 重塑翻译与识别技术:开源语音识别模型Whisper的编译优化与部署
重塑翻译与识别技术:开源语音识别模型Whisper的编译优化与部署

模型介绍
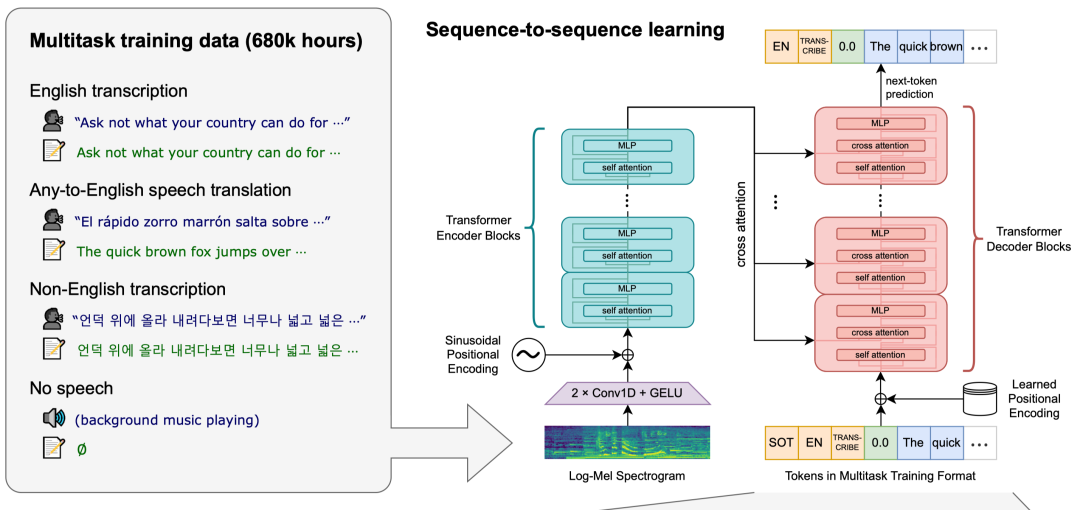
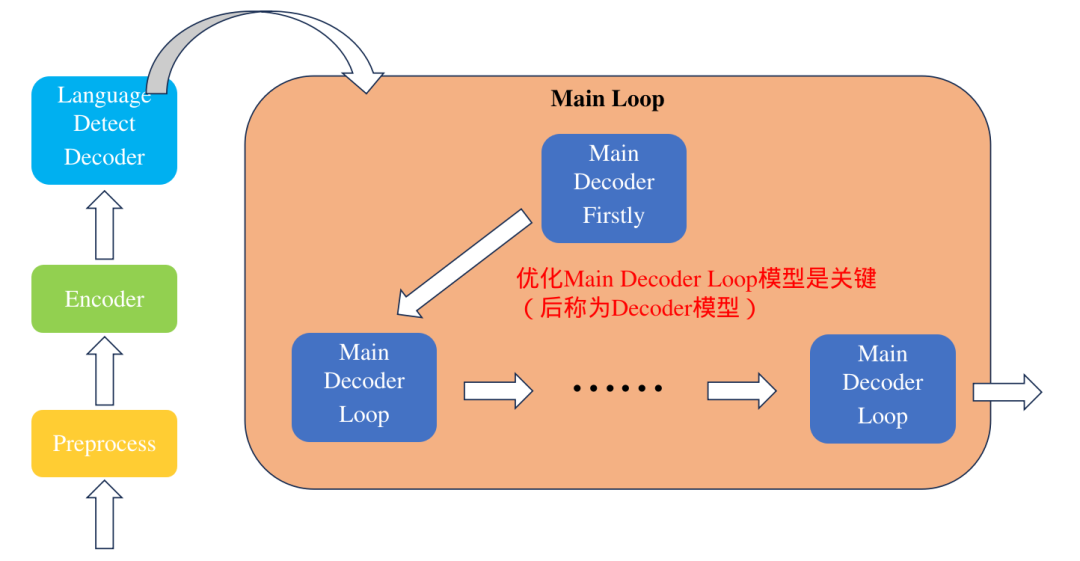
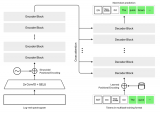
Whisper模型是一个由OpenAI团队开发的通用语音识别模型。它的训练基于大量不同的音频数据集,是一个多任务模型,可以执行语音识别、语言翻译、语言识别。下面是模型的整体架构:
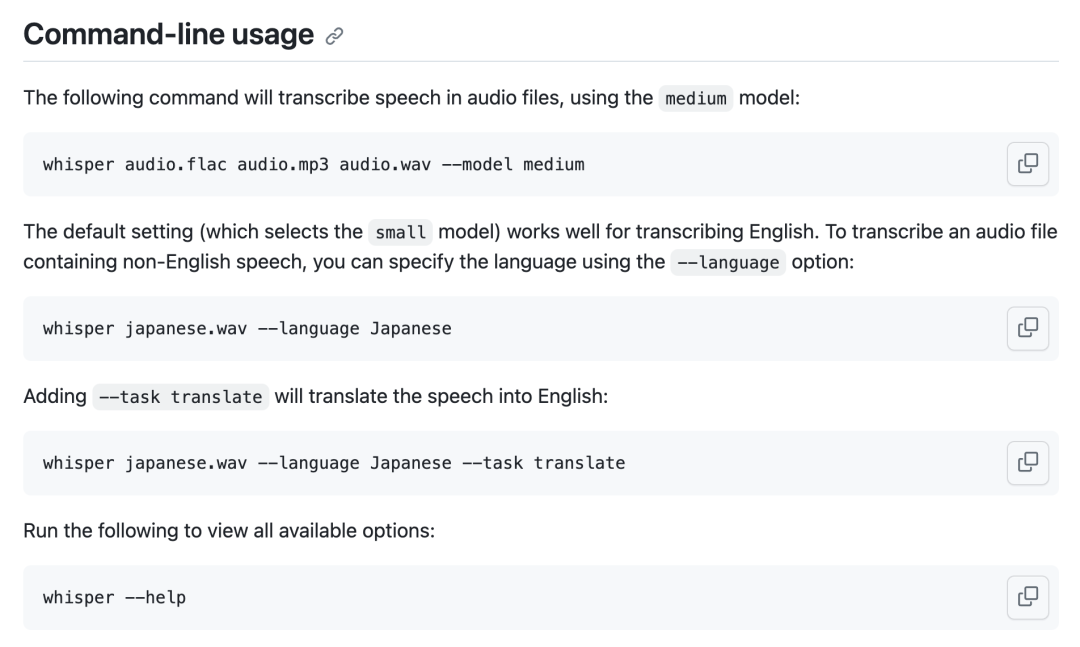
使用方法如下:
