 OneFlow Softmax算子源码解读之WarpSoftmax
OneFlow Softmax算子源码解读之WarpSoftmax
写在前面:近来笔者偶然间接触了一个深度学习框架 OneFlow,所以这段时间主要在阅读 OneFlow 框架的 cuda 源码。官方源码基于不同场景分三种方式实现 Softmax,本文主要介绍其中一种的实现过程,即 Warp 级别 Softmax,适用于矩阵宽度不超过 1024 的情况。
1 Softmax
Softmax 操作是深度学习模型中最常用的操作之一。在深度学习的多分类任务中,最后一层通常是一个 Softmax 操作将 logits 映射成概率,然后结合交叉熵求损失。另外还有一些场景会用到 Softmax 做一个归一化操作,比如 Transformer 结构中 query 和 key 矩阵相乘并缩放后会执行一个 Softmax 操作,这一步的意义是求出 query 和 key 中每一项的两两相似度,具体笔者在另一篇文章有详述——【ASR】基于DFCNN-CTC模型的语音识别系统(二)
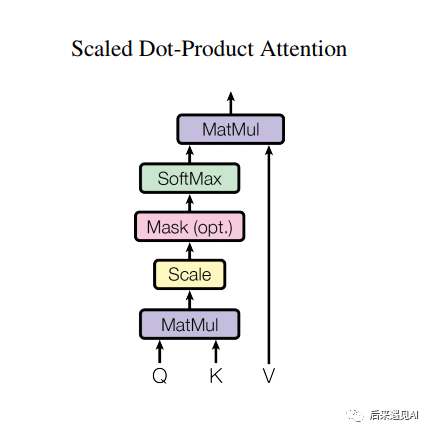
图1 Scaled Dot-Product Attention 结构示意图
深度学习框架中的所有算子底层都对应着 GPU上的 CUDA kernel function,Softmax 操作也不例外。Softmax 作为一个被广泛使用的算子,其 CUDA Kernel 的实现会影响很多网络最终的训练速度。那么如何实现一个高效的 Softmax CUDA Kernel?本文将会介绍 OneFlow 中优化的 Softmax CUDA Kernel 的技巧,在这之前我们先来看一下 Softmax 的计算公式。
定义 x 是一个 n 维向量,其 Softmax 输出 y 也是一个 n 维向量,那么有如下计算公式:
从上面的公式可以发现一个问题,当 为一个较大的正数时,取指数后 将会非常大,从而导致数值溢出,如何解决这个问题呢?
一般的处理方法是,让每个分量去减掉向量的最大值,这样可以保证取指数后的结果必然在 0~1 之间,可以有效避免数值溢出。处理后的公式如下:
根据公式可以看出,要执行 Softmax 计算,需要实现 5 个业务逻辑:reduceMax、broadcastSub、exp、reduceSum、broadcastDiv。下面笔者将对源码中的计算技巧进行解读,有兴趣的读者可以下载源码来阅读(https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/softmax/oneflow_softmax.cu)。
2 三种实现方式
Softmax 函数的输入形状为:(num_rows, num_cols),num_cols 的变化会对有效带宽产生影响。因为,没有一种通用的优化方法可以实现在所有 num_cols 的情况下都是传输最优的。所以,在 OneFlow 中采用分段函数优化 SoftmaxKernel:对于不同 num_cols 范围,选择不同的实现,以期在所有情况下都能达到较高的有效带宽。
针对不同的 Softmax 场景,OneFlow 提供了三种实现,分段对 Softmax kernel 进行优化:
(1) 一个 Warp 处理一行的计算,适用于 num_cols <= 1024 情况
(2) 一个 Block 处理一行的计算,借助 Shared Memory 保存中间结果数据,适用于需要的 Shared Memory 资源满足 Kernel Launch 的可启动条件的情况,在本测试环境中是 1024 < num_cols <= 4096。
(3) 一个 Block 处理一行的计算,不使用 Shared Memory,重复读输入 x,适用于不支持(1)、(2)的情况。
分段处理逻辑在 DispatchSoftmax 函数中体现,主体代码如下:
if (cols < 1024) {
return DispatchSoftmaxWarpImpl(
stream, load, store, rows, cols);
} else {
bool dispatch_smem_impl_success;
{
cudaError_t err =
TryDispatchSoftmaxBlockSMemImpl(
stream, load, store, rows, cols, &dispatch_smem_impl_success);
if (err != cudaSuccess) { return err; }
}
if (!dispatch_smem_impl_success) {
return DispatchSoftmaxBlockUncachedImpl(
stream, load, store, rows, cols);
}
return cudaSuccess;
}
,>,>,>
3 WarpSoftmax
3.1 数据 Pack 提升访问带宽
在笔者上一篇文章【CUDA编程】OneFlow Element-Wise 算子源码解读中详细地介绍了如何进行向量化读写,有兴趣的读者可以移步,这里我们先看源码。
template
struct GetPackType {
