 商汤科技发布新一代大语言模型书生·浦语2.0
商汤科技发布新一代大语言模型书生·浦语2.0
1月17日,商汤科技与上海AI实验室联合香港中文大学和复旦大学正式发布新一代大语言模型书⽣·浦语2.0(InternLM2)。
InternLM2 的核心理念在于回归语言建模的本质,致力于通过提高语料质量及信息密度,实现模型基座语言建模能力质的提升,进而在数理、代码、对话、创作等各方面都取得长足进步,综合性能达到开源模型的领先水平。
InternLM2是在2.6万亿token的高质量语料上训练得到的。沿袭第一代书生·浦语(InternLM)设定,InternLM2包含7B及20B两种参数规格及基座、对话等版本,满足不同复杂应用场景需求,继续开源,提供免费商用授权。
回归语言建模本质
筑牢大模型能力基础
大模型的研究应回归语言建模本质,大模型各项性能提升的基础在于语言建模能力的增强。
为此,联合团队提出了新一代的数据清洗过滤技术,通过更高质量的语料及更高的信息密度,筑牢大模型能力基础。
主要发展了以下几个方面的技术方法:
多维度数据价值评估:基于文本质量、信息质量、信息密度等维度对数据价值进行综合评估与提升。
高质量语料驱动的数据富集:利用高质量语料的特征从物理世界、互联网以及语料库中进一步富集类似语料。
针对性的数据补齐:针对性补充语料,重点加强现实世界知识、数理、代码等核心能力。
目前,浦语背后的数据清洗过滤技术已经历三轮迭代升级。仅使用约60%的训练数据即可达到使用第二代数据训练1T tokens的性能表现,模型训练效率大幅提升。
