 YOLOv8自定义数据集训练实现安全帽检测
YOLOv8自定义数据集训练实现安全帽检测
数据集地址
该图像数据集包含8000张图像,两个类别分别是安全帽与人、以其中200多张图像为验证集,其余为训练集。
模型训练
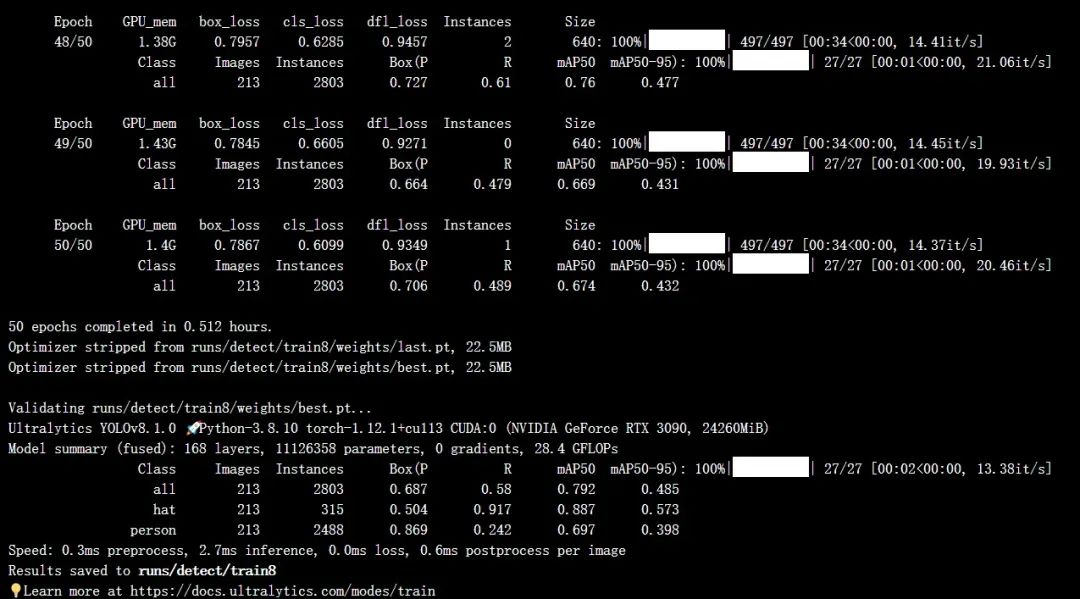
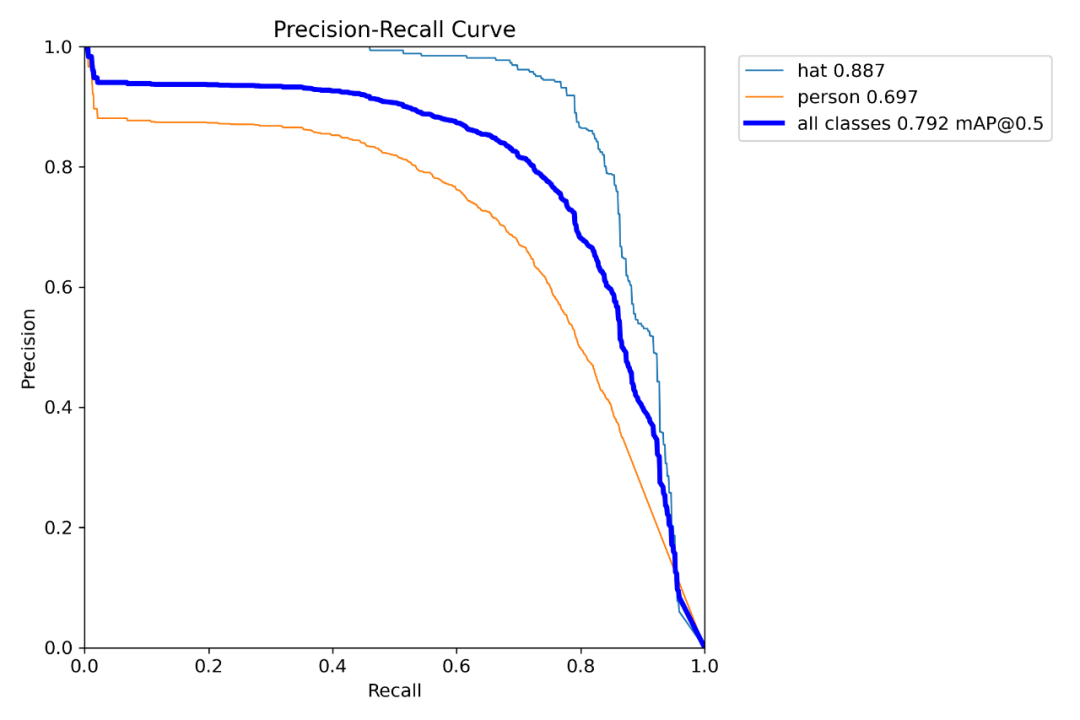
准备好数据集以后,直接按下面的命令行运行即可:
yolotrainmodel=yolov8s.ptdata=hat_dataset.yamlepochs=50imgsz=640batch=4
导出与测试
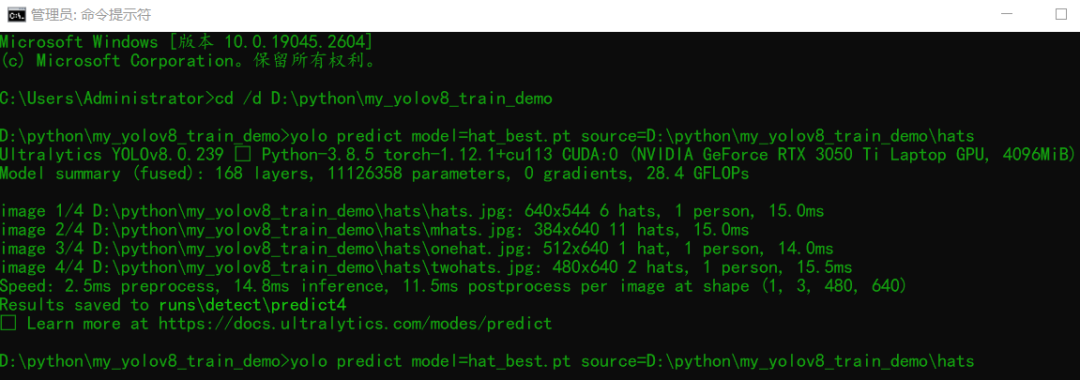
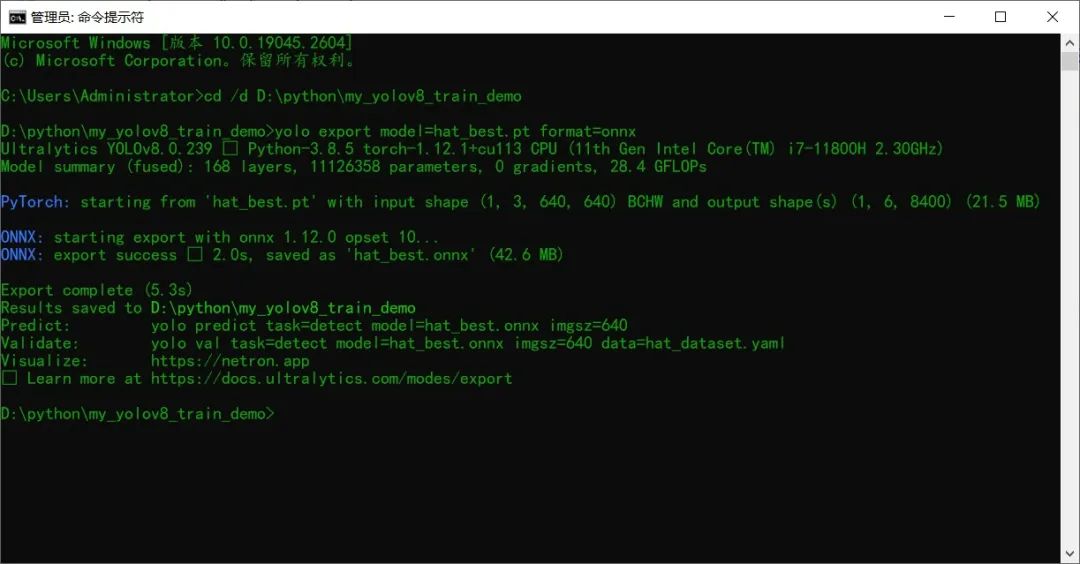
模型导出与测试
yolo export model=hat_best.pt format=onnx yolo predict model=hat_best.pt source=./hats
部署推理
转成ONNX格式文件以后,基于OpenVINO-Python部署推理,相关代码如下
#ReadIR model=ie.read_model(model="hat_best.onnx") compiled_model=ie.compile_model(model=model,device_name="CPU") output_layer=compiled_model.output(0) capture=cv.VideoCapture("D:/images/video/hat_test.mp4") whileTrue: _,frame=capture.read() ifframeisNone: print("Endofstream") break bgr=format_yolov8(frame) img_h,img_w,img_c=bgr.shape start=time.time() image=cv.dnn.blobFromImage(bgr,1/255.0,(640,640),swapRB=True,crop=False) res=compiled_model([image])[output_layer]#1x84x8400 rows=np.squeeze(res,0).T class_ids=[] confidences=[] boxes=[] x_factor=img_w/640 y_factor=img_h/640 