通过修改TPU-MLIR编译器代码,可以对Whisper模型性能进行深度优化,使得模型在SOPHON BM1684X处理器上运行时间减少到原来的一半,本篇文章将带领大家对Whisper模型进行编译与优化,并完成实际应用的部署。
优化方法
本次模型优化很具有典型性,不仅适用当前模型,对其他模型也有帮助,下面对相关的优化方法进行介绍
Tile算子转广播
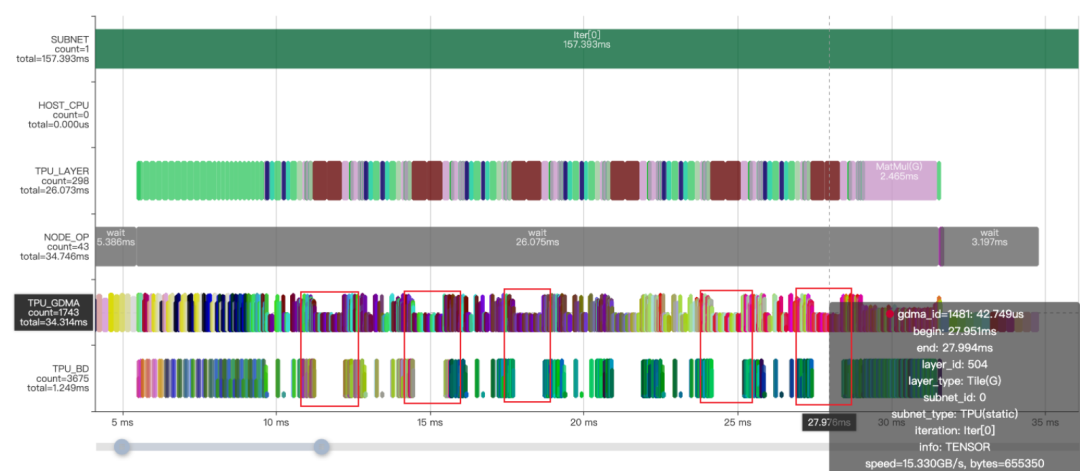
模型转换完成后,观察Profile时序图和对应的MLIR文件,可以看到MatMulOp前面有两个Tile操作,通过复制数据来使数据shape对齐,并且耗时占用十分明显(如红框所示),实际上完全可以利用算子的广播功能实现,解决方法是使MatMulOp在hdim_is_batch的情况下支持n维度的广播 (形如:5x1x8x64@1x1500x8x64 )。

KVCache动态转静态
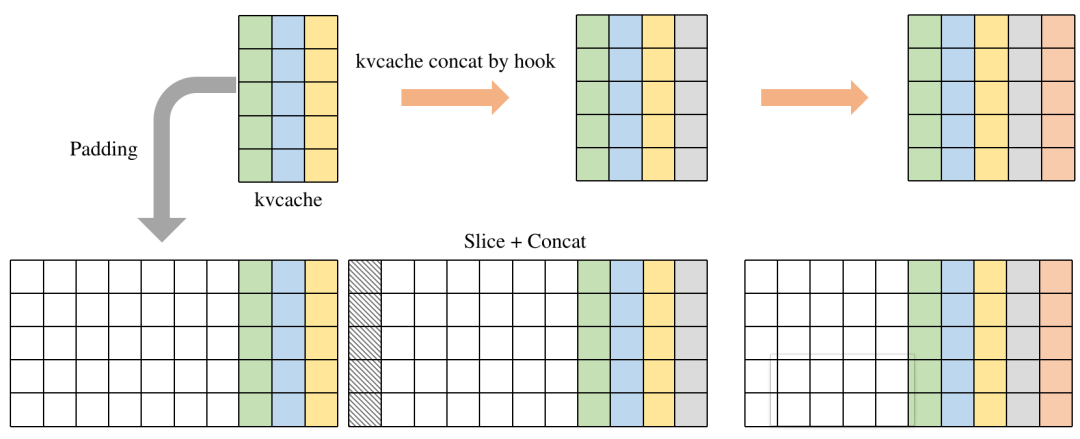
