 Linux进程管理和启动流程方法
Linux进程管理和启动流程方法
一、计算用户ID总和
使用while read line和/etc/passwd,计算用户id总和。
# 初始化用户ID和总和变量
uid=0
sum=0
while read line; do
# 从 /etc/passwd 文件中提取用户ID
uid=$(echo "$line" | cut -d':' -f3)
# 将用户ID添加到总和中
sum=$((sum + uid))
done < /etc/passwd
# 输出ID总和
echo "用户ID总和为:$sum"
上面的脚本首先定义了两个变量 uid 和 sum,分别用于存储当前行的用户ID和所有用户ID的总和。然后使用 while 循环逐行读取 /etc/passwd 文件的内容,每次循环提取当前行的第三个字段,也就是用户ID,并将它加到总和变量中。最后输出所有用户ID的总和。
需要注意的是,脚本执行需要 root 权限才能读取 /etc/passwd 文件。如果没有权限,则需要使用其他方式获取用户列表。
二、数组/字符串处理/高级变量
总结索引数组和关联数组,字符串处理,高级变量使用及示例。
索引数组和关联数组
在Bash中,数组是一种数据结构,可以用来存储一组值。Bash中支持两种类型的数组:索引数组和关联数组。
# 定义一个索引数组
my_array=("apple" "banana" "orange")
# 访问数组中的元素
echo ${my_array[0]} # 输出 "apple"
echo ${my_array[1]} # 输出 "banana"
echo ${my_array[2]} # 输出 "orange"
-
索引数组:索引数组是按照数字索引访问元素的数组类型。在Bash中,索引从0开始。可以使用下标语法获取数组元素的值。例如:
-
关联数组:关联数组是一种根据键名(字符串)访问元素的数组类型。定义关联数组时需要使用声明 -A。可以使用键名访问数组元素的值。例如:
# 定义一个关联数组
declare -A my_array
my_array["红"]="苹果"
my_array["黄"]="雪梨"
my_array["橙"]="橘子"
# 访问数组中的元素
echo ${my_array["红"]} # 输出 "苹果"
echo ${my_array["黄"]} # 输出 "雪梨"
echo ${my_array["橙"]} # 输出 "橘子"
需要注意的是,Bash的版本需要在 4.0 及以上才支持关联数组。
字符串处理
Bash中有很多内置的字符串处理工具和技巧,可以对字符串进行各种操作。以下是一些 Bash 中常用的字符串处理函数和示例:
-
${#string} 可以获得字符串的长度:
my_string="hello, world"
echo ${#my_string} # 输出 12
-
${stringlength} 可以截取子字符串,其中 start 是子字符串开始的位置, length 是子字符串的长度:
my_string="hello, world"
echo ${my_string5} # 输出 "hello"
echo ${my_string5} # 输出 "world"
-
${string#substring} 可以从字符串的开头删除指定的子字符串,其中 substring 是要删除的子字符串:
my_string="hello, world"
echo ${my_string#hello, } # 输出 "world"
-
${string%substring} 可以从字符串的末尾删除指定的子字符串,其中 substring 是要删除的子字符串:
my_string="hello, world"
echo ${my_string%world} # 输出 "hello, "
-
${string/find/replace} 可以将字符串中的所有指定子字符串 find 替换为 replace:
my_string="hello, world"
echo ${my_string/world/there} # 输出 "hello, there"
-
${string//find/replace} 可以将字符串中的所有指定子字符串 find 替换为 replace,并且不止替换一次:
my_string="hello, world"
echo ${my_string//l/L} # 输出 "heLLo, worLd"
高级变量
在 Bash 中,更加高级的变量设置方式可以让我们更加灵活地控制变量的使用。下面我将介绍一些常见的高级变量赋值方式:
-
${parameter:=word}:当变量 parameter 不存在时,将其赋值为 word。
echo "MY_VAR is ${MY_VAR:=default}"
# 输出 MY_VAR is default
echo "MY_VAR is ${MY_VAR}"
# 输出 MY_VAR is default
-
${parameter:+word}:当变量 parameter 存在时,将其赋值为 word。
MY_VAR="value"
echo "MY_VAR is ${MY_VAR:+default}"
# 输出 MY_VAR is default
echo "MY_VAR is ${MY_VAR}"
# 输出 MY_VAR is value
-
${parameter:?error message}:如果变量 parameter 不存在或者为空,则显示错误信息 error message 并退出脚本的执行。
echo "MY_VAR is ${MY_VAR:?Variable not set}"
# 在 MY_VAR 为空或未定义时,输出 Variable not set 并退出
Bash 中的变量间接引用是一种非常有用的技巧,它允许我们使用一个变量的值作为另一个变量的名称来引用它。这个技巧可以用在很多场景中,比如说根据运行时参数来动态引用变量。
在 Bash 中,变量间接引用可以通过 ${!varname} 的语法来实现。其中 varname 为一个变量名,通过 $ 和 {} 来包围表示这是一个变量名的表达式。${!varname} 表示按照 varname 变量中存储的名称引用另一个变量。
下面是一个例子:
var1="Hello"
var2="World"
varname="var1"
echo "${!varname}, ${var2}!" # 输出 "Hello, World!"
在这个例子中,我们首先定义了两个变量 var1 和 var2,然后将 varname 设为 var1,表示我们希望引用 var1 这个变量。在输出中,我们使用 ${!varname} 引用了 var1 这个变量,从而得到了输出 Hello, World!。
需要注意的是,即使 varname 存储的变量名称是不存在的,${!varname} 表达式依然会被展开,并且其结果为空字符串。因此,在使用变量间接引用时应该特别小心,避免因为引用了不存在的变量而产生不可预测的结果。
三、求随机数大小
求10个随机数的最大值与最小值。
declare -i min max
declare -a nums
for ((i=0;i<10;i++));do
nums[$i]=$RANDOM
[ $i -eq 0 ] && min=${nums[0]} && max=${nums[0]} && continue
[ ${nums[$i]} -gt $max ] && max=${nums[$i]} && continue
[ ${nums[$i]} -lt $min ] && min=${nums[$i]}
done
echo "All numbers are ${nums[*]}"
echo Max is $max
echo Min is $min
四、阶乘算法
使用递归调用,完成阶乘算法实现。
function factorial {
if [ $1 -eq 0 -o $1 -eq 1 ]; then
echo 1
else
echo $[$1*(factorial $[$1-1])]
}
factorial $1
五、进程和线程
解析进程和线程的区别?
