 如何高效处理LMEM中的数据?这篇文章带你学会!
如何高效处理LMEM中的数据?这篇文章带你学会!
Weight Reorder是TPU-MLIR的一个pass(参考TPU-MLIR编译流程图),其完成了对部分常量数据的Layout变化和合并。本文介绍其中Convlotion Kernel的Reorder行为以及合并Bias机制,帮助大家理解Conv2D.cpp代码中的原理。
在SOPHON硬件中,存储单元多种多样,包括LMEM(本地存储器)、SMEM(静态SRAM)和GMEM(全局存储器,即片外DDR存储)。其中,LMEM作为一种高速SRAM,因其靠近执行单元(EU)而提供了高带宽和低延迟的访问特性。为了实现这种高速访问,SOPHON BM1684X处理器将LMEM划分为64个分区,每个分区均可由相应的NPU单元独立访问。每个NPU包含多个EU,并且在不同的计算类型下,EU处理的数据各不相同。NPU无法跨分区访问数据。下图展示了这种结构的概览。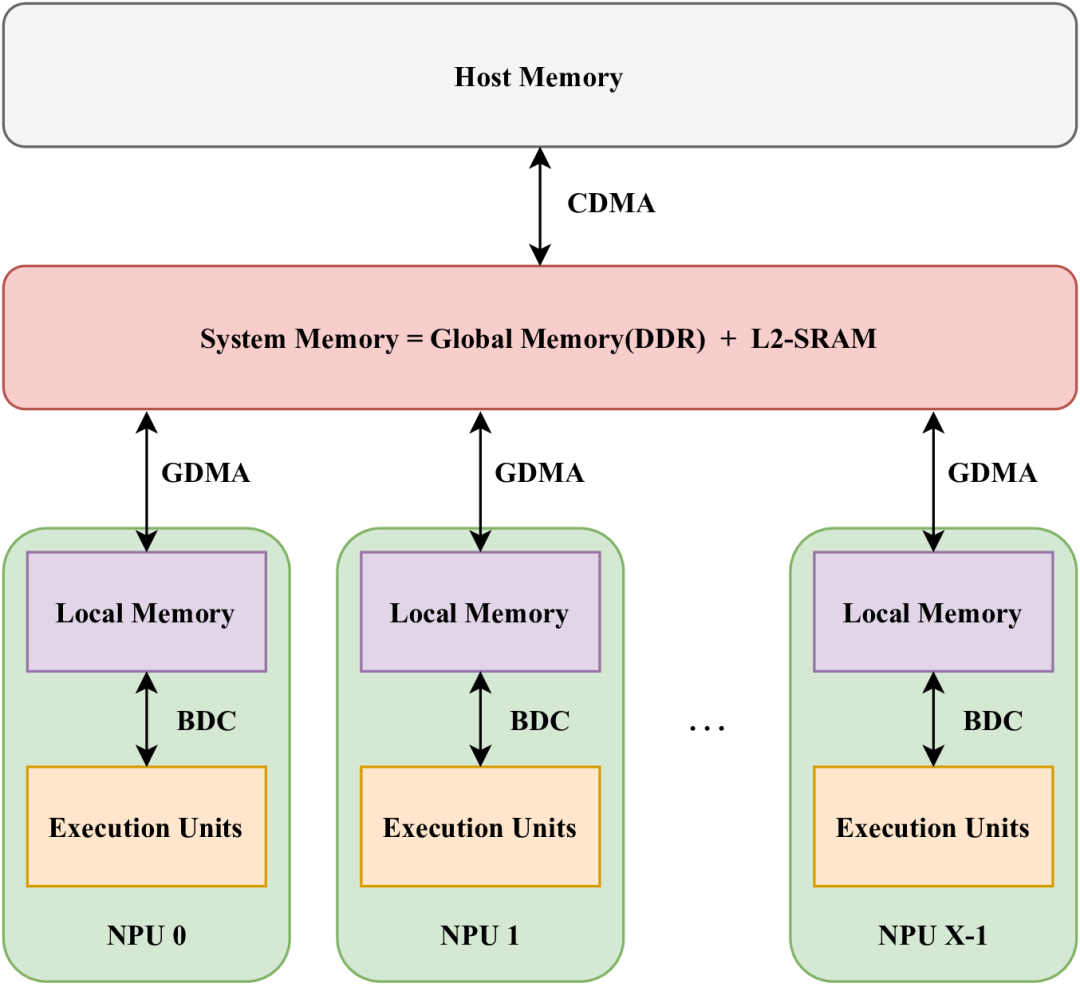
64个分区的地址是连续编码的,即第一个分区的下一个地址便是第二个分区的起始地址。为了简化编程,SOPHON定义了数据在LMEM中的布局(Layout)。为了更直观地描述这种布局,本文将采用numpy中的ndarray形式来演示,并使用numpy定义的操作来说明数据在存储器中的布局与神经网络中定义的数据存在的差异。
本文涉及的ndarray操作包括reshape和transpose,并定义了一个resize函数来整理数据布局。resize函数可以对数据的指定维度进行扩展。例如:
tensor_a.shape=(1,2,3,4)#对应于d0=1,d1=2,d2=3,d3=4
tensor_b=resize(tensor_a,(2,4,3,8))
此时,在d0、d1、d3维度上使用0进行填充,以达到最终尺寸。
In[1]:tensor_a
Out[1]:
array([[[[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9,10,11]],
[[12,13,14,15],
[16,17,18,19],
[20,21,22,23]]]])
In[2]:resize(tensor_a,(1,3,3,6))
Out[2]:
array([[[[0, 1, 2, 3, 0, 0],
[4, 5, 6, 7, 0, 0],
[8, 9,10,11, 0, 0]],
[[12,13,14,15, 0, 0],
[16,17,18,19, 0, 0],
[20,21,22,23, 0, 0]],
[[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]]]])
resize函数的一个参考实现如下:
defresize(src,shape):
out=np.zeros(shape,dtype=src.dtype)
_src_slice=tuple(slice(0,min(i,j))fori,jinzip(src.shape,shape))
out[_src_slice]=src
returnout
LMEM中四维数据的排布
在LMEM中,一个四维数据(n,c,h,w)的Channel维度会被分散到不同的lane上。以一个shape为(2,5,2,3)的数据为例,假设NPU数量为4,每个NPU中EU数量为4,并且数据在h,w维度上需要与EU对齐:
shape=(2,5,2,3)
a=np.arange(np.prod(shape)).reshape(shape)
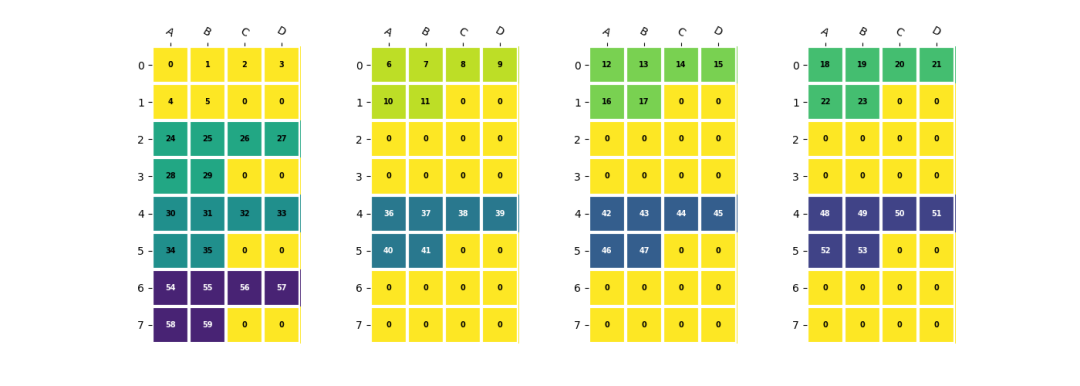
b=a.reshape(2,5,6)#数据hw合并
b=(
resize(b,(2,8,8)) #channel对齐到NPU,hw对齐到EU
.reshape(2,2,4,2,4)
.transpose(2,0,1,3,4)#(4,2,2,2,4)<- (npu_id, n^, c^, h^, w^)
)
其中(n^, c^, h^, w^)为每个lane上数据的实际shape,对应的stride也满足处理器中的定义。可以参考TPUKernel用户开发手册中的描述。npu_id维度是一个隐含维度,其值为npu数量,此处为4。
在4个NPU上对齐EU的数据排列
卷积权重的排列
为了确保EU能够高效地使用,BM1684X处理器中卷积的权重需要按照EU对齐的方式优先存储IC维度的数据,然后将OC维度分布到不同的NPU上。相应的存储方式可以表示为:
c=a.reshape(2,5,6)
c=(
resize(c,(1*4,2*4,6)) #npu,eu_align,h*w
.reshape(1,4,2,4,6)
