 谷歌MIT最新研究证明:高质量数据获取不难,大模型就是归途
谷歌MIT最新研究证明:高质量数据获取不难,大模型就是归途

【导读】数据获取最新解,便是从生成模型中学习。
获取高质量数据,已经成为当前大模型训练的一大瓶颈。
前几天,OpenAI被《纽约时报》起诉,并要求索赔数十亿美元。诉状中,列举了GPT-4抄袭的多项罪证。
甚至,《纽约时报》还呼吁摧毁几乎所有的GPT等大模型。

一直以来,AI界多位大佬认为「合成数据」或许是解决这个问题的最优解。

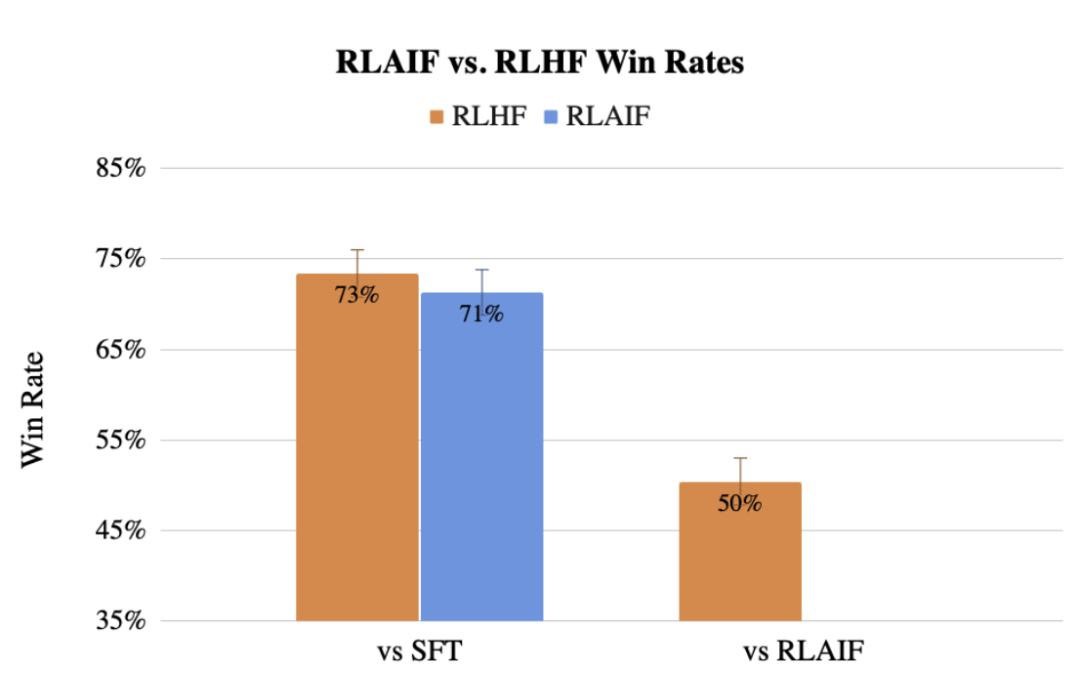
此前,谷歌团队还提出了用LLM代替人类标记偏好的方法RLAIF,效果甚至不输人类。
现如今,谷歌MIT的研究人员发现,从大模型中学习可以得到使用真实数据训练的最佳模型的表征。