进程和线程都是计算机中实现并发的方式,但它们有不同的特点和作用。
进程是操作系统分配资源的基本单位,每个进程都拥有独立的内存空间、代码和数据,进程之间不能直接共享数据。每个进程都有自己的地址空间、堆栈、文件描述符等信息,并且进程之间通过进程间通信(IPC)的方式来进行数据传输。进程的创建、切换和销毁会消耗一定的系统资源,因此进程通常是比较重量级的。
线程是进程中执行任务的最小单位,是进程内部的一个执行路径。线程与进程共享同一份数据和代码段,每个线程都有自己的堆栈和程序计数器,但是所有线程共享进程的虚拟地址空间和物理资源,线程之间可以直接访问同一片内存区域,因此线程之间的通信和数据交换比进程之间更加轻便快捷。线程的创建、切换和销毁所需的系统资源比进程要少得多,因此线程通常是比较轻量级的。
总的来说,进程和线程都是实现并发的方式,但是它们的作用和特点不同。进程是基本的资源分配单位,而线程则是程序执行的最小单位,线程可以更高效地实现并发操作和多任务处理。
六、进程结构
解析进程的结构。
进程是计算机中最基本的资源分配单位,它由操作系统负责创建、管理和调度,进程可以看做是一个程序的执行实例。
进程的结构主要包括以下几个部分:
-
程序段(Code Segment):也称为文本段,是存放程序指令的内存区域,通常是只读的。程序段是进程运行期间不变的部分,它包含了所有可执行指令,程序段在进程创建时就已经确定好了。
-
数据段(Data Segment):数据段存储的是程序中已经初始化的全局变量、静态变量和常量等数据,数据段通常是可读写的。
-
堆栈段(Stack Segment):堆栈段存储着程序执行过程中产生的临时数据和函数调用的返回地址等信息,堆栈段是一个后进先出的数据结构,它的大小可以动态扩展,通常是可读写的。
-
堆区(Heap):堆区是程序执行期间动态申请和释放内存所使用的区域,堆区是可读写的,其大小可以动态调整。
-
进程控制块(Process Control Block,PCB):进程控制块是系统管理进程的数据结构,它包括了进程的基本信息,如进程状态、进程标识符、进程优先级、程序计数器、寄存器等,同时还记录了进程的资源使用情况,如打开的文件、分配的内存等。
以上是进程的主要组成部分,不同操作系统或编程语言中可能会有所差异,但是它们的基本结构都包含了上述的内容。
七、进程的各种状态
结合进程管理命令,说明进程各种状态。
在进程管理中,常见的进程状态有以下几种:
-
运行态(Running):指该进程正在CPU上运行。
-
就绪态(Ready):指该进程已经准备好,只等待CPU分配时间片后就能运行。
-
阻塞态(Blocked):指该进程由于等待某些事件(例如输入/输出、信号等)而无法被执行。
-
创建态(New):表示该进程已被创建,但还没有被操作系统调度运行。
-
终止态(Terminated):表示该进程已经运行完毕或者被强制终止。
在Linux系统中,可以使用ps命令查看进程状态。其中,运行态的进程会被标记为“R”,就绪态的进程则会被标记为“S”,阻塞态的进程会被标记为“D”,终止态的进程会被标记为“Z”,而创建态的进程则不会在进程列表中出现。
在ps aux命令的输出中,STAT表示进程状态。在Linux系统中,进程可以有不同的状态,常见的状态包括:
-
R:进程正在运行;
-
S:进程处于休眠状态,例如等待某个事件的发生,或者正在进行I/O操作;
-
D:进程不可中断的休眠状态,例如等待排队在块设备上的输入/输出;
-
Z:进程被终止,但是它的父进程还没有来得及回收它的资源;
-
T:进程被暂停或者停止。
通常情况下,我们关注的进程状态是R和S,因为它们代表的进程正在运行或者等待CPU以及其他资源。而D和Z状态通常表示该进程出现了异常情况,需要进一步的检查和处理。
八、IPC通信和RPC通信
说明IPC通信和RPC通信实现的方式。
IPC通信(Inter-Process Communication,进程间通信)和RPC通信(Remote Procedure Call,远程过程调用)都是用于不同进程之间进行通信的方式。
IPC通信实现的方式较为多样化,其中最常见的方式包括:
-
管道(Pipe):管道是一种半双工的通信方式,通常用于父子进程之间的通信。管道只支持单向数据传输,它的基本思想是用一个缓冲区作为共享区域来实现父子进程之间的数据交换。
-
消息队列(Message Queue):消息队列是一种消息传递机制,通常用于同一主机内的进程间通信。消息队列提供了一种异步的通信方式,发送方发送消息后即可立即返回,而接收方则可以在需要时从消息队列中取出消息。
-
信号量(Semaphore):信号量是一种用于进程间同步的机制。信号量的作用是保护一段代码,在同一时刻只允许一个进程执行。当一个进程想要执行这段被信号量保护起来的代码时,需要先获取信号量,执行完代码后再释放信号量,以便其他进程能够获取信号量并继续执行。
-
共享内存(Shared Memory):共享内存是一种高效的进程间通信方式。它将一段内存映射到多个进程的地址空间中,多个进程可以直接访问这段共享内存,从而实现数据共享。
RPC通信则通过网络实现跨主机进程之间的通信,其实现方式通常包括:
-
客户端-服务器(Client-Server)模式:在此模式下,客户端应用程序向服务器应用程序发送请求,并等待响应。服务器应用程序接收请求,执行相应的操作,并将结果返回给客户端。
-
远程对象调用(Remote Object Invocation):在此模式下,客户端使用远程对象代理来调用远程对象。远程对象代理掌握着远程对象的网络地址信息,并将请求序列化为网络字节流进行传输,然后等待远程对象返回结果。