由于模型结构是基于Transformer模型结构构建的,KVCache的使用是比较常见的,对于使用KVCache的模型,我们的做法是,将KVCache作为模型的输入和输出。但在推理过程中KVCache会不断增长,呈现一定的动态性,这就使得有一些数据需要PCIe重复搬运;内存管理比较复杂。通过padding将动态模型转换为输入和输出为固定大小的静态模型,并且在内部利用Slice和Concat算子自动完成数据拼接,减少外部内存处理复杂性,而且通过优化runtime过程避免多余的PCIe搬运。
Permute算子消除
完成上面两步优化后,通过观察Profile时序图和分析final.MLIR文件发现,这一部分的网络被分为了两个LayerGroup,之间还存在许多Global Layer,这些都会导致额外的数据搬运。追溯这一现象的原因,很大可能是由于Slice、Concat和Permute三种操作的存在阻断了LayerGroup的划分。而且Permute、Concat和Slice的GDMA操作带宽利用率低,浪费了较多时间。下面从这三个算子入手进行优化。
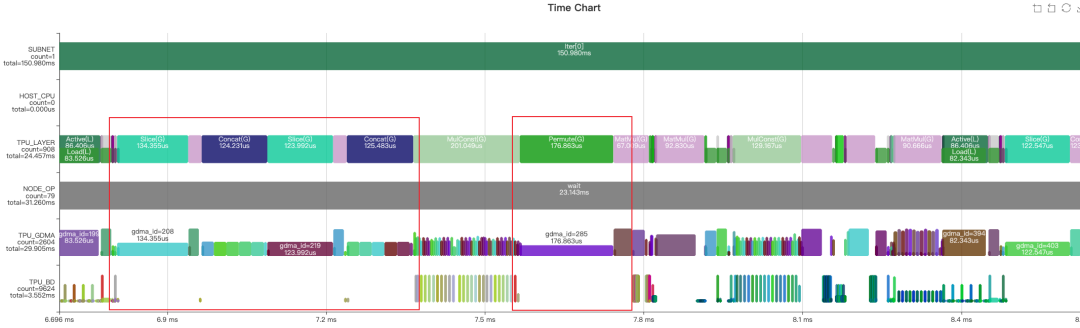
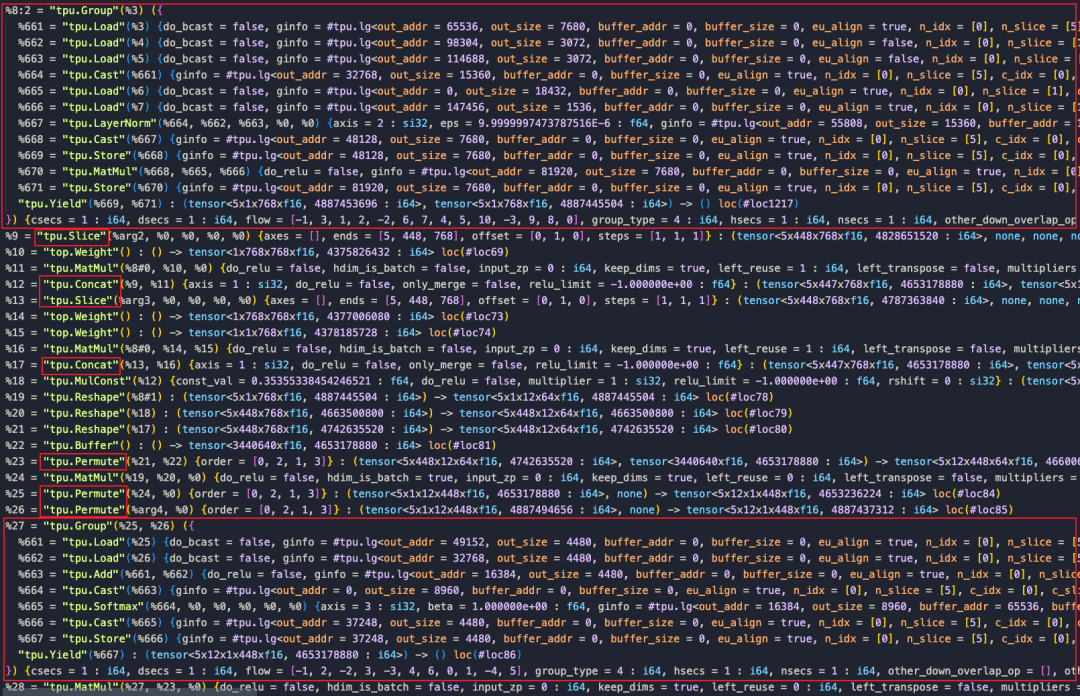
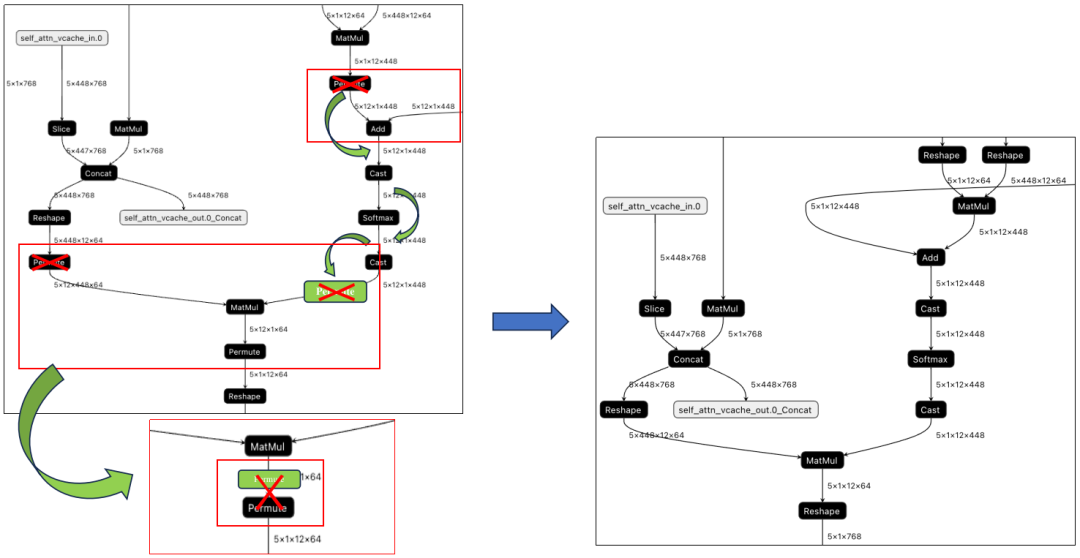
在Transformer类的模型里,由于数据需要维度翻转整理,造成模型里有很多的Permute操作,但是通过算子的实现,一些运行前后的Permute是可以相互抵消的。如下图所示,MatMul算子输入和输出的Permut是可以消除的,主要步骤是将输入的Permute算子移动到输出,MatMul利用TPU指令的特性,实现转置的矩阵乘法,并在输出处与原来的Permute抵消掉。最终结果下图右侧所示。