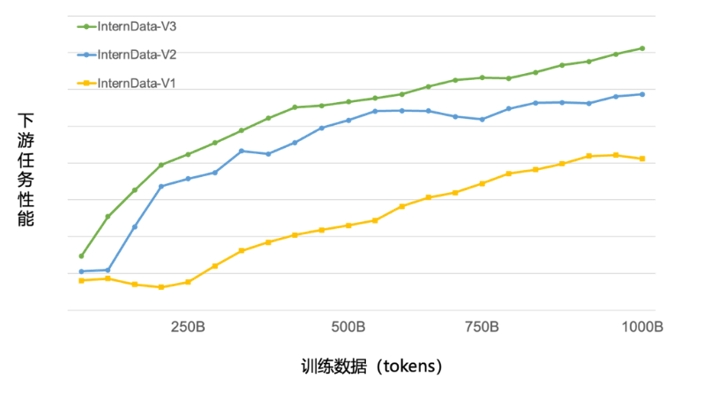
第三代数据清洗过滤技术大幅度提升模型训练效率
基于第三代数据清洗过滤技术,InternLM2语言建模能力实现了显著增强。
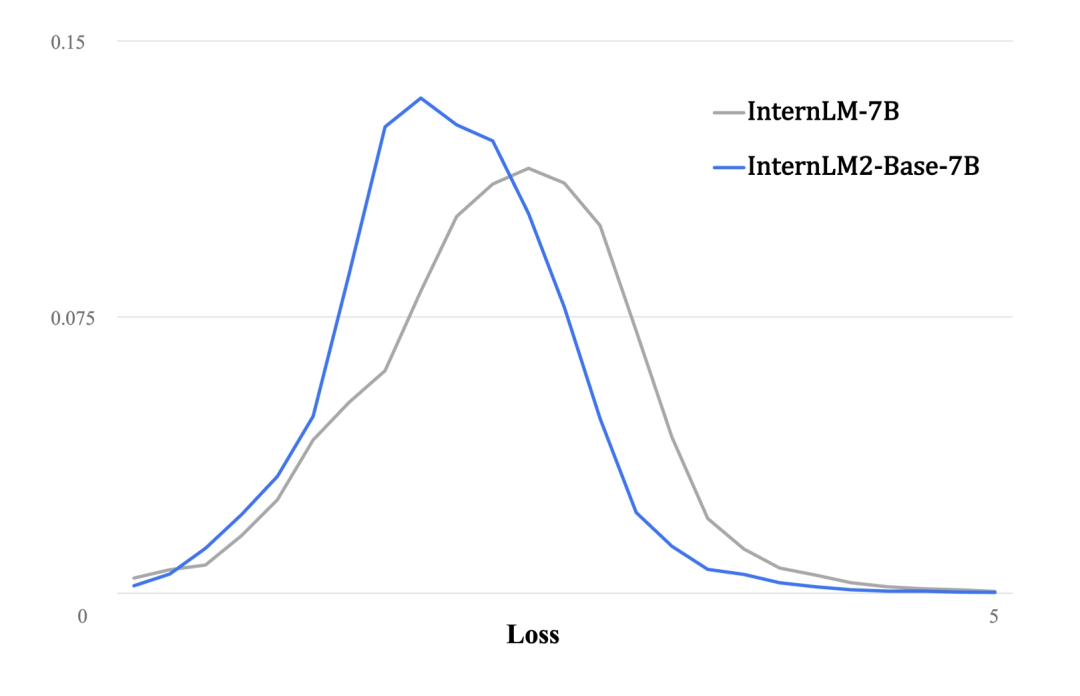
与第一代InternLM相比,InternLM2在大规模高质量的验证语料上的Loss分布整体左移,表明其语言建模能力实质性增强
支持200K超长上下文
“大海捞针”近乎完美
长语境输入及理解能力能够显著拓展大模型应用场景,比如支持大型文档处理、复杂的推理演算和实际场景的工具调用等。然而,大模型有限的上下文长度当前仍是学界及业内面临的重要难题。
通过拓展训练窗口大小和位置编码改进,InternLM2支持20万 tokens的上下文,能够一次性接受并处理约30万汉字(约五六百页的文档)的输入内容,准确提取关键信息,实现长文本中“大海捞针”。
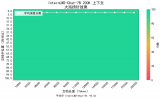
参考业界范例,研究人员对InternLM2进行了“大海捞针”试验:将关键信息随机插入一段长文本的不同位置并设置问题,测试模型能否从中提取出关键信息。
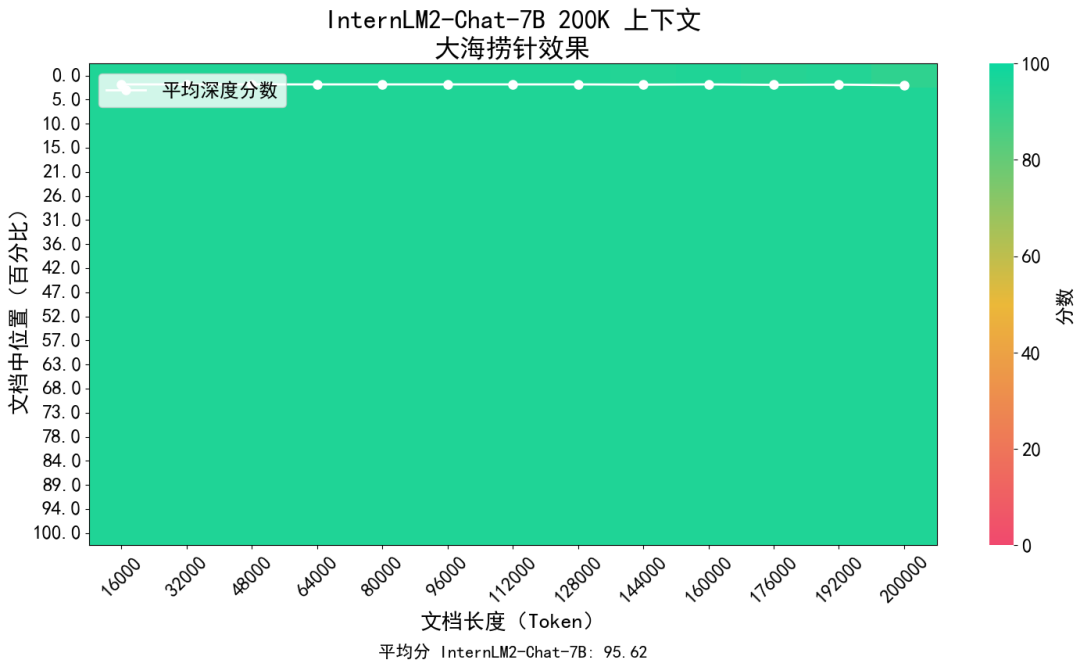
InternLM2“大海捞针”试验效果
