 HTAP在快递行业助力时效分析的落地实践
HTAP在快递行业助力时效分析的落地实践
当前,网购已经成为千家万户主要的购物方式,随着快递体 量的飞速膨胀,分析时效成了摆在快递公司面前的重要课题,有 没有办法既能降低成本又能提升时效呢?
整个快递的生命周期可以用“收发到派签”五个字概括。“收” 是指用户下单,快递小哥来收件,网点建包;“发”是指快递在转 运过程中发往运转中心,发往目的地;“到”是指末端中心到件,分拣到网点;“派”是指派件网点分拣,快递小哥开始派件;“签” 是指快递小哥派件以后,客户签收。
中通快递有一套完善的自研的大数据平台(见图 2-3-1 ), ETL(Extract Transformation Load,抽取、转换、装载)数据建模 支持到半小时的级别。中通快递大数据平台支持多种数据源的接入,如关系数据库 MySQL 、Oracle,文档数据库 MongoDB 以及 Elasticsearch(ES)。基本上,所有实时任务都是通过大数据平台 来管理的,支持 Kafka、消息队列(MQ)等的接入。不论是离线 ETL 还是 Spark/Flink 的实时任务,都通过大数据平台接入整个大 数据的计算集群,最终进行计算。计算分析的结果再通过大数据 平台提供给使用方:一是将数据推送到数据应用端,用于分析和报表;二是提供给 OLAP 的查询引擎,供用户或其他系统查询。
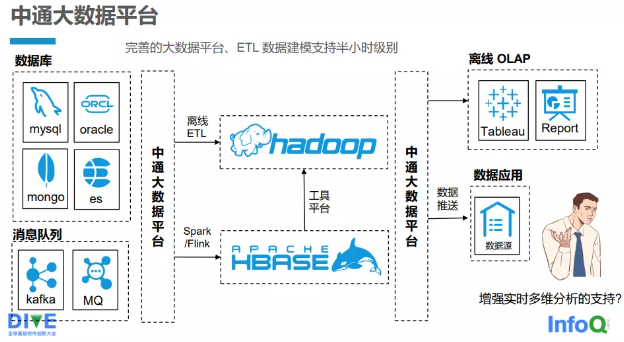
图 2-3-1 中通快递自研大数据平台
2.3.1 1.0 时代:满足业务和技术需求 1. 业务与技术需求分析
大数据平台首先要满足业务的需求。中通快递的业务具有如下特点:
1)体量很大:业务发展很快,数据量很大,而且每笔订单会 有 5~6 次更新,甚至更多次更新。
2)分析周期长:业务方要求的数据分析所覆盖的周期越来越长。
3)时效要求高:对分析时效的要求也越来越高,已经不满足于 T+1 离线计算,或者半小时级别的分析。
4)多维度:技术方案支撑多维的灵活分析。
5 )可用性要求高:要突破单机性能瓶颈、单点故障,缩短甚至消除故障恢复时间。
6)并发高:QPS(Queries Per Second,每秒查询率)高,应用要求达到毫秒级的响应。
以技术为出发点,需要实现:
1)打通多个业务场景,设置多个业务指标。
2)实现强一致的分布式事务,实现原有业务模式切换代价小。
3)分析计算的工程化,以及离线存储过程。
4)支持高并发写、高并发更新。
5)支持二级索引与高并发查询。
6 )支持在线维护,单点故障对业务无影响。
7 )支持热点自动调度。
8)与现有技术生态紧密结合,做到分钟级的统计分析。
9)支持 100 以上列的大宽表,支持多维度的查询分析。
2. 重构时效系统
基于上述业务需求和技术需求,中通快递引入了 TiDB,将多条业务线接到 TiDB 上,包括数据中台、实时宽表、时效分析、 大促看板等。
中通快递的时效系统是对原有时效系统的重构。原来的时效 系统整体架构(见图 2-3-2)比较简单,消费队列通过消息程序把 所有数据写入到数据库,最终在数据库上建立很多存储过程,来 对数据进行统计分析,最终将统计分析的结果提供给应用程序用于查询。
图 2-3-3 是升级后的时效系统架构。
在原有的架构上,升级后的时效系统引入了 TiDB 和 TiSpark,消息接入 Spark/Flink,最终的数据写入 TiDB。把原来 的存储过程全部下线,替换成 TiSpark。数据会写入两端:轻量 级的汇总数据直接写入 Hive(Hadloop 的一个数据仓库工具),通过 OLAP 对外提供查询服务;中途汇总的数据,直接写入关系数据库,如 MySQL。另外,每日使用 DataX 将 T+1 的数据从 TiDB 的数据库同步到 Hive,以便在第二天做离线的 ETL(提取、转换、加载)操作。
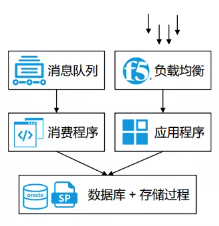
图 2-3-2 中通快递原来的时效系统整体架构
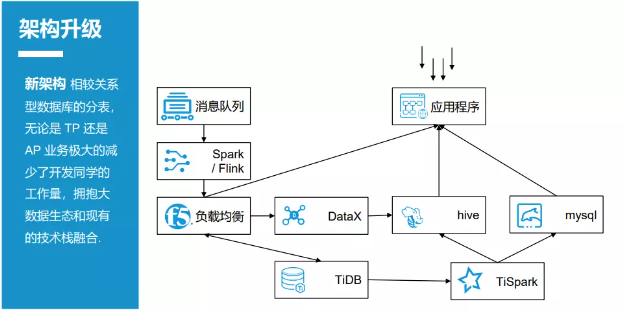
