 GPT-4 Turbo多模态,应用生态加速
GPT-4 Turbo多模态,应用生态加速
本文来自“GPT-4精华专题:多模态能力提升,应用生态加速(2023)”,2023年11月7日,OpenAI通过开发者大会推出新产品:
1)GPT4-Turbo:该模型通过增加上下文窗口以支持更长的工作流,同时具备视觉和语音等多模态能力,输入和输出的tokens价格大幅下降,从而帮助开发者以更低的价格获取更高的模型性能。
2)GPTs:用户只需输入指令并提供外设的知识库即可创建专属GPT,应用开发门槛大幅降低,未来在收益计划的助力下,AI应用有望迎来大爆发,形成全新的AI Agent生态。
3)Assistant API:开发者可以通过函数调用、知识检索、代码解释器简化应用开发流程、实现效率提升。
《400+份重磅ChatGPT专业报告》
1)算力端:OpenAI一系列新产品的推出成功打开新流量入口,更多的用户和开发者希望参与其中,巨大的流量对算力底座提出更高的要求;叠加图片等多模态生成所要求的tokens计算量远高于文本模态(根据OpenAI官网信息推算,在GPT-4-Turbo的Vision pricing calculator高保真度模式下,1张图片所产生的tokens数大约是1个单词的570或830倍),算力供给亟需扩容。
2)存力端:在算力提效到达一定瓶颈的情况下,AI芯片未来将逐步通过堆叠HBM的方式来提升性能,扩大单位算力的存储能力,HBM等存力需求将迎来暴增。
