 中科院提出名为“Zhejiang”的大芯片将使用22 纳米工艺制造
中科院提出名为“Zhejiang”的大芯片将使用22 纳米工艺制造
据中科院研究人员介绍,名为“Zhejiang”的大芯片将使用22 纳米工艺制造。
真正的摩尔定律,即晶体管随着工艺的每次缩小而变得更便宜、更快,这就是正在让芯片制造商抓狂的事。有两种不同的方法可以制造容量更大但通常不是更快的计算引擎,将设备分解成小芯片并将它们连接在一起或将它们蚀刻在整个硅晶圆上,再加上第三种覆盖层,这两种方法都可以与 2.5D 和 3D 堆叠一起使用。芯片以扩展容量和功能。
无论如何,所有这些方法都受到用于蚀刻芯片的光刻设备的掩模版限制的限制。
目前的设备是针对 300 mm 硅片定制的,该屏障为 858 mm2,仅此而已。没有任何芯片可以蚀刻得比这更大。在过去的三十年里,从 150 毫米晶圆到 200 毫米晶圆到 300 毫米晶圆并没有改变掩模版极限,从可见光光刻到水浸光刻再到极紫外光刻也没有改变掩模版极限。假设转向 450 毫米晶圆也不会改变掩模版限制。到 2023 年,拥有 450 毫米晶圆将允许更大容量的晶圆级计算引擎。但 450 毫米晶圆的工程挑战对于 IBM、英特尔、三星、台积电、GlobalFoundries 和尼康来说太难解决,但这一努力于 2015 年被放弃。
光罩限制(光穿过芯片掩模以在硅晶圆上蚀刻晶体管的孔径大小)不仅定义了小芯片的设计方式,而且还限制了离散计算和内存块的大小单个晶圆。如果我们有 450 毫米的晶圆,并且晶圆级计算机的所有逻辑都可以用比晶圆更大的掩模版一次性蚀刻,那将是令人惊奇的,但这不是光刻设备的工作原理。总而言之,小芯片和晶圆级之间的区别实际上在于如何构建互连,以利用计算和内存的离散元件来构建计算引擎插槽。
