 数据中心AI芯片上升趋势能够持续多久呢?
数据中心AI芯片上升趋势能够持续多久呢?
有预测称,今年AI芯片可能会迎来强劲甚至迅猛的增长。然而,一个令人关注的问题是,这种上升趋势能够持续多久呢?
2023年底,AMD大胆地宣称,到2027年,数据中心AI芯片的总潜在市场(TAM)将达到4000亿美元,复合年增长率(CAGR)超过70%。这一预测引起了不同的反应,但也从侧面说明了大型语言模型(LLM)作为处理生成式人工智能(GenAI)应用核心的驱动力。
作为图形处理单元(GPU)市场的领导者,英伟达的成功证明了这些芯片的潜在市场规模。英伟达过去一年的股价上涨了217%,在过去三年增长了140%。
在最新的11月财报中,英伟达公布的营收为181.2亿美元,其中数据中心营收为145.1亿美元。整体销售额同比增长206%,而数据中心销售额同期增长了279%。所有这些都证实了数据中心芯片的销售正经历急剧上升的趋势。然而,关键问题是,这个增长趋势是否能够达到4000 亿美元的高度。
英伟达在数据中心AI GPU市场至少占据80%的份额,未来三年预计将迎来巨大增长。然而,要实现高达4000亿美元的市场规模,英伟达的表现需要比目前更出色,同时其他厂商也需要超出预期。
竞争者不甘示弱
AMD
AMD 认为其将在未来三年内实现大幅增长。2023 年 12 月,AMD发布了MI300 系列芯片,旨在在推理方面超越英伟达的GPU。同时发布的另一款产品AMD Instinct MI300A加速处理单元(APU),将CPU和GPU核心与内存集成在一个平台中。
MI300X 专为云提供商和企业设计,专为生成式 AI 应用而打造,MI300X GPU 拥有超过 1500 亿个晶体管,以 2.4 倍的内存超越了英伟达的 H100。峰值内存带宽达到 5.3 TB/s ,是H100 3.3 TB/s 的 1.6 倍。
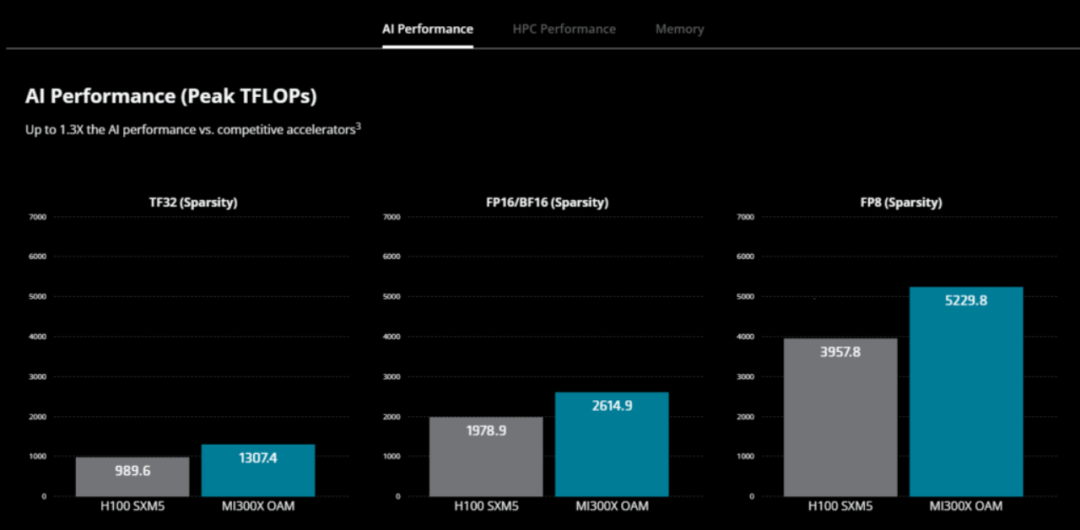
AMD Instinct MI300A APU 配备 128GB HBM3 内存。据称,与之前的 M250X 处理器相比,MI300A 在 HPC 和 AI 工作负载上的每瓦性能提高了 1.9 倍。