using type = typename std::aligned_storage::type;
};
template
using PackType = typename GetPackType::type;
template
union Pack {
static_assert(sizeof(PackType) == sizeof(T) * N, "");
__device__ Pack() {
// do nothing
}
PackType storage;
T elem[N];
};
,>,>,>
oneflow 利用 union 共享空间的特性实现了一个 Pack 类型,细心的读者可能会发现,跟 elementwise.cuh 源码相比,这里少了一个 Packed 类,这是因为 elementwise.cuh 实现的时间晚于 softmax.cuh。可能考虑到 Pack 后类型的内存对齐特性,重新定义了 Packed 类,并声明了内存对齐值为 pack_size * sizeof(T)。
接下来定义了两个代表输入和输出的数据结构 DirectLoad 和 DirectStore,分别实现了 load 和 store 两个函数用来把读取和写入一个 pack 的数据。使用 DirectLoad 和 DirectStore 有两个好处:
可以在CUDA Kernel中只关心计算类型ComputeType,而不用关心具体的数据类型T。
只需要加几行代码就可以快速支持 Softmax 和其他 Kernel Fuse,减少带宽需求,提升整体性能。
/** * @brief 定义了输入的数据结构 * * @tparam SRC 输入数据的类型 * @tparam DST 计算数据的类型,ComputeType */ template struct DirectLoad { /** * @brief Construct a new Direct Load object * * @param src 输入的数据源 * @param row_size num of elements per row */ DirectLoad(const SRC* src, int64_t row_size) : src(src), row_size(row_size) {} /** * @brief 从数据源 load 一个 pack 数据到 dst * * @tparam N pack_size * @param dst * @param row 数据源的第 row 行 * @param col 数据源的第 col 列 * @return __device__ */ template __device__ void load(DST* dst, int64_t row, int64_t col) const { Pack pack; const int64_t offset = (row * row_size + col) / N; // pack 偏移量 pack.storage = *(reinterpret_cast*>(src) + offset); #pragma unroll for (int i = 0; i < N; ++i) { dst[i] = static_cast(pack.elem[i]); } } const SRC* src; int64_t row_size; }; template struct DirectStore { DirectStore(DST* dst, int64_t row_size) : dst(dst), row_size(row_size) {} template __device__ void store(const SRC* src, int64_t row, int64_t col) { Pack pack; const int64_t offset = (row * row_size + col) / N; #pragma unroll for (int i = 0; i < N; ++i) { pack.elem[i] = static_cast(src[i]); } *(reinterpret_cast*>(dst) + offset) = pack.storage; } DST* dst; int64_t row_size; }; ,>,>
3.2 调用链
针对 WarpSoftmax 这个分支,对源码中函数的调用关系梳理后如下:
DispatchSoftmaxWarpImpl ->DispatchSoftmaxWarpImplPackSize ->DispatchSoftmaxWarpImplCols ->DispatchSoftmaxWarpImplPadding ->LaunchSoftmaxWarpImpl ->SoftmaxWarpImpl(kernel)
接下来将从上到下逐个解读其实现细节。
3.3 DispatchSoftmaxWarpImpl
该函数被 DispatchSoftmax 函数调用,其内部逻辑非常简单,实例化了一个 DispatchSoftmaxWarpImplPackSize 类并调用了其重载的()函数,所有的参数都是透传,没有其他逻辑。
template
