 LLM推理加速新范式!推测解码(Speculative Decoding)最新综述
LLM推理加速新范式!推测解码(Speculative Decoding)最新综述
1. Background
近年来,随着LLM (Large Language Model) 规模的逐渐增大(200M->7B->175B),LLM的推理加速技术正逐步引起NLP学界的广泛关注。尤其是像ChatGPT[1],Bard[2]这种线上实时交互的应用,LLM的inference latency(推理耗时)极大程度地影响了用户的使用体验。那么,LLM的Latency主要来自哪里呢?
相关研究表明,LLM推理主要是受内存带宽限制的(memory-bandwidth bound)[3][4]-- LLM每个解码步所用的推理时间大部分并不是用于模型的前向计算,而是消耗在了将LLM巨量的参数从GPU显存(High-Bandwidth Memory,HBM)迁移到高速缓存(cache)上(以进行运算操作)。也就是说,LLM推理下的GPU并不是一个合格的打工人:他把每天大多数的时间都耗费在了早晚高峰堵车上,在公司没干啥实事儿(可不就是我摸鱼仙人:P)。
这个问题随着LLM规模的增大愈发严重。并且,如下左图所示,目前LLM常用的自回归解码(autoregressive decoding)在每个解码步只能生成一个token。这导致GPU计算资源利用率低下(->每个token的生成都需要重复读写LLM的巨量参数),并且序列的生成时间随着序列长度的增加而线性增加。
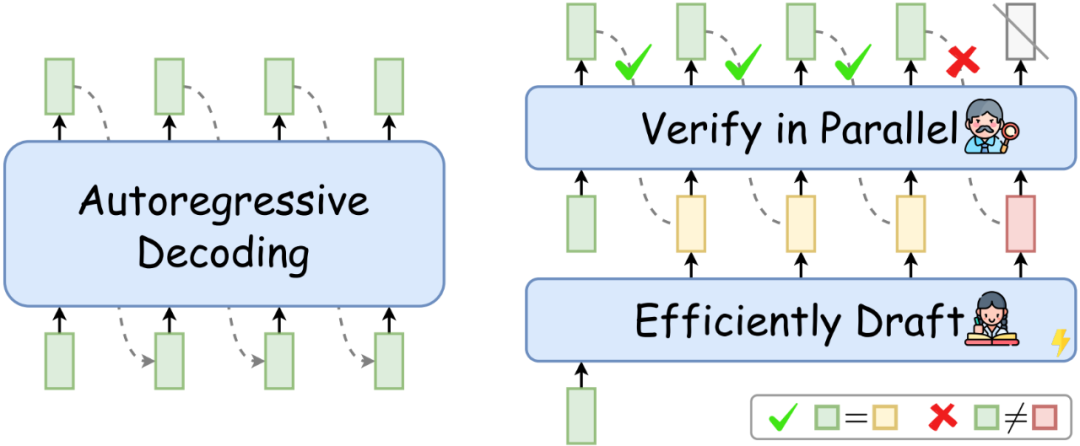
图1: 自回归解码(左),推测解码(右)
2. Speculative Decoding
那么,如何更好地利用GPU资源,让它成为一个合格的打工人呢?相信大家心里已经有答案了:把公司当作家,减少通勤次数,就可以少摸鱼多打工了(泪目)。
推测解码(Speculative Decoding),作为2023年新兴的一项LLM推理加速技术,正是提出了一种类似的解决方案:通过增加每个解码步LLM计算的并行性,减少总的解码步数(即减少了LLM参数的反复读写),从而实现推理加速。
