 为什么GD32F303代码运行在flash比sram更快?
为什么GD32F303代码运行在flash比sram更快?

我们知道一般MCU的flash有等待周期,随主频提升需要插入flash读取的等待周期,以stm32f103为例,主频在72M时需要插入2个等待周期,故而代码效率无法达到最大时钟频率。

所以STM32F103将代码加载到sram运行速度更快。
但使用GD32F303时将代码加载到SRAM后速度反而下降了一些,这是为什么呢?
我们前面了解过GD32F303 flash的code area区是零等待的,GD32F系列MCU片上Flash中Code区和Data区使用解密
零等待访问理论上就应该和在sram运行速度一样,那么为何会比sram更快一些呢?
通过查阅GD32F303用户手册系统架构章节我们可以知道,访问flash时可以直接通过ibus和sbus专用总线进行访问,而访问sram时通过AHB主机接口通过System BUS进行访问,AHB主机接口下更还有挂载有其他主机和外设总线,共享总线带宽。
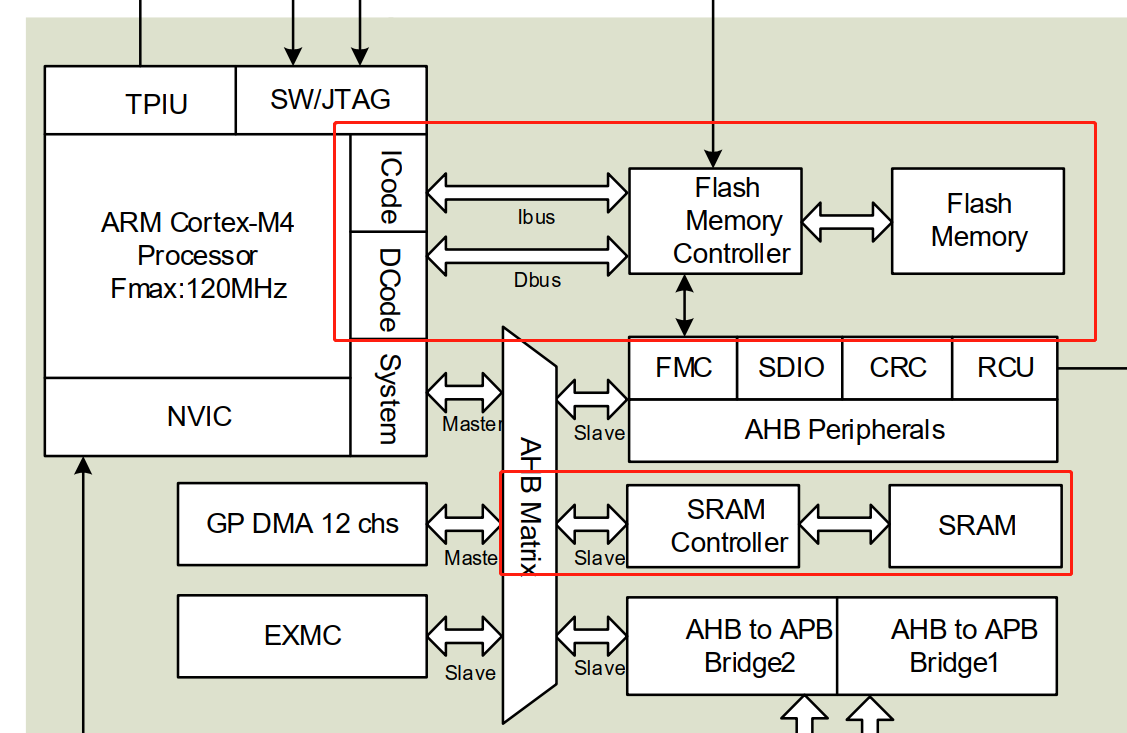
所以GD32F303的代码运行在code area零等待区时,效率会比常规加载sram的方式更高。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
单片机
+关注
关注
6078文章
45624浏览量
675096 -
嵌入式
+关注
关注
5212文章
20746浏览量
338441 -
sram
+关注
关注
6文章
843浏览量
117768 -
GD32
+关注
关注
7文章
435浏览量
27692
发布评论请先 登录
相关推荐
热点推荐


【GD32F303】星空派介绍
GD32官方资料的基础上,提供GD32F303的库函数开发资料、例程讲解、视频课程等。同时还提供RT-Thread相关的驱动开发、应用开发、移植等相关例程。(1)提供20多个基于GD官方标准库的
发表于 09-11 17:55
星空派GD32F303开发板的相关资料下载
一、开发板介绍星空派(GD)开发板是由旗点科技推出的一款GD32开发板,板载GD32F303ZET6芯片,支持RT-Thread操作系统等,支持WiFi、4G、loRa等物联通信接口。板载Fl
发表于 12-10 08:27
在GD32f303工程里使用独立看门狗
在使用rt-thread studio建立GD32f303工程(使用board里面的f303代码模板)。建立完毕后,使用Fwdt(独立看门狗)的时候,在库文件里面缺少
发表于 07-05 11:22
AN029 GD32F103程序在GD32F303和GD32F403芯片上运行DSP
AN029 GD32F103程序在GD32F303和GD32F403芯片上运行DSP
发表于 02-27 18:33
•0次下载

GD32F303固件库开发
/qq_24312945/article/details/124325797] GD32F303固件库开发(2)----读保护与写保护 芯片读保护以后,flash将不可以从外部读取,这样可以防止别人读取或者盗取芯片代码,如果想再

STM32CUBEMX开发GD32F303(17)----内部Flash读写
本章STM32CUBEMX配置STM32F103,并且在GD32F303中进行开发,同时通过开发板内进行验证。
本例程主要讲解如何对芯片自带Flash进行读写,用芯片内部Flash可

GD32F303为什么启动慢?
在MCU开发中,有一项非常重要的参数——MCU启动时间,即MCU上电后到程序开始运行这段时间。我们来看下GD32F303的datasheet中对启动时间的描述:
【GD32F303红枫派开发板使用手册】第五讲 FMC-片内Flash擦写读实验
MC即Flash控制器,其提供了片上Flash操作所需要的所有功能,在GD32F303系列MCU中,Flash前256K字节空间内, CPU执行指令零等待,具有相同主频下最快的
【GD32F303红枫派开发板使用手册】第二十讲 SPI-SPI NAND FLASH读写实验
通过本实验主要学习以下内容:
•SPI通信协议,参考19.2.1东方红开发板使用手册
•GD32F303 SPI操作方式,参考19.2.2东方红开发板使用手册
•NAND FLASH基本原理
•SPI NAND介绍
•使用GD32F
【GD32 MCU 移植教程】2、从 GD32F303 移植到 GD32F503
GD32E503 系列是 GD 推出的 Cortex_M33 系列产品,该系列资源上与 GD32F303 兼容度非常高,本应用笔记旨在帮助您快速将应用程序从 GD32F303 系列微控



评论