这一最新方法称SynCLR,一种完全从合成图像和合成描述学习虚拟表征的方法,无需任何真实数据。

论文地址:https://arxiv.org/abs/2312.17742
实验结果表明,通过SynCLR方法学习到的表征,能够与OpenAI的CLIP在ImageNet 上的传输效果一样好。
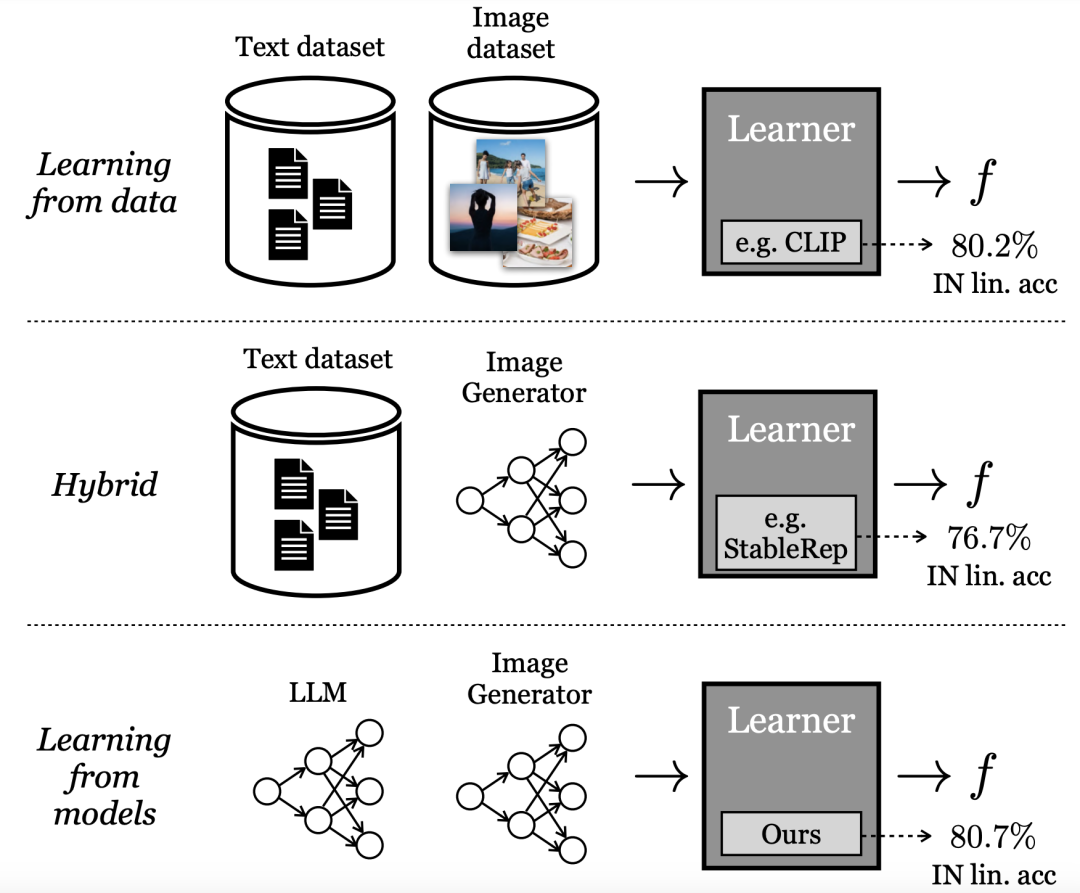
从生成模型中学习
目前表现最好的「视觉表征」学习方法依赖于大规模的实际数据集。然而,真实数据的收集却有不少的困难。
为了降低收集数据的成本,研究人员本文中提出了一个问题:
从现成的生成模型中采样的合成数据,是否是一条通往大规模策划数据集的可行之路,从而训练出最先进的视觉表征?
