 基于Discrete Diffusion的模型不可知分割细化
基于Discrete Diffusion的模型不可知分割细化
这次这篇文章介绍一篇很有意思的工作:SegRefiner,来自 NeurIPS, 2023,目前代码已开源。
SegRefiner 提出一种新的的任务解释,将分割细化视为一个数据生成过程。因此,细化可以通过一系列去噪扩散步骤来实现,其中 Coarse Mask 是 Ground Truth 的噪声版本。此外,为了处理二值掩模,进一步设计了一种新颖的离散扩散过程,在该过程中,每个像素执行单向随机状态转换。所提出的过程可以在训练期间逐渐将 Ground Truth 转换为 Coarse Mask,并在推理期间使用 Coarse Mask 作为采样起点。换句话说,SegRefiner 将掩模细化任务表述为一个条件生成问题,其中输入图像(指原图)作为条件,用于迭代更新/细化 Coarse Mask 中的错误预测。
SegRefiner 是模型不可知的,因此适用于不同的分割模型和任务。SegRefiner 验证的任务包括:语义分割,实例分割和二分图像分割。
相关工作
分割细化的目标是提高现有分割模型中掩模的质量。一些工作专注于增强特定的分割模型。还有一些模型不可知方法的细化方法,这些策略强调使用多种形式的输入,包括整个图像、边界补丁和边缘条带等。尽管这些技术可以细化来自不同模型的粗糙掩模,但它们的适用性仍然局限于特定的分割任务。
扩散模型在检测和分割任务中的应用也成为越来越多研究的焦点,这些研究主要遵循 DDPM 的高斯扩散过程,并利用额外的图像编码器来提取图像特征作为生成掩模的条件。SegRefiner 是第一个将扩散模型应用于图像分割细化任务的工作,它还在基于扩散的分割任务中首次放弃连续的高斯假设,转而采用新设计的离散扩散过程。
Forward diffusion process
在介绍前向过程之前,先看一下整体框架的实现:
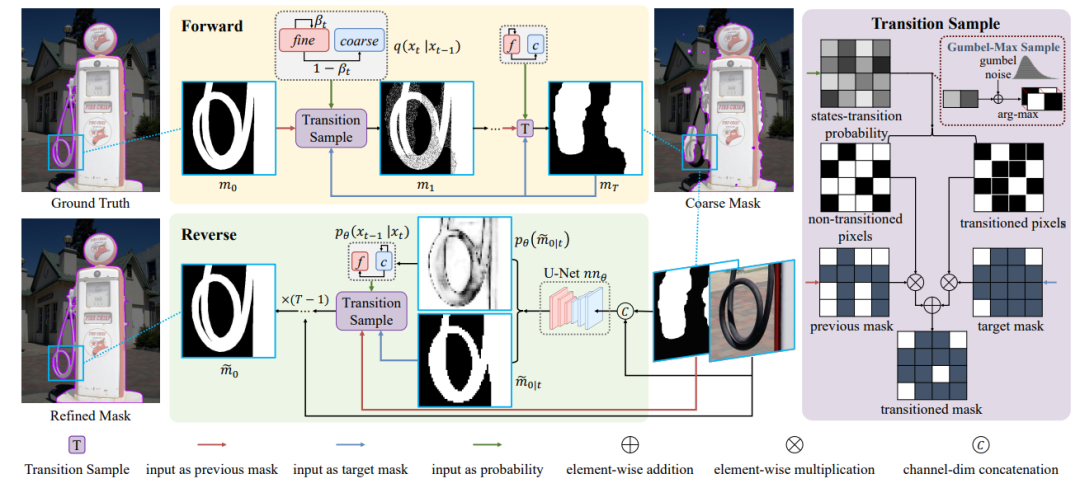 请添加图片描述
请添加图片描述
右侧是提出的 transition sample 模块,它基于输入状态转换概率从当前掩模中随机采样像素,并改变它们的值以匹配目标掩模中的值(也就是完成我们在引言中提到的“每个像素执行单向随机状态转换”)。看这张框架图的时候,注意区分不同 pipeline 的颜色区分,这里吐槽一下,我第一看 transition sample 没有清楚的看到三种输入。
在训练期间,转换样本模块将 Ground Truth 转换为 Coarse Mask,因此 Coarse Mask 是目标掩模。在推理过程中,目标掩模指的是预测的细致掩模,这个模块根据预测的细致掩模和转换概率在每个时间步中更新 Coarse Mask 中的值。
接下来仔细介绍下前向过程:
这种方法涉及将一个精细的 mask 逐渐转变为一个更粗糙的 mask,包含以下关键要素:
起始状态 (mo):与 ground truth 的精细 mask 相对应。
目标状态 (mr):一个粗糙的 mask。
中间状态 (mt):随着时间步 t 的增加,逐渐从 mo 向 mr 演变的中间状态。
转移采样模块
引入了“转移采样”模块,该模块负责根据当前 mask mt、粗 mask mr 以及状态转移概率来进行状态的转移。状态的转移是单向的,保证了最终会收敛到粗糙 mask mr。
重参数技巧