-
Web服务(Web Service):Web服务是一种基于HTTP协议实现的RPC机制。客户端通过HTTP请求访问Web服务,Web服务接收请求并调用相应的处理函数,最终将处理结果封装为XML或JSON格式返回给客户端。
九、前台和后台作业
总结Linux,前台和后台作业的区别,并说明如何在前台和后台中进行状态转换。
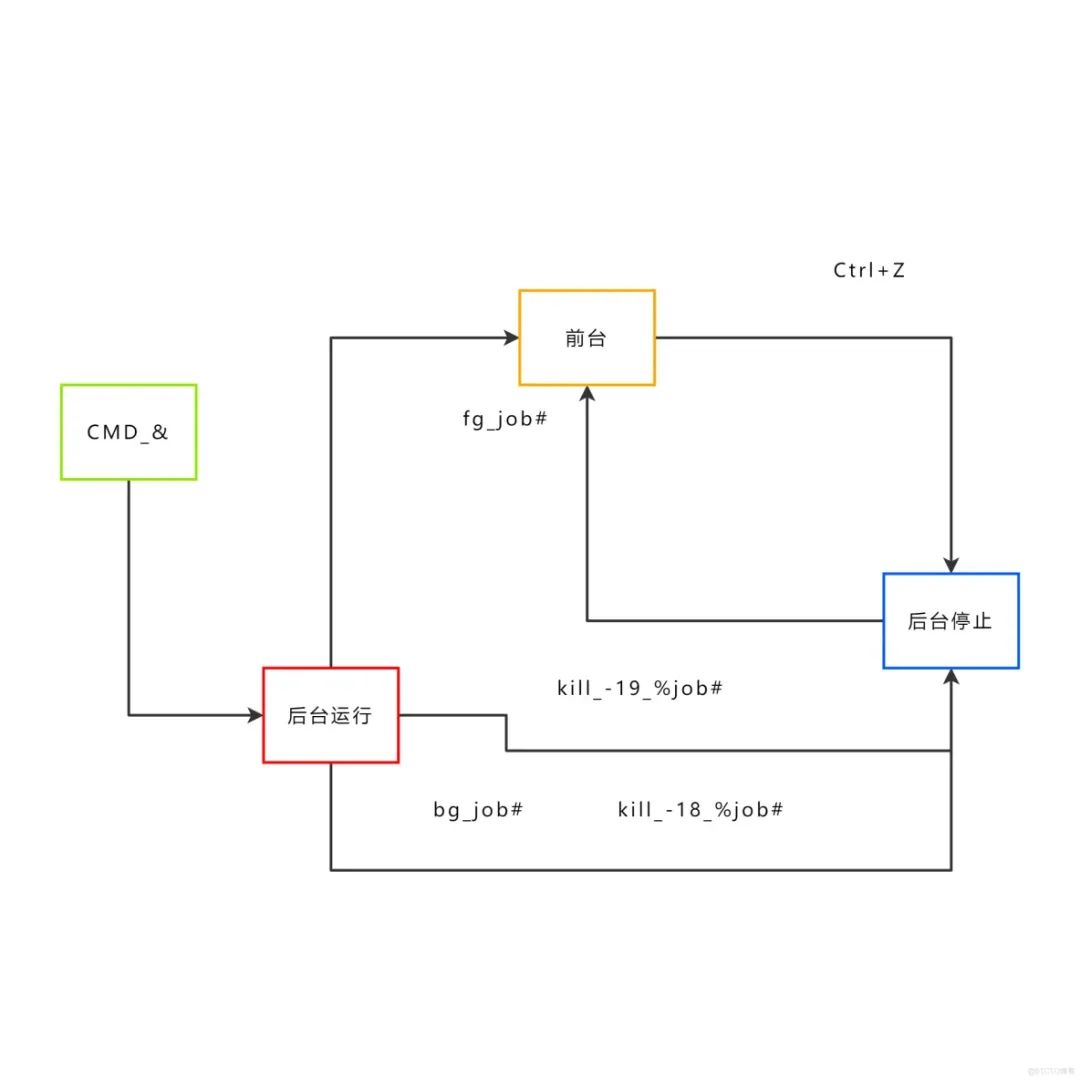
Linux中,前台作业和后台作业的区别在于是否占用当前命令行终端。
前台作业是指当前正在命令行终端中运行的程序,它会占用终端,此时用户需要等待该程序执行完毕才能输入下一个命令。而后台作业是指在后台运行的程序,即该程序不占用当前终端,用户可以继续输入其它命令。
在前台和后台之间进行状态转换有以下两种方法:
-
在前台作业中执行后台作业:
在前台运行的作业可以通过在命令后面添加 "&" 实现将其转为后台作业。例如:
./my-program &
-
在后台作业中切换到前台:
使用命令 fg 可以将后台作业切换至前台,让程序重新占用当前终端。例如:
fg [job ID]
其中, [job ID] 是后台作业的进程号或任务号。
使用命令 bg 可以将前台作业转为后台作业。例如:
bg [job ID]
同样, [job ID] 是前台作业的进程号或任务号。
十、内核设计流派
总结内核设计流派及特点。
内核设计是操作系统的核心组成部分,其设计流派主要有单内核、微内核和混合内核。
-
单内核 单内核是最初的内核设计模式。在单内核中,所有的操作系统服务和驱动程序都运行在核心空间内,这些服务和驱动程序直接访问硬件设备,并且实现了内存管理、进程调度、文件系统等核心功能。这种设计模式的优点是效率高,因为所有服务和驱动程序都在同一个地址空间内工作。缺点是安全性不高,因为一个错误的服务或驱动程序可能会破坏整个系统。
-
微内核 微内核是将内核功能分解成多个独立的程序运行的设计模式,每个程序都运行在独立的地址空间内,只提供最基本的服务。例如,任务调度、内存管理、IPC(进程间通信)和设备驱动程序等服务都是以相互独立的方式运行的。这种设计模式的优点是可靠性和安全性高,因为每个服务都以独立的方式运行,并且错误的服务或驱动程序的影响只限于自己的进程。缺点是性能低,因为由于每个服务都是独立的程序运行,因此在服务之间传递数据需要额外的开销。
-
混合内核 混合内核是单内核和微内核的结合。它将一些核心函数移动到独立的地址空间中,以提高系统的可靠性和安全性,并以较低的开销提供IPC和设备驱动程序等服务。这种设计模式的优点是可靠性和安全性高,同时性能也比微内核设计模式高。缺点是代码复杂性高,因为不同的服务和驱动程序有不同的运行方式和限制,所以必须确保它们之间的协作和一致性。
十一、Linux启动流程
总结rocky启动流程,grub工作流程。
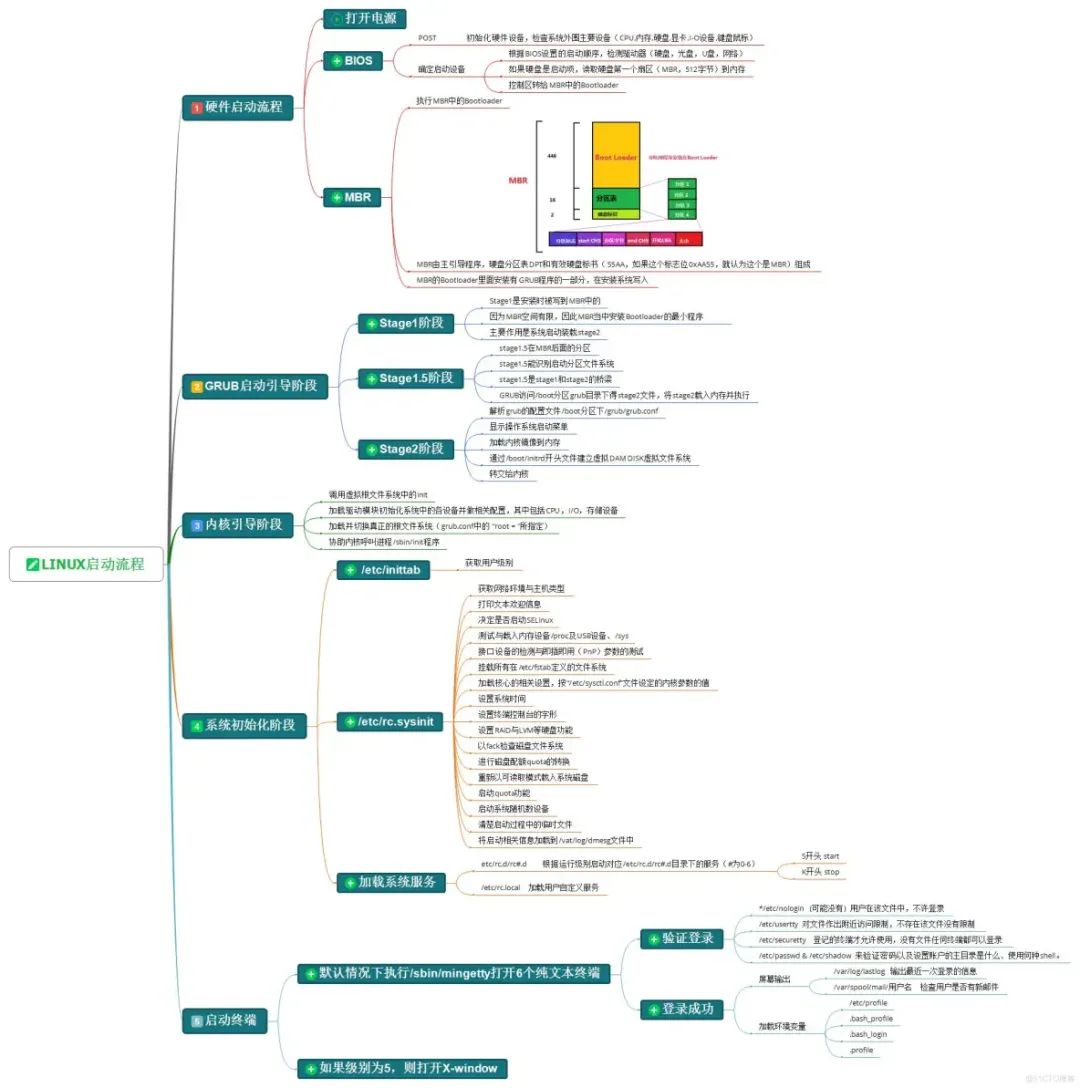
Rocky启动流程大致如下:
1.计算机通电后,BIOS会自动运行并执行POST(Power-On Self Test)。
2.BIOS会寻找可启动设备,通常会先寻找硬盘、光驱和USB设备。
3.当BIOS找到可启动设备后,它会将引导扇区(boot sector)加载到内存中,并将控制权交给引导扇区程序。
4.引导扇区程序会加载GRUB(Grand Unified Bootloader)引导程序。GRUB是R默认的引导程序。
5.GRUB会显示启动菜单,让用户选择要启动的操作系统或内核。
6.用户选择了操作系统或内核后,GRUB会加载内核文件和启动选项,并将控制权交给内核。
7.内核会初始化硬件、加载驱动程序、挂载文件系统等操作。
8.内核完成初始化后,会运行/sbin/init程序,此时系统进入用户空间。
9./sbin/init程序会根据配置文件/etc/inittab启动各种服务,并设置系统运行级别。
10.至此,Rocky系统启动完成。
GRUB的工作流程大致如下:
1.GRUB被加载到内存中后,显示启动菜单。
2.用户选择要启动的操作系统或内核后,GRUB会加载内核文件和启动选项。
3.GRUB会从文件系统中读取内核文件和相关的初始化文件,例如/etc/grub.conf。
4.GRUB会将内核和相关文件加载到内存中,并设置启动参数。
5.最后,GRUB会将控制权交给内核,让内核开始启动操作系统。
十二、chkconfig服务脚本
手写chkconfig服务脚本,可以实现服务的开始,停止,重启。
# chkconfig: - 96 3
# description: This is test service script
. /etc/init.d/functions
start(){
[ -e /var/lock/subsys/testsrv ] && exit || touch /var/lock/subsys/testsrv
echo $PATH
action "Starting testsrv"
sleep 3
}
stop(){
[ -e /var/lock/subsys/testsrv ] && rm /var/lock/subsys/testsrv || exit
action "Stopping testsrv"
}
status(){
[ -e /var/lock/subsys/testsrv ] && echo "testsrv is running..." || echo "testsrv is stopped"