尽管存在这样的限制,业界始终需要构建更强大的计算引擎,并且在摩尔定律结束时,如果能够找到一种方法,让这些设备的制造成本也更低,那就太好了。
中国科学院(CAS)计算技术研究所的研究人员刚刚在《基础研究》杂志上发表了一篇论文,讨论了光刻和小芯片的局限性,并提出了一种他们称之为“大芯片”的架构,该架构模仿了晶圆级Trilogy Systems 在 20 世纪 80 年代的努力以及Cerebras Systems 在 2020 年代成功的晶圆级架构。埃隆·马斯克 (Elon Musk) 的特斯拉正在打造自己的“Dojo”超级计算机芯片,但这不是晶圆级设计,而是将Dojo D1 核心复杂地封装成某种东西,如果你眯着眼睛看,它看起来就像是由 360 个小芯片构建的晶圆级插槽。也许通过 Dojo2 芯片,特斯拉将转向真正的晶圆级设计。看起来并不需要做很多工作就能完成这样的壮举。
中国科学院整理的这篇论文讨论了很多关于为什么需要开发晶圆级器件的问题,但没有提供太多关于他们开发的大芯片架构实际上是什么样子的细节。它并没有表明大芯片是否会像特斯拉对 Dojo 那样采用小芯片方法,或者像 Cerebras 从一开始就一路向晶圆级发展。
研究人员表示,该设计能够在单个分立器件中扩展至 100 个小芯片,我们过去称之为插槽,但对我们来说听起来更像是系统板。目前尚不清楚这 100 个小芯片将如何配置,也不清楚这些小芯片将实现什么样的内存架构(阵列中将有 1,600 个内核)。