此外,SegRefiner 还提到了重参数技巧(reparameterization trick),通过引入二元随机变量 x 来描述这一过程。该过程允许直接获取任何中间时间步的 mask mt,而无需逐步采样。具体表述为:
定义 x 表示为一个 one-hot 向量,表示中间掩模 mt 中像素 (i, j) 的状态。
设置 xi = [1, 0] 和 xi = [0, 1] 分别表示精细状态和粗糙状态。
因此,前向过程可以表示为公式:
where
为超参数,而 对应了上述的状态转移概率。状态转移矩阵 的边缘分布可以表示为:
整体上还是遵循 DDPM,但是引入 二元随机变量 x 。
Reverse diffusion process
将粗糙 mask mr 逐渐修正为精细 mask mo。
由于此时精细 mask mo 和状态转移概率未知,对照着 SegRefiner 框架图来看,训练一个神经网络 来预测精细 ,表示为:
其中 I 是相应的图像。
和 分别表示预测的精细 mask 和其置信度分数。相应的, 可视作 中每个像素处于“精细状态”的概率。
反向状态转移概率
根据前向过程的设定和贝叶斯定理,延续 DDPM 的方法,我们可以由前向过程的后验概率和预测的 得到反向过程的概率分布,表示为:
where
其中 为反向过程的状态转移概率。
迭代修正过程
给定粗糙 mask mr 以及相应的图像 I,首先将所有像素初始化为粗糙状态 xi = [1, 0]。通过不断迭代地状态转移,逐渐修正 m_T 中的预测值。
推理过程
给定一个粗糙的掩模和其对应的图像,我们首先初始化所有像素为粗糙状态。我们在以下步骤之间迭代:
前向过程:以获取 和 。
计算反向状态转移矩阵: 并得到 。
计算精细化的掩模:基于 , 和 计算精细化的掩模 。
这个过程(1)-(3)迭代进行,直到获得精细的掩模。
实验
分别训练了 LR-SegRefiner 和 HR-SegRefiner,数据集和具体的 settings 在上 。
定性对比其他方法,觉得对比 U-Net 和 ISNet 的效果的确很明显。
总结
SegRefiner 是首个基于扩散的图像分割细化方法,采用了离散扩散过程。SegRefiner 执行模型不可知的分割细化,并在各种分割任务的细化中取得了强有力的实证结果。虽然它在准确度上取得了显著的提升,但其局限性在于扩散过程由于多步迭代策略而导致推理速度变慢。
-
开源
+关注
关注
3文章
3255浏览量
42410 -
模型
+关注
关注
1文章
3176浏览量
48721 -
代码
+关注
关注
30文章
4752浏览量
68360
原文标题:基于 Discrete Diffusion 的模型不可知分割细化
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于多级混合模型的图像分割方法

电磁屏蔽知识,必不可知!
关于宽禁带生态系统的仿真模型验证
基于Diffusion Probabilistic Model的医学图像分割
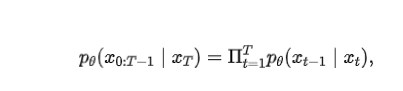
使用OpenVINO™在算力魔方上加速stable diffusion模型
近期分割大模型发展情况

优化 Stable Diffusion 在 GKE 上的启动体验
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了

CLE Diffusion:可控光照增强扩散模型






 工商网监
工商网监
评论