 轻量级占用网络FlashOcc:主打实时性,高精度高效内存
轻量级占用网络FlashOcc:主打实时性,高精度高效内存
自特斯拉在2021 AI Day上提出BEV障碍物感知的思路后,BEV逐渐成为业界争相落地的热点。
但BEV也存在一些待解决问题,比如:
(1) 仅能对真实世界中类别限定的目标进行的感知(如图1.b所示),如果想得到可行驶区域、环岛、人行横道、上方障碍物(如各类红绿灯或摄像头悬臂、地库限高架等)、临时广告牌等,需要额外的感知模块去进行处理;
(2) 障碍物仅能用3D框描述,具体的形状轮廓也丢失了;
(3) 如果行驶环境中出现没见过的物体(如图1.a中右下角的红色移动广告牌或者红绿灯悬臂),那障碍物检测也会失效,只能通过多模态开放场景检测技术来弥补这类问题,但是这在目前算力有限的自动驾驶芯片上是无法实现的。
因此在2022的AI day上特斯拉提出占据预测的新思路,成功解决了上述问题。占据预测任务就是将以自车为中心的三维空间划分成一个个小的体素栅格,然后预测每个栅格的语义类别。具体效果如图1.c所示,可以看出占据预测可以对整个复杂世界的所有物体进行有效感知,从而有效的解决上述障碍物预测的问题。
但是现有公开的占据预测方法都需要构建三维体素级的特征表示,这不可避免地引入大量计算资源消耗,此外还需要硬件平台对3D(可变形)卷积或者transformer模块有较好的支持,这些都阻碍了业界将占用预测在实车上的部署落地。
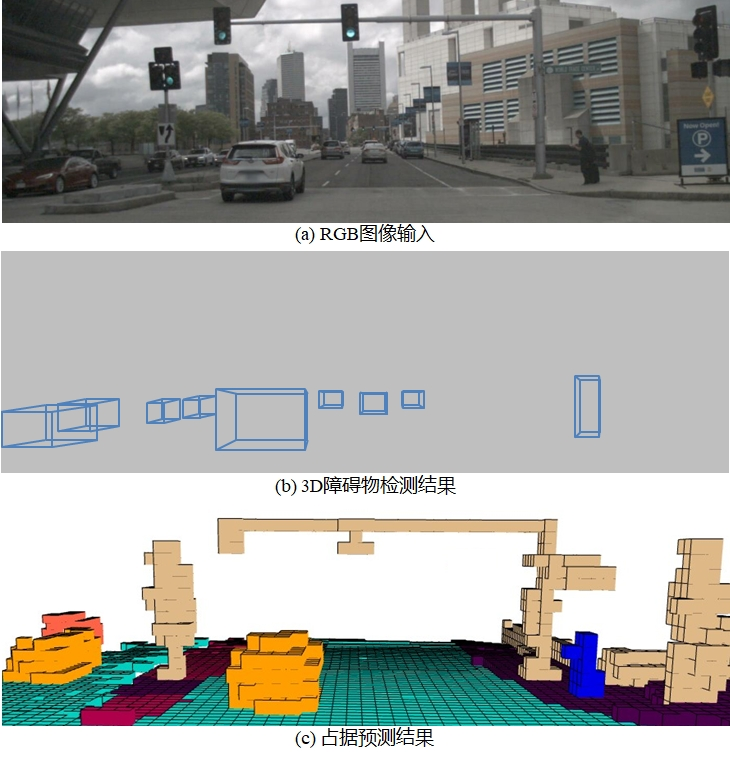