inline cudaError_t DispatchSoftmaxWarpImpl(cudaStream_t stream, LOAD load, STORE store, const int64_t rows, const int64_t cols) {
return DispatchSoftmaxWarpImplPackSize()(stream, load, store, rows, cols);
}
,>
3.4 DispatchSoftmaxWarpImplPackSize
顾名思义,pack_size 参数是在这个结构体内部确定的。该结构体内部重载了一个小括号运算符,其函数内部只做了一件事,对矩阵的列数进行判断,如果是偶数,pack_size 取 2,否则取 1。
template
struct DispatchSoftmaxWarpImplPackSize {
cudaError_t operator()(cudaStream_t stream, LOAD load, STORE store, const int64_t rows, const int64_t cols) {
if (cols % 2 == 0) {
return DispatchSoftmaxWarpImplCols(stream, load, store, rows, cols);
} else {
return DispatchSoftmaxWarpImplCols(stream, load, store, rows, cols);
}
}
};
,>,>
笔者读到这里不禁产生了疑问,前面说过数据 Pack 后可以提升 GPU 访问带宽,但是在该函数中 pack_size 最大也只能取到 2,在前面的文章中笔者提到过在 cuda 中最大支持一次 128 bit的读写,意味着针对 float 类型 pack_size 最大可以取 4,对 half 类型甚至可以取 8。所以带着这个疑问笔者咨询了官方源码的作者俊丞大佬,答曰可以取更大的 pack_size,这里是考虑到更多的特化会导致编译时间过长所以只实现了 2 个模板。获得解答后,笔者自行实现了一个 pack_size = 4 的模板,然后经过实测(矩阵大小为 1024*1024, 32*16)发现, pack_size 取 4 和取 2 相比几乎没有提升。。。倒是取 2 相比取 1 有 6% 的提升。猜测可能是 pack_size 影响了 DispatchSoftmaxWarpImplCols 这个 kernel 的启动参数,所以间接影响了性能,这里官方肯定做过一系列测试。。。
3.5 DispatchSoftmaxWarpImplCols
DispatchSoftmaxWarpImplCols 函数代码比较长,读起来稍显晦涩,要理解它的实现逻辑,我们可以换个思路,看它的目的是什么,然后倒推它的实现过程。很显然,该函数在最后调用了 DispatchSoftmaxWarpImplPadding 函数,那么我们就来看被调用的函数需要哪些参数,DispatchSoftmaxWarpImplCols 的作用就是确定这些参数。读了 DispatchSoftmaxWarpImplPadding 的参数列表我们可以发现,有三个重要参数需要传入:cols_per_thread, thread_group_width, rows_per_access,这里先对这三个参数做一个解释:
cols_per_thread:每个线程处理的元素列数
thread_group_width:线程组的大小,一个线程组要处理整行的数据
rows_per_access:每个线程组一次处理的行数
函数体内主要是针对 cols 的大小做了分支,前后代码有一个分水岭,即 cols <= 32 * pack_size,可以分开来看。
当 cols <= 32 * pack_size 时,thread_group_width 取 2 的 n 次幂,从 1 到 32 一直判断,如果 cols <= (thread_group_width)*pack_size 那么 thread_group_width 就取当前的值。cols_per_thread 取 pack_size,就是说当前一个线程只处理一个 Pack 宽度的数据,这时候数据量也比较小,所以对 rows 也做了一层判断,如果 rows 是偶数,那么 rows_per_access 取 2,每个线程一次处理 2 行数据,否则一次只处理 1 行。
当 cols > 32 * pack_size 时,这种属于数据量比较大的情况,所以 thread_group_width 直接取能取到的最大值 32,即 Warp 的大小。每个线程也要处理多个 Pack,cols_per_thread 取 pack_size 的整数倍,直到 32 * cols_per_thread = 1024,一直判断 cols <= 32 * cols_per_thread,如果满足条件,cols_per_thread 就取当前值。对于 rows_per_access 参数,直接取 1,即每个线程一次只处理 1 行数据。
至此函数逻辑就介绍完了,这个函数里有两个宏,不熟悉 C++ 的读者读起来可能没那么顺畅,这里推荐一个网站(https://cppinsights.io/),从编译器的角度将 C++ 源码展开显示,对阅读泛型编程和宏这类代码很有帮助。