}
case $1 in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
status)
status
;;
*)
echo $"Usage: $0 {start|stop|status|restart}"
exit 2
esac
十三、systemd服务配置文件
总结systemd服务配置文件。
systemd是一个Linux系统的初始化系统和服务管理器。在systemd中,每个服务都有一个对应的配置文件,其中定义了服务的各种属性和行为。通常情况下,这些配置文件存储在/etc/systemd/system目录下。
以下是一个简单的systemd服务配置文件的示例:
[Unit]
Description=My Service
After=network.target
[Service]
ExecStart=/usr/local/bin/my-service
Restart=always
[Install]
WantedBy=multi-user.target
该文件分为三个部分:
-
[Unit]:包含服务的基本信息和依赖关系。
-
Description:服务的描述信息。
-
After:指定服务所需的其他服务或者单元,在这个例子中,服务需要在网络服务之后启动。
-
[Service]:包含服务执行时的相关信息。
-
ExecStart:指定服务的启动命令。
-
Restart:指定服务异常退出后的重启策略,这里设置为always表示总是重启。
-
[Install]:包含安装服务时的相关信息。
-
WantedBy:指定服务在哪些运行级别下启动,这里设置为multi-user.target表示在多用户模式下启动。
一个标准的systemd服务配置文件通常由三个主要部分组成:[Unit]、[Service]和[Install]。下面我们将详细介绍这些部分以及它们的属性。
[Unit]
该部分包含了服务的基本信息和依赖关系。下面是一些常用的属性:
-
Description:服务的描述信息。
-
After:指定服务所需的其他服务或者单元启动完成之后才能启动。
-
Requires:指定服务所需的其他服务或者单元(必须同时启动)。
-
Wants:指定服务所需的其他服务或者单元(推荐同时启动)。
-
Before:指定服务启动之前需要启动的服务或者单元。
-
Conflicts:指定服务与其他服务或单元存在冲突。
[Service]
该部分包含了服务执行时的相关信息。下面是常用的属性:
-
Type:指定服务的类型,可以是simple(默认,直到服务退出才会返回控制权)、forking(在服务启动时派生一个子进程)、oneshot(服务只会运行一次)等。
-
ExecStart:指定服务的启动命令。
-
ExecStop:指定服务的停止命令。
-
Restart:指定服务异常退出后的重启策略,可以是no(不重启)、always(总是重启)、on-failure(仅在非0退出状态时重启)等。
-
User:指定服务所属的用户。
-
Group:指定服务所属的组。
-
Environment:指定服务执行时需要的环境变量。
-
WorkingDirectory:指定服务执行时的工作目录。
[Install]
该部分包含了安装服务时的相关信息。下面是常用的属性:
-
WantedBy:指定服务在哪些运行级别下启动,可以是multi-user.target(多用户模式)、graphical.target(图形化模式)等。
-
RequiredBy:指定需要该服务的其他服务或单元(必须同时启动)。
-
Also:指定需要该服务的其他服务或单元(推荐同时启动)。
以上是systemd服务配置文件的主要部分和属性介绍,这些属性根据服务需求而异。使用systemd配置文件来管理服务非常方便,可以有效地提高系统管理的效率和可靠性。
十四、system启动流程
总结system启动流程。
systemd 是一个具有启动管理、服务管理、日志管理和设备管理等功能的系统和服务管理器,其启动流程主要包括以下几个步骤:
-
系统引导:当计算机启动时,BIOS/UEFI会加载GRUB2或者其他引导程序,并从硬盘、光盘或者网络中读取内核映像文件。
-
内核初始化:内核映像文件被加载后,内核会对硬件进行初始化操作,并创建第一个用户空间进程systemd(PID 1)。
-
systemd初始化:systemd会读取所有的unit文件,并按照启动顺序将它们加入到启动队列中,这些unit文件包括target文件、service文件、socket文件等。
-
启动目标:每个target文件都是一套预定义的unit,在systemd启动时,会根据指定的default target决定启动哪一个target文件(比如multi-user.target,表示只启动多用户模式,并不启动图形界面)。
-
加载依赖项:在启动target前,systemd会根据unit文件中的Requires和Wants字段,来查找并自动加载必要的依赖文件和服务。
-
启动服务:在所有依赖关系满足后,systemd会按照启动顺序执行服务文件,并在执行过程中记录各种系统日志。
-
启动完成:一旦所有服务都启动完毕,systemd会进入idle状态,并等待下一次事件发生。
总之,systemd启动流程非常复杂和庞大,但由于其高度集成和可扩展性,已成为众多Linux发行版的标配启动管理器。
十五、AWK工作原理
总结awk工作原理,awk命令,选项,示例。