forrinrange(rows.shape[0]): row=rows[r] classes_scores=row[4:] _,_,_,max_indx=cv.minMaxLoc(classes_scores) class_id=max_indx[1] if(classes_scores[class_id]>.25): confidences.append(classes_scores[class_id]) class_ids.append(class_id) x,y,w,h=row[0].item(),row[1].item(),row[2].item(),row[3].item() left=int((x-0.5*w)*x_factor) top=int((y-0.5*h)*y_factor) width=int(w*x_factor) height=int(h*y_factor) box=np.array([left,top,width,height]) boxes.append(box) indexes=cv.dnn.NMSBoxes(boxes,confidences,0.25,0.45) forindexinindexes: box=boxes[index] color=colors[int(class_ids[index])%len(colors)] cv.rectangle(frame,box,color,2) cv.rectangle(frame,(box[0],box[1]-20),(box[0]+box[2],box[1]),color,-1) cv.putText(frame,class_list[class_ids[index]],(box[0],box[1]-10),cv.FONT_HERSHEY_SIMPLEX,.5,(0,0,0)) end=time.time() inf_end=end-start fps=1/inf_end fps_label="FPS:%.2f"%fps cv.putText(frame,fps_label,(20,45),cv.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2) cv.imshow("YOLOv8hatDetection",frame) cc=cv.waitKey(1) ifcc==27: break cv.destroyAllWindows()
审核编辑:汤梓红
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
模型
+关注
关注
1文章
3372浏览量
49314 -
数据集
+关注
关注
4文章
1210浏览量
24865 -
命令行
+关注
关注
0文章
78浏览量
10423
原文标题:YOLOv8自定义数据集训练实现安全帽检测
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于YOLOv8实现自定义姿态评估模型训练
Hello大家好,今天给大家分享一下如何基于YOLOv8姿态评估模型,实现在自定义数据集上,完成自定义姿态评估模型的