上图展示了InternLM2在不同长度的上下文(横轴)及上下文中不同位置(纵轴)上召回关键信息的准确率(Recall)。红色代表较低的召回准确率,而绿色则代表较高的召回率。试验结果表明,InternLM2在上下文长度延展到200K时依旧保持了近乎完美的召回成功率,验证了InternLM2对于超长上下文坚实的支持能力。
为测试InternLM2在真实长文本处理任务中的能力,研究人员将一份时长3小时的公开会议录音转录稿输入模型中,并要求InternLM2从中提取出关键信息。
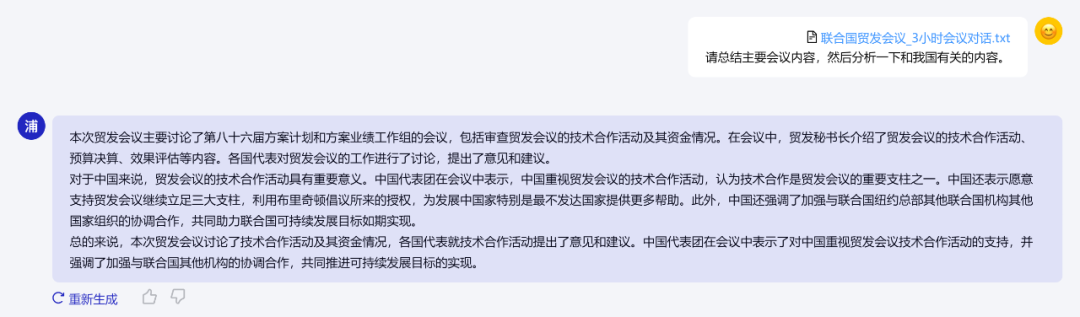
InternLM2准确总结“联合国2023年10月2日召开的联合国贸易和发展会议会议记录”
原始公开记录详见:
https://conf.unog.ch/digitalrecordings/index.html?guid=public/60.5295/9849DF25-F3B5-4BFF-8979-C5A989586205_10h09&position=0&channel=ORIGINAL
测试结果表明,尽管在未校对的文本中存在较多错别字,但InternLM2仍从中准确提炼出了关键信息,并总结了关键发言人的观点。
性能全面提升
综合领先同量级开源模型
InternLM2的各项能力获得全面进步,相比于初代InternLM,在推理、数学、代码等方面的能力提升尤为显著,综合能力领先于同量级开源模型。
