 一种基于PV变换和CNN模型生成BEV数据的方法
一种基于PV变换和CNN模型生成BEV数据的方法
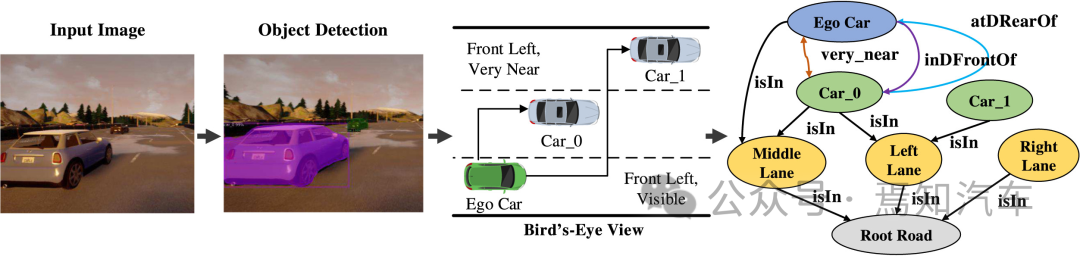
车载视觉终端数据提取可以生成一项有价值的信息,那就是检测捕获图像中的目标物体位置信息、方向信息以及与自车之间的距离信息,这样可以很好的预测自车以及周围物体未来的运动趋势,这些信息可以有效的聚合称一个自上而下的表示形式,也就是我们常说的BEV鸟瞰图,这样可以很好的为自动驾驶车辆导航提供除高精地图外的其他图层信息。
获取BEV图的经典图像处理方法是利用单应性矩阵Homograph对 RGB 图像进行变换,从而PV透视图投影转换到3D坐标系下的BEV视图。此类传统方法的基本原理都是需要利用提前计算的相机矩阵来实现单应阵的构造。然而,这样的方式适配性是交叉的,因为当相机的位置发生变化时,需要更新传输矩阵值重新构造对应的单应性矩阵Homograph,以确保新的转换的正确性。
然而,使用常规的几何变换会在某些场景下存在较大问题。比如,当构建环境目标时,一些车辆或行人目标由于遮挡而对自车不可见时,就会在图像变换时被自动忽略。而由于深度学习网络可以在一段时间内通过对移动目标在时间域上进行跟踪和学习。也就是哪怕在某一段短时间内看不到该目标,通过历史学习信息,也可模拟出当前时刻该目标的运动状态。
此算法架构主要包括几个模块。
为了解决这样的问题,本文介绍另一种适配性更强,适应范围更广的鸟瞰图定位构建方法。即采用深度学习方法从图像中提取重要信息进行透视变换,与经典方法相比,降低了相对于物体的方向和位置变化的敏感度,实现了更高的准确性和效率。当然,单应性变换的方法尚未被新方法完全取代,并且仍在一些算法中被研究使用。
实际上,这种基于深度学习的鸟瞰图生成方式是需要大量数据作为支撑的,因为只有训练的数据集够多,才能真正通过足够多的泛化模型来提升2D图像到3D状态下的BEV图层的准确性。
这里有比较典型的几种深度学习的方法实现相应的BEV制图功能:
1、基于卷积神经网络(CNN)实现BEV构图
考虑到 PV 与 BEV 相比完全位于不同的空间,尝试生成对抗网络 (GAN)、自动编码器 (AE) 以及授权Transformer和CNN来解决分组进行变换问题。这一系列先进的神经网络方法在生成BEV地图方面可以相当高效,因为基于对抗性学习来生成BEV地图,可以确保判别器具备较高精度。当然,应用几何学作为网络的附加属性来改变对抗神经网络的一些特征,也可以获得更好的性能。
2、利用AE、可变AE (VAE)的模型组合进行转换
以上架构的目的是提供一组有价值的信息,将图像通过编码信息映射到低维空间,这样可以以较少的信息很好的生成对应BEV地图表示。
3、利用Transformer生成BEV目标映射
有一些研究利用 Transformer(具有交叉注意力)通过构建查询并搜索相应的 BEV 图像来实现映射目标,以便通过注意力机制获得有益的特征。
4、利用视角间/帧间变换生成BEV目标映射