我们所知道的是,随着大芯片的迭代,有 16 个 RISC-V 处理器使用芯片上的网络在共享主内存上进行对称多处理,相互连接,并且小芯片之间有 SMP 链接,因此每个块可以在整个复合体中共享内存。
以下是RISC-V 小芯片的框图:
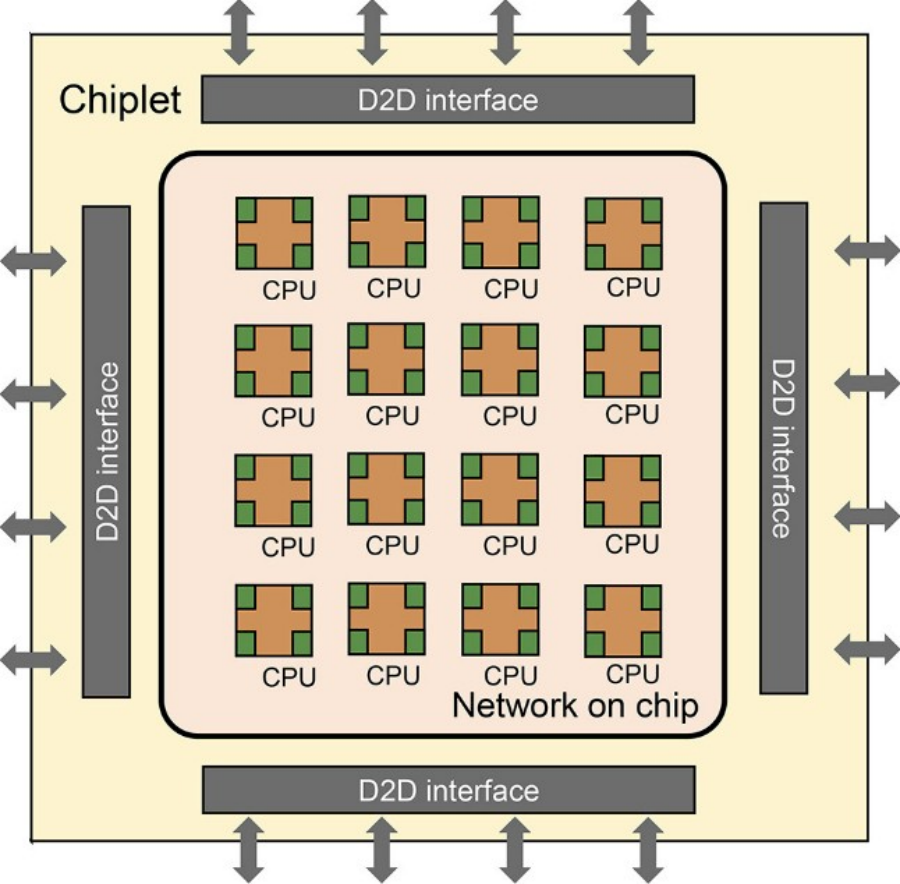
以下是如何使用中介层将 16 个小芯片捆绑在一起形成具有共享内存的 256 核计算复合体,从而实现芯片间 (D2D) 互连:
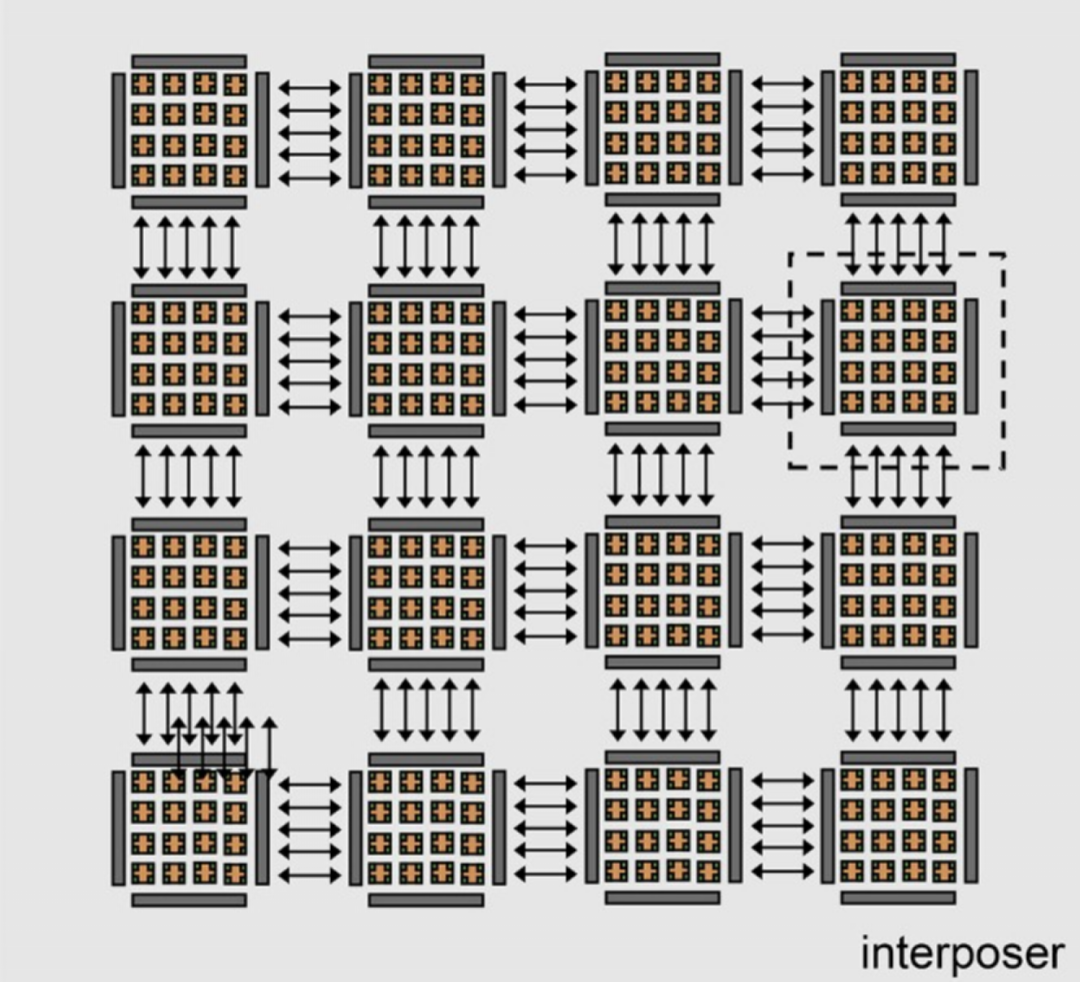
CAS 研究人员表示,绝对没有什么可以阻止这种小芯片设计以晶圆级实现。然而,对于这次迭代,看起来它将是使用 2.5D 中介层互连的小芯片。
互连与计算元件一样重要,这在系统和子系统设计中始终如此。
“该接口是使用基于时间复用机制的通道共享技术设计的,”研究人员在谈到 D2D 互连时写道。“这种方法减少了芯片间信号的数量,从而最大限度地减少了 I/O 凸块和内插器布线资源的面积开销,从而可以显着降低基板设计的复杂性。小芯片终止于顶部金属层,微型 I/O 焊盘就建在该金属层上。”
虽然一个大芯片计算引擎作为多芯片或晶圆级复合体可能很有趣,但重要的是如何将这些设备互连以提供百亿亿级计算系统。以下是 CAS 研究人员对此的看法:
研究人员在谈到这种计算和内存的分层结构时写道:“对于当前和未来的亿亿级计算,我们预测分层小芯片架构将是一种强大而灵活的解决方案。”如下图所示,这段来自 CAS 的长篇引用纸。“分层小芯片架构被设计为具有多个内核和许多具有分层互连的小芯片。在chiplet内部,内核使用超低延迟互连进行通信,而chiplet之间则以得益于先进封装技术的低延迟互连,从而在这种高可扩展性系统中实现片上延迟和NUMA效应可以最小化。