如上右图所示,在每个解码步,推测解码首先高效地“推测”target LLM(待加速的LLM)未来多个解码步可能生成的token,然后再用target LLM同时验证这些token。通过验证的token作为当前解码步的解码结果。如果“推测”足够准确,推测解码就可以在单个解码步并行生成多个token,从而实现LLM推理加速。并且,使用target LLM的验证过程可以在理论上保证解码结果和target LLM自回归解码结果的完全一致[5][6]。
也就是说,推测解码在实现对target LLM推理加速的同时,不损失LLM的解码质量。这种优异的性质导致推测解码受到了学界和工业界的广泛关注,从2023年初至今涌现了许多优秀的研究工作和工程项目(如Assisted Generation[7],Medusa[8],Lookahead Decoding[9]等等)。
考虑到推测解码领域2023年以来飞速的研究进展,我们撰写了一篇系统性的survey,给出推测解码的统一定义和通用算法,详细介绍了推测解码研究思路的演化,并对目前已有的研究工作进行了分类梳理。在下文中,我们将文章内容凝练为太长不看版——分享一些关于推测解码关键要素的看法,以及目前常用的研究思路,欢迎感兴趣的小伙伴一起讨论~
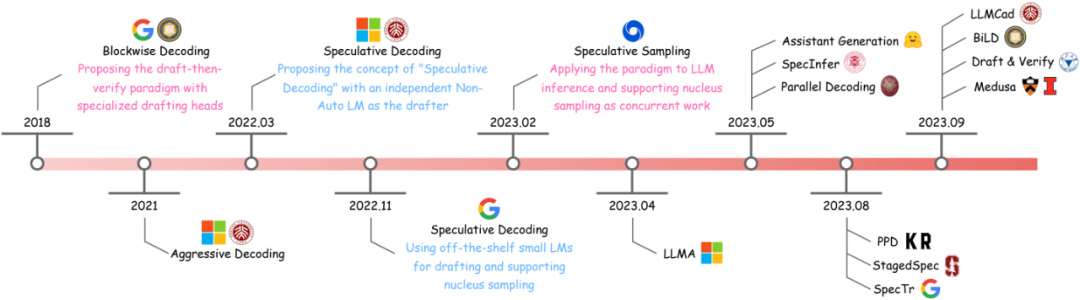
图2: 推测解码研究思路的演化
3. Key Facets of Speculative Decoding
首先,我们总结推测解码的定义:
推测解码是一种“先推测后验证” (Draft-then-Verify) 的解码算法:在每个解码步,该算法首先高效地“推测”target LLM未来多个解码步的结果,然后用target LLM同时进行验证,以加速推理。
也就是说,所有符合在每个解码步“高效推测->并行验证“模式的推理算法,都可以称为是推测解码(或其变体)。推测解码实现加速的关键要素,主要在于如下三点:
相比于生成单一token,LLM并行计算额外引入的latency很小,甚至可以忽略;