目前生成BEV的方法有很多种不同的方法,考虑视角间的方法主要是通过利用主流的7V(前视、周视、后视)摄像头实现360°覆盖,最终利用图像拼接直接生成BEV图。此外,使用视频序列图像中在时间序列上的帧间信息代替单个图像信息的处理,可以充分利用前序帧和后续帧中的信息获得更好的准确性能。
基于深度学习的BEV构图模型
本文介绍的方法是利用 PV 图像以及其中车辆边界框的位置为自车创建自上而下的环境表示。这样的图像无需采用360°环绕式摄像头模组进行,而是可以利用单前视2V。;当然有条件可以加上测前视实现4V。因为对于自动驾驶系统来说,除开变道这类特殊场景外,自车通常更关心自车前方的目标信息。然而有个比较棘手的问题是,如果是非多视角下的场景重构,单视角是无法实现从2D到3D的精确变换的,因为图像坐标到世界坐标下的P阵没法完整建立起来。所以对于BEV重建目标来说,如果想通过Mono3D的方式,则需要采用提前注入真值系统的方式实现对应的场景图重构。原理就是当识别场景后,需要与提前建立的真值系统匹配,从而分析现实场景下相应的真值。
当然,真值系统的建立是需我们如何从现实环境中收集大量此类数据,特别是因为它需要获得相应的 PV 图像的自上而下的表示。这里有必要首先解决可用于自动驾驶车辆领域的全面数据集收集方法。这种方法可以创建一个数据集,生成带有车辆边界框位置信息的PV图像,以及相应的BEV地图。其次,需要研究这种基于深度学习将PV图像转换为精确的BEV地图的方法,实际上是一种端到端深度学习架构。
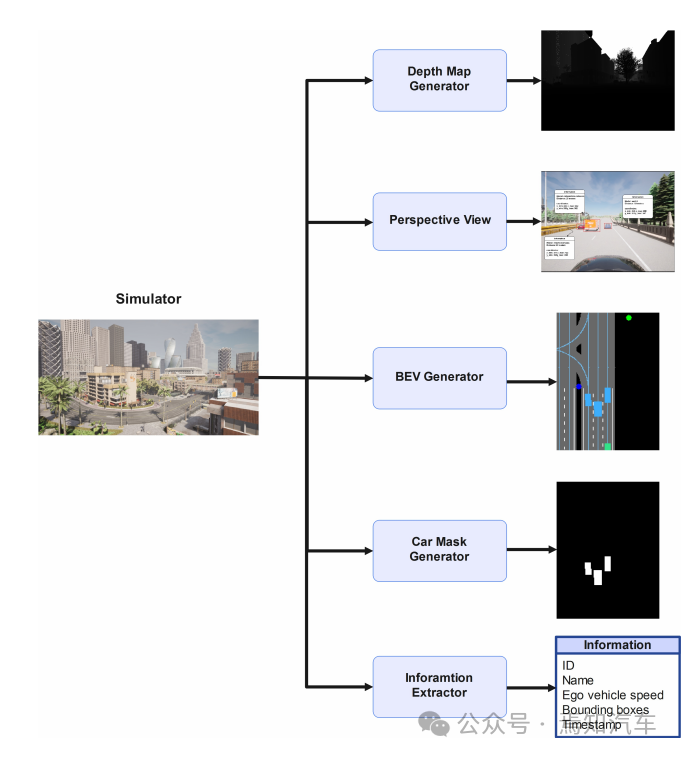
如下图表示本文介绍的这种端到端学习架构的处理方法。其中输入处理主要包括图像采集、输入图像分割、目标跟踪几个。其过程是负责收集输入,提取其关键特征,并将其转换为不同的特征空间供后续使用。输出处理通过区分横纵向分割特征模式,最终通过一定的聚合方法论生成最终BEV图中的边界框。
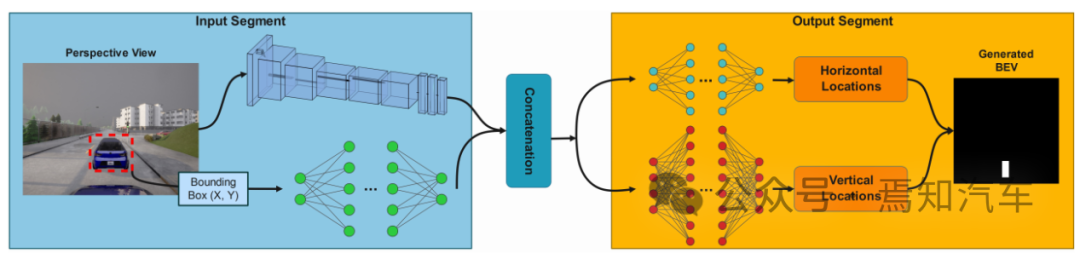
用于预测鸟瞰图的深度神经网络架构
1、输入处理:
该输入处理主要分两路进行数据处理。
特征提取分支:采用预先训练的主干模型来提取关键特征(如提取图像中ROI之间的位置信息、形状信息等)。然后将如上这些特征转化为特征向量,并对特征向量进行编码。由于提取的特征显着影响最终输出,因此对于主干网的选择将很大程度影响整体系统性能和准确性。这里的主干网络当前也有很多不同的选择,有较多的主流算法模型都可以提供较大的训练效率和灵活性。
边界绘制分支:通过多个完全链接的密集层,将如上特征提取的信息编码维特征向量。利用聚合向量的形式从上而下的定位选定的车辆目标,建立如上两个分支之间的关系,最终可以增强模型识别目标之间在空间关系的能力。
2、输出处理:
针对前序车辆目标边界框定位其水平和垂直轴位置,两种轴需要分别关注图像在其水平行方向和垂直列方向上的特征值。为了构建对应在水平和垂直方向上处理分支,需要利用多个完全链接的密集层,将前序特征输入到对应的两个分支中。由于前视摄像头观察到的车辆信息通常是相对本车垂直放置的,因此对于垂直方向需要生成的边界框更多,其对应的垂直值分布的方差也会更大。