与直接从数据中学习不同,谷歌研究人员称这种模式为「从模型中学习」。作为建立大规模训练集的数据源,模型有几个优势:
- 通过其潜在变量、条件变量和超参数,为数据管理提供了新的控制方法。
- 模型也更容易共享和存储(因为模型比数据更容易压缩),并且可以产生无限数量的数据样本。
越来越多的文献研究了生成模型的这些特性和其他优点和缺点,并将其作为训练下游模型的数据源。
其中一些方法采用混合模式,即混合真实数据集和合成数据集,或需要一个真实数据集来生成另一个合成数据集。
其他方法试图从纯粹的「合成数据」中学习表征,但远远落后于表现最好的模型。
论文中,研究人员提出的最新方法,使用生成模型重新定义可视化类的粒度。
如图2所示,使用2个提示生成了四张图片「一只戴着墨镜和沙滩帽的金毛猎犬骑着自行车」和「一只可爱的金毛猎犬坐在寿司做成的房子里」。
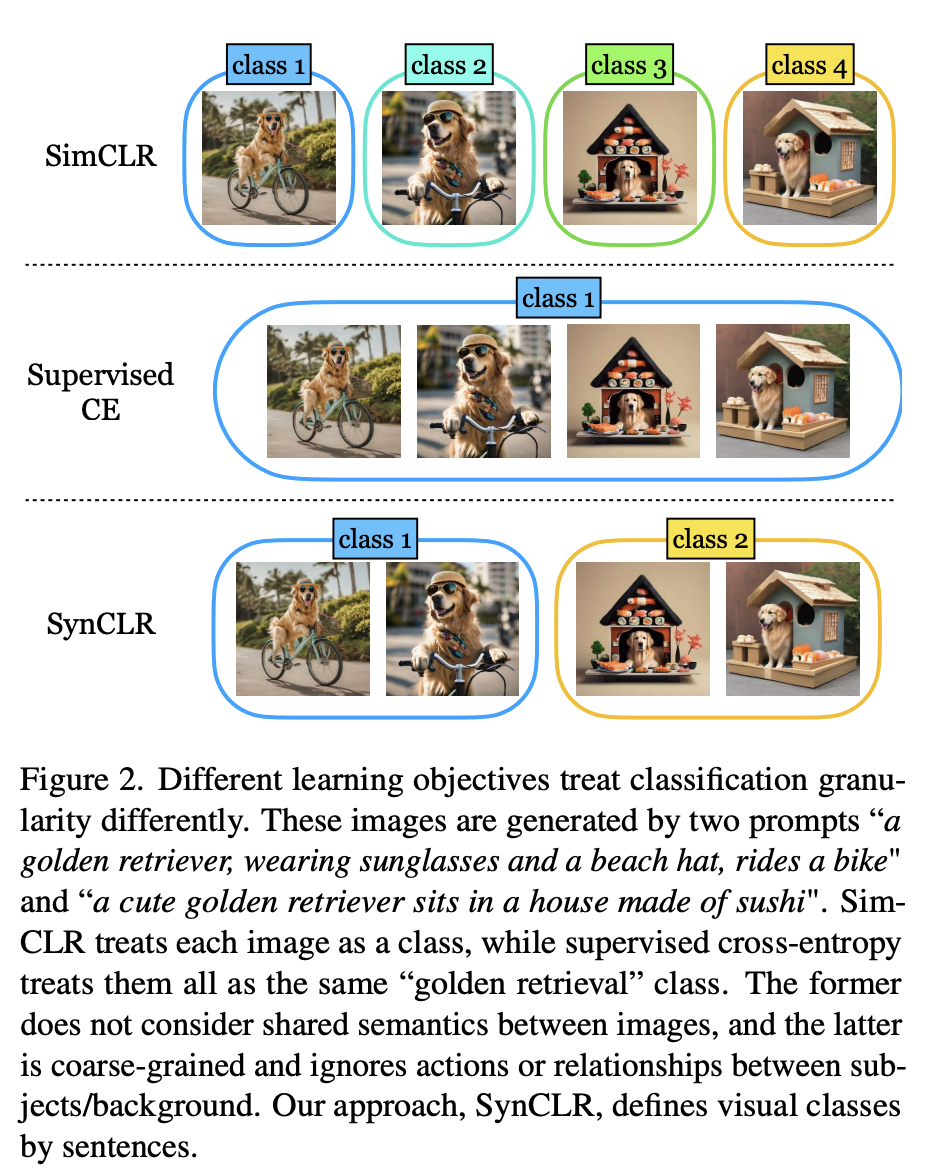
传统的自监督方法(如Sim-CLR)会将这些图像视为不同的类,不同图像的嵌入会被分开,而不会明确考虑图像之间的共享语义。
另一个极端是,监督学习方法(即SupCE)会将所有这些图像视为单一类(如「金毛猎犬」)。这就忽略了这些图像在语义上的细微差别,例如在一对图像中狗在骑自行车,而在另一对图像中狗坐在寿司屋内。
