 幻方量化发布了国内首个开源MoE大模型—DeepSeekMoE
幻方量化发布了国内首个开源MoE大模型—DeepSeekMoE
幻方量化旗下组织深度求索发布了国内首个开源 MoE 大模型 ——DeepSeekMoE,全新架构,免费商用。
今年 4 月,幻方量化发布公告称,公司将集中资源和力量,全力投身到服务于全人类共同利益的人工智能技术之中,成立新的独立研究组织,探索 AGI 的本质。幻方将这个新组织命名为 “深度求索 (DeepSeek)”。
DeepSeekMoE 的模型、代码、论文均已同步发布。
模型下载:https://huggingface.co/deepseek-ai
微调代码:https://github.com/deepseek-ai/DeepSeek-MoE
技术报告:https://github.com/deepseek-ai/DeepSeek-MoE/blob/main/DeepSeekMoE.pdf
据介绍,DeepSeekMoE 的多尺度(2B->16B->145B)模型效果均领先:
DeepSeekMoE-2B 可接近 MoE 模型的理论上限2B Dense 模型性能(即相同 Attention/FFN 参数配比的 2B Dense 模型),仅用了 17.5% 计算量
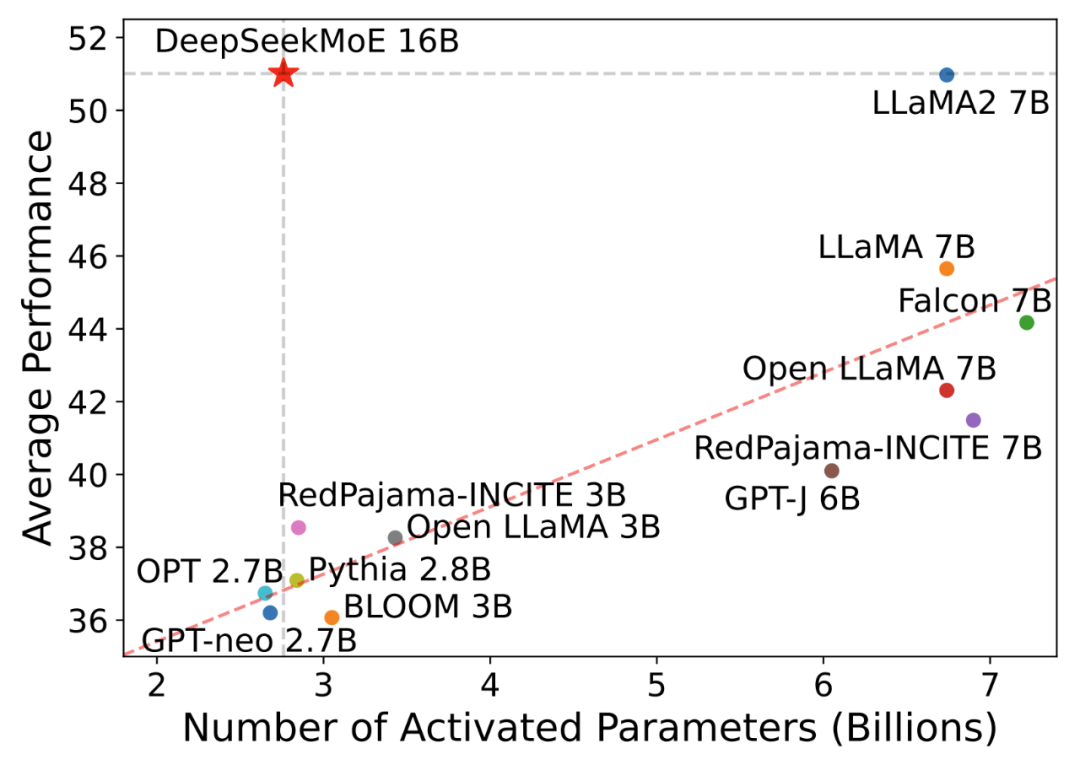
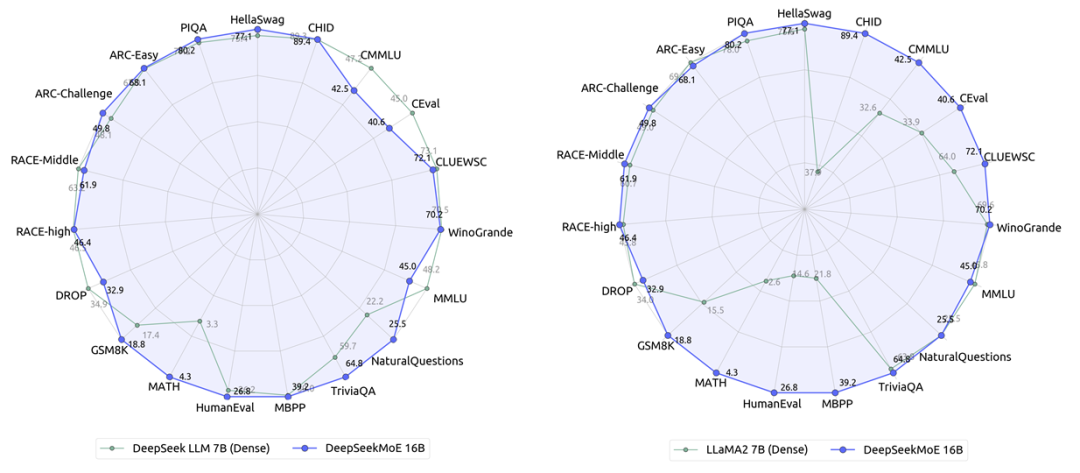
DeepSeekMoE-16B 性能比肩 LLaMA2 7B 的同时,仅用了 40% 计算量,也是本次主力开源模型,40G 显存可单卡部署
DeepSeekMoE-145B 上的早期实验进一步证明该 MoE 架构明显领先于 Google 的 MoE 架构 GShard,仅用 28.5%(甚至 18.2%)计算量即可匹配 67B Dense 模型的性能
混合专家模型 (Mixed Expert Models,简称 MoEs)是用于提高大语言模型效率和准确度的技术。这种方法的核心是将复杂任务划分为更小、更易管理的子任务,每个子任务由专门的小型模型或 “专家” 负责,然后根据输入数据的特性选择性地激活这些 “专家”。 MoE 核心组成:
专家 (Experts):训练有素的小型神经网络,擅长特定领域。每个专家通常专注于处理一种特定类型的数据或任务。专家的设计可以是多种形式,如完全连接的网络、卷积网络等。