图 2-3-3 升级后的时效系统架构
升级后的时效系统架构相较以前的关系数据库的分表,无论是 TP 业务还是 AP 业务,都极大地减少了开发人员的工作量,并且把原来的消息接入切换成大数据的 Spark / Flink,拥抱了现有 的大数据生态,和现有的技术栈融合。
整个架构的升级带来了很多收益。
1)已有系统的数据存储周期从原来的 15 天增加到 45 天, 接下来会到 60 天,以后甚至会更长。在扩展性方面,升级后的架 构能支持在线的横向扩展,随时上下线存储和计算节点,对此应 用基本上是无感知的。
2)在高并发方面,升级后的架构能满足高性能的 OLTP 业务 需求,查询性能略低于原系统,但是满足需求。
3 )数据库单点的压力没有了,实现了 TP 和 AP 的“分离”, 做到了资源隔离。
4)支持更多维度的业务分析,满足了更多业务分析的需求。
整体架构清晰,可维护性增强,相比之前的存储过程,升级 后整个架构体系非常清晰。
3. 大宽表建设
接下来给大家简单地介绍中通快递的大宽表建设情况,如 图 2-3-4 所示。
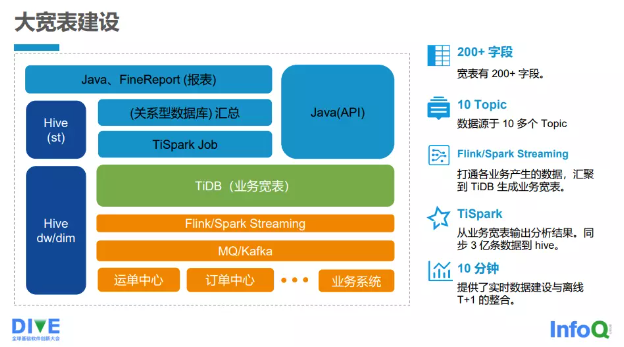
图 2-3-4 大宽表建设情况
1)目前宽表有 200 多个字段,至今还在继续增加。
2)接入了 10 多个主题(Topic)数据来源。
3)打通各业务产生的数据,并汇聚到 TiDB 生成业务宽表,借助流处理系统 Flink/Spark Streaming 把各个业务端的数据最终 写入 TiDB 的宽表。
4)借助 TiSpark,从业务宽表输出分析结果,同步 3 亿余条数据到 Hive。
5)提供实时数据建设与离线数据 T+1 的整合,基本上可 在 10min 以内完成。
下边是各个接入端,如运单中心、订单中心等以及其他业务系统,接入端会把业务写入 MQ/Kafka。Flink/Spark Streaming 会将 Kafka 里面的消息写入 TiDB 的宽表 (TDB)。TiDB 的宽表上面是 TiSpark,它会通过 TiSpark 的批处 理最终将数据写入 DW 或者 DIM 层,也会将一些汇总数据写入 ST 层,而逐步汇总的数据会写入关系数据库。最终 Java 应用或者 FineReport 报表,会读取关系数据库的汇总数据以及 ST 层的数据。
另外,宽表也会对外提供大量 API 的服务,数据中台、时效系统、数据看板系统等产品,都会调用宽表提供的数据服务。在使用的过程中,我们也遇到了很多问题,我总结为量变引起质变。
1 )热点问题:在业务高峰时,索引热点较为突出,很多业务是基于时间来查询的,在连续的时间段写入或更新会导致索引的 热点。在大促的时候尤为明显,这样会导致部分 TiKV 的压力非常大。
2)内存碎片化的问题:在系统运行稳定一段时间之后,大量的更新和删除会导致内存碎片化。这个问题已经在后续的版本中修复,系统升级之后没有发现异常。
3)正确使用参数的问题:当读取的数据量达到总体数据量的 1/10 以上时,建议关闭 tispark.plan.allow_index_read 参数。因为在这种情况下,这个参数的收益会变成很小,甚至会带来一些负收益。
4. 运维监控
TiDB 已经有很丰富的监控指标,它使用的是现在主流的 Prometheus + Grafana,监控指标非常多、非常全。TiDB 支持用户的线上业务,同时也支持开发人员查询数据,因此可能会遇到一些异常的操作,甚至遇到一些 SQL 影响 Server 运行,对生产产生影响。基于 TiDB 提供的监控功能,并针对使用过程中遇到 的一些问题,我们自建了自动监管和告警系统,监控线上特殊账 号的慢查询,自动“杀掉”异常 SQL,并通知运维和应用负责人。我们还开发了查询平台让用户使用 Spark SQL 去查询 TiDB 的数 据,兼顾了并发和安全。对一些很核心的指标,我们额外接入了自研的监控,将核心的告警信息电话告知到相关的值班人员。
2.3.2 2.0 时代:HTAP 提升