3)应用端:类比移动互联网时代,AI时代的应用市场有望如同移动互联网时代具备无限潜力,GPTs数量将呈现非线性高速增长;此外,OpenAI的GPTs通过提供API,使得开发者只需喂给大模型更多的垂类数据即可打造垂类AI应用,同时使满足更多长尾需求成为可能。
4)数据端:从OpenAI GPTs的Knowledge功能来看,专业知识与大模型通用能力的结合将成为未来的重中之重,私域数据库和专业数据库方向将会不断产生新热点、新需求,因此,如何在合规前提下留存垂类数据并构建体系化数据库、以及保证知识产权的确权或成为未来的重要议题。

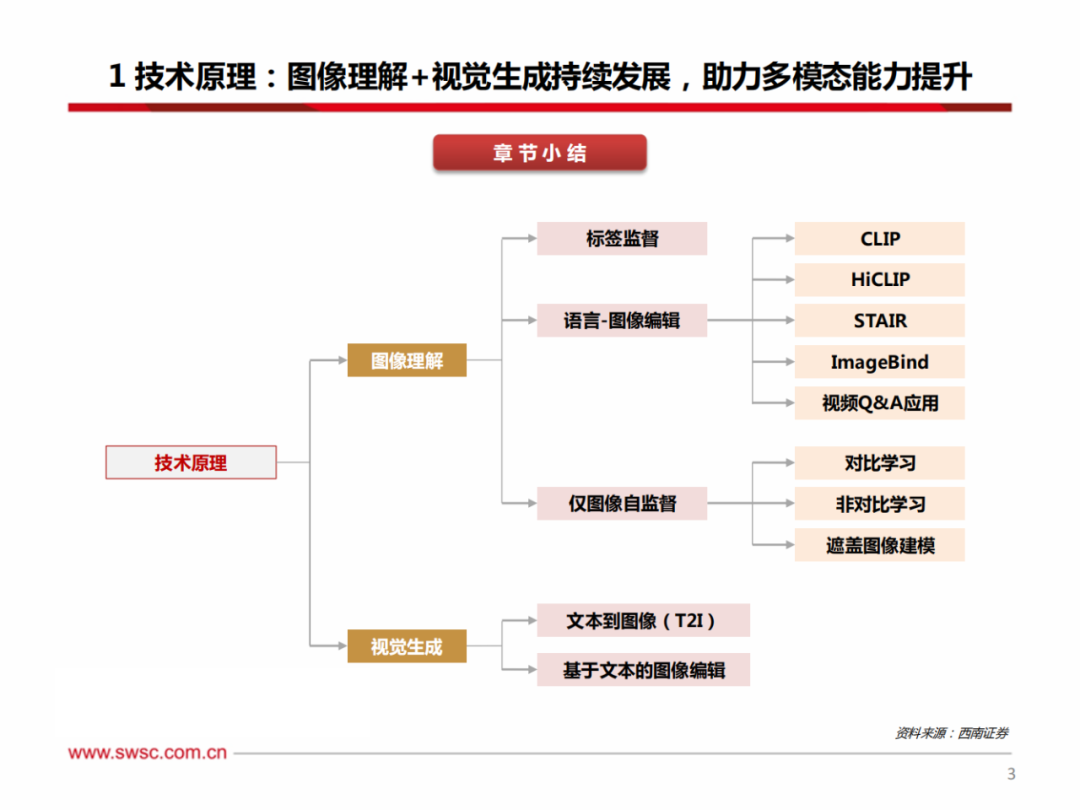
为打造视觉大模型,建立高效视觉预训练体系以提升图像理解能力至关重要,这影响到从图像整体(如分类、图文检索、标注)到部分区域(如物体识别、短语定位)及到像素细节(如语义、实例、全景分割)的各项任务。
通用视觉预训练方法主要可归纳为三大类。1)标签监督:此方法在每张图片都配有对应标签的数据集上进行训练,如图像分类中,一张狗的照片会对应“狗”的标签,模型的核心任务是准确预测此标签。2)语言-图像监督:利用完整的文本描述来引导模型学习,使模型能够深入挖掘图像内容与文本语义间的关联。3)仅图像自监督:利用图像本身固有的结构和信息来学习有意义的表示,而不依赖于显式的人工注释标签。

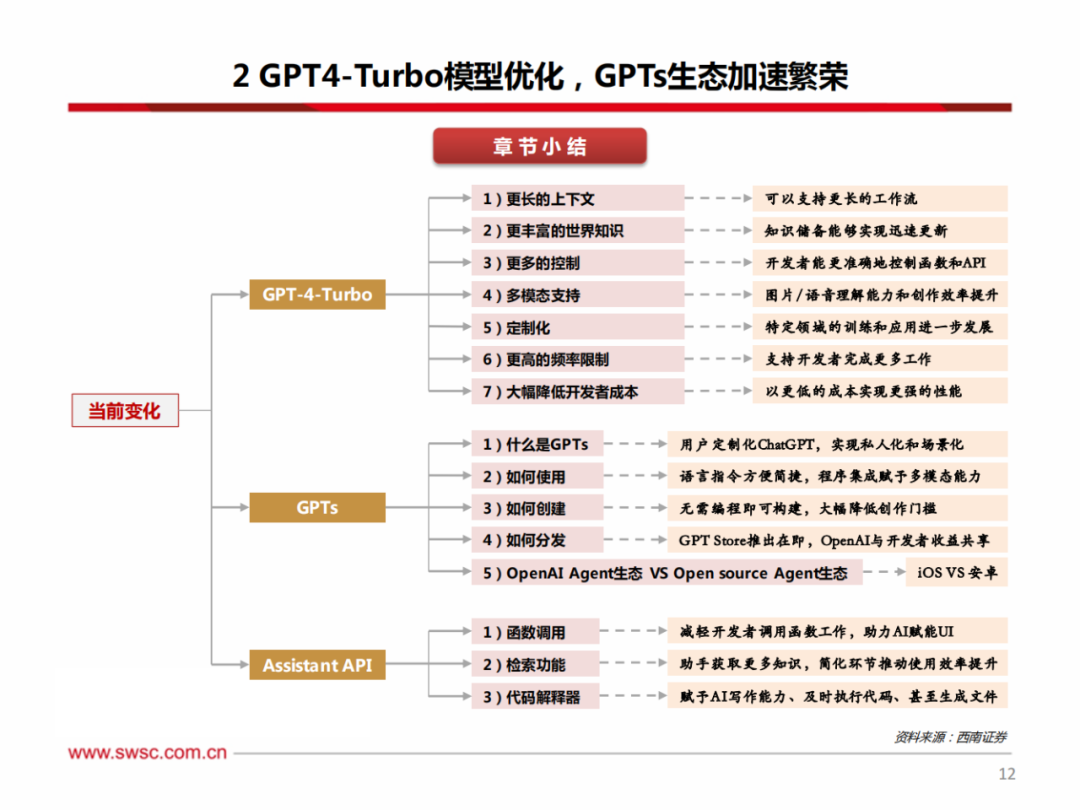
