 大模型训练loss突刺原因和解决办法
大模型训练loss突刺原因和解决办法
最近阅读了《A Theory on Adam Instability in Large-Scale Machine Learning 》这篇论文。比较全面的阐述了100B以上的大模型预训练中出现loss spike的原因(loss 突然大幅度上涨),并介绍了一些可能的解决办法。论文写的非常精彩,但整体上有点散和深,我尝试着站在工业立场上把它串一下
突刺是什么
首先介绍一下什么是loss spike:
loss spike指的是预训练过程中,尤其容易在大模型(100B以上)预训练过程中出现的loss突然暴涨的情况
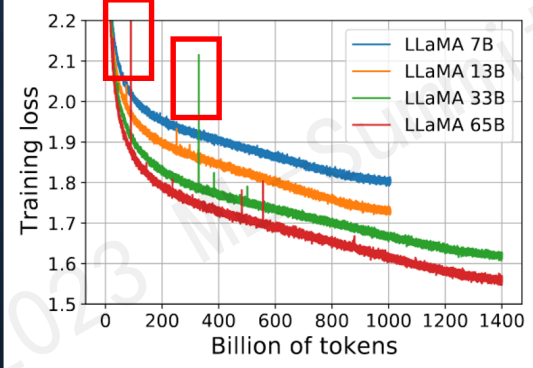
如图所示模型训练过程中红框中突然上涨的loss尖峰loss spike的现象会导致一系列的问题发生,譬如模型需要很长时间才能再次回到spike之前的状态(论文中称为pre-explosion),或者更严重的就是loss再也无法drop back down,即模型再也无法收敛
PaLM和GLM130b之前的解决办法是找到loss spike之前最近的checkpoint,更换之后的训练样本来避免loss spike的出现。
突刺成因分析
这篇论文(以下称本文)对loss spike的出现原因做了十分详细的分析,最后认为预训练使用的Adam优化器是导致这个现象出现的重要原因之一
首先回顾一下Adam优化器的结构(这里介绍的是较为传统的Adam优化器,现在nlp任务更偏向于使用带有正则化项的Adamw变体):
其中均为超参数( ,防止除0),表示第t次更新的梯度, 的初始值 为0。
本文首先对Adam的有效性做了论述,其本质在于证明了Adam优化过程是对牛顿下降法(二阶导)的一个有效逼近,因此在收敛速度上大幅度领先传统SGD(一阶导),证明过程不做赘述,可以参考本文和Adam系列相关论文
Adam算法是牛顿下降法的一个迭代逼近

一切显得十分完美,但是理想很丰满,现实很骨感,收敛过程并不是一帆风顺的
首先我们想象一下这个更新参数的变化趋势
在 的时候, ,, 集中在 附近。而在训练到最后,假设模型收敛到某个最优点,此时 应该集中在0附近。也就是说,我们似乎可以把更新参数的变化过程想象成为一个从两端(非稳态)向中间(稳态)收拢的过程。实际的观察现象也是如此:
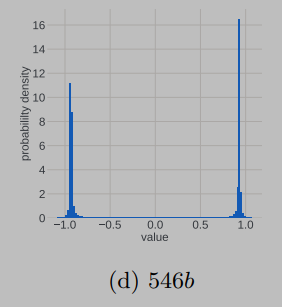
非稳态
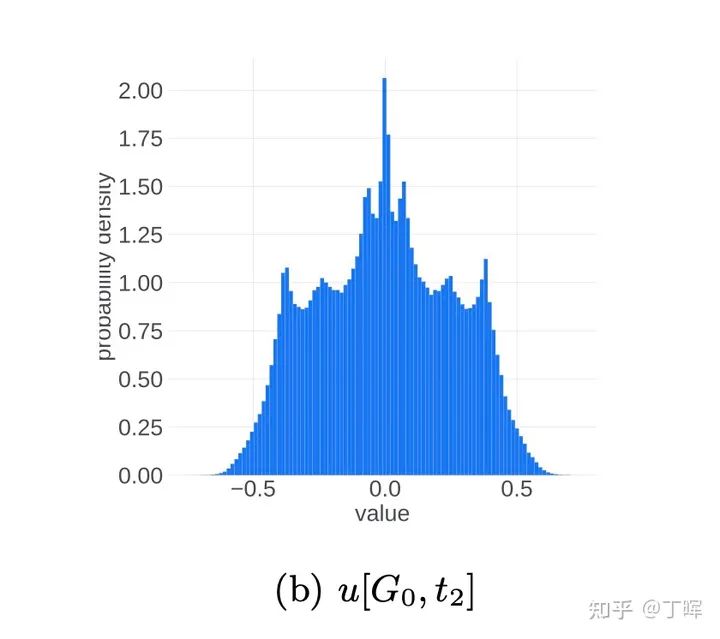
中间态
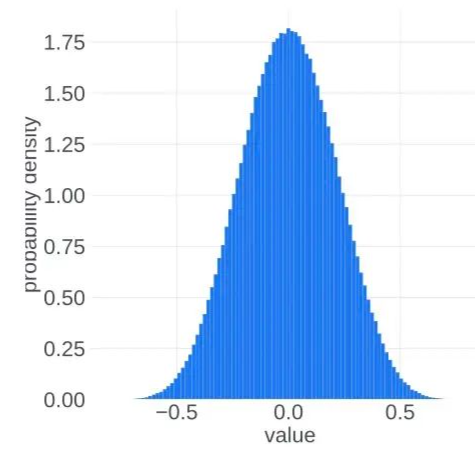
稳态
进入正态分布的稳态之后,理想的更新参数变化趋势应该是方差越来越小,所有更新参数逐渐向0靠近。这应该是一个单向的过程,即稳定的单峰状态(unimodal)不会再次进入非稳定的双峰状态(bimodal),但事实并非如此,更新参数会再次进入非稳定的双峰状态
本文在理论层面做了研究和解释,从中心极限定理(可以结合道尔顿板实验理解)出发,认为随机事件的叠加进入单峰的正态分布的必要条件之一是各个随机事件事件之间应该是相互独立的,但是梯度变化以及更新参数的变化并不能特别好的满足独立性这一条件,而这一点恰恰是导致更新参数振荡,loss spike出现以及loss 不收敛的重要原因之一