AMD 总裁兼首席执行官苏姿丰 (Lisa Su) 在去年 10 月的公司第三季度电话会议上表示:“随着 2024 年的到来,我们预计收入将持续增长,而且主要来源将是AI。”“在AI领域,我们的客户覆盖面很广,包括从超大规模企业到原始设备制造商、企业客户以及一些新的人工智能初创企业。从工作负载的角度来看,我们希望 MI300 能够同时处理训练和推理工作负载。”
英特尔上个月推出了AI芯片 Gaudi3 以及第五代 Xeon 处理器,作为进一步进军数据中心AI市场的一部分。
英特尔表示,Gaudi3 是专为深度学习和创建大规模生成人工智能模型而设计的下一代人工智能加速器,将与英伟达的 H100 和 AMD 的 MI300X 展开竞争。
英特尔声称Xeon 是唯一内置 AI 加速的主流数据中心处理器,全新第五代 Xeon 在多达 200 亿个参数的模型上提供高达 42% 的推理和微调能力。它也是唯一一款具有一致且不断改进的 MLPerf 训练和推理基准测试结果的 CPU。
Xeon的内置人工智能加速器,加上优化的软件和增强的遥测功能,可以为通信服务提供商、内容交付网络和包括零售、医疗保健和制造在内的广泛垂直市场实现更易于管理、更高效的高要求网络和边缘工作负载部署。
云厂商各显神通
AWS、谷歌等云厂商一直在为自己的大型数据中心打造定制芯片。一方面是不想过度依赖英伟达,另外针对自身需求定制芯片也有助于提高性能和降低成本。
AWS
亚马逊的AI芯片Trainium和Inferentia专为训练和运行大型人工智能模型而设计。
AWS Trainium2是 AWS 专门为超过 1000 亿个参数模型的深度学习训练打造的第二代机器学习 (ML) 加速器。AWS CEO Adam Selipsky 表示,近期推出的Trainium2的速度是其前身的4倍,能源效率是其之前的2倍。Tranium2 将在 AWS 云中由 16 个芯片组成的集群中的 EC Trn2 实例中使用,在 AWS 的 EC2 UltraCluster 产品中可扩展到多达 10万个芯片。AWS表示,10万个 Trainium 芯片可提供 65 exaflops 的计算能力,相当于每个芯片可提供 650 teraflops 的计算能力。