Slice+Concat算子融合
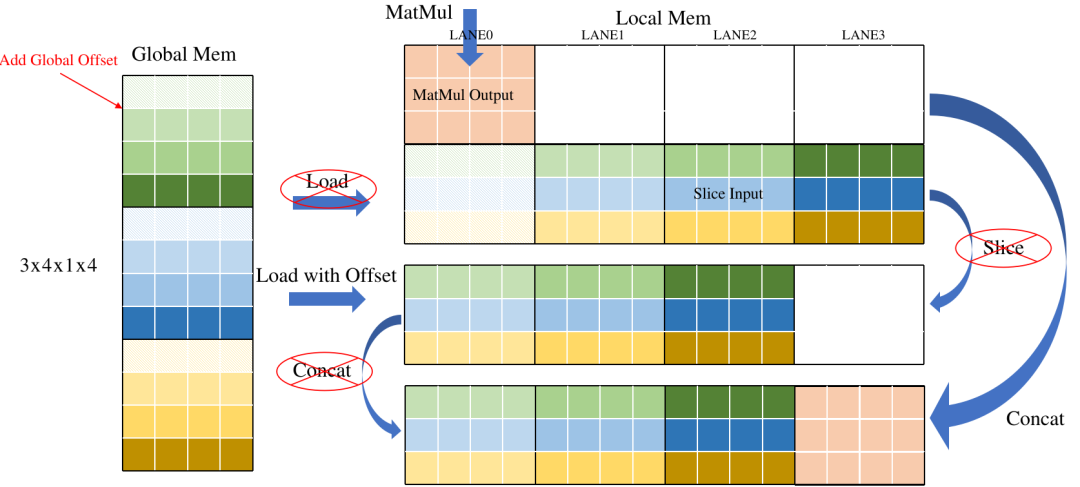
Slice和Concat本质上是将已经计算好但放置位置错误的结果进行截取或搬运。如果我们能提前知道结果应该放到哪里,就可以完全去掉这两种操作。下面是一个典型的Slice+Concat的Pattern。通过分析右图,可以看到为了将数据排到前面,Slice将Load后的数据进行搬运,之后Concat将MatMul的结果搬运到Slice后数据后面。其实这两次搬运如果提前知道了放置位置,是可以去掉的。
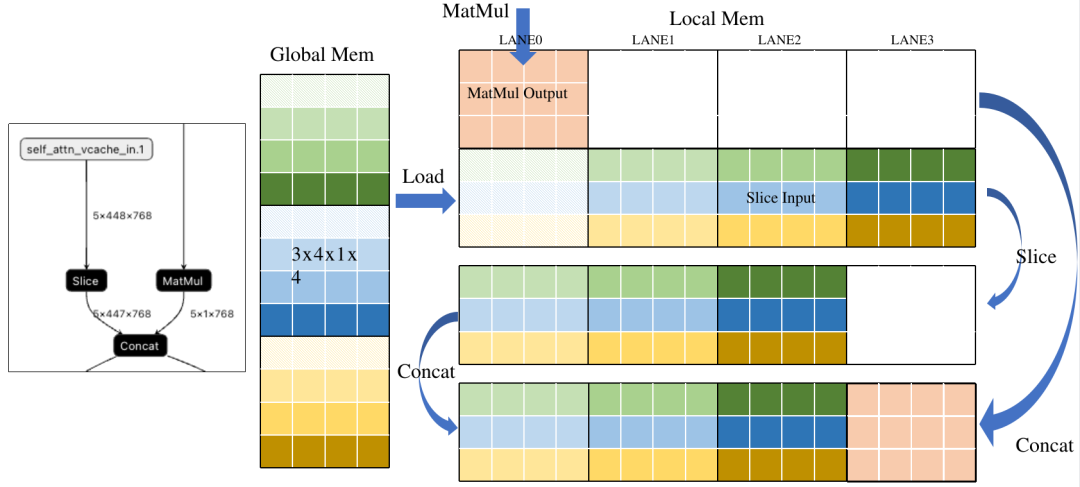
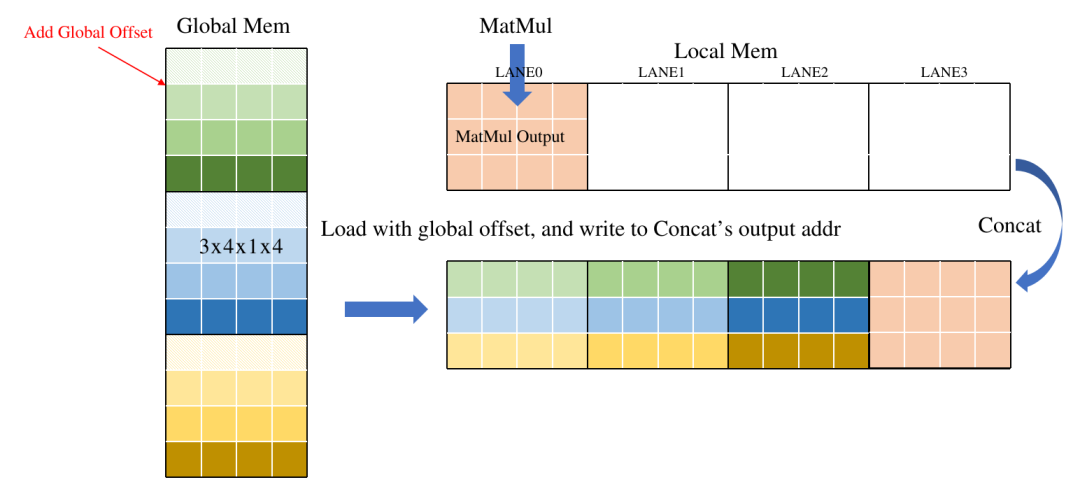