造成梯度变化不独立的原因(1、浅层参数长时间不更新2、batch太大,后期梯度更新趋于平稳)上述的理论有些晦涩,本文作者可能也了解这一点,之后开始直接点题,结合实验观察抛出了重要现象和结论
即训练过程中loss spike的出现与:梯度更新幅度, 大小,batch大小这三个条件密切相关
本文作者对loss spike出现时模型的前后变化做了仔细拆解,发现下列一系列连续现象的出现导致了loss spike:

当前模型处在稳态(健康状态),即单峰的正态分布状态,并且梯度值 ,此时loss平稳,训练过程正常

2.模型浅层(embedding层)梯度 ,这一般是由于训练一段时间之后,浅层的语义知识表示此时一般已经学习的较好。但此时深层网络(对应复杂任务)的梯度更新还是相对较大

3.一段时间浅层(embedding层)梯度 之后会导致 , 。此时趋于0。因此导致浅层参数得不到更新(也对应于上述参数更新事件不独立的原因)

4.此时虽然浅层(embedding层)参数长时间不更新,但是深层的参数依然一直在更新。长时间这样的状态之后,batch之间的样本分布变化可能就会直接导致浅层(embedding层)再次出现较大的梯度变化(可以想象成一个水坝蓄水太久终于被冲开了。至于小模型为什么不会出现这种情况,推测是小模型函数空间小,无法捕获样本的分布变化,越大规模的模型对样本之间不同维度的特征分布变化越敏感),此时 , 再次集中在 附近(此时 , ),变成双峰的非稳定状态,本文提到了浅层(embedding层)这种突然的参数变化可能造成模型的连锁反应进而出现loss spike的现象(这也对应了更换样本重新训练有可能会减少loss spike的出现频率,实际上就是选择分布变化较小的样本,减小浅层梯度变换幅度)

5.这个阶段模型处于非稳态,梯度变化幅度较大,每一次的梯度变化和更新参数变化事件之间又出现了一定的独立性,因此经过一定的时间之后模型有可能再次进入稳态,loss再次drop back down(注意,本文着重提了这个再次drop back down并不是一定出现的,也很有可能loss长期处于flat状态,再也无法收敛)
因此我们得出一些结论,loss spike的出现和浅层的梯度更新幅度, 大小密切相关(batch大小带来的相关性问题倒是显得没那么大说服力),实际上就是浅层网络参数突然进入到了之前长时间不在的状态与模型深层参数当前的状态形成了连锁反应造成了模型进入非稳态。同时一般情况即使出现loss spike也会自动回复到正常状态,但也有可能再也不会
突刺解法
本文最后提到了防止loss spike出现的一些方法:
1.如之前提到的PaLM和GLM130B提到的出现loss spike后更换batch样本的方法(常规方法,但是成本比较高)
2.减小learning rate,这是个治标不治本的办法,对更新参数的非稳态没有做改进
3.减小 大小。或者直接把 设为0,重新定义
在等于0时候的值(这应该是个值得尝试的办法)
值得一提的是智谱华章在本文发表之前,在去年的GLM130B训练时似乎也观察到了浅层梯度变化和loss spike相关这一现象(GLM-130B: An Open Bilingual Pre-trained Model),他采取的是把浅层梯度直接乘以缩放系数 来减小浅层梯度更新值

出自130b

其实这块我有个自己的想法,和是否也可以做衰减,随着训练过程逐渐减小,来避免loss spike的现象
另外假设我们能一次性加载所有样本进行训练(实际上不可能做到),是否还会出现loss spike的现象
最后目前流行的fp8,fp16混合训练,如果upscale设置的过小,导致梯度在进入优化器之前就下溢,是不是会增加浅层梯度长时间不更新的可能性,进而增加loss spike的出现的频率。(这么看来似乎提升upscale大小以及优化 大小是进一步提升模型效果的一个思路)
审核编辑:黄飞
-
Palm
+关注
关注
0文章
22浏览量
11283 -
人工智能
+关注
关注
1791文章
47285浏览量
238546 -
大模型
+关注
关注
2文章
2454浏览量
2725
原文标题:大模型训练loss突刺原因和解决办法
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
电脑开机启动时提示(显示)NTLDR文件丢失解决办法及原因分
音箱没声音的原因和解决办法
板式给料机链条磨损过快原因分析和解决办法
空气开关跳闸常见原因、解决办法和卸下步骤
PCBA加工焊点拉尖产生的原因及解决办法
电感啸叫的原因和解决办法





 工商网监
工商网监
评论