相反,SynCLR方法将描述视为类,即每个描述一个可视化类。
这样,我们就可以按照「骑自行车」和「坐在寿司店里」这两个概念对图片进行分组。
这种粒度很难在真实数据中挖掘,因为收集由给定描述的多张图片并非易事,尤其是当描述数量增加时。
然而,文本到图像的扩散模型从根本上就具备这种能力。
只需对相同的描述设定条件,并使用不同的噪声输入,文本到图像的扩散模型就能生成与相同描述相匹配的不同图像。
具体来说,作者研究了在没有真实图像或文本数据的情况下,学习视觉编码器的问题。
最新方法依赖3个关键资源的利用:一个语言生成模型(g1),一个文本到图像的生成模型(g2),以及一个经过整理的视觉概念列表(c)。
前处理包括三个步骤:
(1)使用(g1)合成一组全面的图像描述T,其中涵盖了C中的各种视觉概念;
(2)对于T中的每个标题,使用(g2)生成多个图像,最终生成一个广泛的合成图像数据集X;
(3)在X上进行训练,以获得视觉表示编码器f。
然后,分别使用llama-27b和Stable Diffusion 1.5作为(g1)和(g2),因为其推理速度很快。
合成描述
为了利用强大的文本到图像模型的能力,来生成大量的训练图像数据集,首先需要一个不仅精确描述图像而且展示多样性的描述集合,以包含广泛的视觉概念。