以上水平和垂直位置分布最终通过聚合器脚本生成边界框。为了比较水平和垂直方向的预测值,需要利用均方误差(MSE)作为损失函数来进行模型优化,这样可以最大限度地减少这种损失。在终极框架中,将ReLU 激活函数应用于除输出层之外的所有层。而输出层则利用线性激活来促进像素坐标中的边界框预测。
Mono3D中的真值数据集获取
对于自动驾驶系统数据集的获取很少有包含街道图像的数据集空间、行人和车辆被公开发布,因为这些数据集多变且难以完整的重现。此外,还有些数据集还额外提供一些其他注释,例如针对不同对象的边界框以及各种类型的环境和天气条件下的语义分段地图作为附加信息。实际上,没有特定的真实数据集可以直接解决所有场景挖掘任务,研究人员需要在使用数据集之前构建预处理步骤、增加数据丢失的机会并减慢该过程。为了全方位泛化生成所有自动驾驶使用场景,同时降低实车数据采集的获取成本,就需要使用虚拟城市空间模拟器合成了一个全新的数据集。该模拟器复制了现实世界的物体和事件,在这种情况下,则可以通过PV图像很轻松的生成BEV图像。
由于深度学习模型需要大量数据,因此需要大量数据才能做出更准确的预测。在数据采样研究中,需要使用模拟器的巨大数据集来解决上述问题,同时生成更真实的图像。
1、数据集模拟器设置
为了使用模拟器生成的数据集,需要在地图的随机生成自车位置作为输出图像的起源,并且在数据捕获的每个epoch重复此过程,以便结果数据集将涵盖来自不同分布和环境的不同记录。
这些记录可以是如下一些内容:
- 道路信息、车道信息、路口信息;
- 建筑物、道路特征表面(如纹理信息、凹凸信息、坡度信息)等。
- 自定义白天天气条件。
- 不同的气候类别,如雨天,晴天和多云。
以上这些属性将使生成的数据集成为一个广义集,包含各种各样的情况,能够使模拟器尽可能真实的反应现实环境情况。在最终数据集中的每条记录中,以结构化的形式存储有关自车各种有价值的信息,如名称、目标id、位置和速度等。
2、传感器设置
对于这类数据采集的传感器需要在自动驾驶的车上暗转多个视觉传感器实现对周边环境信息的采集。首先,在车辆中部正前方平行于地面安装摄像头一个用于捕获原始RGB图像,该图像需要覆盖车辆引擎盖。其对应视频图像的属性经过调整可生成具有所需纵横比的 PV 图像,这些PV图像包括视场、输出图像尺寸以及相对于自车的相对位置。需要在智驾系统域控装置中设置对应的时间同步模块,能够保证时间能够与其他传感器同步。
此外,安装的深度相机传感器可以提供场景视图,编码每个像素到具有相同属性和位置的相机距离。因此 RGB 相机和深度传感器的输出完全匹配。
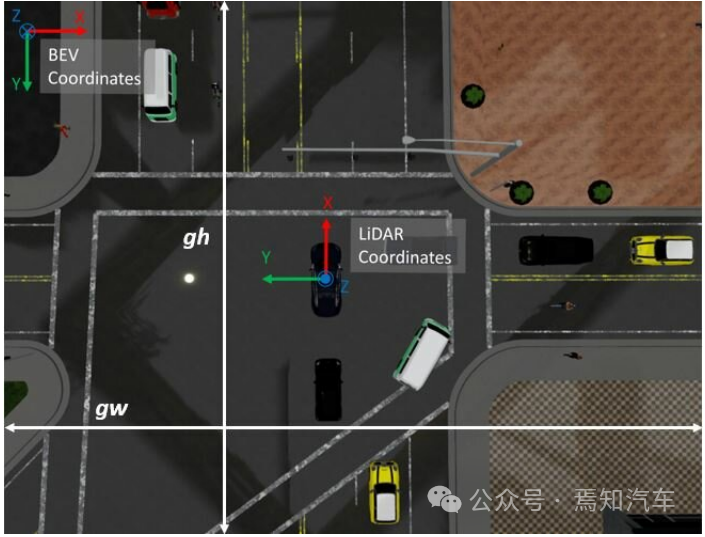
3、地图生成