图 1. 障碍物检测与占据预测效果对比。受训练数据约束,预测范围为前后左右40m,上下-1m到5.4m,栅格粒度0.4m。
与使模型变得更大、更复杂从而取得优异性能的趋势相反,理想的框架应该对不同的端上芯片部署友好,并且保持高精度。本着轻量易部署且性能无损甚至还提升的初衷下,大连理工、后摩智能以及阿德莱德联合提出了一种简单轻量的占据插件,称之为FlashOCC。
通过在主流占据方法(BEVDetOcc、FBOcc、UniOcc等)上的验证,证明了FlashOCC在部署显存需求、推理时间、训练耗时以及模型精度上都取得了最优的权衡,并且对各类端上芯片部署友好。

论文地址:https://arxiv.org/abs/2311.12058
代码链接:https://github.com/Yzichen/FlashOCC
内容简介
方法架构:
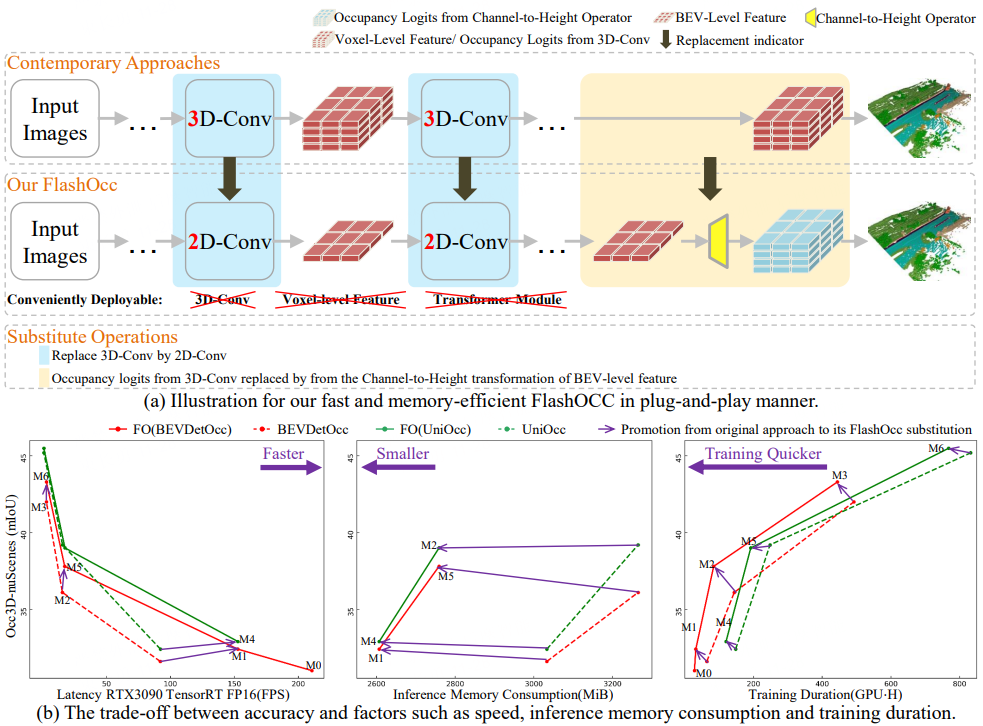
图 2插件概述以及综合性能比对
FlashOcc以极优的精度完成了实时环视3D占用预测,代表了该领域的开创性贡献。此外,它还展示了跨不同车载平台部署的优越性,因为不需要昂贵的体素级特征处理,从而避免了transformer或 3D(可变形)卷积算子。FlashOcc通过2类替换对现有基于体素级3D特征的占据任务进行提升:
(1) 用2D卷积替换3D卷积;
(2) 用通道到高度变换替换从3D卷积得到的占用预测,具体如图1.(a)所示。图1.(b)则通过图表详细说明了模型精度与速度、推理内存消耗以及训练时间等因素之间的权衡。
虽然FlashOcc专注于以即插即用的方式增强现有模型,但它仍然可以分为五个基本模块,具体如图2所示:
(1) 用于提取图像特征的2D图像编码器。
(2) 将2D图像特征映射到BEV表征的视图转换模块。
(3) 修正BEV特征的BEV编码器。
(4) 预测每个体素分割标签的占用预测头。
(5) 集成历史信息以提高性能的时间融合模块(可选)。
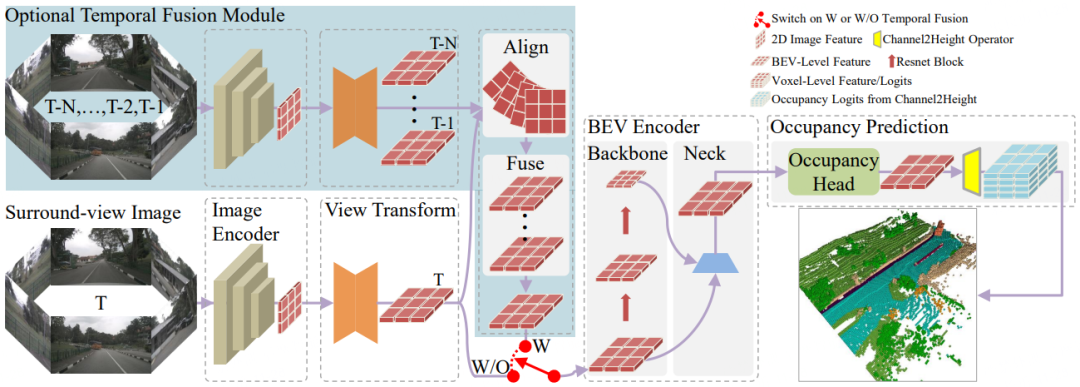
图 3框架图
实验表明我们方法在同比条件下都取得了最优的性能以及训练及部署资源消耗。
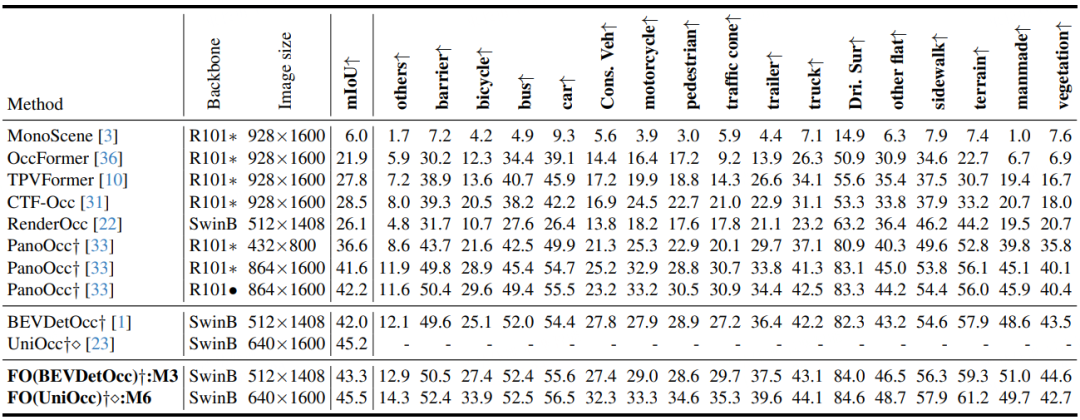
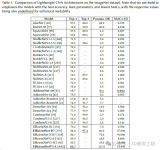
表 1Occ3D-nuSences验证集上的性能
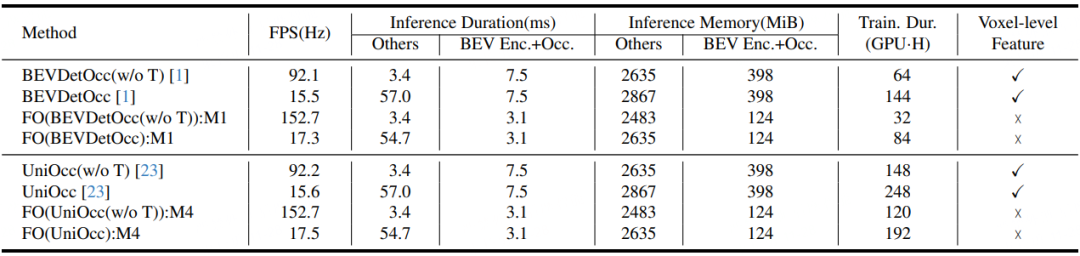
表 2训练及部署消耗说明
下图对模型预测进行可视化。由于用于训练的数据的栅格细粒度是40cmx40cmx40cm,因此对细节的构建较为粗糙。但即便如此,可以看到我们的方法可以有效预测横跨马路悬空的红绿灯,这证明FlashOcc有效的构建了高度信息,此外悬空树木的轮廓预测也证明了这一点;而图中表示行人的占据栅格,在胸口前栅格占据表示手持手机、腿后栅格占据表示后拉行李箱,证明我们方法对细节外形捕捉能力;交通锥的准确预测证明了小目标捕获能力。
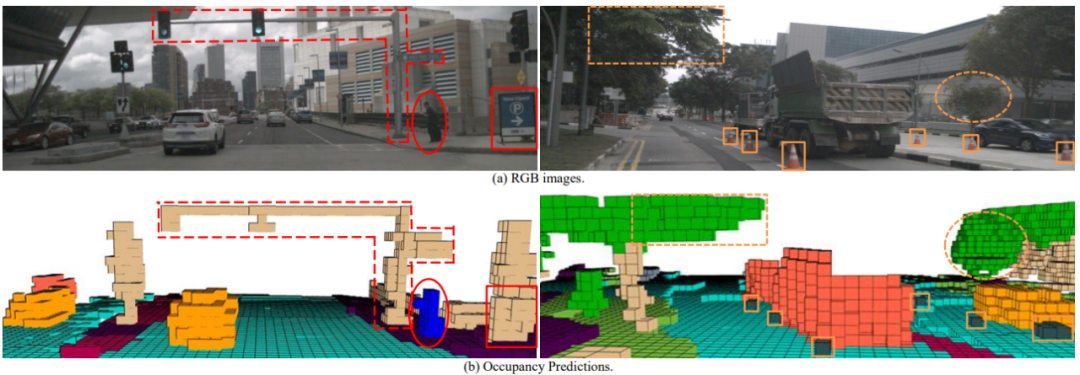
图 4 可视化。受训练数据约束,预测范围为前后左右40m,上下-1m到5.4m,栅格粒度0.4m。
总结与展望