对此,作者开发了一种可扩展的方法来创建如此大量的描述集,利用大模型的上下文学习能力。
如下展示了三个合成模板的示例。

如下是使用Llama-2生成上下文描述,研究人员在每次推理运行中随机抽取三个上下文示例。
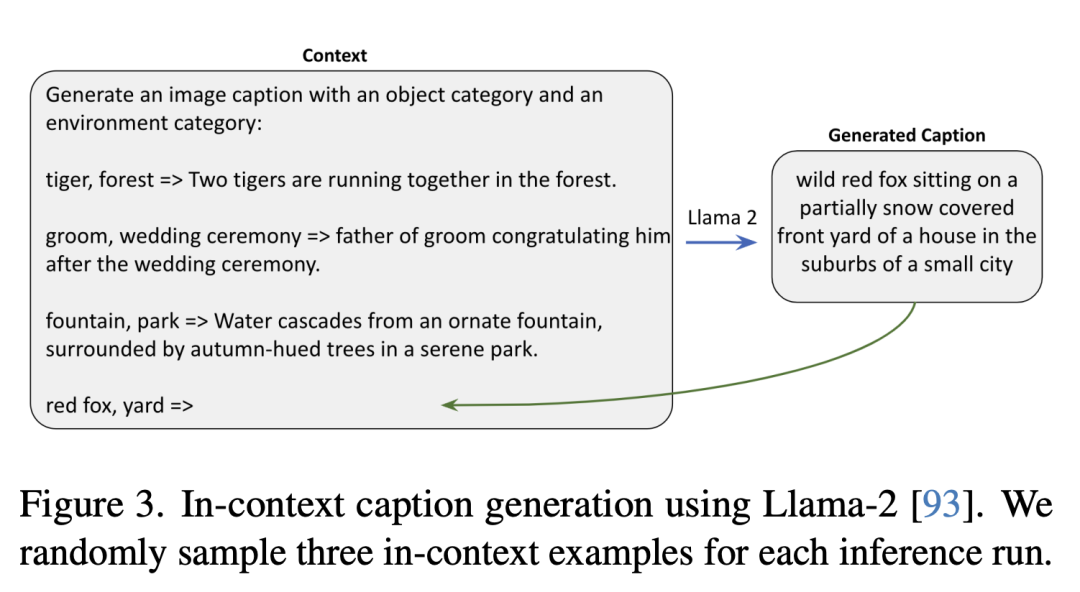
合成图像
对于每个文本描述,研究人员都会用不同的随机噪声启动反向扩散过程,从而生成各种图像。
在此过程中,无分类器引导(CFG)比例是一个关键因素。
CFG标度越高,样本的质量和文本与图像之间的一致性就越好,而标度越低,样本的多样性就越大,也就越符合基于给定文本的图像原始条件分布。

表征学习
论文中,表征学习的方法建立在StableRep的基础上。
作者提出的方法的关键组成部分是多正对比学习损失,它的工作原理是对齐(在嵌入空间)从同一描述生成的图像。
另外,研究中还结合了其他自监督学习方法的多种技术。
与OpenAI的CLIP相媲美
实验评估中,研究人员首先进行消融研究,以评估管道内各种设计和模块的有效性,然后继续扩大合成数据的量。
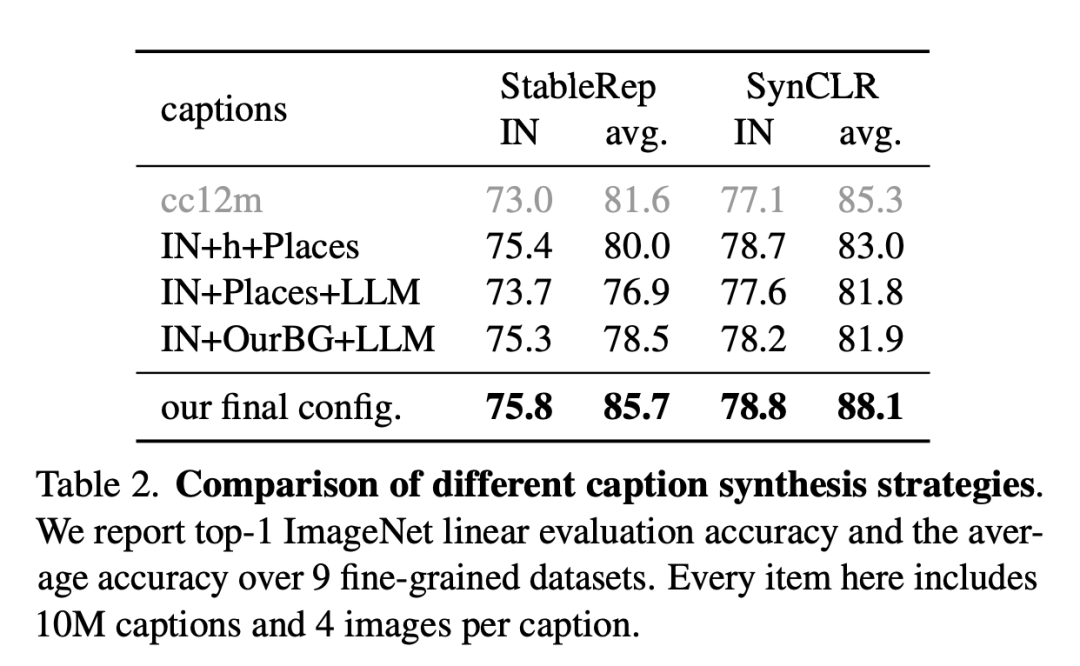
下图是不同描述合成策略的比较。
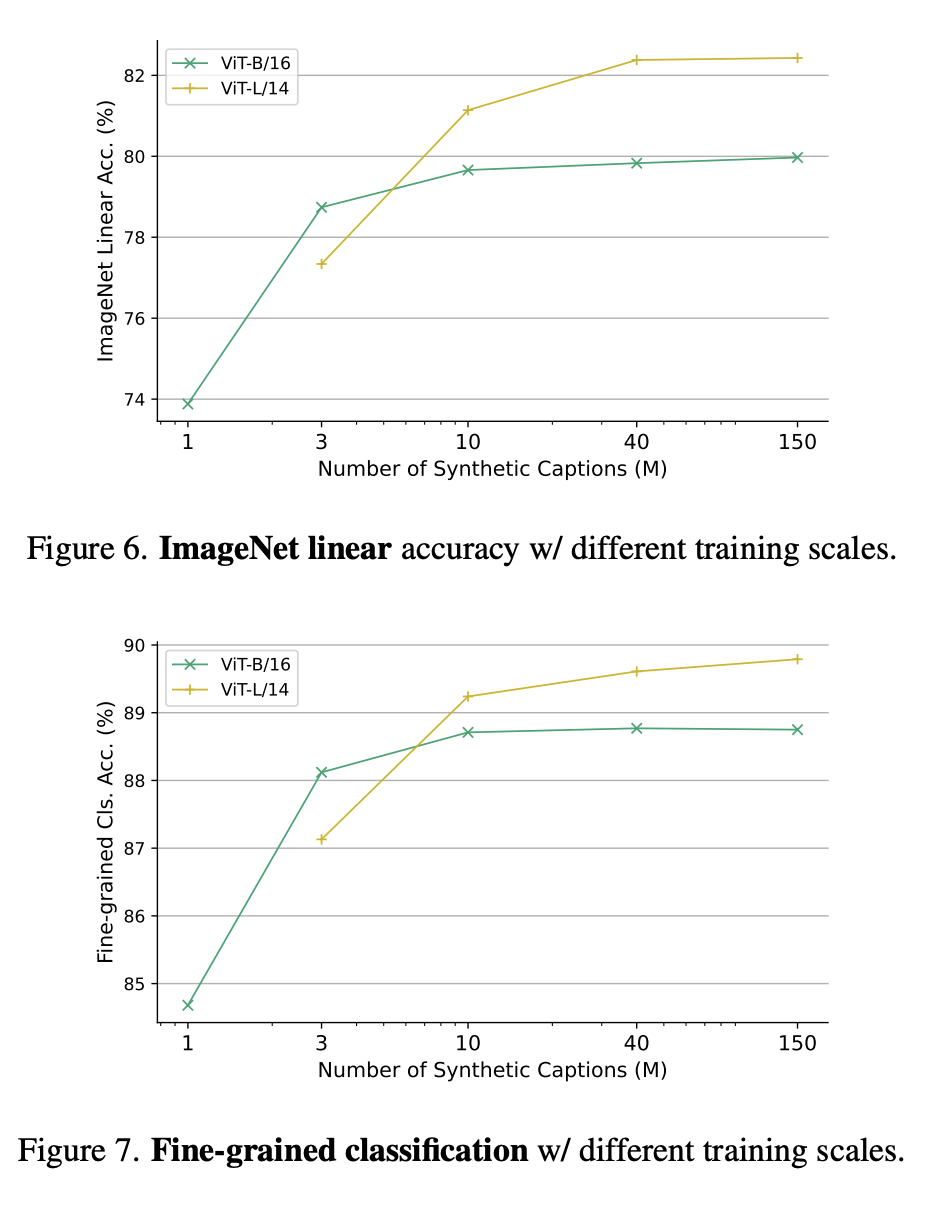