根据大语言模型的应用方式和用户关注的重点领域,研究人员定义了语言、知识、推理、数学、代码、考试等六个能力维度,在55个主流评测集上对多个同量级模型的表现进行了综合评测。
评测结果显示,InternLM2的轻量级及中量级版本性能在同量级模型中表现优异。
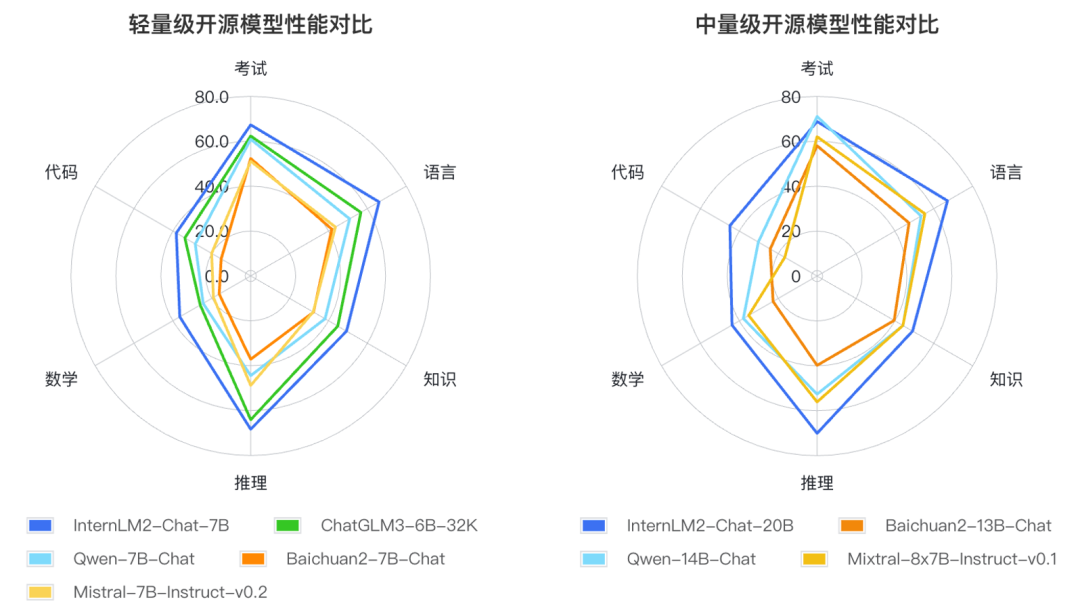
InternLM2的轻量级及中量级版本性能在同量级开源模型中表现优异
下面表格对比了InternLM2各版本与ChatGPT(GPT-3.5)以及GPT-4在典型评测集上的表现。
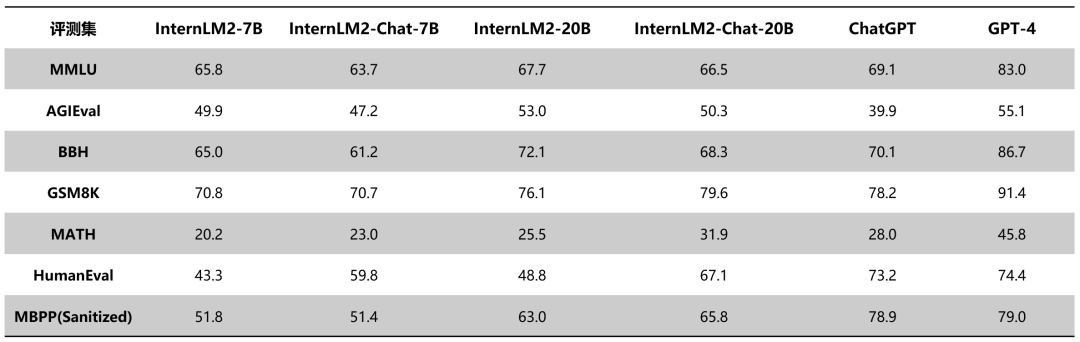
InternLM2与ChatGPT的评测结果对比
可以看到,InternLM2只用20B参数的中等规模,即在整体表现上达到了与ChatGPT比肩的水平。其中,在AGIEval、 BigBench-Hard(BBH)、GSM8K、MATH等对推理能力有较高要求的评测上,InternLM2表现甚至优于ChatGPT。
与此同时,综合性能的增强,带来了下游任务的全方位能力提升。新发布的InternLM2提供优秀的对话及创作体验,支持多轮任务规划及工具调用,并提供实用的数据分析能力。
对话及创作:更温情、更富想象力
InternLM2不仅在客观性能指标上提升显著,在主观体验上也有明显改善,可以为用户提供优秀的对话和交互体验。
研究测试表明,InternLM2-Chat可以精准地理解和遵循用户意图,具备较强的共情能力和丰富的结构化创作能力。