AWS Inferentia2 加速器与第一代相比在性能和功能方面实现了重大飞跃。Inferentia2 的吞吐量提高了 4 倍,延迟低至 1/10。
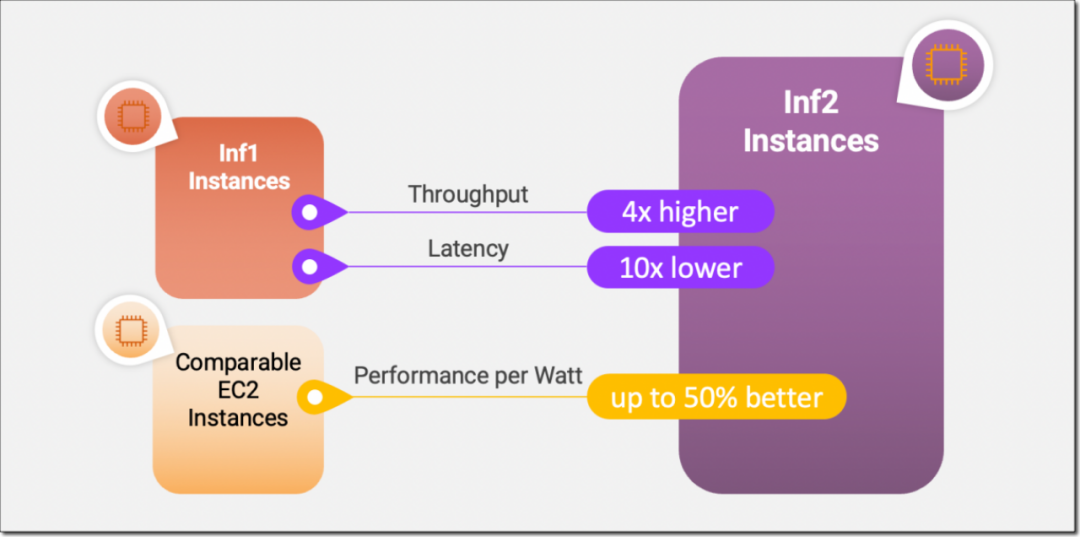
AWS Inferentia2 支持多种数据类型,包括 FP32、TF32、BF16、FP16 和 UINT8,还支持新的可配置 FP8 (cFP8) 数据类型,因为它减少了模型的内存占用和 I/O 要求。AWS Inferentia2 具有嵌入式通用数字信号处理器 (DSP),可实现动态执行,因此无需在主机上展开或执行控制流运算符。AWS Inferentia2 还支持动态输入形状,这对于输入张量大小未知的模型(例如处理文本的模型)至关重要。AWS Inferentia2 支持用 C++ 编写的自定义运算符。
谷歌
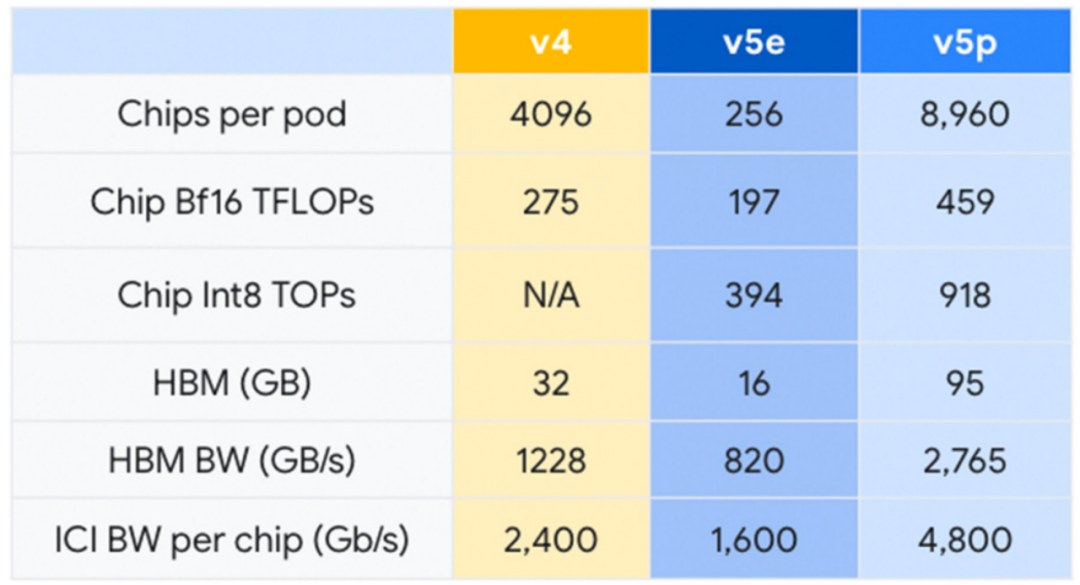
2023 年 12 月,谷歌发布最新的Cloud TPU v5p,并号称是迄今最强大的TPU。每个 TPU v5p Pod由 8,960 个芯片组成,采用 3D 环面拓扑,互连速度达 4,800 Gbps。与 TPU v4 相比,TPU v5p 的FLOPS 提高了 2 倍以上,高带宽内存 (HBM) 提高了 3 倍以上。
TPU v5p 专为性能、灵活性和规模而设计,训练大型 LLM 模型的速度比上一代 TPU v4 快 2.8 倍。此外,借助第二代SparseCores,TPU v5p训练嵌入密集模型的速度比 TPU v4 2快 1.9 倍。
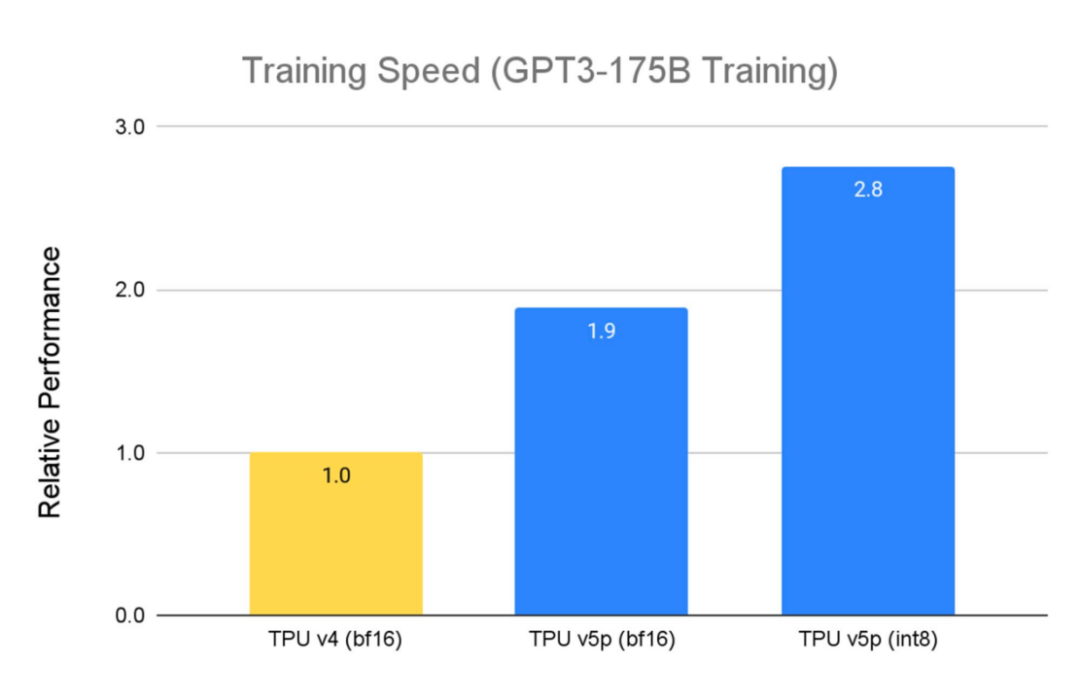
除了性能改进之外,TPU v5p 在每个 pod 的总可用 FLOP 方面的可扩展性也比 TPU v4 高 4 倍。与 TPU v4 相比,每秒浮点运算次数 (FLOPS) 加倍,并且单个 Pod 中的芯片数量加倍,可显著提高训练速度的相对性能。
微软
2023 年 11 月,微软推出了AI芯片Azure Maia 100。Maia 100 是 Maia AI 加速器系列中的首款产品。
