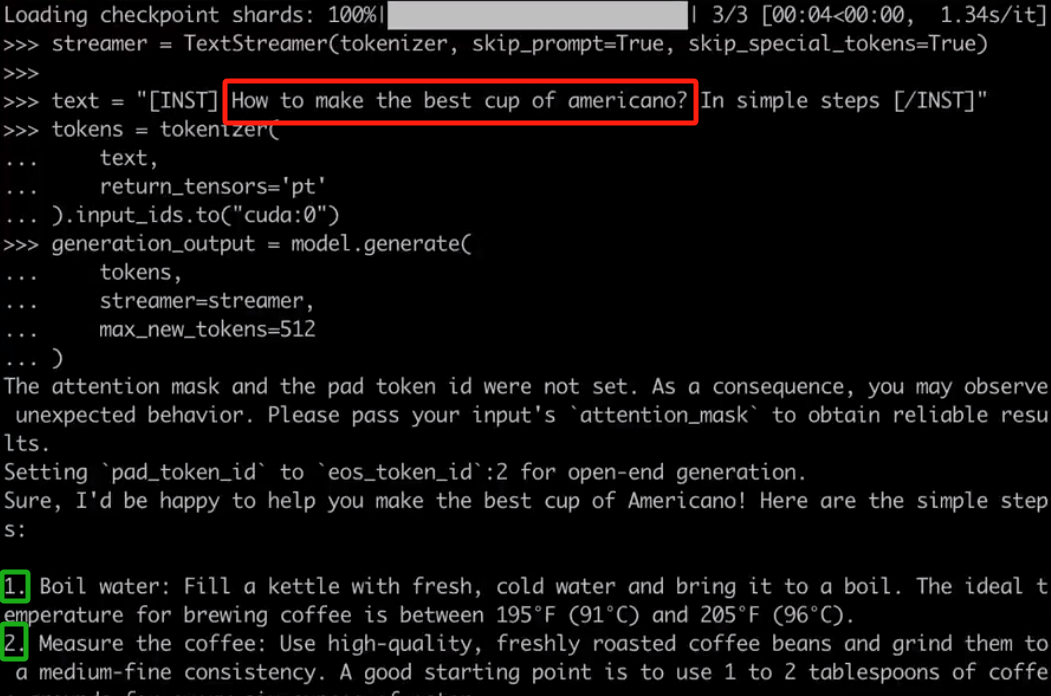


我们都知道,OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。Mistral 8x7B 的放出,无疑给广大开发者提供了一种「非常接近 GPT-4」的开源选项。
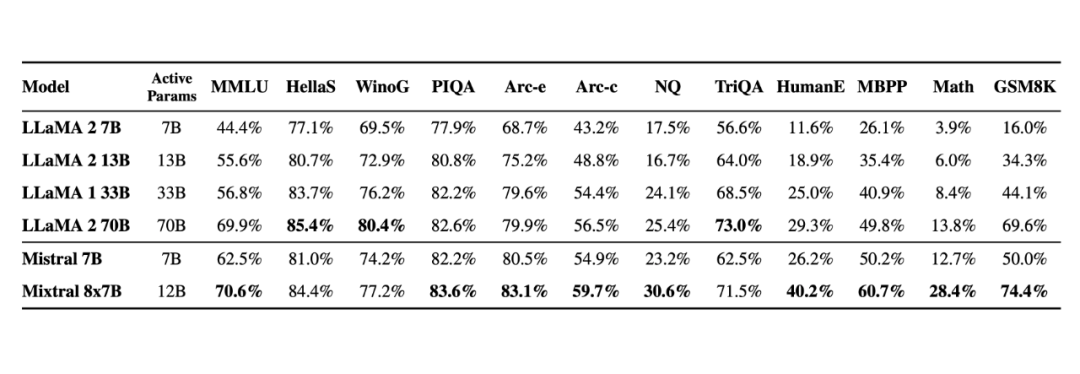
在基准测试中,Mistral 8x7B 的表现优于 Llama 2 70B,在大多数标准基准测试上与 GPT-3.5 不相上下,甚至略胜一筹。
▲图源 https://mistral.ai/news/mixtral-of-experts/随着这项研究的出现,很多人表示:「闭源大模型已经走到了结局。」
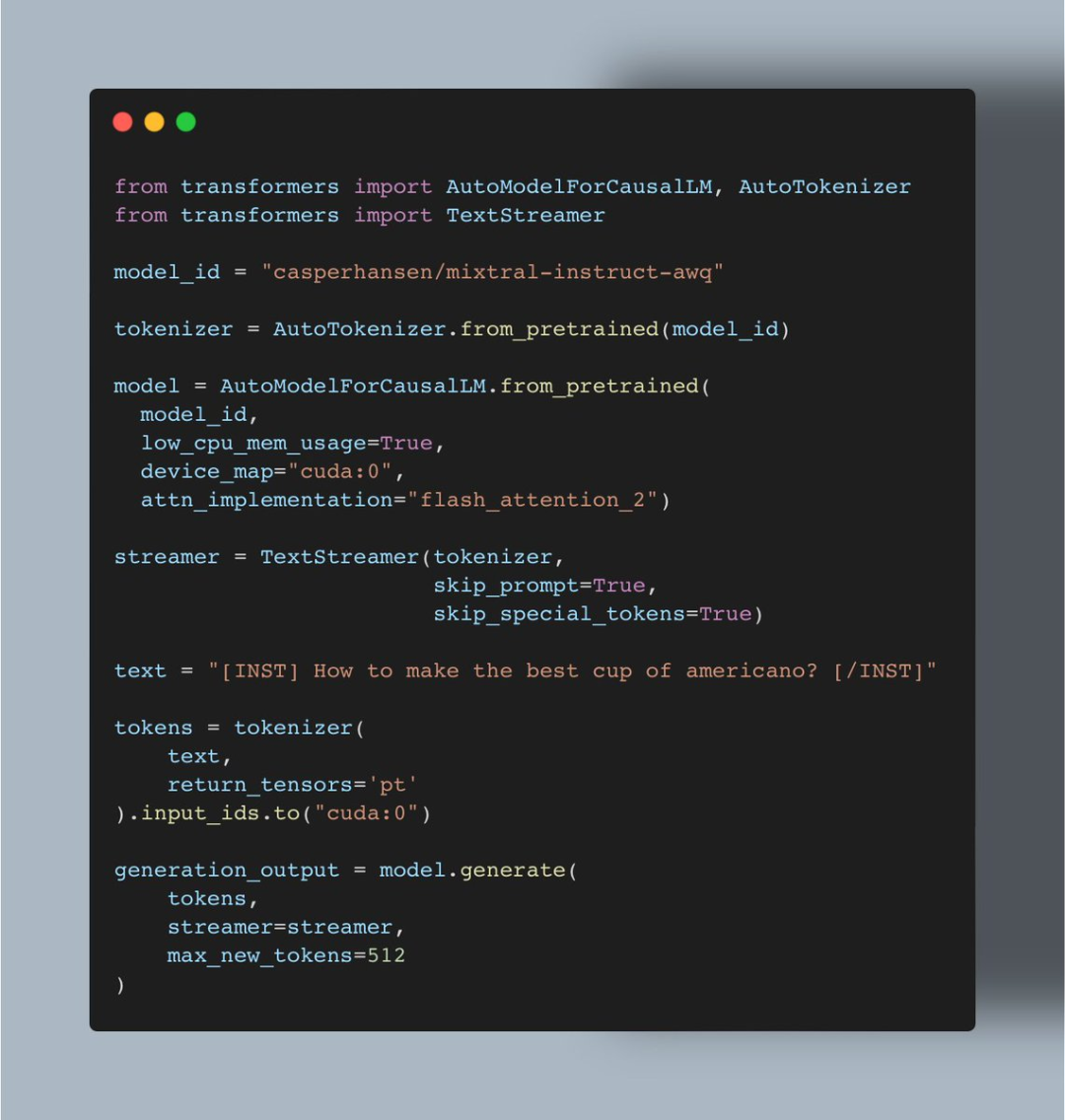
短短几周的时间,机器学习爱好者 Vaibhav (VB) Srivastav 表示:随着 AutoAWQ(支持 Mixtral、LLaVa 等模型的量化)最新版本的发布,现在用户可以将 Mixtral 8x7B Instruct 与 Flash Attention 2 结合使用,达到快速推理的目的,实现这一功能大约只需 24GB GPU VRAM、不到十行代码。
▲图源 https://twitter.com/reach_vb/status/1741175347821883502
AutoAWQ地址:
https://github.com/casper-hansen/AutoAWQ 操作过程是这样的: 首先是安装 AutoAWQ 以及 transformers:
pipinstallautoawqgit+https://github.com/huggingface/transformers.git
第二步是初始化 tokenizer 和模型:
第三步是初始化 TextStreamer:
第四步对输入进行 Token 化:
第五步生成:
当你配置好项目后,就可以与 Mixtral 进行对话,例如对于用户要求「如何做出最好的美式咖啡?通过简单的步骤完成」,Mixtral 会按照 1、2、3 等步骤进行回答。
项目中使用的代码:
Srivastav 表示上述实现也意味着用户可以使用 AWQ 运行所有的 Mixtral 微调,并使用 Flash Attention 2 来提升它们。 看到这项研究后,网友不禁表示:真的很酷。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
代码
+关注
关注
30文章
4813浏览量
68838 -
GPT
+关注
关注
0文章
354浏览量
15448 -
OpenAI
+关注
关注
9文章
1108浏览量
6605
原文标题:8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Flexus X 实例 C#/.Net Core 结合(git 代码管理、docker 自定义镜像)快速发布部署 - 让你的项目飞起来~
前言 ���云端部署新体验,C# Web API 遇上 Git Docker,828 B2B 企业节特惠来袭!Flexus X 实例,为您的 C#应用提供强大支撑,结合 Git 版本控制