1)更长的上下文(Context Length):GPT-4-turbo支持的上下文窗口(128k)相较于GPT-4-8k提升16倍,相较于GPT-4-32k提升4倍,即GPT-4-turbo可在单个prompt中处理超过300页的文本,且GPT-4-turbo模型在较长的上下文中更加准确。我们认为GPT-4-turbo更长且更准确的上下文处理能力将支持更长的工作流,在B端有能力承担更多的工作负载,提升用户体验。
2)更丰富的世界知识(Better Knowledge):外部文档和数据库的截止更新日期从21年9月更新至23年4月,意味着OpenAI的大模型在半年内已学习互联网一年半的知识,学习速度极快。
什么是GPTs:GPTs是指“针对特定目的定制的ChatGPT”,用户可以通过自定义行为创建一个定制版的ChatGPT,定制版的ChatGPT具备带有任何功能的可能性(在保证隐私和安全的情况下)。
不论是开发者还是不会写代码的普通人,都可以拥有自定义版本的GPT。
更加个性化、私人化、场景化,每个人都可以拥有自己的AI Agent。GPTs通过结合①说明/Instruction+②扩展的知识/Expand knowledge+③操作/Actions,能够在很多情况下更好地工作,并且为用户提供更好地控制,用以帮助用户轻松完成各种任务、或者获得更多乐趣。



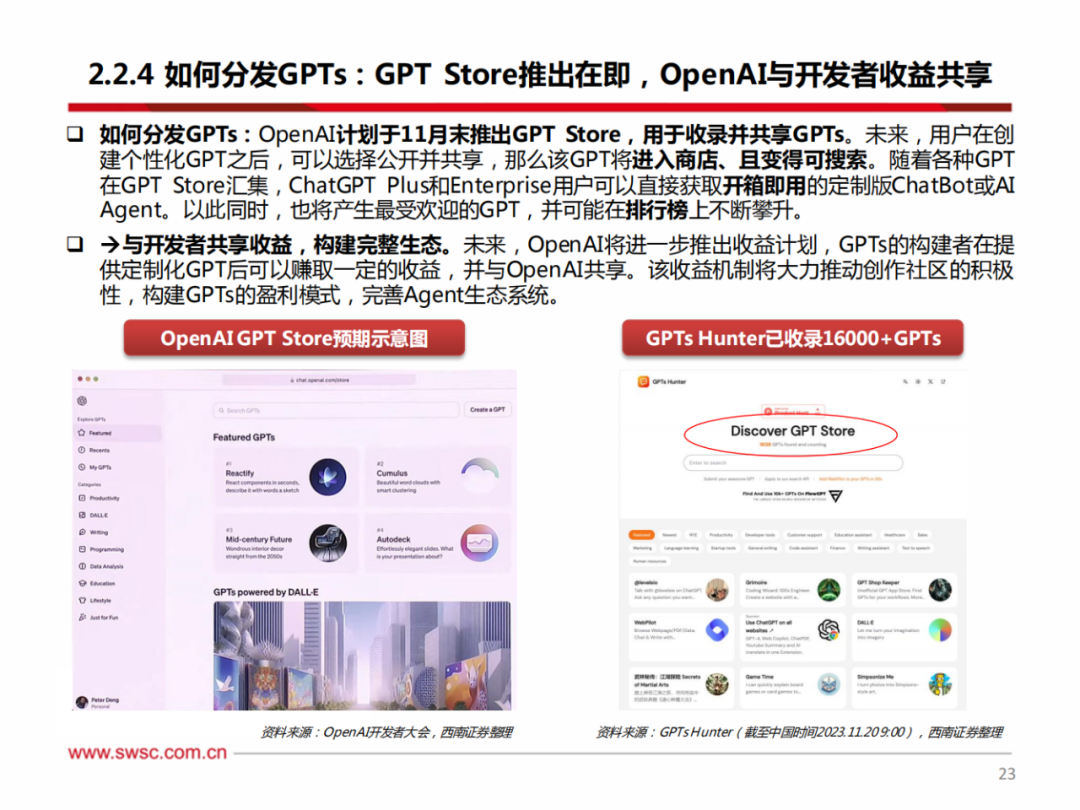
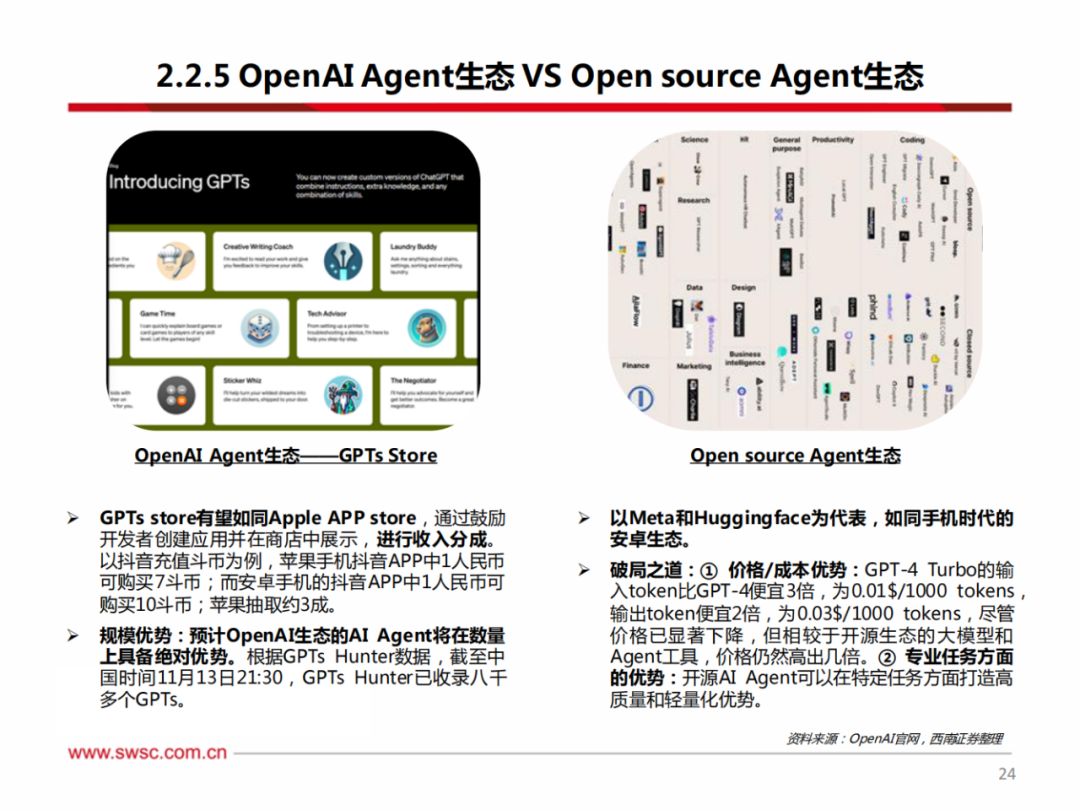