Maia 采用 5 nm台积电工艺制造,拥有 1050 亿个晶体管,比 AMD MI300X AI GPU的 1530 亿个晶体管少约 30% 。微软表示,“Maia 支持我们首次实现低于 8 位数据类型(MX 数据类型),以便共同设计硬件和软件,这有助于我们支持更快的模型训练和推理时间。”
Maia 100 目前正在 GPT 3.5 Turbo 上进行测试,该模型也为 ChatGPT、Bing AI 工作负载和 GitHub Copilot 提供支持。微软正处于部署的早期阶段,还不愿意发布确切的 Maia 规范或性能基准。
总的来说,从AMD 4000亿美元市场的预测中至少可以得出三个结论:首先,数据中心仍是短期内AI芯片的焦点;其次,数据中心 AI芯片领域正急剧上升,尽管上升的幅度仍然是一个问题;第三, 英伟达将继续在该领域占据主导地位,但包括 AMD 在内的其他供应商正努力削弱其地位。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19274浏览量
229734 -
gpu
+关注
关注
28文章
4735浏览量
128914 -
晶体管
+关注
关注
77文章
9685浏览量
138127 -
HPC
+关注
关注
0文章
316浏览量
23763 -
AI芯片
+关注
关注
17文章
1884浏览量
35005
原文标题:数据中心AI芯片市场有多大?
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI与数据中心驱动下 芯片电感的技术革命

AmpereOne如何满足现代数据中心需求
Meta AI数据中心网络用了哪家的芯片
AI数据中心的能源危机,需要更高效的PSU
当今数据中心新技术趋势
数据中心的AI时代转型:挑战与机遇

AI时代,我们需要怎样的数据中心?AI重新定义数据中心

HNS 2024:星河AI数据中心网络,赋AI时代新动能

苹果正在开发用于数据中心的AI芯片
苹果正在研发全新数据中心AI芯片
苹果自研数据中心AI芯片

数据中心存储的趋势
英飞凌推出高密度功率模块,为AI数据中心降本增效
让数字世界坚定运行 | 华为发布2024数据中心能源十大趋势






 工商网监
工商网监
评论