存储器层次结构包含核心存储器、片内存储器和片外存储器。这三个级别的内存在内存带宽、延迟、功耗和成本方面有所不同。在分层chiplet架构的概述中,多个核心通过交叉交换机连接并共享缓存。这就形成了一个pod结构,并且pod通过chiplet内网络互连。多个pod形成一个chiplet,chiplet通过chiplet间网络互连,然后连接到片外存储器。需要仔细设计才能充分利用这种层次结构。合理利用内存带宽来平衡不同计算层次的工作负载可以显著提高chiplet系统效率。正确设计通信网络资源可以确保小芯片协同执行共享内存任务。”
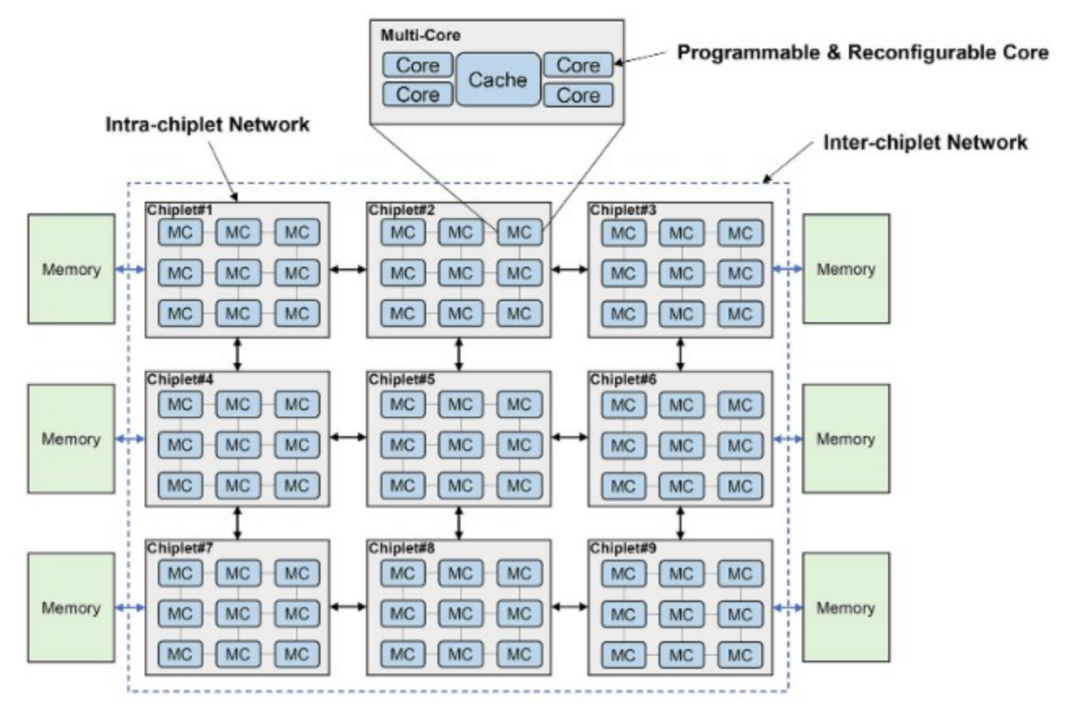
很难反驳这句话中所说的任何内容,但 CAS 研究人员并没有说明他们将如何实际处理这些问题。这是最困难的部分。
有趣的是,该图中的内核被称为“可编程”和“可重新配置”,但我们不确定这意味着什么。它可能需要使用可变线程技术(例如 IBM 的 Power8、Power9 和 Power10 处理器)来完成更多工作,而不是在核心中混合使用 CPU 和 FPGA 元件。
CAS 研究人员表示,大芯片计算引擎将由超过 1 万亿个晶体管组成,占据数千平方毫米的总面积,采用小芯片封装或计算和存储块的晶圆级集成。对于百亿亿级 HPC 和 AI 工作负载,我们认为 CAS 很可能正在考虑 HBM 堆叠 DRAM 或其他一些替代双泵浦主内存,例如英特尔和 SK Hynix 开发的 MCR 内存。RISV-V 内核可能会有大量本地 SRAM 进行计算,这可能会消除对 HBM 内存的需求,并允许使用 MCR 双泵浦技术加速 DDR5 内存。很大程度上取决于工作负载以及它们对内存容量和内存带宽的敏感程度。