“推测”的高效性&准确性:如何又快又准地“推测”LLM未来多个解码步的生成结果;
“验证“策略的选择:如何在确保质量的同时,让尽可能多的“推测”token通过验证,提高解码并行性。
如上文所述,LLM推理的主要latency瓶颈在于推理过程中参数的反复读写。在只考虑一个解码步的情况下,decoder-only LLM的forward latency主要和decoder层数有关——层数越深,推理时间越长。相比于这两者,LLM运算并行性带来的额外latency很小,这一点在非自回归解码的多个相关工作中有所讨论[10][11]。
因此,推测解码的算法设计主要考虑如下两点:“推测”(Drafting)的高效性和准确性,以及“验证“策略(Verification)的选择:
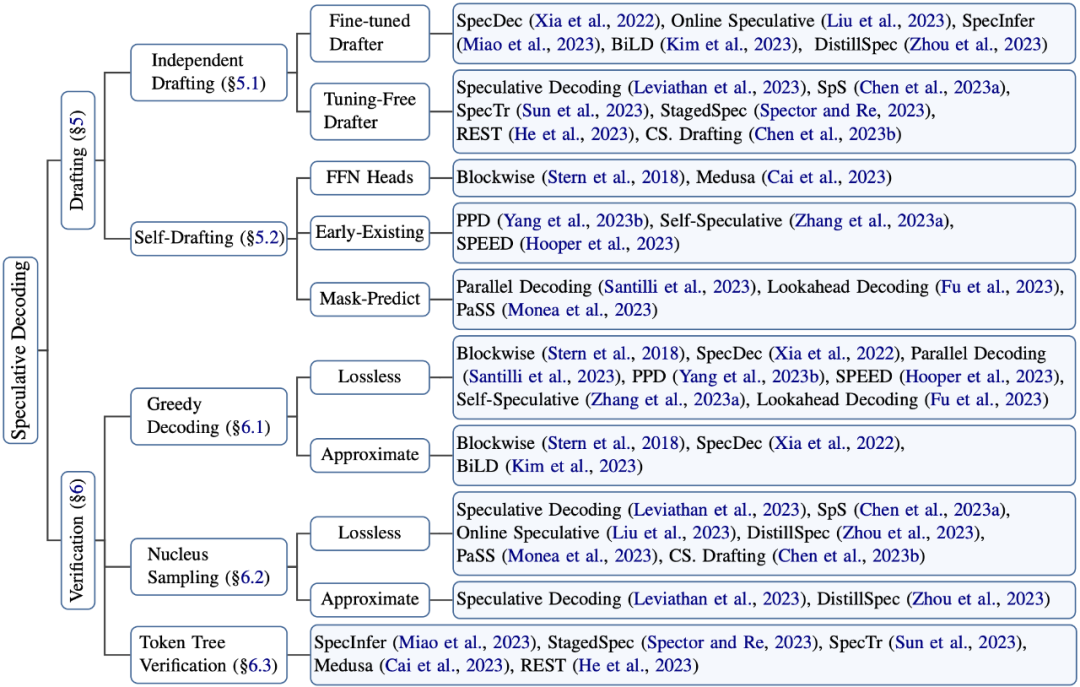
图3: 推测解码相关研究的归纳分类
4. “推测”的高效性和准确性
“推测“阶段(Drafting)的目的是精准地“预测”LLM未来多个解码步的生成结果,且不引入过多的latency。
因此,“推测”阶段的设计聚焦在“推测精度(accuracy)”和“推测耗时(latency)“的权衡上。一般来说,用以推测的模型越大,推测精度越高(即通过验证的token越多),但是推测阶段的耗时越大。如何在这两者之间达到权衡,使得推测解码总的加速比较高,是推测阶段主要关注的问题。
4.1 Independent Drafting
最简单的Drafting思路是,拿一个跟target LLM同系列的smaller LM进行“推测”[12][13]。比如OPT-70B的加速可以用OPT-125M进行推测,T5-XXL可以用T5-small。这样的好处是可以直接利用现有的模型资源,无需进行额外的训练。而且,由于同系列的模型使用相近的模型结构、分词方法、训练语料和训练流程,小模型本身就存在一定的和target LLM之间的“行为相似性“(behavior alignment),适合用来作为高效的“推测“模型。
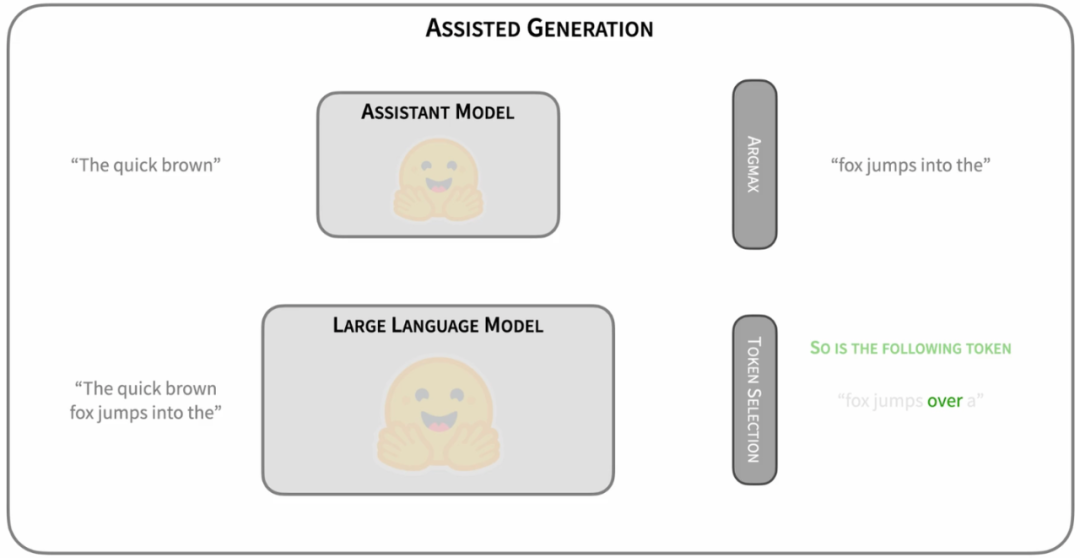