.transpose(1,0,2,4,3) #<4x1x2x6x4>
)
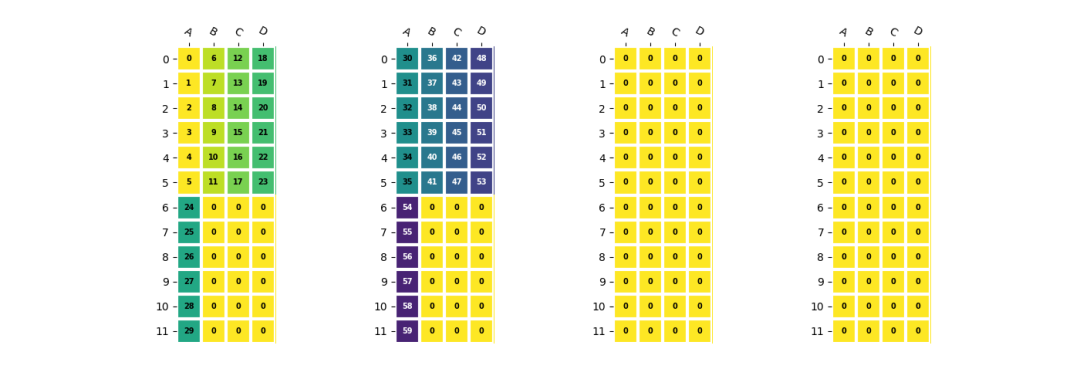 卷积权重的存储方式
卷积权重的存储方式
卷积权重与偏置的合并
在BM1684X中,权重需要按照EU对齐方式存储,而偏置则采用紧凑模式。由于偏置数据量较小,直接拷贝效率不高。因为两种模式下数据的stride不一致,无法直接将它们拼接在一起。在TPU-MLIR中,通过预先将权重和偏置合并,形成最终在LMEM中的存储形式,然后通过一条DMA指令直接加载到LMEM中。
d=np.arange(60,65).reshape(1,5,1,1)
d=(
resize(d,(1,2*4,1,1)) #npu,eu_align
.reshape(1,2,4,1,1)
.transpose(2,0,3,4,1) #<4x1x1x1x2>
.resize(4,1,2,1,4)#EUalign<4x1x1x1x4>
)
e=np.concatenate((d.reshape(4,1,4),c.reshape(4,12,4)),axis=1)
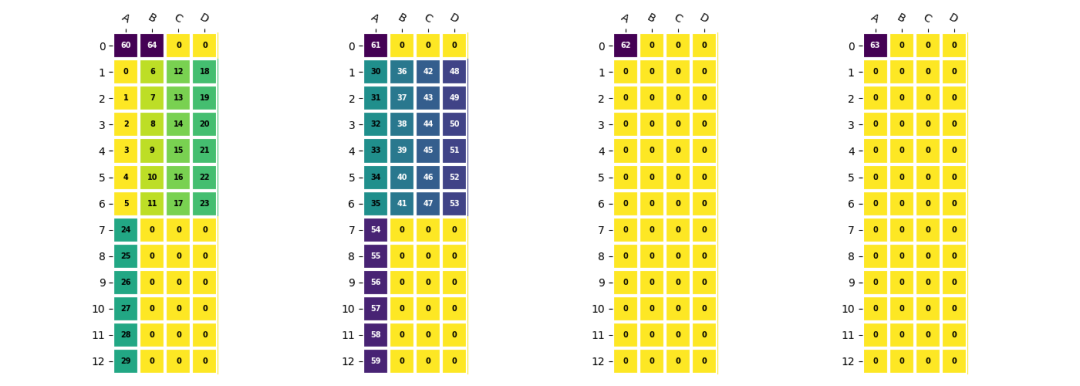 卷积权重和偏置合并后的形式
卷积权重和偏置合并后的形式
通过上述方法,我们可以有效地组织LMEM中的数据,以适应SOPHON BM1684X处理器的计算需求,从而提高整体的执行效率和性能。
-
处理器
+关注
关注
68文章
19281浏览量
229779 -
存储器
+关注
关注
38文章
7490浏览量
163817 -
编译
+关注
关注
0文章
657浏览量
32868
发布评论请先 登录
相关推荐
康谋分享 | 如何应对ADAS/AD海量数据处理挑战?

轻松学会单片机
从0开始,181页知识带你轻松搞定C++语言
如何处理好FPGA设计中跨时钟域间的数据
带你玩转RT-Thread,开发教程汇总(共13篇)
带你深入探索okio组件高效的奥秘
无法让SWO数据在MCUXpresso上高效工作怎么处理?
基于ARM处理器的高效异常处理解决方案

关于选择处理器的八个认知错误
Python数据清洗和预处理入门完整指南
labview处理excel数据中的粗大误差
盛显科技:拼接处理器如何实现高效数据拼接操作?






 工商网监
工商网监
评论