awk是一种文本处理工具,它按行读取输入文件并将每行分解为字段。可以使用任意分隔符来指定字段之间的分隔符,默认情况下使用空格和制表符。在每个字段中,awk执行指定的动作,并且可以根据需要打印输出结果。
awk的基本工作原理如下:
-
将输入文件读入内存,一行一行地处理。
-
按照指定的字段分隔符将每行拆分为多个字段。
-
对于每个字段,执行指定的操作,这些操作包括条件判断、变量设置、数学计算、字符串操作等。
-
根据需要输出结果。
对于每个输入行,awk会执行指定的操作,这些操作可以是内置函数、用户自定义函数、条件语句、循环语句等。awk还支持多种模式和模式匹配方式,以便更容易地处理文本数据。常见的应用包括文本处理、报告生成、数据转换和格式化等。
awk命令的一般语法格式为:
awk 'pattern {action}' input_file
其中,pattern用于指定需要匹配的模式,action用于指定匹配成功后需要执行的操作,input_file表示要处理的输入文件。如果没有指定输入文件,则awk默认从标准输入读取数据。
以下是一些常见的awk命令使用示例:
-
输出指定列:打印第1列和第3列
awk '{print $1, $3}' input_file
-
根据条件过滤数据:打印第2列等于"hello"的行
awk '$2 == "hello" {print}' input_file
-
基于统计信息生成报告:输出文件的行数、单词数和字符数
awk 'BEGIN {lines=words=chars=0} {lines++; words+=NF; chars+=length} END {print lines, words, chars}' input_file
-
对数据进行计算:求第2列的平均值
awk '{sum+=$2} END {print sum/NR}' input_file
awk命令有许多选项可用于指定模式匹配和规则动作的行为。以下是一些常见的awk选项:
-
-F:指定字段分隔符,默认为制表符或空格。例如,-F:将冒号作为字段之间的分隔符。
-
-
-v:定义变量并将其传递给awk程序。例如,awk -v var=value 'pattern {action}' input_file中的var变量可在awk程序中使用。
-
-f:从文件中读取awk程序。例如,awk -f script.awk input_file将从script.awk文件中读取awk程序。
-
-i inplace:启用原地编辑模式,并将结果写回到输入文件中,而不是打印到标准输出。该选项只适用于GNU awk(gawk)版本4.1及更高版本。
-
-W:指定gawk扩展功能。例如,-W interactive可以启用交互式模式,-W compat可以使gawk与旧版awk兼容。
-
-n:禁用默认打印操作,只执行指定的规则操作,不输出处理的数据。
-
-N:禁用所有输入记录的拆分,默认情况下,awk将根据空格和制表符分割输入记录。
这只是一小部分常见的awk选项,还有其他许多选项和功能可供选择,具体取决于你所使用的awk版本。可以通过查看man awk命令来获取完整的选项列表和说明。
十六、AWK数组/函数
总结awk的数组,函数。
awk中的数组是一种关联数组,它可以存储多个值,并使用一个键来引用每个值。awk数组中的键通常是字符串或数字,数组中的值可以是任何类型的数据,包括字符串、数字、其他数组等。
在awk中,可以通过以下方法声明和访问数组:
-
声明数组:使用下面的语法来声明数组:
array[index]=value
array["key"]=value
其中,index和key都是索引值,value则是与索引相关联的值。
-
访问数组:可以使用以下语法来访问数组中的元素:
# 通过数字索引访问数组
array[index]
# 通过字符串索引访问数组
array["key"]
可以像访问普通变量一样使用数组来访问它们的元素。
以下是一个简单的例子,演示了如何在awk中创建和使用数组:
# test.txt
apple,fruit,red
banana,fruit,yellow
carrot,vegetable,orange
# awk程序获取test.txt文件中所有水果的名称
awk -F, '{ if ($2 == "fruit") { fruits[$1] = $3 } } END { for (f in fruits) print f, fruits[f] }' test.txt
在上面的例子中,我们创建了一个名为fruits的数组,存储了所有水果的名称和颜色。在每一行上,如果水果的类型是fruit,则将该水果的名称和颜色存储到fruits数组中。最后,使用for循环遍历fruits数组并输出所有水果的名称和颜色。
希望这个例子演示了如何使用awk数组来处理文本数据。
awk是一种强大的文本处理工具,它还提供了许多内置函数来处理文本和数值类型。此外,awk还允许用户定义自己的函数,以便更好地组织和重复使用代码。
在awk中,可以通过以下语法来定义和调用函数:
-
定义函数:定义一个函数需要使用function关键字,并在函数名称后面跟一个括号。如果函数有参数,这些参数应该放在括号中,并用逗号分隔。
function name(parameter1, parameter2, ...) {
# 函数体,包括语句和表达式
}
-
调用函数:使用函数名称和参数列表来调用函数。参数应该用逗号分隔,并放在括号中。
name(argument1, argument2, ...)