图4: https://huggingface.co/blog/assisted-generation
这一思路由Google和Deepmind同时提出[12][13]。作为Speculative Decoding的早期探索,这种“推测”思路易于实践和部署。并且,这两篇工作同时在理论上证明了推测解码不仅支持greedy decoding,还支持nucleus sampling的无损加速(我们下文会讲到)。这两种解码策略涵盖了LLM应用的大多数场景。因此,这两篇工作极大地促进推测解码在LLM推理加速中的应用,吸引了工业界和学术界的大量关注。
然而,同系列小模型的“推测”精度还有提升空间吗?
显然是有的。最直接的思路,就是去增强小模型和大模型之间的“行为相似性”(behavior alignment),让小模型模仿得“更像”一些。目前在这方面的研究进展集中在知识蒸馏(knowledge distillation)上:将target LLM作为教师模型,小模型作为学生模型,通过知识蒸馏让小模型更加趋向于target LLM的预测行为[14][15]。并且,知识蒸馏还可以有效地增强小模型的生成质量,通过减少低级的预测错误,增加通过验证的token数量。
4.2 Self-Drafting
然而,采用一个独立的“推测”模型也有缺点:
首先,并不是所有的LLM都能找到现成的小模型,比如LLaMA-7B。重新训练一个小模型需要较多的额外投入。
另外,引入一个额外的小模型增加了推理过程的计算复杂度,尤其不利于分布式部署场景。
因此,相关研究工作提出利用target LLM自己进行“高效推测”。比如Blockwise Decoding[5]和Medusa[8]在target LLM最后一层decoder layer之上引入了多个额外的FFN Heads(如下所示),使得模型可以在每个解码步并行生成多个token,作为“推测”结果。
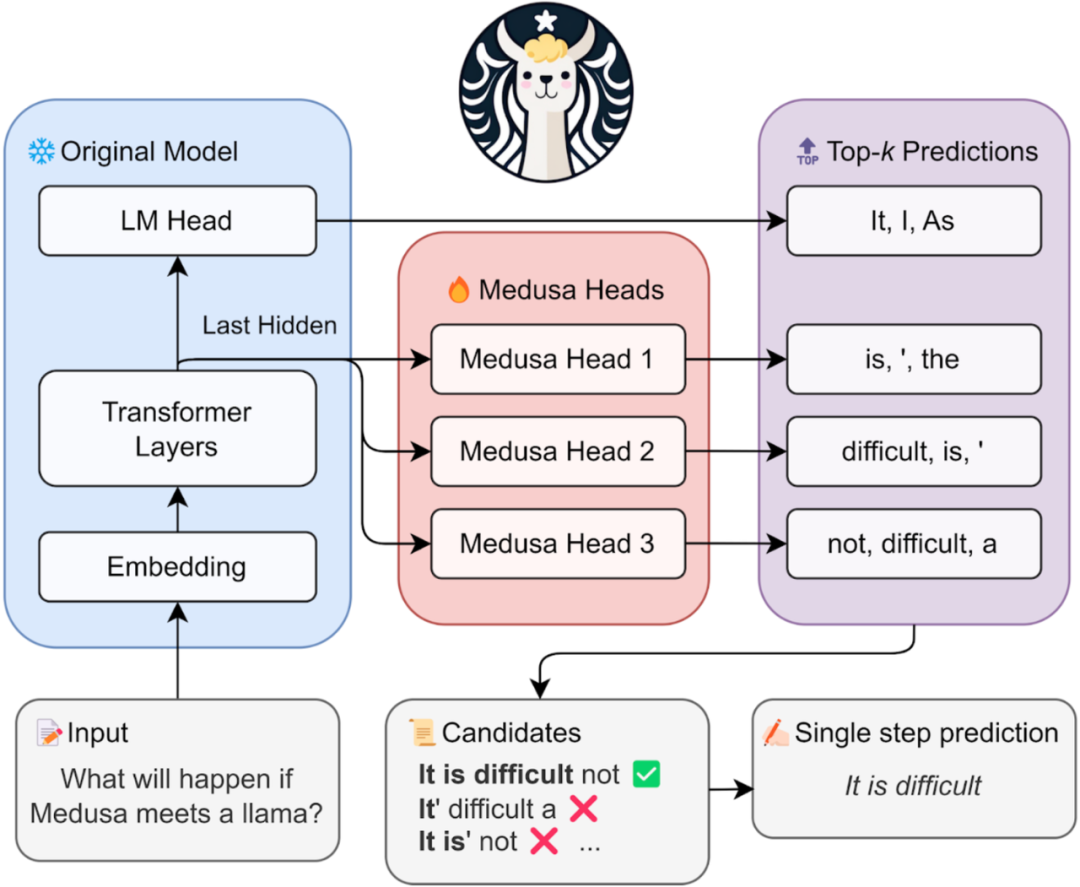
图5: https://sites.google.com/view/medusa-llm