RK3399pro实现安全帽识别
省了。
这个数据中把没戴安全帽的头标注为 head, 把戴了安全帽的头标注为 helmet, 没戴在头上的安全帽没有标注。这样算法就不会把没戴在头上的
发表于 05-11 16:09
ZLG安全帽佩戴检测方案的解读
安全帽佩戴检测是工地安防的重中之重,但人为主观检测的方式时效性差且不能全程监控。AI技术的日渐成熟催生了安全帽佩戴检测方案,成为了监督佩戴
发表于 03-13 15:32
•1542次阅读
TensorRT 8.6 C++开发环境配置与YOLOv8实例分割推理演示
对YOLOv8实例分割TensorRT 推理代码已经完成C++类封装,三行代码即可实现YOLOv8对象检测与实例分割模型推理,不需要改任何代码即可支持
YOLOv8实现任意目录下命令行训练
当你使用YOLOv8命令行训练模型的时候,如果当前执行的目录下没有相关的预训练模型文件,YOLOv8就会自动下载模型权重文件。这个是一个正常操作,但是你还会发现,当你在参数model中
用自己的数据集训练YOLOv8实例分割模型
YOLOv8 于 2023 年 1 月 10 日推出。截至目前,这是计算机视觉领域分类、检测和分割任务的最先进模型。该模型在准确性和执行时间方面都优于所有已知模型。


基于YOLOv8的自定义医学图像分割
YOLOv8是一种令人惊叹的分割模型;它易于训练、测试和部署。在本教程中,我们将学习如何在自定义数据集上使用YOLOv8。但在此之前,我想告

如何基于深度学习模型训练实现圆检测与圆心位置预测
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现圆检测与圆心位置预测,主要是通过对YOLOv8姿态评估模型在自定义的

如何基于深度学习模型训练实现工件切割点位置预测
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现工件切割点位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上

YOLOv8实现旋转对象检测
YOLOv8框架在在支持分类、对象检测、实例分割、姿态评估的基础上更近一步,现已经支持旋转对象检测(OBB),基于DOTA数据集,支持航拍图像的15个类别对象





 工商网监
工商网监
评论