下面是几个示例:
示例一:在严格格式要求下编制课程大纲

InternLM2设计的课程大纲精准遵循用户要求(比如格式、数量、内容等)
示例二:以富有人文关怀的回答开解用户

InternLM2能够在对话中与用户“共情”
示例三:展开想象力,编写《流浪地球3》的剧本

InternLM2设计的具备充满丰富的合理想象,比如外星遗迹、量子纠缠的引入等。同时整个故事表现了人类面对危机时的勇气和团结精神
对话和创造的体验进步的原因,一方面是基础语言能力的显著增强,另一方面也得益于微调技术的提升。
InternLM2进行微调的过程使用了经过第三代数据清洗过滤技术处理的指令微调语料,同时也采用了更强的Online RLHF。
研究人员在微调InternLM2的过程中,对奖励模型和对话模型进行了三轮迭代更新,每一轮更新均针对前一轮模型的表现更新偏好数据与提示词。
在奖励模型训练(RM)和近端策略优化(PPO)阶段,研究人员均衡采用各类提示词,不仅提高了对话的安全性,也提升了用户体验。
工具调用:能力升级,更精准的工具选用,更可靠的多步规划
基于更强大、更具泛化性的指令理解、工具筛选与结果反思等能力,InternLM2可支持复杂智能体的搭建,支持对工具进行多轮有效调用及多步骤规划,完成复杂任务。
联合团队针对多种任务构建了细粒度工具调用评测集T-Eval(https://open-compass.github.io/T-Eval),InternLM2-Chat-7B在该评测集上表现超越了Claude-2.1和目前的开源模型,性能接近GPT-3.5。