然而,这些FFN Heads依然需要进行额外的训练。除了这两个工作,还有一些研究提出利用Early-Existing或者Layer-Skipping来进行“高效推测“[16][17],甚至仅仅是在模型输入的最后插入多个[PAD] token,从而实现并行的“推测”[18]。然而,“部署的便捷性”和“推测精度”之间依然存在一定的权衡关系。如何选择合适的“推测”策略,达到令人满意的加速效果,就见仁见智了。
感兴趣的友友可以移步具体论文查看细节,我们后续也准备提供一个公平的加速评测,给大家提供一个参考~
5. 验证策略的选择
“验证“阶段(Verification)的首要目的是保证解码结果的质量。
让我们重新回顾推测解码的验证过程:
如下图所示,在给定“草稿”(即推测结果)时,LLM的并行验证其实和训练阶段teacher-forcing的形式是一致的——在生成每个token时,都假设LLM的前缀输入是正确的。比如,在验证第三个“推测”token时,LLM以绿色前缀和两个黄色的"推测“token作为前缀输入。以贪婪解码(greedy decoding)为例,以该前缀作为输入时,LLM会自己生成一个概率最大的token。如果这个token(绿色)和第三个“推测”token相同,就说明第三个“推测”token通过了“验证”——这个token本来就是LLM自己会生成的结果。
因此,第一个没有通过验证的“推测”token (图中的红色token)后续的“推测”token都将被丢弃。因为这个红色token不是LLM自己会生成的结果,那么前缀正确性假设就被打破,这些后续token的验证都无法保证前缀输入是“正确”的了。
图6:recap of Speculative Decoding
由此可见,推测解码是可以保证最终解码结果和target LLM原先的贪婪解码结果完全一致的。因此,贪婪解码经常被用于推测解码的demo展示[8],用以清晰直观地表示推测解码在保持和target LLM解码结果等同的前提下,实现了数倍的推理加速。
然而,严格要求和target LLM解码结果完全匹配(exact-match)是最好的策略吗?