针对开发者在开发API中的痛点,OpenAI推出Assistant API,致力于为开发者赋能。根据此前市场上推出的各种API,我们可以发现API通过接入各种程序和应用,有助于帮助应用实现特定功能。
例如,Shopify的Sidekick允许用户在平台上进行操作;Discord的Clyde允许discord版主设置自定义人格;Snap my AI作为定制聊天机器人工具,可以添加至群聊中并提出建议。但以上API的构建可能需要开发者耗费几个月的时间、并由数十名工程师搭建,而目前Assistant API的推出将使其变得容易实现。

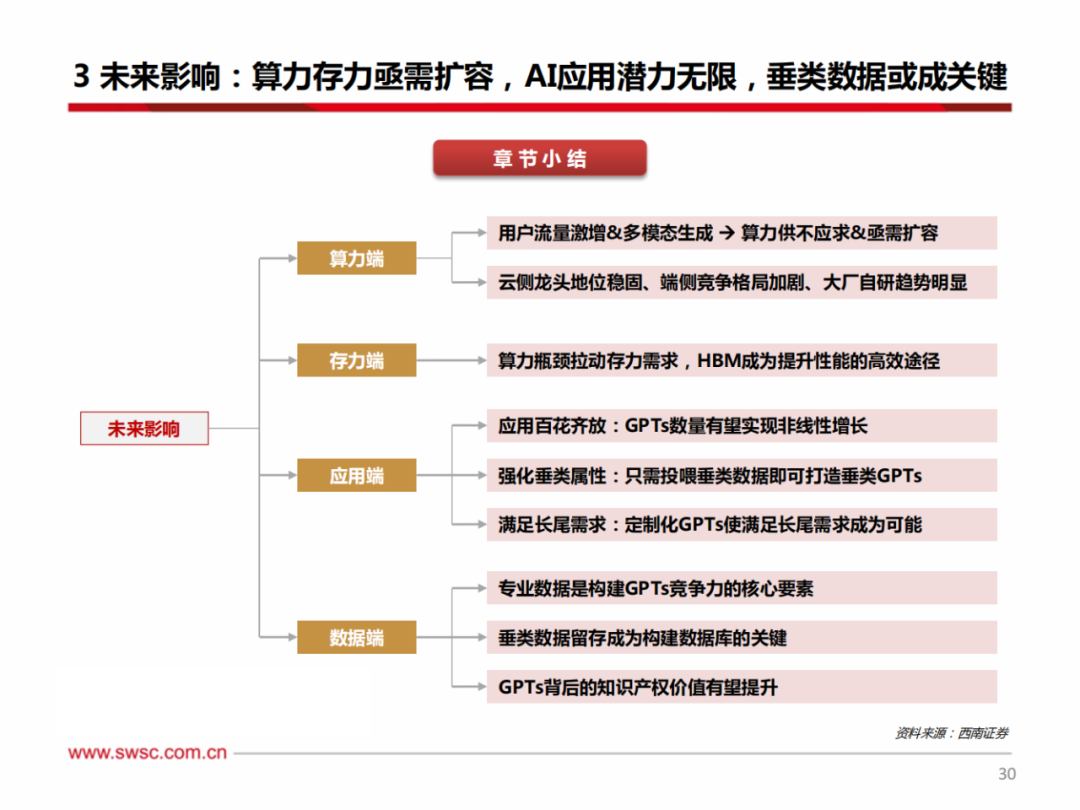
① 英伟达:2023年11月13日,英伟达推出H200,内存方面首次采用HBM3e,容量高达141GB,带宽实现大幅提升;性能方面着重强化推理能力和HPC性能,可将Llama2模型的推理速度提高近一倍,相较于H100可降低50%的TCO和能耗成本。2023年以来,英伟达AI芯片已发布多个产品,在云侧算力芯片领域龙头优势明显。
② AMD:2023年6月,AMD正式发布MI300系列,MI300将CPU、GPU和内存封装为一体,大幅缩短DDR内存行程和CPU-GPU PCIe行程,提高性能和效率;MI300采用Chiplet设计,拥有13个基于3D堆叠的小芯片(5nm: 3个CPU,6个GPU;4个6nm芯片),包括24个Zen4 CPU内核,同时融合CDNA 3和8个HBM3显存堆栈,集成5nm和6nm IP,总共包含128GB HBM3显存和1460亿个晶体管。