template
typename std::enable_if::type DispatchSoftmaxWarpImplCols(
cudaStream_t stream, LOAD load, STORE store, const int64_t rows, const int64_t cols) {
if (cols <= 0) { return cudaErrorInvalidValue; }
#define DEFINE_ONE_ELIF(thread_group_width)
else if (cols <= (thread_group_width)*pack_size) {
if (rows % 2 == 0) {
return DispatchSoftmaxWarpImplPadding(stream, load, store,
rows, cols);
} else {
return DispatchSoftmaxWarpImplPadding(stream, load, store,
rows, cols);
}
}
DEFINE_ONE_ELIF(1)
DEFINE_ONE_ELIF(2)
DEFINE_ONE_ELIF(4)
DEFINE_ONE_ELIF(8)
DEFINE_ONE_ELIF(16)
DEFINE_ONE_ELIF(32)
#undef DEFINE_ONE_ELIF
#define DEFINE_ONE_ELIF(col)
else if (cols <= (col)*kWarpSize) {
return DispatchSoftmaxWarpImplPadding(stream, load, store, rows, cols);
}
DEFINE_ONE_ELIF(4)
DEFINE_ONE_ELIF(6)
DEFINE_ONE_ELIF(8)
DEFINE_ONE_ELIF(10)
DEFINE_ONE_ELIF(12)
DEFINE_ONE_ELIF(14)
DEFINE_ONE_ELIF(16)
DEFINE_ONE_ELIF(18)
DEFINE_ONE_ELIF(20)
DEFINE_ONE_ELIF(22)
DEFINE_ONE_ELIF(24)
DEFINE_ONE_ELIF(26)
DEFINE_ONE_ELIF(28)
DEFINE_ONE_ELIF(30)
DEFINE_ONE_ELIF(32)
#undef DEFINE_ONE_ELIF
else {
return cudaErrorInvalidValue;
}
}
,>,>,>
3.6 DispatchSoftmaxWarpImplPadding
顾名思义,这个函数内部的逻辑跟 padding 相关,实际上这个函数只做了一件事,当 cols == cols_per_thread * thread_group_width 时说明矩阵列数能被线程组均分,这时候不需要 padding,否则需要 padding。
template
inline cudaError_t DispatchSoftmaxWarpImplPadding(cudaStream_t stream, LOAD load, STORE store,
const int64_t rows, const int64_t cols) {
if (cols == cols_per_thread * thread_group_width) {
return LaunchSoftmaxWarpImpl(
stream, load, store, rows, cols);
} else {
return LaunchSoftmaxWarpImpl(
stream, load, store, rows, cols);
}
}
,>,>
3.7 LaunchSoftmaxWarpImpl
该函数是核函数的启动函数,函数内主要是确定 block_size、num_blocks 这两个参数。这两个参数的确定笔者在上一篇文章【CUDA编程】OneFlow Element-Wise 算子源码解读中有详细介绍,有兴趣的读者可以移步,这里不再赘述。
函数中定义了一个 block_dim 对象,从初始化参数可以看出这是一个二维的 block,宽是 thread_group_width,高取 thread_groups_per_block。从核函数启动参数 grid_dim_x 可以看出网格是一维的,由此我们可以确定 cuda 线程网格的形状。这里笔者给出示意图如下。
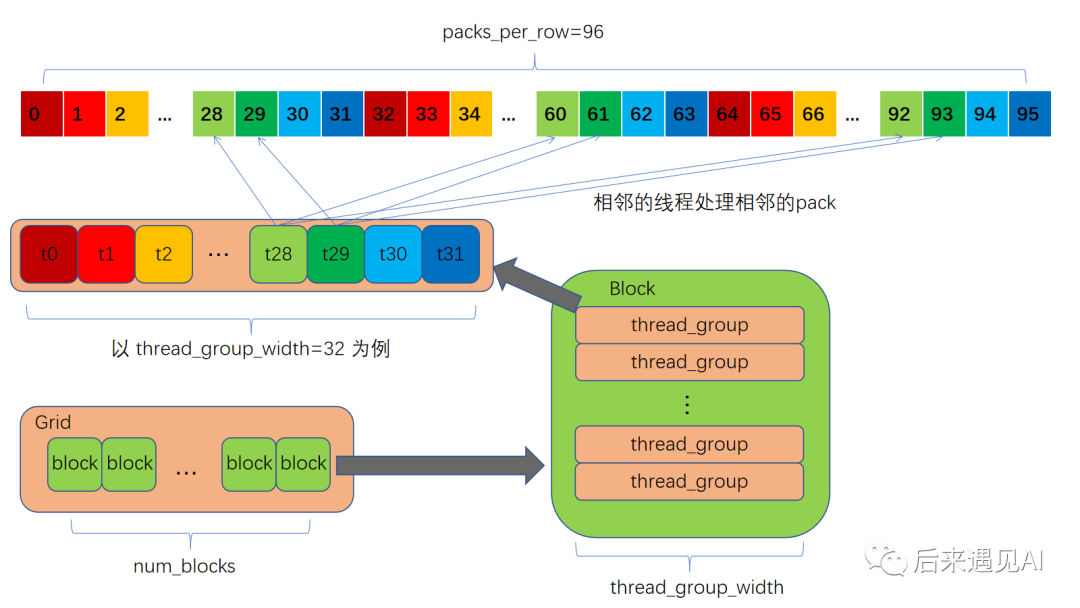
图2 线程网格示意图
template
inline cudaError_t LaunchSoftmaxWarpImpl(cudaStream_t stream, LOAD load, STORE store,
const int64_t rows, const int64_t cols) {
constexpr int block_size = 128;
constexpr int waves = 32;
static_assert(block_size % thread_group_width == 0, "");