显然,并不是所有概率最大的token都是最合适的解码结果(比如beam search)。当推测模型的性能较好时,严格要求和target LLM结果匹配会导致大量高质量的“推测”token被丢弃,仅仅是因为它们和target LLM top-1解码结果不一致。这导致通过验证的“推测”token数量较小,从而影响推测解码的加速比。
因此,有一些工作提出可以适当地放松“验证”要求,使得更多高质量的“推测”token被接受,增大每个解码步通过验证的“推测”token数量,进一步提升加速比[12][14][15]。
除了支持贪婪解码,推测解码还可以在理论上保障和target LLM nucleus sampling的分布相同[12][13],具体证明感兴趣的朋友可以查看相关paper~。另外,相比于只验证单一的“推测”序列,相关研究还提出可以让target LLM并行验证多条“推测”序列,从而进一步增大通过验证的“推测”token数量[19]。
6. 总结
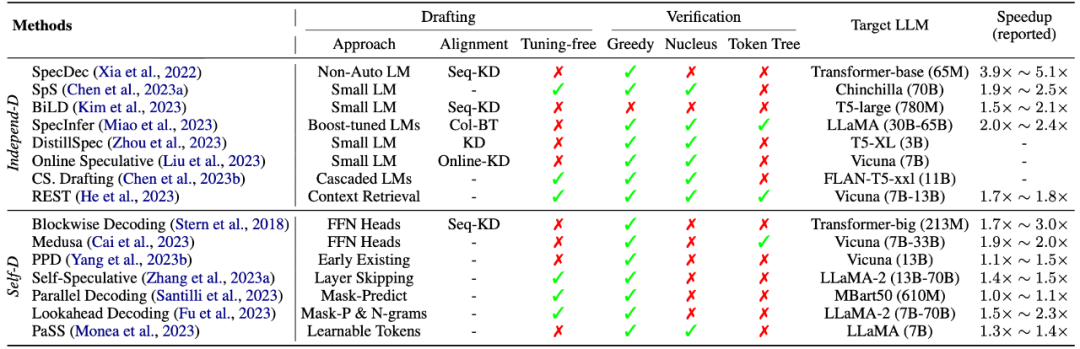
表1: 推测解码算法总结
在上表中,我们给出目前常用的推测解码算法的总结~。作为一种新兴的推理加速算法,推测解码在实现对target LLM推理加速的同时保障了解码结果的质量,具有广阔的应用前景和极大的科研潜力,个人比较看好~。然而,推测解码研究本身也存在许多尚未解答的问题,比如如何更好地实现target LLM和“推测”模型之间的行为对齐、如何结合具体任务的特点设计相应的推测解码策略(比如多模态模型加速),都是值得思考的问题。
-
解码
+关注
关注
0文章
180浏览量
27359 -
模型
+关注
关注
1文章
3158浏览量
48700 -
LLM
+关注
关注
0文章
272浏览量
304
原文标题:LLM推理加速新范式!推测解码(Speculative Decoding)最新综述
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
对比解码在LLM上的应用
【飞凌嵌入式OK3576-C开发板体验】rkllm板端推理
压缩模型会加速推理吗?
基准数据集(CORR2CAUSE)如何测试大语言模型(LLM)的纯因果推理能力
特斯拉前AI总监Andrej Karpathy:大模型有内存限制,这个妙招挺好用!
mlc-llm对大模型推理的流程及优化方案
周四研讨会预告 | 注册报名 NVIDIA AI Inference Day - 大模型推理线上研讨会
FlashAttenion-V3: Flash Decoding详解
Hugging Face LLM部署大语言模型到亚马逊云科技Amazon SageMaker推理示例

基于LLM的表格数据的大模型推理综述

自然语言处理应用LLM推理优化综述

LLM大模型推理加速的关键技术
高效大模型的推理综述






 工商网监
工商网监
评论