以下是一个简单的例子,演示如何在awk中定义和调用函数:
# awk程序计算两个数字之和
function add(x, y) {
return x + y
}
# 在main out中调用add函数
BEGIN {
a = 2
b = 3
print "The sum of", a, "and", b, "is", add(a, b)
}
在上面的例子中,我们定义了一个名为add的函数,它接受两个参数并返回它们的和。然后,在BEGIN块中,我们声明了两个变量a和b,并在print语句中调用了add函数,以显示它们的和。
除此之外,awk还提供了许多内置函数,例如字符串函数、数学函数、时间函数等。可以在awk的官方文档中查找完整列表,并在需要时使用它们来处理数据。
十七、CA管理相关工具
总结ca管理相关的工具,根据使用场景总结示例。
要建立私有证书颁发机构(CA),可以参考以下步骤:
-
选择适合的CA软件:可以根据自己的需求选择开源的或商业的CA软件,如OpenSSL、EJBCA、Microsoft Certificate Services等。这些软件提供了创建和管理证书的工具和面板,能够方便地处理数字证书。
-
创建根证书:在选择好CA软件后,需要创建一个根证书。根证书是CA的顶级证书,对其进行签名的证书只有两种方式,即信任或被撤销。创建根证书时需要输入一些组织信息,如组织名称、国家、州/省、城市以及联系信息等。
-
创建中间证书(可选):如果需要更复杂的证书结构,可以在根证书下创建其他中间CA。中间CA是通过根CA签名的证书,用于颁发子证书。中间CA的目的是为了隔离根证书,防止根证书被泄露后全部证书都失效。
-
颁发子证书:在创建完根证书和中间证书(可选)之后,可以开始颁发子证书。颁发子证书时需要指定证书的一些信息,如证书名称、公钥、有效期限等。子证书颁发之前必须使用父证书进行签名,以便证书链的完整性验证。
-
处理证书吊销:如果某个证书不再被信任或者存在安全风险,需要对其进行吊销操作。在吊销证书后,该证书将不再被认为是有效的,并且无法用来进行加密或数字签名。吊销证书可以通过CA软件中提供的工具来完成。
-
公开证书:最后,需要将颁发的证书公开发布到可信赖的目录中,这样其他人才能获得并验证证书的合法性。
需要注意的是,在建立私有CA时,需要非常小心和谨慎地保护私钥,确保它们不被泄露。泄露私钥可能会导致他人伪造证书,进而进行恶意attack。
OpenSSL的openssl.cnf配置文件比较复杂,包括多个节(section)以及各种选项参数,下面是一些比较常见的选项参数:
-
RANDFILE:用于指定随机数文件的路径,这个文件存储了OpenSSL需要生成加密算法中所需的随机数,例如需要创建自签名证书时。
-
HOME:用于指定OpenSSL默认的主目录,默认值为/etc/pki/tls。
-
certificate:用于设置证书文件的名称,默认值为$dir/cert.pem。
-
private_key:用于设置私钥文件的名称,默认值为$dir/private/key.pem。
-
default_md:用于设置默认使用的消息摘要算法,默认值为sha256。
-
req_extensions:用于设置证书请求时添加的扩展信息。
-
x509_extensions:用于设置证书时添加的扩展信息。
此外,根据你的应用场景,还可以设置其它许多参数,比如:
-
[ca] 配置 CA 证书和 CA 目录信息
-
[req] 配置证书的请求信息
-
[req_distinguished_name] 配置证书请求的 DN
-
[usr_cert] 配置用户证书信息
-
[v3_ca] 配置 CA 证书的 V3 扩展
-
[v3_req] 配置证书请求的 V3 扩展
需要注意的是,在修改openssl.cnf文件时需要小心操作,确保其符合安全标准,并进行相应的测试和验证,以保证系统的安全性和稳定性。
创建CA所需要的文件
#生成证书索引数据库文件
touch /etc/pki/CA/index.txt
#指定第一个颁发证书的序列号
echo 01 > /etc/pki/CA/serial
生成CA私钥
cd /etc/pki/CA/
(umask 066; openssl genrsa -out private/cakey.pem 2048)
生成CA自签名证书
openssl req -new -x509 -key /etc/pki/CA/private/cakey.pem -day 3650 -out /etc/pki/CA/cacert.pem
-new:生成新证书签署请求
-x509:专用于CA生成自签证书
-key:生成请求用到的私钥文件
-days n:证书的有效期限
-out /PATH/TO/SOMECERTFILE:证书的保存路径
用户生成私钥和证书申请
(umask 066;openssl genrsa -out /data/app1/app1.key 2048)
openssl req -new -key /data/app1/app1.key -out /data/app1/app1.csr
CA 颁发证书
openssl ca -in /data/app1/app1.csr -out /etc/pki/CA/certs/app1.crt -days 1000
十八、加密算法
总结对称加密和非对称加密算法和用openssl签发证书步骤。
对称加密
对称加密:加密和解密使用同一个密钥
特性:
-
加密、解密使用同一个密钥,效率高;
-
将原始数据分割成固定大小的块,逐个进行加密
缺陷:
-
密钥过多
-
密钥分发
-
数据来源无法确认
常见对称加密算法:
-
DES:Data Encryption Standard,56bits
-
3DES:
-
AES:Advanced (128, 192, 256bits)
-
Blowfish,Twofish
-
IDEA,RC6,CAST5
非对称加密
非对称加密:密钥是成对出现
-
公钥:public key,公开给所有人,主要给别人加密使用
-
私钥:secret key,private key 自己留存,必须保证其私密性,用于自已加密签名
-
特点:用公钥加密数据,只能使用与之配对的私钥解密;反之亦然
功能:
-
数据加密:适合加密较小数据,比如: 加密对称密钥
-
数字签名:主要在于让接收方确认发送方身份
缺点:
-
密钥长,算法复杂
-
加密解密效率低下
常见算法:
-
RSA:由 RSA 公司发明,是一个支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的,可实现加密和数字签名
-
DSA(Digital Signature Algorithm):数字签名算法,是一种标准的 DSS(数字签名标准)
-
ECC(Elliptic Curves Cryptography):椭圆曲线密码编码学,比RSA加密算法使用更小的密钥,提供相当的或更高等级的安全
OpenSSL签发证书
建立私有CA:
-
OpenCA:OpenCA开源组织使用Perl对OpenSSL进行二次开发而成的一套完善的PKI免费软件
-
openssl:相关包 openssl和openssl-libs
证书申请及签署步骤:
-
生成证书申请请求
-
RA核验
-
CA签署
-
获取证书
[]
[]
[]
[]
配置文件部分内容说明
[ CA_default ]
dir = ./demoCA #所有与证书相关的文件目录,在实际使用时此处
要进行修改
certs = $dir/certs #颁发的证书文件目录
crl_dir = $dir/crl #吊销的证书文件
database = $dir/index.txt #证书索引文件
new_certs_dir = $dir/newcerts #新颁发的证书目录
certificate = $dir/cacert.pem #CA机构自己的证书
serial = $dir/serial #证书编号文件,下一个证书编号,16进制
crlnumber = $dir/crlnumber #存放当前CRL编号的文件
crl = $dir/crl.pem #CA证书吊销列表文件
private_key = $dir/private/cakey.pem #CA证书的私钥
[ policy_match ]
countryName = match
stateOrProvinceName = match
organizationName = match
organizationalUnitName = optional
commonName = supplied
emailAddress = optional
匹配策略,指用此CA颁发证书时,证书的相关字段与CA的值的匹配规则
|
匹配规则 |
说明 |
|
match |
要求申请填写的信息跟CA设置信息必须一致 |
|
optional |
可有可无,跟CA设置信息可不一致 |
|
supplied |
必须填写这项申请信息 |
创建私有CA
1、创建CA所需要的文件
[]
[]
/etc/pki/CA/
├── certs
├── crl
├── newcerts
└── private
4 directories, 0 files
2、 生成CA私钥
[]
[]
3、生成CA自签名证书
[root@ubuntu CA]# openssl req -new -x509 -key /etc/pki/CA/private/cakey.pem -days
3650 -out /etc/pki/CA/cacert.pem
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:CN #国家代码
State or Province Name (full name) [Some-State]:beijing #省/州
Locality Name (eg, city) []:beijing #城市
Organization Name (eg, company) [Internet Widgits Pty Ltd]:magedu #公司/单位
Organizational Unit Name (eg, section) []:m54 #部门
Common Name (e.g. server FQDN or YOUR name) []:www.magedu.org #域名
Email Address []: #邮箱
-new #生成新证书签署
请求
-x509 #专用于CA生成自
签证书
-key #生成请求时用到
的私钥文件
-days n #证书的有效期限
-out /PATH/TO/SOMECERTFILE #证书的保存路径
#查看证书
[root@ubuntu CA]# cat /etc/pki/CA/cacert.pem