constexpr int thread_groups_per_block = block_size / thread_group_width;
dim3 block_dim(thread_group_width, thread_groups_per_block);
const int64_t num_blocks =
(rows / rows_per_access + thread_groups_per_block - 1) / thread_groups_per_block;
int grid_dim_x;
{
cudaError_t err = GetNumBlocks(block_size, num_blocks, waves, &grid_dim_x);
if (err != cudaSuccess) { return err; }
}
SoftmaxWarpImpl
<<>>(load, store, rows, cols);
return cudaPeekAtLastError();
}
,>,>
3.8 核函数 SoftmaxWarpImpl
接下来就是 WarpSoftmax 的核函数 SoftmaxWarpImpl,该函数体内部实现了 Softmax 的核心计算逻辑。
template
__global__ void SoftmaxWarpImpl(LOAD load, STORE store, const int64_t rows, const int64_t cols) {
static_assert(cols_per_thread % pack_size == 0, ""); // 确保每个thread处理的元素个数正好被完全pack
static_assert(thread_group_width <= kWarpSize, ""); // 处理元素的线程组的宽度需要小于等于kWarpSize,并且需要被kWarpSize整除
static_assert(kWarpSize % thread_group_width == 0, "");
constexpr int num_packs = cols_per_thread / pack_size; // 每个线程处理的 pack 的数目,即每个线程需要处理的元素个数 / pack_size
assert(cols <= cols_per_thread * thread_group_width); // 确保一个thread group 能处理的列数大于等于一行
ComputeType buf[rows_per_access][cols_per_thread]; // 声明寄存器大小,这是一个二维数组
const int global_thread_group_id = blockIdx.x * blockDim.y + threadIdx.y; // 当前warp的全局index
const int num_global_thread_group = gridDim.x * blockDim.y; // warp的总数量
const int lane_id = threadIdx.x; // warp内的线程id
const int64_t step = num_global_thread_group * rows_per_access; // 处理的行数步长
// for 循环的开始为 row = 全局的线程组id * 每个线程组一次处理的行数,结束为总行数
for (int64_t row = global_thread_group_id * rows_per_access; row < rows; row += step) {
// 寄存器中开辟一块内存记录当前线程组处理的每一行的最大值
ComputeType thread_max[rows_per_access];
// 对每一行的循环
#pragma unroll
for (int row_id = 0; row_id < rows_per_access; ++row_id) {
// 把当前行最小值初始化为 -inf
thread_max[row_id] = -Inf();
// 获取第 row_id 行的指针
ComputeType* row_buf = buf[row_id];
#pragma unroll
for (int pack_id = 0; pack_id < num_packs; ++pack_id) {
const int pack_offset = pack_id * pack_size;
// 相邻的线程读取相邻的pack,也就是说同一个线程处理的相邻pack间间隔是thread_group_width*pack_size
const int col = (pack_id * thread_group_width + lane_id) * pack_size;
if (!padding || col < cols) {
// 使用 obj.template 调用函数模板防止歧义,load 一个 pack 的数据到寄存器
load.template load(row_buf + pack_offset, row + row_id, col);
#pragma unroll
for (int i = 0; i < pack_size; ++i) {
