 ChatGLM3-6B在CPU上的INT4量化和部署
ChatGLM3-6B在CPU上的INT4量化和部署
作者:刘力 英特尔边缘计算创新大使
ChatGLM3-6B 简介
ChatGLM3 是智谱 AI 和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在填写问卷进行登记后亦允许免费商业使用。
请使用命令,将 ChatGLM3-6B 模型下载到本地:
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
左滑查看更多
BigDL-LLM 简介
BigDL-LLM 是开源,遵循 Apache 2.0 许可证,专门用于在英特尔的硬件平台上加速大语言模型(Large Language Model, LLM)推理计算的软件工具包。它是在原有的 BigDL 框架基础上,为了应对大语言模型在推理过程中对性能和资源的高要求而设计的。BigDL-LLM 旨在通过优化和硬件加速技术来提高大语言模型的运行效率,减少推理延迟,并降低资源消耗。
BigDL-LLM 的主要特点包括:
1低精度优化:通过支持 INT4/INT5/INT8 等低精度格式,减少模型的大小和推理时的计算量,同时保持较高的推理精度。
2硬件加速:利用英特尔 CPU 集成的硬件加速技术,如 AVX(Advanced Vector Extensions)、VNNI(Vector Neural Network Instructions)和 AMX(Advanced Matrix Extensions)等,来加速模型的推理计算。
3使用方便:对于基于 Hugging Face Transformers API 的模型,只需修改少量代码即可实现加速,使得开发者可以轻松地在其现有模型上应用 BigDL-LLM。
4性能提升:BigDL-LLM 可以显著提高大语言模型在英特尔平台上的运行速度,减少推理时间,特别是在处理大规模模型和复杂任务时。
5资源友好:通过优化模型运行时的资源使用,BigDL-LLM 使得大语言模型可以在资源受限的环境中也能高效运行,如普通的笔记本电脑或服务器。
使用 BigDL-LLM
量化并部署 ChatGLM3-6B
第一步,创建虚拟环境
请安装 Anaconda,然后用下面的命令创建名为 llm 的虚拟环境:
conda create -n llm python=3.9 conda activate llm
左滑查看更多
第二步,安装 BigDL-LLM
执行命令:
pip install --pre --upgrade bigdl-llm[all] -i https://mirrors.aliyun.com/pypi/simple/
左滑查看更多
第三步:运行范例程序
范例程序下载地址:
https://gitee.com/Pauntech/chat-glm3/blob/master/chatglm3_infer.py
import time
from bigdl.llm.transformers import AutoModel
from transformers import AutoTokenizer
CHATGLM_V3_PROMPT_FORMAT = "<|user|>
{prompt}
<|assistant|>"
# 请指定chatglm3-6b的本地路径
model_path = "d:/chatglm3-6b"
# 载入ChatGLM3-6B模型并实现INT4量化
model = AutoModel.from_pretrained(model_path,
load_in_4bit=True,
trust_remote_code=True)
# 载入tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path,
trust_remote_code=True)
# 制作ChatGLM3格式提示词
prompt = CHATGLM_V3_PROMPT_FORMAT.format(prompt="What is Intel?")
# 对提示词编码
input_ids = tokenizer.encode(prompt, return_tensors="pt")
st = time.time()
# 执行推理计算,生成Tokens
output = model.generate(input_ids,max_new_tokens=32)
end = time.time()
# 对生成Tokens解码并显示
output_str = tokenizer.decode(output[0], skip_special_tokens=True)
print(f'Inference time: {end-st} s')
print('-'*20, 'Prompt', '-'*20)
print(prompt)
print('-'*20, 'Output', '-'*20)
print(output_str)
左滑查看更多
运行结果,如下所示:
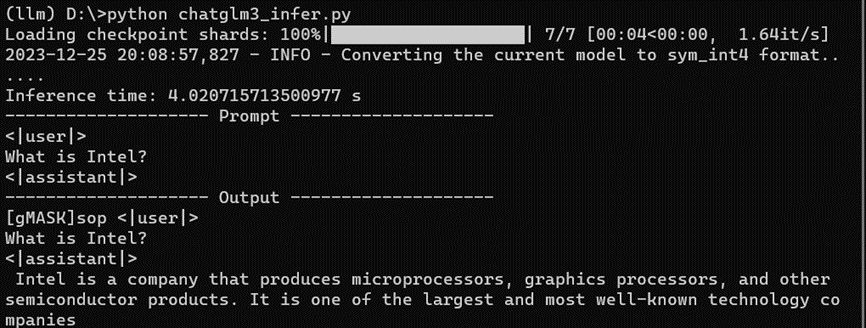
ChatGLM3-6B WebUI demo
请先安装依赖软件包:
pip install gradio mdtex2html streamlit -i https://mirrors.aliyun.com/pypi/simple/
左滑查看更多
下载范例程序:
https://gitee.com/Pauntech/chat-glm3/blob/master/chatglm3_web_demo.py
然后运行:
streamlit run chatglm3_web_demo.py
左滑查看更多
运行结果如下:
总结
BigDL-LLM 工具包简单易用,仅需三步即可完成虚拟环境创建、BigDLL-LLM 安装以及 ChatGLM3-6B 模型的 INT4 量化以及在英特尔 CPU 上的部署。
作者简介
刘力,深圳市铂盛科技有限公司的创始人。带领团队成功设计了多种计算机系统,并申请了多项专利和软件著作,铂盛科技为国家高新技术企业,深圳市专精特新企业。铂盛通过整合算力和算法,打造软硬件一体化的AIPC解决方案,目前产品已在工业控制、智能机器人、教育、医疗、金融等多个边缘计算领域得到广泛应用。
审核编辑:汤梓红
-
英特尔
+关注
关注
61文章
10082浏览量
172906 -
cpu
+关注
关注
68文章
10953浏览量
213955 -
AI
+关注
关注
87文章
32504浏览量
271716 -
开源
+关注
关注
3文章
3472浏览量
42947
原文标题:三步完成 ChatGLM3-6B 在 CPU 上的 INT4 量化和部署 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NCNN+Int8+yolov5部署和量化