-----BEGIN CERTIFICATE-----
MIIDszCCApugAwIBAgIURIyd0TW4qqffpbh1NudkH3ZLWQUwDQYJKoZIhvcNAQEL
BQAwaTELMAkGA1UEBhMCQ04xEDAOBgNVBAgMB2JlaWppbmcxEDAOBgNVBAcMB2Jl
aWppbmcxDzANBgNVBAoMBm1hZ2VkdTEMMAoGA1UECwwDbTU0MRcwFQYDVQQDDA53
d3cubWFnZWR1Lm9yZzAeFw0yMzA1MjIxMzMwMzFaFw0zMzA1MTkxMzMwMzFaMGkx
CzAJBgNVBAYTAkNOMRAwDgYDVQQIDAdiZWlqaW5nMRAwDgYDVQQHDAdiZWlqaW5n
MQ8wDQYDVQQKDAZtYWdlZHUxDDAKBgNVBAsMA201NDEXMBUGA1UEAwwOd3d3Lm1h
Z2VkdS5vcmcwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCjAuAX6QgC
o1GBbWefyHTib/Unq7k4l1mgbjvfLv9mccSUFaZcZllIdRb5HPpeGPtjHjgxRfS6
iMNdVrVwON9gkLMv/BDPJKUdK7a3LokweohU+i0o2Xnp2ZZ1AhDgUvE1vHhOQa/a
YZKTgnbucJAeKr0u3/GoHlJvb652t7/g13yUR9XrLaLjIYk+IcDvdBVd2apRO6w3
IvkUrhhLQ3FSNWLi6mOuCdXfTs7TtQDbu1guLMo5ZNZffHXlnUNpjF5rtvsD8L7m
bvjRvEdBAyYp9IwV0vMLntSZ0bdrntAGlBXi18W2nb6LGskQhViC2J0U59gk5bVZ
0LvGbVeXMQm1AgMBAAGjUzBRMB0GA1UdDgQWBBREjMYMzWwjJT1PtwMJ3/CASxIK
EjAfBgNVHSMEGDAWgBREjMYMzWwjJT1PtwMJ3/CASxIKEjAPBgNVHRMBAf8EBTAD
AQH/MA0GCSqGSIb3DQEBCwUAA4IBAQBJz2HTy/UlOUyVlVf+7imbToWyCkDDrB1P
26hrHIPcl+njzP5qFn662po4LczXRK1oqv7OOBjvLOTuj5eVmz3Jzf4dGk54E6jP
Vqp6SjnH0gOFBqJx0bRo5fIzbBZ6yVedXPQM5X11rhS+eJmeU2bU4QcT9PZ08M1Z
Hp+QJmJBpXHxd8ouu+YU4fyFtde24NYQNtKLFfJCyJl4wO210CXYHoTVe8dtWFoS
UvqUR49iFZW1uPXXQtP6eizw4k+sV9afaEii+u4fnGdIs2q3c+GPn276V1MrcQnw
GRdFX/WHvr0asO9wvoQTnB9LM+UEqn61oJ+aGXgkujbaTtaNYOS/
-----END CERTIFICATE-----
#查看证书
[root@ubuntu CA]# openssl x509 -in /etc/pki/CA/cacert.pem -noout -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
44:8c:9d:d1:35:b8:aa:a7:df:a5:b8:75:36:e7:64:1f:76:4b:59:05
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = CN, ST = beijing, L = beijing, O = magedu, OU = m54, CN =
www.magedu.org
Validity
Not Before: May 22 13:30:31 2023 GMT
Not After : May 19 13:30:31 2033 GMT
Subject: C = CN, ST = beijing, L = beijing, O = magedu, OU = m54, CN =
www.magedu.org
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
......
......
#导到WINDOWS中查看
[root@ubuntu CA]# sz /etc/pki/CA/cacert.pem
https://country-code.cl/ #国家代码
申请证书并颁发证书
1、为需要使用证书的主机生成生成私钥
[root@ubuntu CA]# openssl genrsa -out /data/test.key 2048
2、为需要使用证书的主机生成证书申请文件
#注意:默认要求国家,省,公司名称三项必须和CA一致
CA]# openssl req -new -key /data/test.key -out /data/test.csr
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:CN
State or Province Name (full name) [Some-State]:beijing
Locality Name (eg, city) []:beijing
Organization Name (eg, company) [Internet Widgits Pty Ltd]:magedu
Organizational Unit Name (eg, section) []:m54-class
Common Name (e.g. server FQDN or YOUR name) []:www.m54.magedu.com
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
3、用CA签署证书并将证书颁发给请求者
#创建索引文件
[root@ubuntu CA]# touch /etc/pki/CA/index.txt
#创建序号文件
[root@ubuntu CA]# echo 0F > /etc/pki/CA/serial
#签发证书
[root@ubuntu CA]# openssl ca -in /data/test.csr -out /etc/pki/CA/certs/test.crt -
days 100
Using configuration from /usr/lib/ssl/openssl.cnf
Check that the request matches the signature
Signature ok
Certificate Details:
Serial Number: 15 (0xf)
Validity
Not Before: May 22 13:56:23 2023 GMT
Not After : Aug 30 13:56:23 2023 GMT
Subject:
countryName = CN
stateOrProvinceName = beijing
organizationName = magedu
organizationalUnitName = m54-class
commonName = www.m54.magedu.com
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
X509v3 Subject Key Identifier:
13:7E:49:68:5E5F:23:68127EB5:90:020C:64
X509v3 Authority Key Identifier:
44:8C0C6C:23:25:3D:4F03:09F0:80:4B:12:0A:12
Certificate is to be certified until Aug 30 13:56:23 2023 GMT (100 days)
Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]y
Write out database with 1 new entries
Data Base Updated
#查看
[root@ubuntu CA]# tree /etc/pki/CA/
/etc/pki/CA/
├── cacert.pem
├── certs
│ └── test.crt
├── crl
├── index.txt
├── index.txt.attr
├── index.txt.old
├── newcerts
│ └── 0F.pem
├── private
│ └── cakey.pem
├── serial
└── serial.old
4 directories, 9 files
#原来是0F,加1后变成10
[root@ubuntu CA]# cat /etc/pki/CA/serial
10
#V 表示有效,230830 表示2023年8月30日过期,0F 表示证书编号
[root@ubuntu CA]# cat /etc/pki/CA/index.txt
V 230830135623Z 0F unknown /C=CN/ST=beijing/O=magedu/OU=m54-
class/CN=www.m54.magedu.com
4、查看证书中的信息:
#根据编号查看状态
CA]# openssl ca -status 0F
Using configuration from /usr/lib/ssl/openssl.cnf
0F=Valid (V)
CA]# openssl x509 -in /etc/pki/CA/certs/test.crt -noout -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 15 (0xf)
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = CN, ST = beijing, L = beijing, O = magedu, OU = m54, CN =
www.magedu.org
Validity
Not Before: May 22 1323 2023 GMT
Not After : Aug 30 1323 2023 GMT
Subject: C = CN, ST = beijing, O = magedu, OU = m54-class, CN =
www.m54.magedu.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
: (2048 bit)
......
......