研究人员报告了9个细粒度数据集的ImageNet线性评估准确性和平均准确性。这里的每个项目包括1000万个描述和每个描述4张图片。
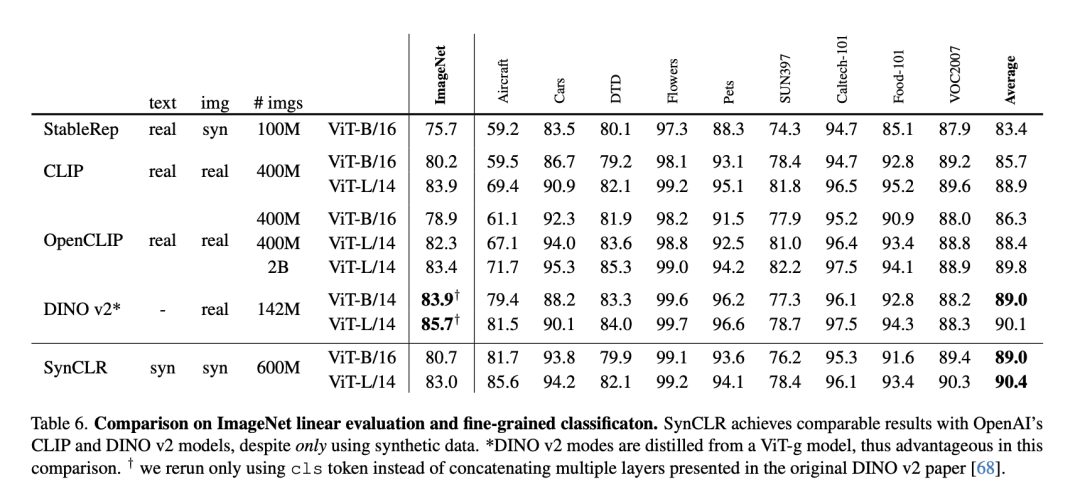
下表是ImageNet线性评估与细粒度分类的比较。
尽管只使用了合成数据,但SynCLR与OpenAI的CLIP和DINO v2模型取得了不相上下的结果。
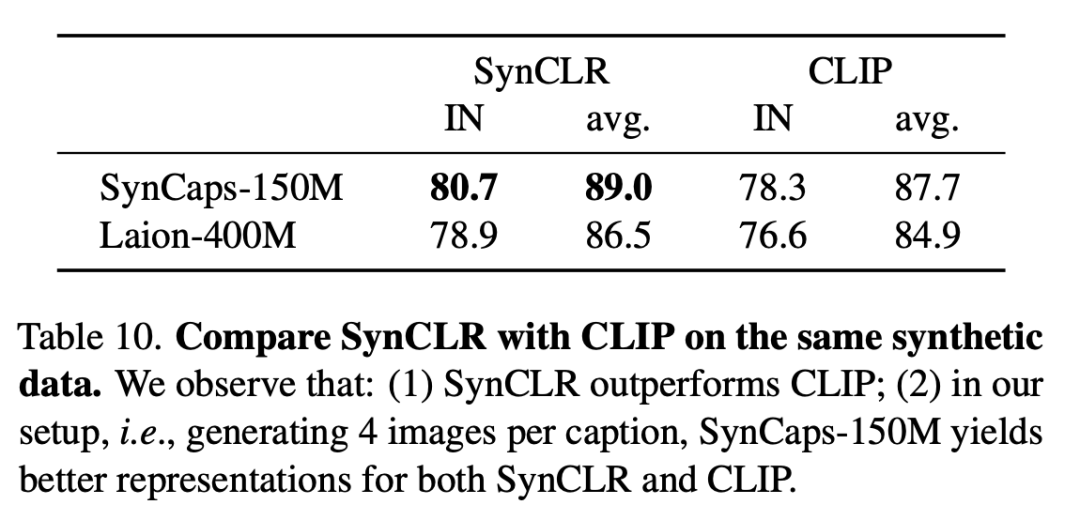
下表是在相同的合成数据上比较SynCLR和CLIP,可以看出,SynCLR明显优于CLIP。
具体设置为,每个标题生成4个图像,SynCaps-150M为SynCLR和CLIP提供了更好的表示。
PCA可视化如下。按照DINO v2,研究人员计算了同一组图像的斑块之间的PCA,并根据其前3个分量进行着色。
与DINO v2相比,SynCLR对汽车和飞机的绘制的图更为准确,而对能绘制的图则稍差一些。

图6和图7中,分别展示了不同训练规模下的ImageNet线性准确率,以及不同训练参数规模下的精细分类。
为什么要从生成模型中学习?
一个令人信服的原因是,生成模型可以像数百个数据集一样同时运作,能够为策划训练数据提供了一种方便有效的方法。
总而言之,最新论文研究了视觉表征学习的新范式——从生成模型中学习。
在没有使用任何实际数据的情况下,SynCLR学习到的视觉表征,与最先进的通用视觉表征学习器学习到的视觉表征不相上下。
-
模型
+关注
关注
1文章
3854浏览量
52310 -
GPT
+关注
关注
0文章
375浏览量
17003 -
OpenAI
+关注
关注
9文章
1258浏览量
10309 -
大模型
+关注
关注
2文章
3841浏览量
5289
原文标题:谷歌MIT最新研究证明:高质量数据获取不难,大模型就是归途
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
新型汽车工厂质量量化评估体系——基于用户体验与反馈研究及模型构建
高质量RAG系统的五个核心设计要点
万里红入选2025“铸基计划”高质量数字化转型典型案例集
万里红入选信通院2025年高质量数字化转型解决方案集
万里红入选信通院2025高质量数字化转型全景图三大核心领域
声智科技亮相2026海淀区经济社会高质量发展大会
中科曙光入选信通院2025上半年度高质量数字化转型十大典型案例
标贝科技参编《人工智能高质量数据集建设指南》
易华录入选国家首批高质量数据集建设先行先试工作名单
索尼重载设备的高质量远程制作方案和应用(2)

索尼重载设备的高质量远程制作方案和应用(1)




评论