下图示意了简单的优化方法,在Load操作中引入一个Offset参数,表示数据在Global中的偏移,相当于在Load时直接做Slice, 减少了重复数据搬运,另外直接将Concat的输出地址分配给Load,将数据直接写在Concat的输出地址,省去Concat的GDMA搬运时间。
最终效果如下:
可以对比下优化前后的final.MLIR文件

比较上面两图,可以看到Concat和Slice, Permute大部分都去掉了。从下面的Profile也可以看出明显的提升:
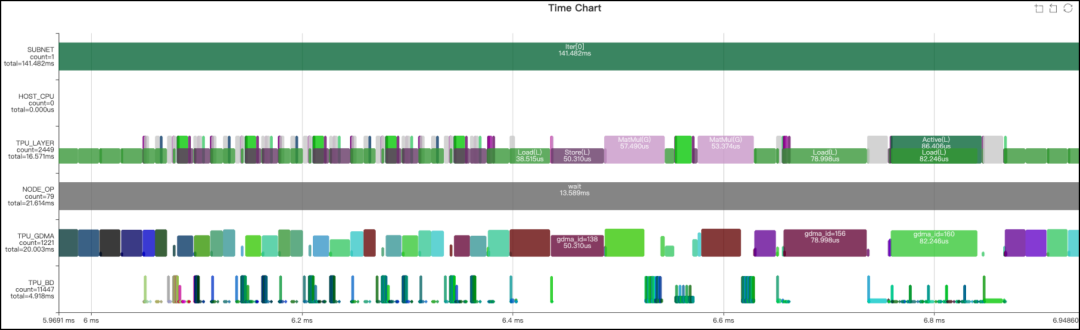
优化结果
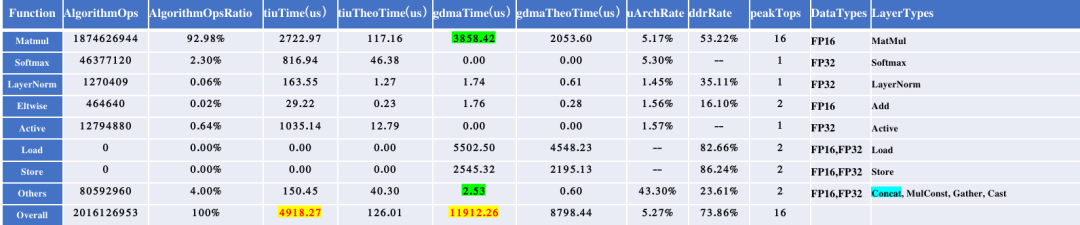
经过上述优化,模型的运行时间由原来的23.143ms变为13.589ms。为方便定量分析,下面提供了优化前后的算子性能统计结果。