门控机制 (Gating Mechanism):MoE 架构决策者,这是一个智能路由系统,负责决定哪些专家应该被激活来处理当前的输入数据。门控机制基于输入数据的特性,动态地将数据分配给不同的专家。
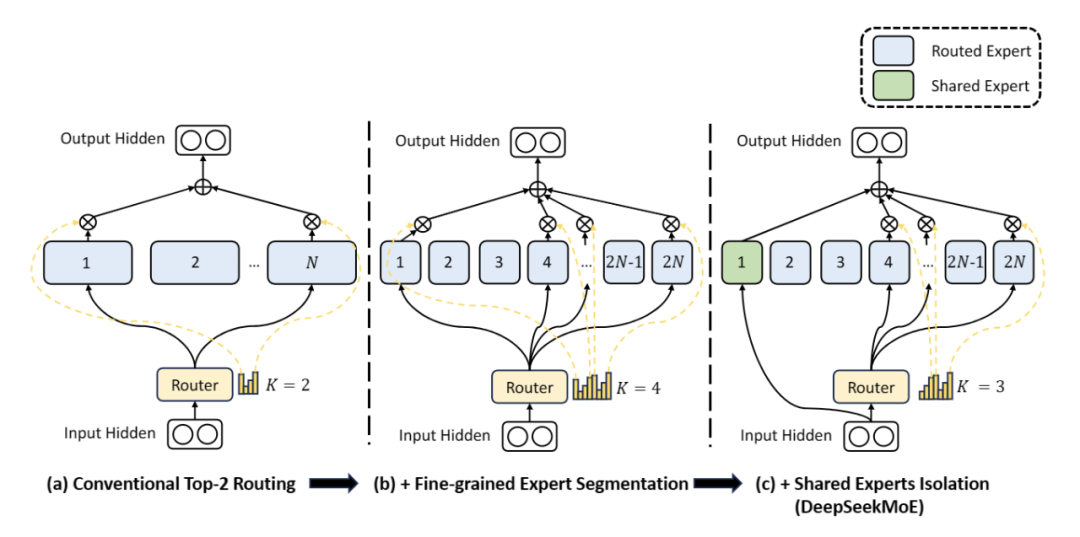
官方称 DeepSeekMoE 是自研的全新 MoE 框架,主要包含两大创新:
细粒度专家划分:不同于传统 MoE 直接从与标准 FFN 大小相同的 N 个专家里选择激活 K 个专家(如 Mistral 7B8 采取 8 个专家选 2 专家),DeepSeekMoE把 N 个专家粒度划分更细,在保证激活参数量不变的情况下,从 mN 个专家中选择激活 mK 个专家(如 DeepSeekMoE 16B 采取 64 个专家选 8 个专家),如此可以更加灵活地组合多个专家
共享专家分离:DeepSeekMoE 把激活专家区分为共享专家(Shared Expert)和独立路由专家(Routed Expert),此举有利于将共享和通用的知识压缩进公共参数,减少独立路由专家参数之间的知识冗余
审核编辑:刘清
-
神经网络
+关注
关注
42文章
4777浏览量
100997 -
智能路由
+关注
关注
0文章
9浏览量
7151 -
卷积网络
+关注
关注
0文章
42浏览量
2188
原文标题:幻方量化开源国内首个MoE大模型,全新架构、免费商用
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
猎户星空发布Orion-MoE 8×7B大模型及AI数据宝AirDS
腾讯发布开源MoE大语言模型Hunyuan-Large
全球首个开源AI标准正式发布
Meta发布Llama 3.2量化版模型
深开鸿联合深天使发布国内首个开源鸿蒙产业加速营

深开鸿联合中软国际、粤科金融集团发布国内首个开源鸿蒙创业投资基金
深开鸿联合深天使发布国内首个开源鸿蒙产业加速营

全球首个芯片设计开源大模型SemiKong正式发布
“燃鸿”重磅发布!国内首个燃气行业开源鸿蒙化智能产品及解决方案
昆仑万维开源2千亿稀疏大模型Skywork-MoE
浪潮信息发布“源2.0-M32”开源大模型
通义千问推出1100亿参数开源模型
思必驰参编,国内第一个“汽车大模型标准”正式发布






 工商网监
工商网监
评论