-
芯片
+关注
关注
458文章
51539浏览量
429651 -
晶体管
+关注
关注
77文章
9830浏览量
139439 -
晶圆级
+关注
关注
0文章
36浏览量
9929
原文标题:晶圆级大芯片,中科院提出
文章出处:【微信号:ICViews,微信公众号:半导体产业纵横】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
红木棉电子携手中科院,国内首条干法全固态电池线诞生

芯片制造的7个前道工艺
联发科调整天玑9500芯片制造工艺
【「大话芯片制造」阅读体验】+ 芯片制造过程和生产工艺
大话芯片制造之读后感超纯水制造
【「大话芯片制造」阅读体验】+芯片制造过程工艺面面观
名单公布!【书籍评测活动NO.50】亲历芯片产线,轻松图解芯片制造,揭秘芯片工厂的秘密
上海光机所提出基于空间啁啾实现相干合束焦斑改善新方案

【龙芯2K0300蜂鸟板试用】1 龙芯中科必知3件事
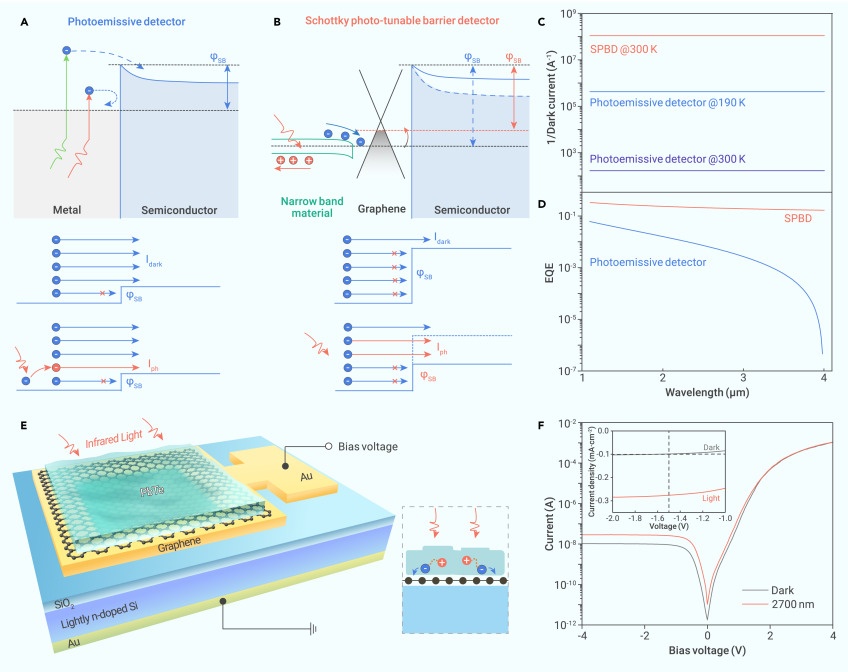
中科院重庆研究院在势垒可光调谐新型肖特基红外探测器研究获进展
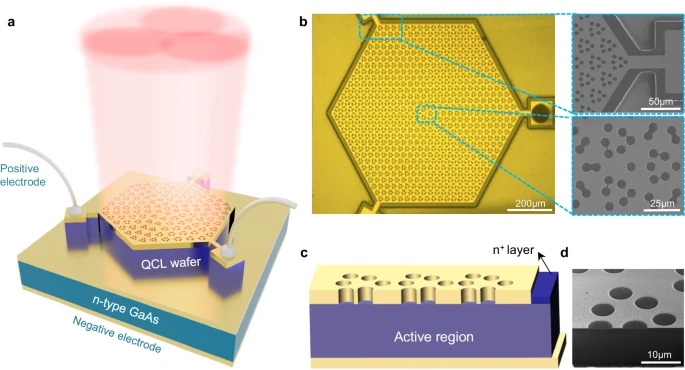
中科院半导体所在高性能电泵浦拓扑激光器研发方面获进展
为什么45纳米至130纳米的工艺节点如此重要呢?

产学研深度融合,创新印刷电子未来|绿展科技团队阶段性科研成果介绍





 工商网监
工商网监
评论