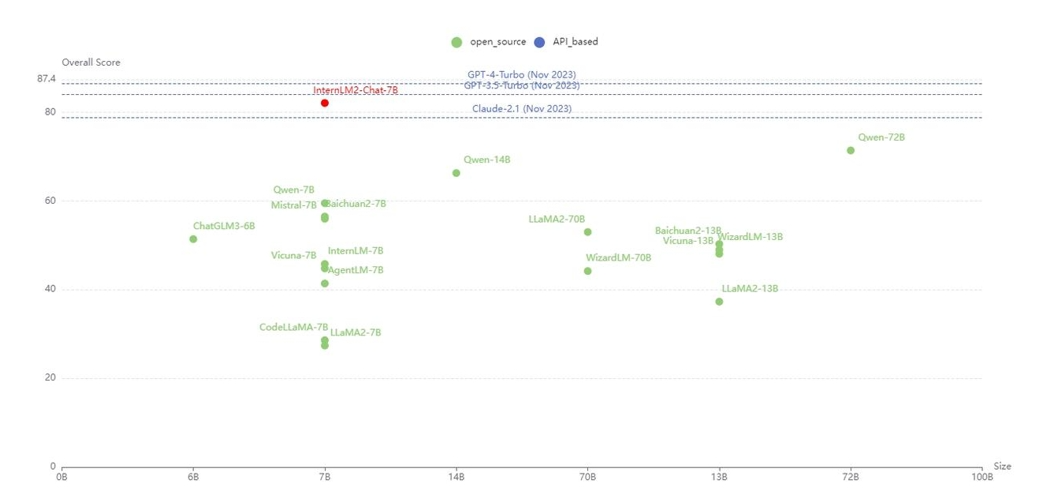
InternLM2工具调用能力全面提升
通过工具调用,使得大语言模型可通过搜索、计算、代码解释器等获取知识并处理更复杂的问题,从而拓展应用边界。研究人员对模型调用工具流程实施细粒度的拆解和分析,针对规划、推理、工具选择、理解、执行、反思等步骤进行了针对性增强和优化。
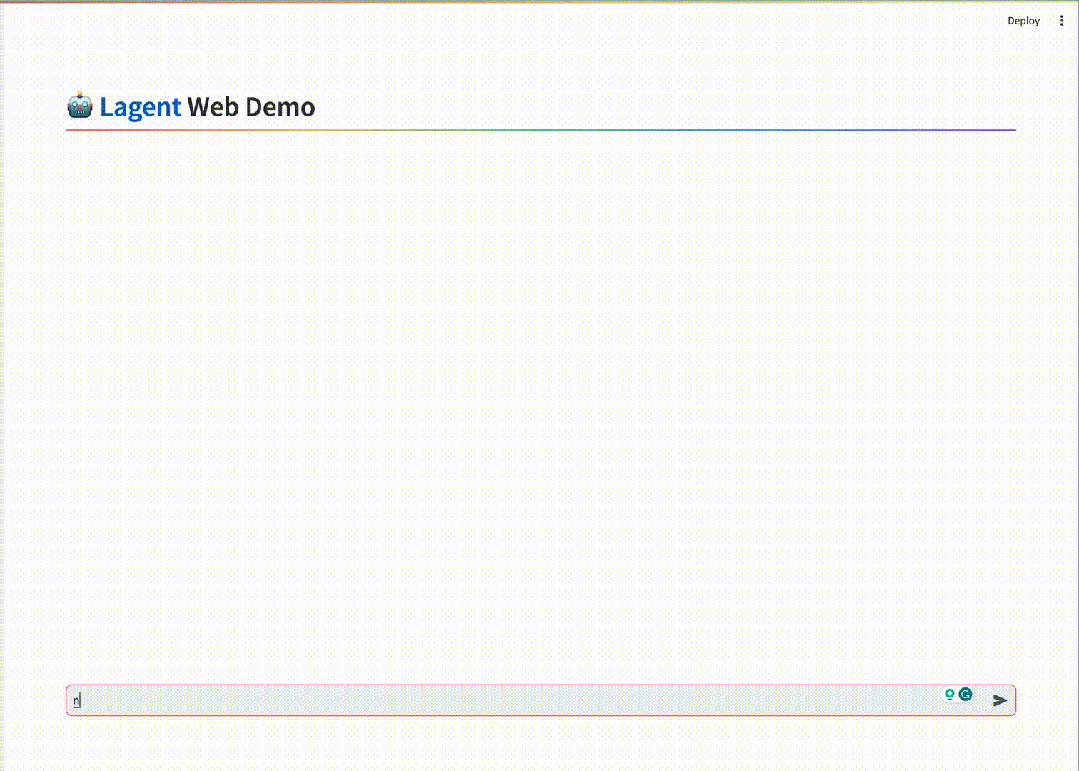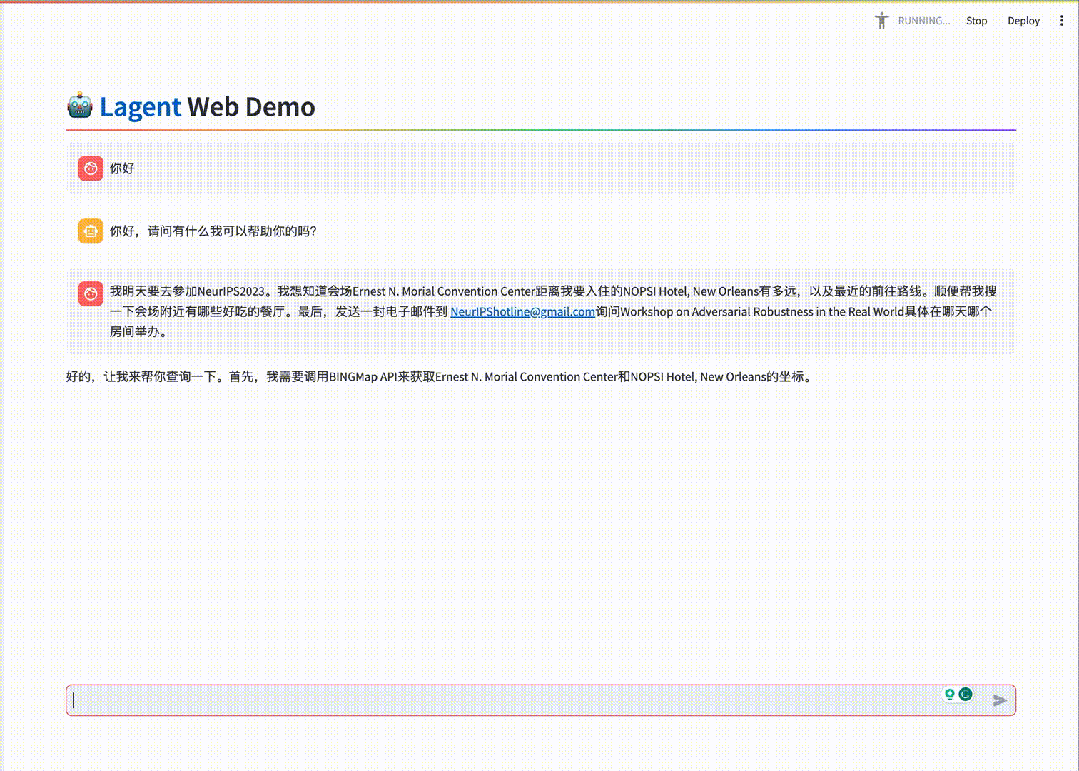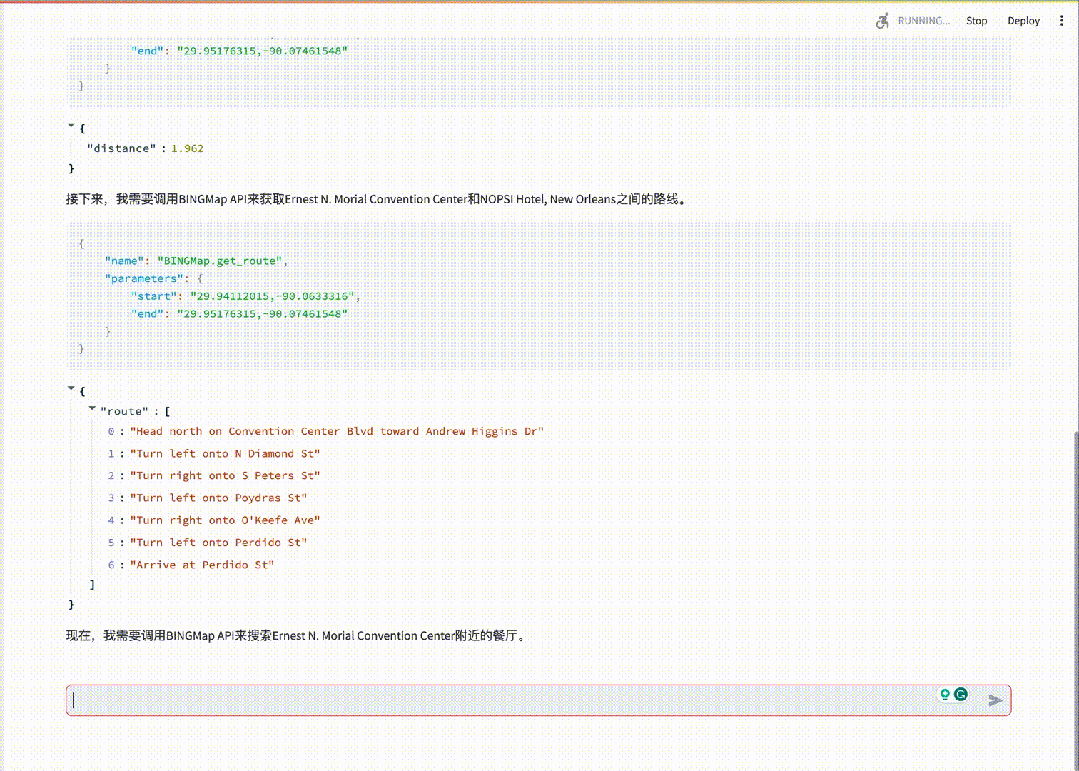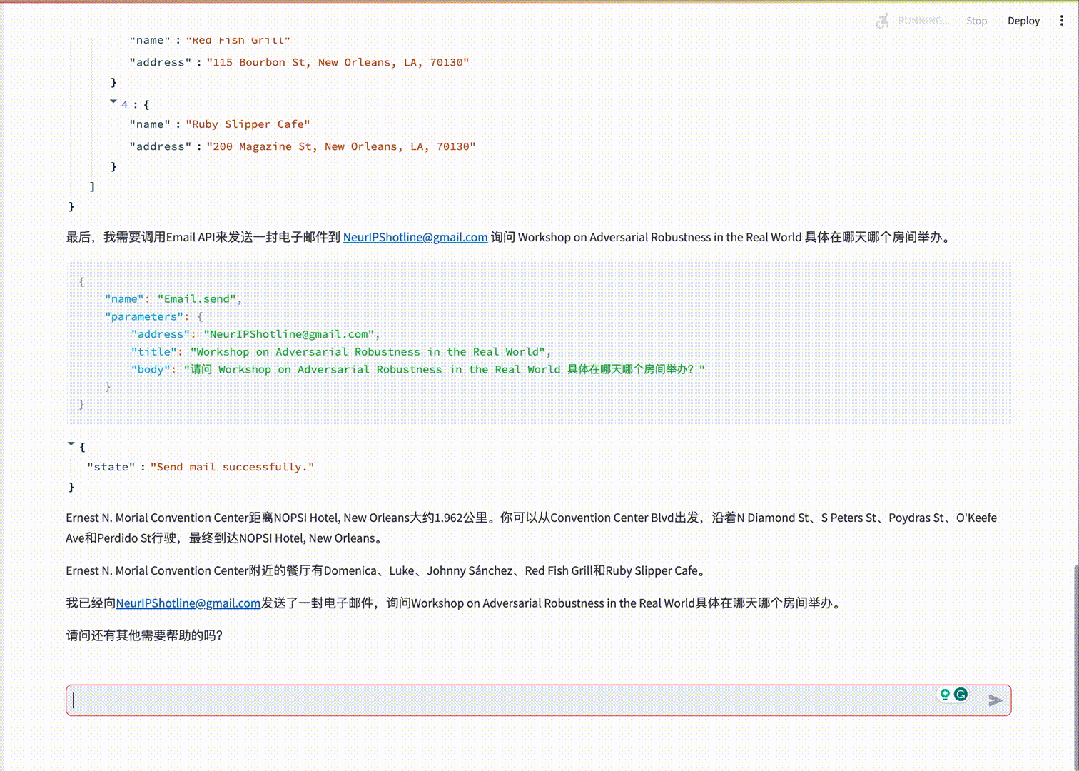
基于InternLM2通过开源智能体框架Lagent搭建的用户助手智能体,能够在一次指令回应中完成地图查询、路线规划、发邮件等任务
数理推理:会做题,还会可视化分析
数学能力是大模型逻辑思维和推理能力的重要体现。
InternLM2的数学能力全面提升,达到当前开源模型的标杆水平。
基于更加科学构建的预训练语料,InternLM2形成了很强的内生计算能力。
在不依靠计算器等外部工具的情况下,在100以内的简单数学运算上能够做到接近100%的准确率,在1000以内达到80%左右的运算准确率。在GSM8K和MATH评测中,InternLM2-20B的表现超过了ChatGPT(GPT-3.5)。