FlashOcc初步探索了性能无损端上部署友好轻量级占用预测方法,为占据任务实车落地提供技术原型支撑,精度、效率和内存消耗均超越当前SOTA。未来进一步探索高效的端上可部署的端到端自动驾驶方案将是我们重要的研究方向。
审核编辑:刘清
-
FlaSh
+关注
关注
10文章
1644浏览量
148880 -
特斯拉
+关注
关注
66文章
6344浏览量
126919 -
自动驾驶芯片
+关注
关注
3文章
48浏览量
5128
原文标题:后摩前沿 | 轻量级占用网络FlashOcc:主打实时性,高精度高效内存
文章出处:【微信号:后摩智能,微信公众号:后摩智能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
风丘科技发布可调节档位高精度高压隔离模块
国巨高精度高容值贴片电容有哪些?

音频信号采集为什么要用专用的CODEC来实现,普通高精度高采样率ADC可以吗?
VS高精度电压传感器
TMAG5123-Q1 汽车类平面高精度高压霍尔效应开关数据表

国产芯上运行TinyMaxi轻量级的神经网络推理库-米尔基于芯驰D9国产商显板
实时Linux:解锁高效能和可靠性的关键
国产芯上运行TinyMaxi轻量级的神经网络推理库-米尔基于芯驰D9国产商显板
国产芯上运行TinyMaxi轻量级的神经网络推理库-米尔基于芯驰D9国产商显板

OPA627-DIE高精度高速DIFET运算放大器数据表

未来轻量级深度学习技术探索
EtherCAT主站控制器系统实时性测试






 工商网监
工商网监
评论