对比MI250加速卡,MI300可带来8倍AI性能和5倍每瓦性能的提升(FP8),使ChatGPT和DALL-E等超大AI模型的训练时间可以从几个月缩短到几周。
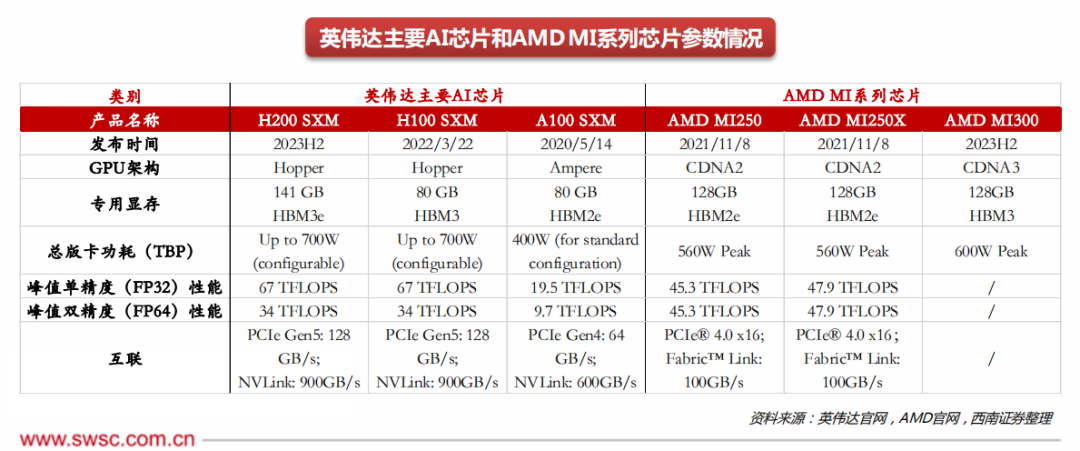
2)端侧芯片格局:对于AI PC端侧适用芯片,英特尔进展保持领先,高通有望实现从0到1。
① 英特尔:PC主芯片包括CPU和GPU。GPU方面,根据Statista数据,英特尔在22Q4全球PC GPU市场中占据71%的市场份额;CPU方面,根据Counterpoint Research数据,英特尔在2022年全球Notebook CPU/SoC市场中占据69.6%的市场份额,当前英特尔在PC主芯片市场中处于主导地位。23H2,英特尔推出Meteor Lake处理器,助力PC效能提升,专为AI任务设计,在AI PC主芯片市场中具备先发优势。
② 高通:2023年10月,高通于骁龙峰会上推出骁龙X Elite芯片,可支持130亿参数大模型,为Windows-on-Arm笔记本设计,预计在2024年中期发布。算力方面,AI PC对PC芯片的算力要求更高,高通在端侧AI推理能力优于英特尔。与此同时,生态方面,2022年至今Windows开始支持高通,已发布多轮支持Arm架构芯片的操作系统。未来,高通在以骁龙X Elite为代表的AI PC芯片的助力下,将在PC领域实现重要突破,逐步抢占市场份额。
3)大厂自研趋势:科技巨头加速自研,优先服务于自身云服务业务及AI条线。微软于23年11月16日Ignite技术大会上发布两款自研芯片——Azure Maia 100和Azure Cobalt 100,分别用于大语言模型的训练推理和通用云服务的支持。近年来,各大科技厂商纷纷自研芯片,一是为了降低自身对第三方芯片和外部供应链的依赖;二是自研芯片可帮助各大厂商克服一定的通用芯片局限,通过CPU+GPU+DPU+定制芯片等结合方案,提升全系统整合效率、实现业务赋能;三是提高计算能效、减少长期硬件成本。
-
AI芯片
+关注
关注
17文章
1879浏览量
34991 -
算力
+关注
关注
1文章
964浏览量
14794 -
OpenAI
+关注
关注
9文章
1079浏览量
6481
原文标题:GPT-4 Turbo多模态,应用生态加速
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
科大讯飞发布讯飞星火4.0 Turbo:七大能力超GPT-4 Turbo
OpenAI推出新模型CriticGPT,用GPT-4自我纠错
国内直联使用ChatGPT 4.0 API Key使用和多模态GPT4o API调用开发教程!

开发者如何调用OpenAI的GPT-4o API以及价格详情指南





 工商网监
工商网监
评论