thread_max[row_id] = max(thread_max[row_id], row_buf[pack_offset + i]);
}
} else { // 需要 padding 且 col > cols,这种情况对于第 col 列的数据直接将 row_buf 赋最新小值,不影响 thread_max 计算即可
#pragma unroll
for (int i = 0; i < pack_size; ++i) { row_buf[pack_offset + i] = -Inf(); }
}
}
}
// 记录属于同一个warp的线程组的每一行的最大值,也就是需要进行一次warpReduce max
ComputeType warp_max[rows_per_access];
#pragma unroll
for (int row_id = 0; row_id < rows_per_access; ++row_id) {
// 通过线程束洗牌函数对一个线程组内的所有线程的 thread_max 求规约得到一个线程组处理的每一行的最大值
warp_max[row_id] = WarpAllReduce(thread_max[row_id]);
}
// 记录当前线程组处理的每一行的sum
ComputeType thread_sum[rows_per_access];
#pragma unroll
for (int row_id = 0; row_id < rows_per_access; ++row_id) {
thread_sum[row_id] = 0;
ComputeType* row_buf = buf[row_id];
#pragma unroll
for (int i = 0; i < cols_per_thread; ++i) {
if (algorithm == Algorithm::kSoftmax) {
row_buf[i] = Exp(row_buf[i] - warp_max[row_id]);
thread_sum[row_id] += row_buf[i];
} else if (algorithm == Algorithm::kLogSoftmax) {
row_buf[i] -= warp_max[row_id];
thread_sum[row_id] += Exp(row_buf[i]);
} else {
__trap(); // 内核的执行被中止并在主机程序中引发中断。
}
}
}
ComputeType warp_sum[rows_per_access];
#pragma unroll
for (int row_id = 0; row_id < rows_per_access; ++row_id) {
warp_sum[row_id] = WarpAllReduce(thread_sum[row_id]);
}
#pragma unroll
for (int row_id = 0; row_id < rows_per_access; ++row_id) {
ComputeType* row_buf = buf[row_id];
#pragma unroll
for (int i = 0; i < cols_per_thread; ++i) {
if (algorithm == Algorithm::kSoftmax) {
row_buf[i] = Div(row_buf[i], warp_sum[row_id]);
} else if (algorithm == Algorithm::kLogSoftmax) {
row_buf[i] -= Log(warp_sum[row_id]);
} else {
__trap();
}
}
#pragma unroll
for (int i = 0; i < num_packs; ++i) {
const int col = (i * thread_group_width + lane_id) * pack_size;
if (!padding || col < cols) {
store.template store(row_buf + i * pack_size, row + row_id, col);
}
}
}
}
}
,>,>
具体代码如上,在解读之前,需要先介绍一下几个重要参数的意义。
algorithm:代表所使用的的算法,有 Algorithm::kSoftmax 和 Algorithm::kLogSoftmax。
global_thread_group_id:当前线程组的全局索引
lane_id:当前线程在线程组内的索引
首先在核函数内部做了几个编译期断言操作,确保核函数能够正常启动。然后在寄存器中定义了一个二维数组 buf[rows_per_access][cols_per_thread] 用来存储矩阵中的数据,我们知道,寄存器中的变量只能对当前线程可见,每个线程中都有一个变量 buf,但是存储的值可以不同,这里是为了减少对全局内存的读取,所以给每个线程都定义一个寄存器变量用于存储该线程处理的矩阵元素。