业务方的需求不断升级,他们不再满足于数据存得越来越多,还希望系统跑得更快,不仅希望系统要满足分析数据周期的增长,还希望更快地感知业务的变化。下游系统需要更多的订阅信息,希望信息不满足需求时,能主动调取。在开展大促活动时,TiKV 的压力非常大,我们需要真正地实现计算和存储分离。集群太大,不容易管理,问题排查很困难。所以,我们对架构再次进行升级,再次升级后的架构如图 2-3-5 所示。
2.0 时代我们引入了 TiFlash 和 TiCDC,为什么引入 TiFlash?因为 TiFlash 是一个列存数据库,当在 TiDB 上建一条同步链时,整个架构包括 TiDB 都不需要改动。数据写入的整个架构是不变 的,仍然可以通过 Flink/Spark 写入 TiDB 宽表。我们虽然引入了 TiFlash,但是依然保留了部分 TiSpark 任务。由于业务特性,由一些数据汇总得到的结果数据可能会达到了几百万或者上千万的 级别,全部通过 TiFlash 写入 TiDB,时效性跟不上。TiDB 对此 需求提供了后续的解决方案,数据计算会部分切换到 TiFlash 上, TiSpark 和 TiFlash 是共存的。TiSpark 或者 TiSpark 的汇总数据还是会写到 Hive,也有一部分会写到 MySQL,它们都会对外提供数据服务。我们通过引入 TiCDC 把 TiDB 的 Biglog 同步到消息队列里,供下游的业务方使用,进行地域式消费。
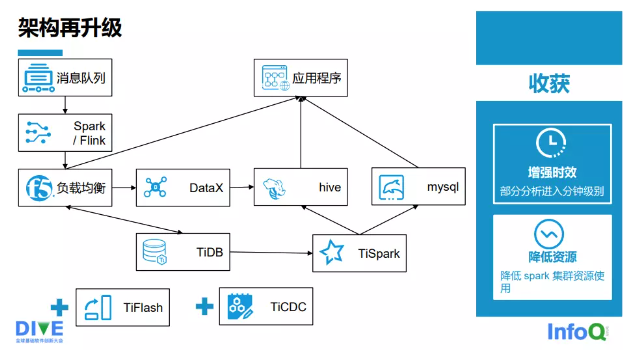
图 2-3-5 再次升级后的架构
架构再升级的收获共有两点:
一 是增强时效,部分分析进入了分钟级,运行间隔从 5~15min 降到了 1~2min。
二是降低了资源的使用,降低了 Spark 集群所需的资源量, 物理节点大概从 137 个降到了 77 个。
2.3.3 3.0 时代:展望未来
未来,仍然有很多问题等着我们处理,也有很多地方需要进 一步提升。
1)监控一直是我们比较头疼的一个问题—我们的集群规模 比较大,指标很多,而且有的时候加载非常慢,排查问题的效率得不到保证。监控虽然很全,但是出了问题无法快速定位,这也 给我们线上排查问题带来了一些困扰。
2 )执行计划偶发不准,会影响集群的指标,导致业务相互 影响。这个情况可能与表的统计信息相关。过去数据清理还是比 较麻烦的,我们现在是通过自己写脚本来支持旧数据的自动 TTL (Time to Live)功能。TiFlash 现在虽然已经支持很多函数知识下 推,但是我们希望可以更多地支持一些应用中遇到的函数。
3)提升集群稳定性。
4)实现 TiSpark 对 TiFlash Batch 的支持。
5)支持用户、资源隔离,避免相互影响。
6)实现分区表支持、数据过滤,提高计算性能。
7)缓解计算抖动问题。
作者介绍
朱友志:中通快递大数据架构师,负责中通大数据基础架构工作。
审核编辑:刘清
-
ETL
+关注
关注
0文章
20浏览量
9405 -
MySQL
+关注
关注
1文章
804浏览量
26531 -
QPS
+关注
关注
0文章
24浏览量
8800 -
OLAP
+关注
关注
0文章
24浏览量
10095
原文标题:HTAP 在快递行业助力时效分析的落地实践
文章出处:【微信号:AI前线,微信公众号:AI前线】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
福田欧马可智蓝ES1快递版有哪些亮点
海康威视助力快递物流行业场景数字化升级
名单公布!【书籍评测活动NO.49】大模型启示录:一本AI应用百科全书

托寄物智能识别——大模型在京东快递物流场景中的应用与落地

云天励飞加速推动大模型行业落地
振弦采集仪的工程安全监测实践与案例分析

海康威视助力快递行业场景数字化
CET中电技术邀您参加第六届综合能源服务落地实践峰会

嵌入式工业一体机在快递柜设备上的应用

杭州掀起快递物流创新浪潮,2024长三角快递物流展7月共绘智慧物流新蓝图






 工商网监
工商网监
评论