如果证书申请文件中的配置项与CA机构的匹配规则不一致,将无法签发证书
吊销证书
在客户端获取要吊销的证书的 serial
[root@ubuntu CA]# openssl x509 -in /etc/pki/CA/certs/test.crt -noout -serial -
subject
serial=0F
subject=C = CN, ST = beijing, O = magedu, OU = m54-class, CN =
www.m54.magedu.com
在CA上,根据客户提交的 serial 与 subject 信息,对比检验是否与 index.txt 文件中的信息一致,吊销证书:
[root CA]# openssl ca -revoke /etc/pki/CA/certs/test.crt
Using configuration from /usr/lib/ssl/openssl.cnf
Revoking Certificate 0F.
Data Base Updated
[root CA]# cat /etc/pki/CA/index.txt
R 230830135623Z 230522141008Z 0F unknown
/C=CN/ST=beijing/O=magedu/OU=m54-class/CN=www.m54.magedu.com
指定第一个吊销证书的编号,注意:第一次更新证书吊销列表前,才需要执行
[]
更新证书吊销列表
[]
Using configuration from /usr/lib/ssl/openssl.cnf
查看crl文件:
CA]# openssl crl -in /etc/pki/CA/crl.pem -noout -text
Certificate Revocation List (CRL):
Version 2 (0x1)
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = CN, ST = beijing, L = beijing, O = magedu, OU = m54, CN =
www.magedu.org
Last Update: May 22 1400 2023 GMT
Next Update: Jun 21 1400 2023 GMT
CRL extensions:
X509v3 CRL Number:
......
......
CentOS7 创建自签名证书
certs]# cd /etc/pki/tls/certs
certs]# make
This makefile allows you to create:
......
......
Examples:
make server.key
make server.csr
make server.crt
make stunnel.pem
make genkey
make certreq
make testcert
make server.crt SERIAL=1
make stunnel.pem EXTRA_FLAGS=-sha384
make testcert DAYS=600
#根据目录中的 Makefile 来执行不同操作
certs]# ls
ca-bundle.trust.crt make-dummy-cert Makefile renew-dummy-cert
certs]# cat Makefile
UTF8 := $(shell locale -c LC_CTYPE -k | grep -q charmap.*UTF-8 && echo -utf8)
DAYS=365
KEYLEN=2048
......
......
#centos8中没有该Makefile,可以SCP过去使用
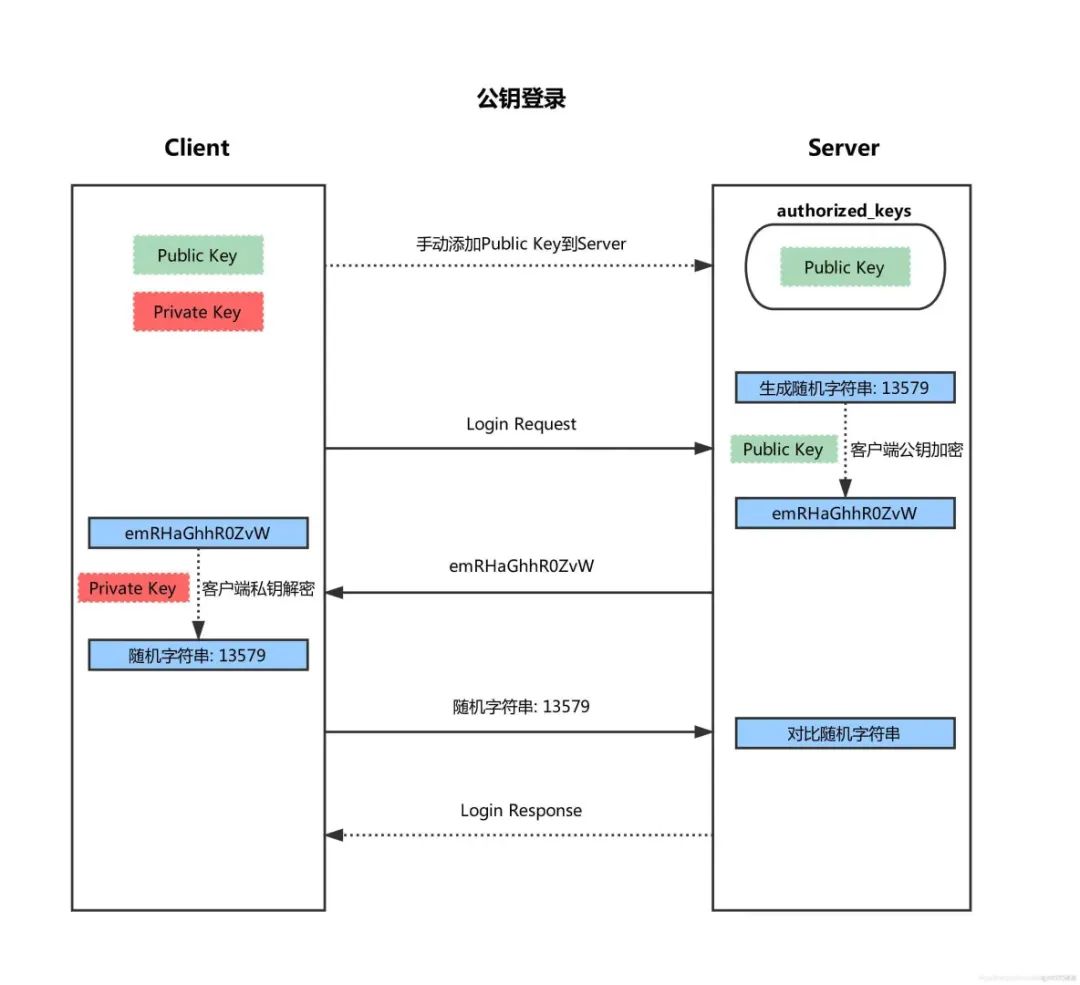
OpenSSH 免密认证是通过使用公钥、私钥实现的。在 OpenSSH 中,客户端和服务器端都会有一对密钥:私钥和公钥。
-
首先在客户端生成一对密钥(ssh-keygen)
-
并将客户端的公钥ssh-copy-id复制到服务端
-
当客户端再次发送一个连接请求,包括ip、用户名
-
服务端得到客户端的请求后,会到authorized_keys中查找,如果有响应的IP和用户,就会随机生成一个字符穿,例如:13579
-
服务端将使用客户端复制过来的公钥进行加密,然后发送给客户端
-
得到服务端发来的消息后,客户端会使用私钥进行解密,然后解密后的字符串发送给服务端
-
服务端接受到客户端发来的字符串后,跟之前的字符串进行对比,如果一致,就允许免密码登录
-
Linux
+关注
关注
87文章
11230浏览量
208931 -
字符串
+关注
关注
1文章
577浏览量
20485 -
变量
+关注
关注
0文章
613浏览量
28329
原文标题:Linux进程管理和启动流程
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

Linux使用Systemd管理进程服务
Linux使用Systemd管理进程服务
Linux内核编译和启动的相关资料分享
Linux守护进程详解


Linux进程管理:什么是进程?进程的生命周期

学会Linux进程管理的方法
简要剖析Linux系统的进程管理机制_LINUX_操作系统_脚本之家
深入Linux进程管理:提升效率与稳定性的关键方法





 工商网监
工商网监
评论