优化前性能统计

优化后性能统计
部署代码
部署代码目前已经开源(https://github.com/JKay0327/whisper-TPU_pyd)。本Whisper应用整体是由多个环节串联起来的,包括前处理、Encoder、Language Detect Decoder、以及主循环中的Decoder迭代过程。上面优化的主要是针对主循环中的Decoder模型进行的。具体运行过程如下图所示。
使用方法如下: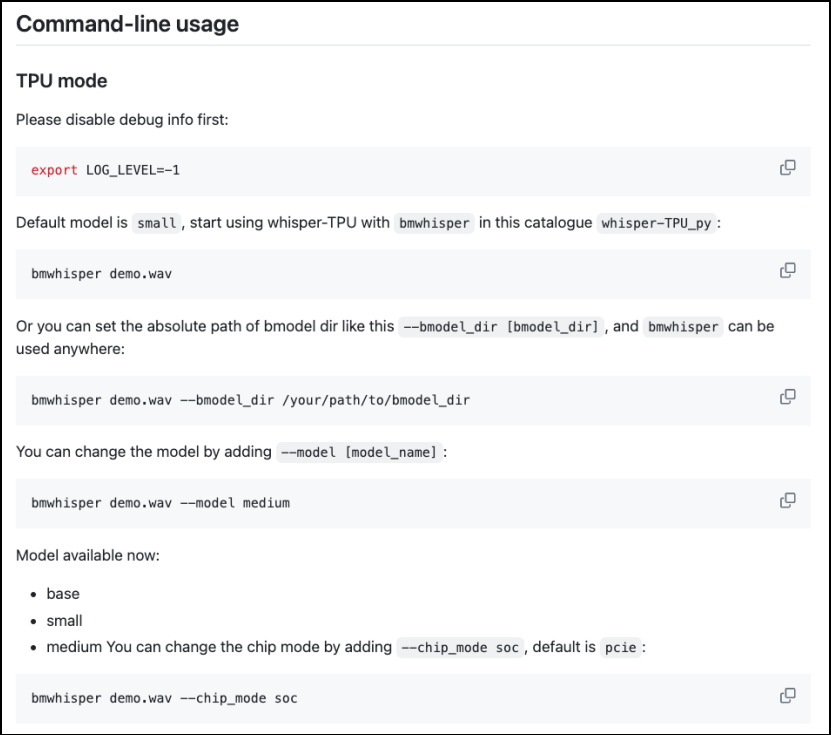
下面是实际的运行结果展示: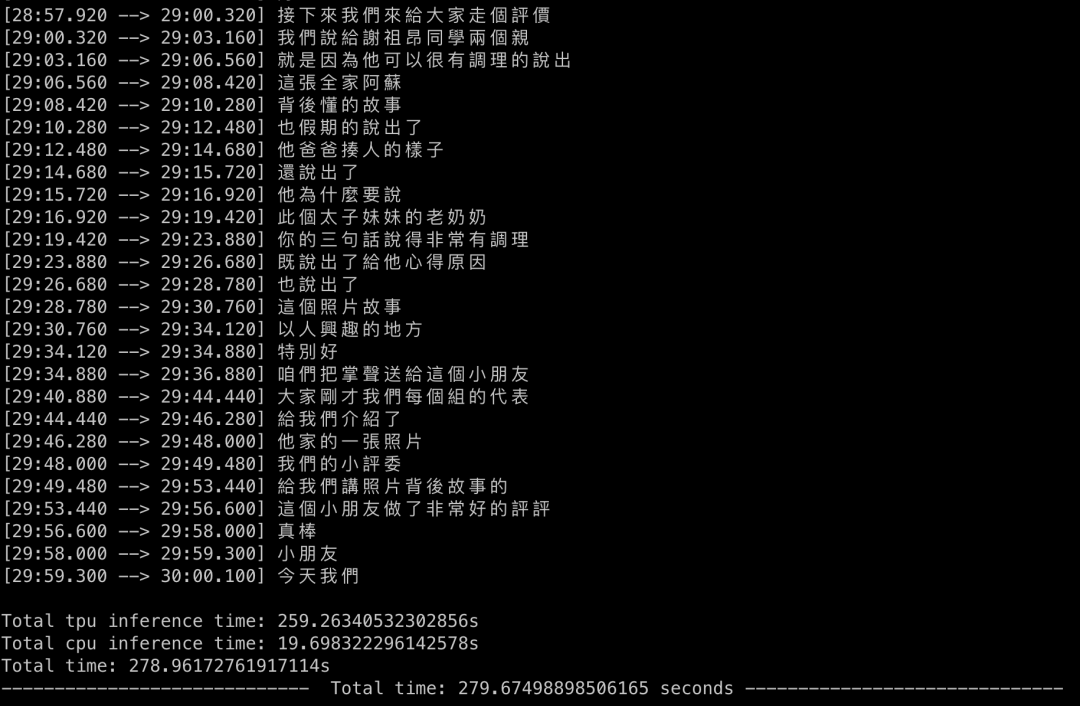
结论
本文是对在Whisper模型应用过程中的总结,说明了在模型优化过程中采用的各种思路和方法,最终将模型的性能翻倍。Whisper模型是一个很有价值的应用,可以实现各种语音任务,期待大家借助算能产品进行更多功能的开发。
-
语音识别
+关注
关注
39文章
1828浏览量
116326 -
模型
+关注
关注
1文章
3865浏览量
52324 -
音频数据
+关注
关注
0文章
13浏览量
10133
发布评论请先 登录
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
【HarmonyOS HiSpark AI Camera】基于图像的手语识别机器人系统
用英特尔CPU及GPU运行OpenAI-whisper模型语音识别
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程

广和通发布自研端侧语音识别大模型FiboASR
瑞芯微(EASY EAI)RV1126B 语音识别




评论