英伟达:5nm实验芯片用INT4达到INT8的精度
ChatGLM-6B的局限和不足
ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜单位列榜首
类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练

探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商业落地

Yolo系列模型的部署、精度对齐与int8量化加速
OpenVINO™ 2023.2 发布:让生成式AI在实际场景中更易用
三步完成在英特尔独立显卡上量化和部署ChatGLM3-6B模型
使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理优化实践
【AIBOX】装在小盒子的AI足够强吗?

chatglm2-6b在P40上做LORA微调
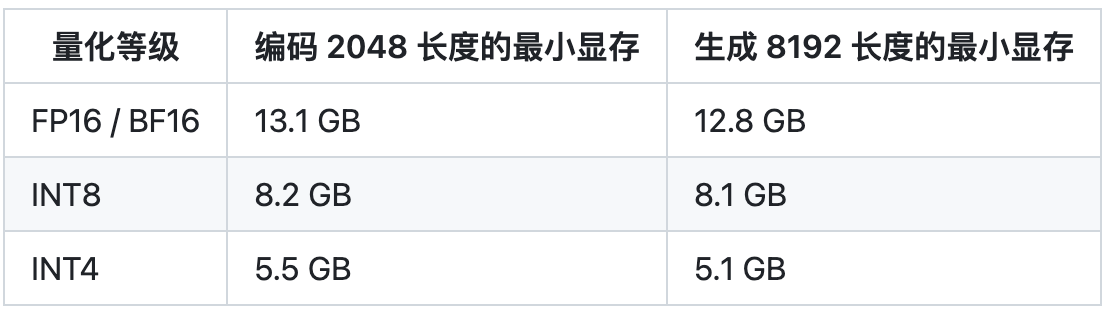
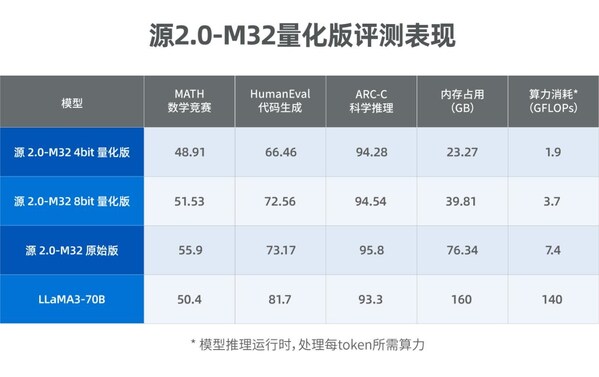
源2.0-M32大模型发布量化版 运行显存仅需23GB 性能可媲美LLaMA3





 工商网监
工商网监
评论