猎户星空发布Orion-MoE 8×7B大模型及AI数据宝AirDS
近日,猎户星空携手聚云科技在北京共同举办了一场发布会。会上,猎户星空正式揭晓了其自主研发的Orion-MoE 8×7B大模型,并与聚云科技联合推出了基于该大模型的数据服务——AI数据宝AirDS
CC13x2x7和CC26x2x7 SimpleLink无线MCU技术参考手册
电子发烧友网站提供《CC13x2x7和CC26x2x7 SimpleLink无线MCU技术参考手册.pdf》资料免费下载
发表于 11-14 14:16
•0次下载

阿里Qwen2-Math系列震撼发布,数学推理能力领跑全球
阿里巴巴近期震撼发布了Qwen2-Math系列模型,这一系列模型基于其强大的Qwen2 LLM构建,专为数学解题而生,展现了前所未有的数学推理能力。Qwen2-Math家族包括1.5
PerfXCloud顺利接入MOE大模型DeepSeek-V2
今日,在 PerfXCloud 重磅更新支持 llama 3.1 之后,其平台再度实现重大升级!目前,已顺利接入被誉为全球最强的 MOE 大模型 DeepSeek-V2 ,已在 PerfXCloud(澎峰云)官网的体验中心对平台
Verilog:【8】基于FPGA实现SD NAND FLASH的SPI协议读写
校验 2Bytes
** 6 模块代码**
本代码所实现的功能,是基于黑金AX301B,实现
发表于 06-21 17:58
ESP32-S2能否支持8位串行RGB?
看ESP32-S2手册上写的是支持8位串口RGB的。但是在编译esp-idf master代码时出错。
我有一片LCD是8位串行RGB接口(
发表于 06-17 06:17
昆仑万维开源2千亿稀疏大模型Skywork-MoE
近日,昆仑万维公司宣布开源一款名为Skywork-MoE的稀疏大模型,该模型拥有高达2千亿参数,不仅性能强劲,而且推理成本更低,为人工智能领域带来了新的突破。
STM32G0B1无法操作FLASH,解锁FLASH失败的原因?
使用STM32G0B1写内部的Flash时出现问题,代码:
#pragma arm section code = \"RAMCODE\"
uint32_t
发表于 04-02 07:45
8b10b编码verilog实现
8b/10b编码是一种用于减少数据线上的低效能时钟信号传输的技术,通过在数据流中插入特殊的控制字符,来同步数据和时钟。在Verilog中实现8b/1
发表于 03-26 07:55
基于NVIDIA Megatron Core的MOE LLM实现和训练优化
本文将分享阿里云人工智能平台 PAI 团队与 NVIDIA Megatron-Core 团队在 MoE (Mixture of Experts) 大语言模型(LLM)实现与训练优化上的创新工作。

基于OpenCV DNN实现YOLOv8的模型部署与推理演示
基于OpenCV DNN实现YOLOv8推理的好处就是一套代码就可以部署在Windows10系统、乌班图系统、Jetson的Jetpack系
大模型系列:Flash Attention V2整体运作流程
基于1.1中的思想,我们在V2中将原本的内外循环置换了位置(示意图就不画了,基本可以对比V1示意图想象出来)。我们直接来看V2的伪代码(如果对以下伪代码符号表示或解读有疑惑的朋友,最好

最佳开源模型刷新多项SOTA,首次超越Mixtral Instruct!「开源版GPT-4」家族迎来大爆发
Mixtral 8x7B模型开源后,AI社区再次迎来一大波微调实践。来自Nous Research应用研究小组团队微调出新一代大模型Nous-Hermes 2 Mixtral 8x7B,在主流基准测试中击败了Mixtral In

CYT2B7 flash分区的疑问求解
在看看 CYT2B7 的手册时,对于 flash 分区有疑问。
为什么 Dual Bank 的分区中码 flash和data flashdapping A和Mapping B?使用时单
发表于 01-22 07:30





 工商网监
工商网监
评论