InternLM2在100以内的简单数学运算上能够做到接近100%的准确率
为应对各类复杂计算,InternLM2-Chat还可借助代码解释器(Code-Interpreter)编写代码进行计算,或对推理的结果进行形式化验证,从而解决计算要求更高或者演算过程更加复杂的问题。
在典型的数学评测集 GSM8K 和 MATH 上,配合代码解释器,InternLM2取得了更高的评测分数。其中对于难度更高的 MATH 数据集,InternLM2的计算精度从 32.5 大幅提升到 51.2,甚至超过了 GPT-4 的表现。

下面示例展示了InternLM2可以和代码解释器结合解决较复杂的高等数学问题。
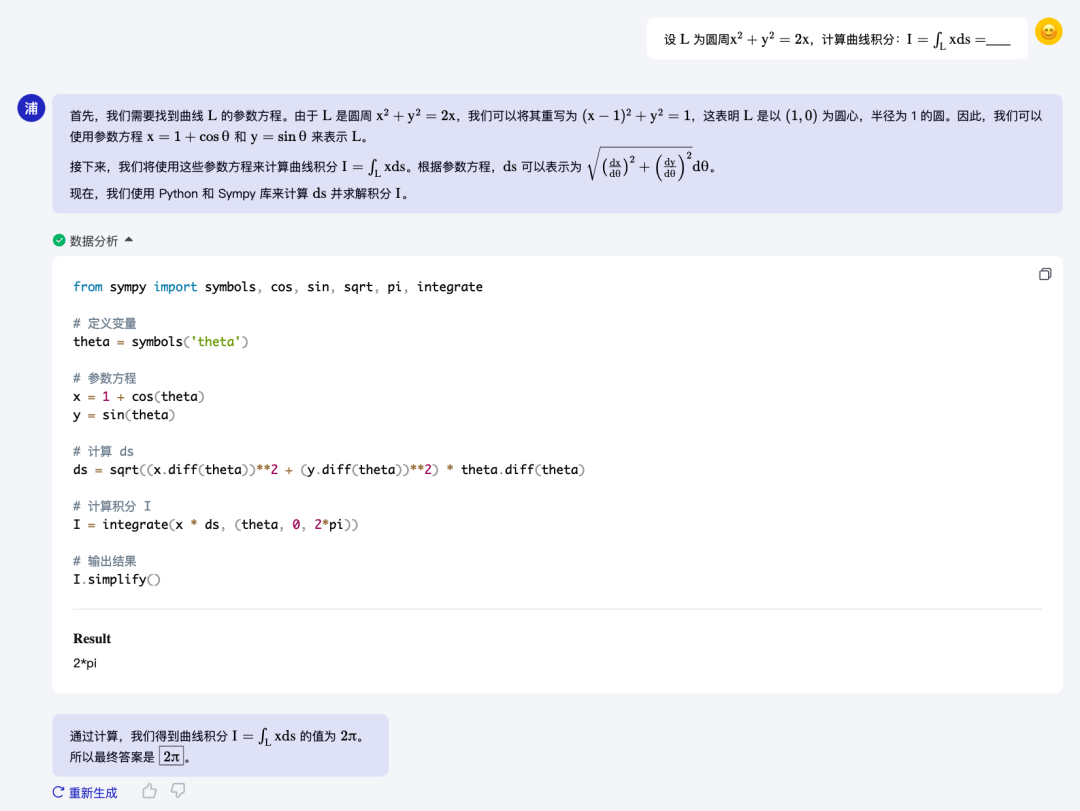
InternLM2能够完成积分求解等高等数学题目
基于在计算及工具调用方面强大的基础能力,InternLM2在语言模型中具备了数据分析和可视化实用能力,进一步贴近用户使用场景。
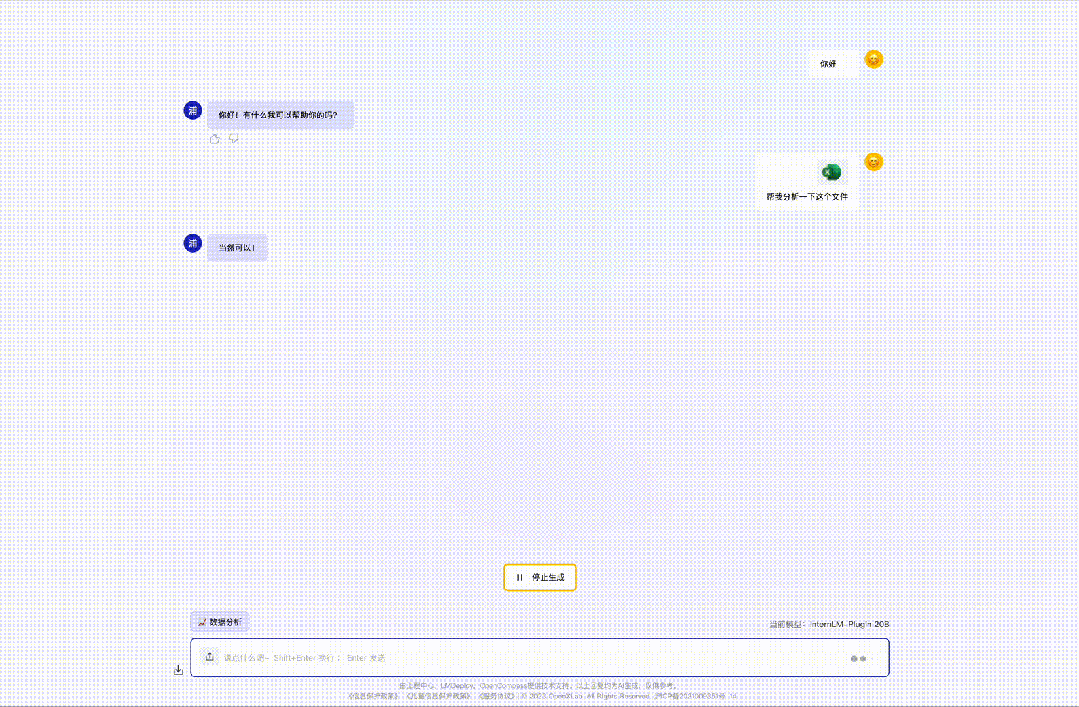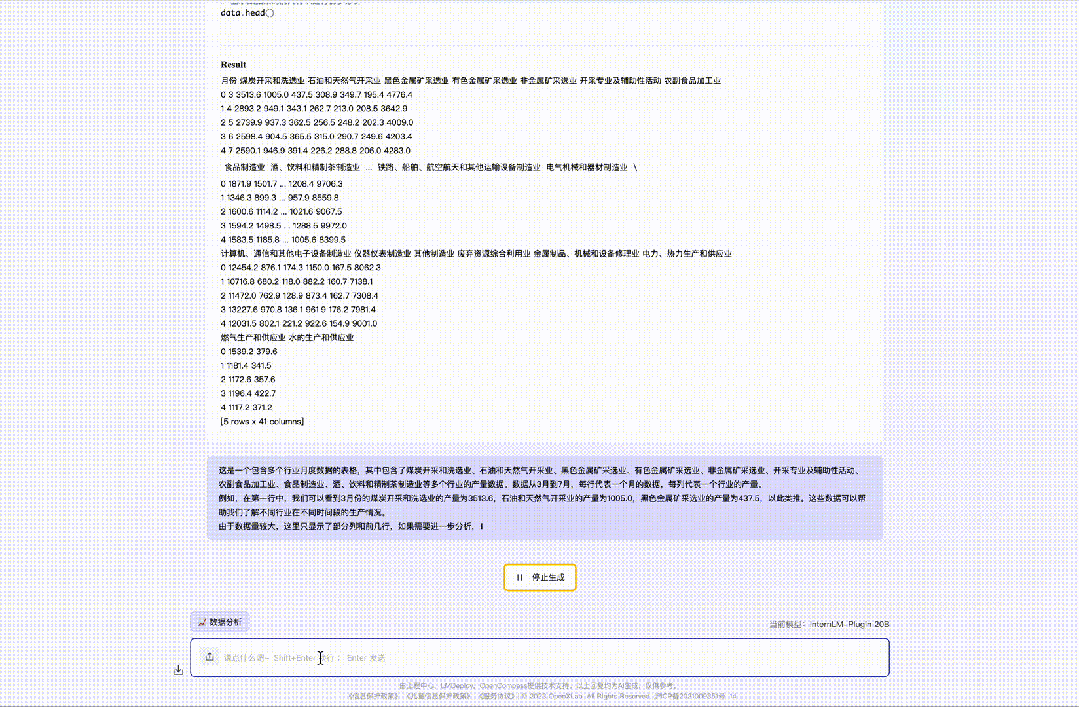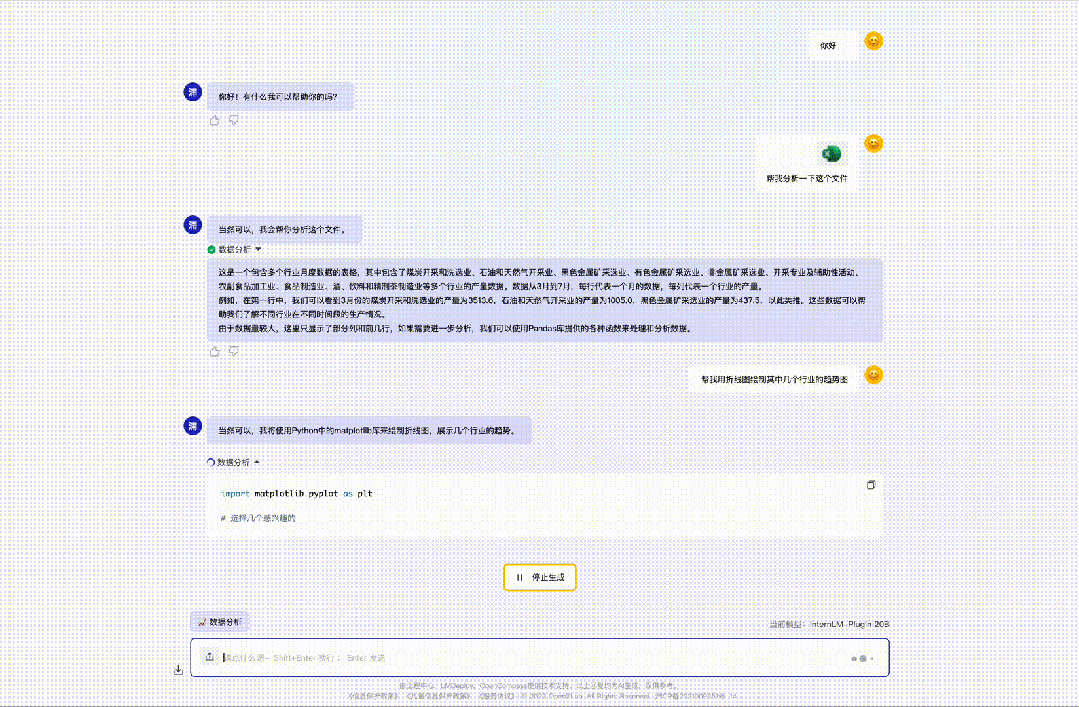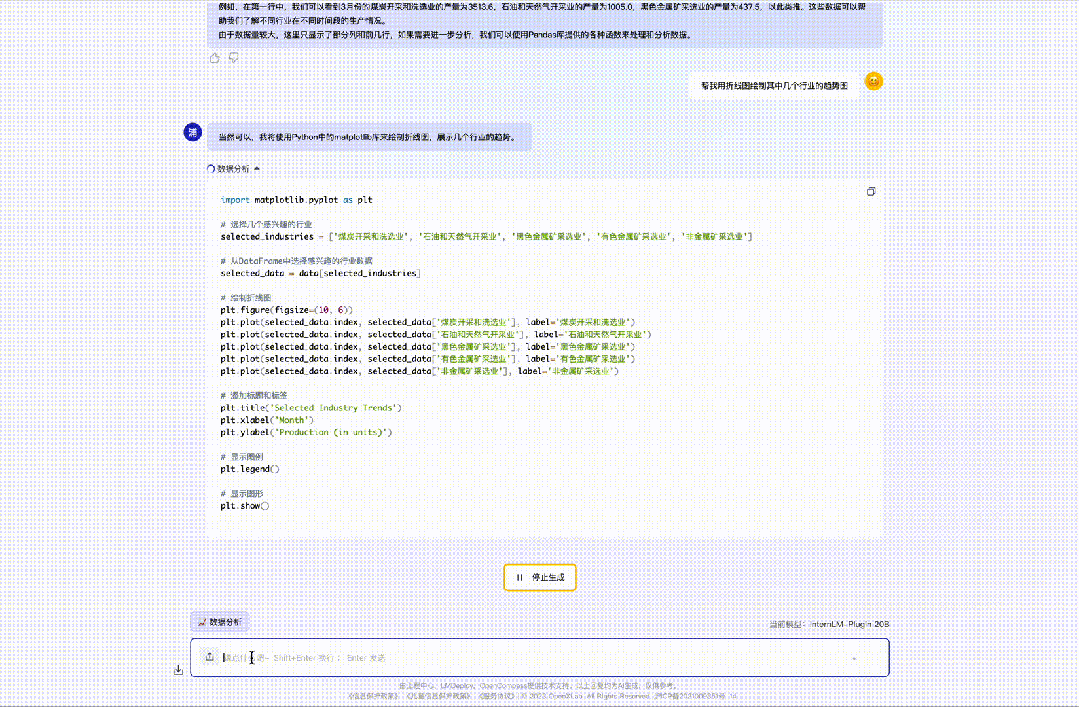
向InternLM2输入国家统计局公布的“2023年3-11月份规模以上工业企业主要财务指标(分行业)”,InternLM2能够分析数据并绘制折线图
审核编辑:汤梓红
-
AI
+关注
关注
87文章
30728浏览量
268874 -
语言模型
+关注
关注
0文章
520浏览量
10268 -
商汤科技
+关注
关注
8文章
508浏览量
36083
原文标题:支持200K超长上下文,一次可读30万汉字,“书生·浦语”2.0正式开源
文章出处:【微信号:SenseTime2017,微信公众号:商汤科技SenseTime】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
商汤星云发布新一代智能服务器AIS 4.0
联发科新一代天玑旗舰芯片针对谷歌大语言模型Gemini Nano优化
DeepL推出新一代翻译编辑大型语言模型
商汤科技与泰国DTGO集团联合发布泰语大模型

商汤科技发布日日新5.5大模型体系
商汤发布日日新大模型5.0粤语版
英特尔AI产品助力其运行Meta新一代大语言模型Meta Llama 3
商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo
上海AI实验室发布新一代书生·视觉大模型
恩智浦发布新一代智能语音技术组合的语音识别引擎
书生・浦语 2.0(InternLM2)大语言模型开源





 工商网监
工商网监
评论