接着是一个 Grip-loop 的循环,因为有可能矩阵行数过大导致前面求 num_blocks 的时候是根据硬件参数选取的,这时候每个线程不止处理一次,所以循环步长设置为网格大小。Grip-loop 内部定义了一个寄存器变量 thread_max[rows_per_access],这个数组用来存储当前线程处理的元素中的每一行的最大值。接下来就是一个 reduceMax 操作。
(1)reduceMax
如图 2,每个线程处理了多个 Pack 的数据,求最大值需要两层循环。第一层循环中把一个 Pack 的矩阵元素 load 到 buf 数组中,这里主要是要理解 col 变量的含义,结合图 2 的示意图不难理解,相邻的线程读取相邻的 Pack 的目的是让一个线程束中各线程单次访问的数据在内存中相邻,这是一个合并访问的概念,目的是提升访问效率。第二层循环中对单个 Pack 中的元素求最大值存到 thread_max 中。
注意,这时候 thread_max 中存的只是每个线程内部处理的元素的最大值,但是 reduceMax 操作要获取的是矩阵每一行的最大值,由于 WarpSoftmax 的应用范围就是一个线程组处理一行数据,所以再对线程组内所有的 thread_max 求最大值即可。前面说过,每个线程内部都有一个 thread_max 变量,对这些变量求最大值,必然要在线程间进行通信,源码中使用了 WarpAllReduce() 函数完成了这一操作得到了矩阵每一行的最大值 warp_max,核心就是利用了线程束洗牌指令 __shfl_xor_sync 完成了一个束内折半规约操作,笔者之前在另一篇文章也有介绍:【CUDA编程】CUDA编程中的并行规约问题。有兴趣的读者可以去 cuda 官网详细了解一下束内洗牌指令的用法,当然了这里也可以直接使用共享内存存储数据,我们知道共享内存在整个 block 都是可见的,也就不需要使用束内通信,但是从访问性能出发,共享内存是不如寄存器快的,所以 oneflow 选择了寄存器。,>
template class ReductionOp, typename T, int thread_group_width = kWarpSize>
__inline__ __device__ T WarpAllReduce(T val) {
for (int mask = thread_group_width / 2; mask > 0; mask /= 2) {
val = ReductionOp()(val, __shfl_xor_sync(0xffffffff, val, mask));
}
return val;
}
(2)reduceSum
接下来就是 reduceSum 操作,这里源码提供了两种算法: Algorithm::kSoftmax 和 Algorithm::kLogSoftmax。kSoftmax 就是公式(2)中的计算公式,kLogSoftmax 计算的是 计算公式如下:
reduceSum 的计算思路和 reduceMax 相同,先在寄存器定义一个变量 thread_sum 然后求出各个线程内的指数和,最后束内规约求每一行的指数和 warp_sum。
broadcastSub、exp、broadcastDiv 这三个操作比较简单,其逻辑就直接包含在两个规约操作的实现代码里,这里不再赘述,至此 WarpSoftmax 源码解读完毕,有兴趣的读者可以自行尝试。调用时可以将矩阵 cols 限制在 1024 以内调用 DispatchSoftmax 函数,也可以直接调用 DispatchSoftmaxWarpImpl 函数。
4 小结
总结一下 WarpSoftmax 源码中的一些值得注意的内容。
数据 Pack 可以有效地提升访问带宽,pack_size 可以根据 cuda 中最大支持一次 128 bit 的读写来确定最大值。
WarpSoftmax 的核心就是束内规约,利用了束内线程可互相访问寄存器的特性提高效率,但受制于单个线程可使用的寄存器大小,所以 WarpSoftmax 不适用于矩阵列数比较大的场景。
源码中对于 pack_size 和 row_per_access 的确定都比较简单粗暴,可以进行更细致的处理。
审核编辑:汤梓红
-
源码
+关注
关注
8文章
656浏览量
29699 -
模型
+关注
关注
1文章
3399浏览量
49416 -
深度学习
+关注
关注
73文章
5524浏览量
121766 -
OneFlow
+关注
关注
0文章
9浏览量
8824
原文标题:【CUDA编程】OneFlow Softmax 算子源码解读之WarpSoftmax
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OneFlow Softmax算子源码解读之BlockSoftmax

TensorFlow、PyTorch,“后浪”OneFlow 有没有机会
机器学习的Softmax定义和优点
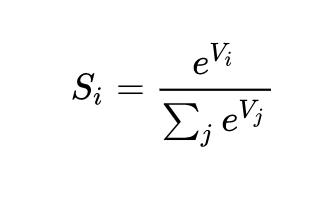
使用Softmax的信息来教学 —— 知识蒸馏
基于EAIDK的人脸算法应用-源码解读(2)
Sobel算子原理介绍与实现方法
解析OneFlow Element-Wise算子实现方法
解析OneFlow BatchNorm相关算子实现
深度学习编译器之Layerout Transform优化
PyTorch教程4.4之从头开始实现Softmax回归






 工商网监
工商网监
评论