本文介绍的BEV地图生成方法主要是基于数据集的注入后生成的端到端信息,这里需要建立一个BEV生成管道,该管道需要与PV透视图在宽高比上进行同步,其结果会以自车为中心生成自上而下的分段表示。同时,由于自车的运动状态是实时变化的,比如转弯、掉头、横纵破都会对自车采集的BEV地图产生不同的结果。因此,这就要求以自车定位在BEV中心和底部后,生成的BEV图必须具备能够旋转视图的能力。
4、数据采集
这里介绍的数据集采集是针对 6 个不同的图重复数据采集过程 6 次。且模拟器需要在每个采集过程中,提供随机选择不同种类的 100 辆环境目标车和恶20量自车,并在不同位置放置对应的车辆。为了尽可能减少碰撞,需要每辆车都具有低阶辅助驾驶功能。每辆自车都针对前面提到不同道路特征、天气特征、路口信息捕获 20 个连续帧的数据。存储过程需要进行一定程度的抽帧,以便降低帧率,确保在存储限制内满足不同环境组合情况的泛化能力。
5、数据标注
对于采集的原始数据集需要使用这里的模拟器工具箱对PV透视图和BEV地图进行感兴趣目标ROI标注。标注出与自车距离不大于50m的车辆,且对于潜在风险车辆可能是不可见的部分也会以边界框标注出来。
在数据采集过程的每次迭代中从上述传感器收集原始数据后,作者使用模拟器提供的工具在 PV 和 BEV 中注释每个车辆边界框。输出仅包含与自我车辆距离等于或小于 50 米的车辆。车辆的边界框是不可见的车辆 PV,但也发布了位于上述距离的车辆。存储每辆车在PV中的左上角和右下角的位置以及它们在BEV地图中的对应位置。使用模拟器提供的地图中的车辆位置来计算其他车辆相对于自我车辆的距离。
总结
为了训练深度神经网络将 RGB 相机捕获的透视 (PV) 图像转换为鸟瞰 (BEV) 地图,需要大量且多样化的数据集来增强模型在各种条件下的泛化性和性能。从现实环境中收集此类数据可能具有挑战性且成本高昂,特别是因为它需要对获得的 PV 图像做自上而下的表示。本文介绍了一种端到端深度学习架构,旨在将PV图像转换为精确的BEV地图。同时,提出一种使用模拟器创建一个数据集的方法,通过生成带有车辆边界框位置信息的PV图像,以及相应的BEV地图,可以适合特定需求的新数据收集,也可以应用于现场的类似任务。
审核编辑:汤梓红
-
相机
+关注
关注
4文章
1367浏览量
53884 -
模型
+关注
关注
1文章
3298浏览量
49179 -
车载视觉
+关注
关注
0文章
15浏览量
8754 -
自动驾驶
+关注
关注
784文章
13926浏览量
166948
原文标题:一种基于PV变换和CNN模型生成BEV数据的方法
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种基于路测数据的传播模型校正方法
一种新的软件测试模型—软件层次化模型
一种新的DEA公共权重生成方法
一种利用强化学习来设计mobile CNN模型的自动神经结构搜索方法
一种基于Mask R-CNN的人脸检测及分割方法

一种基于改进的DCGAN生成SAR图像的方法






 工商网监
工商网监
评论