 单芯片没有神经网络加速器NPU可以玩微型AI应用吗?
单芯片没有神经网络加速器NPU可以玩微型AI应用吗?
讲到AI相信大家第一时间多半是联想到大型语言模型(LLM)和生成式AI(genAI, AIGC)应用,可以对话聊天、查询数据、生成文章图像和音乐,而这些应用多半需要用到极大的云端算力才能完成。
对于微型AI应用,如语音唤醒(语音命令)、异常侦测(振动、异音、环境传感器)、运动侦测(手势、跌倒)、影像分类、影像对象侦测、影像姿态侦测(全身、手指)等,通常可利用单芯片(MCU)或微处理器(MPU)配合较小的AI模型就有机会办到边缘(离网)就完成推论工作。
在之前的文章中提到,AI推论主要都是在进行巨量的矩阵乘加运算(MAC),就是「a×b+c」。而加速计算方式可使用「提高工作频率速度」、「平行/向量指令集加速」、「多核心加速」、「NPU神经网络加速器」等硬件加速作法。
而一般单芯片在单核CPU的情况下,最容易达成的作法就是前两项,而本文将从「平行/向量指令集加速」的角度来为大家说明如何在没有神经网络加速器NPU时也能顺利玩微型AI应用。
1. Arm精简指令集的演进
目前市售32bit单芯片大约有八到九成都是使用Arm Cortex-M系列硅IP)完成的,不同系列分别对应到不同的指令集(ARMv6-M~v8.1-M),而「-M」就是指将该版本指令集浓缩后专门提供给单芯片使用的。相关指令集对应的IP如下所示。
ARMv6-M: Cortex M0(2009) / M0+(2012) /M1(2007)
ARMv7-M: Cortex M3(2004)
ARMv7E-M: Cortex M4(2010) / M7(2014)
ARMv8-M Baseline: Cortex M23(2016)
ARMv8-M Marnline: Cortex M33(2016) /M35P(2018)
ARMv8.1-M: Cortex M55(2020) / M85(2022) /M52(2023)
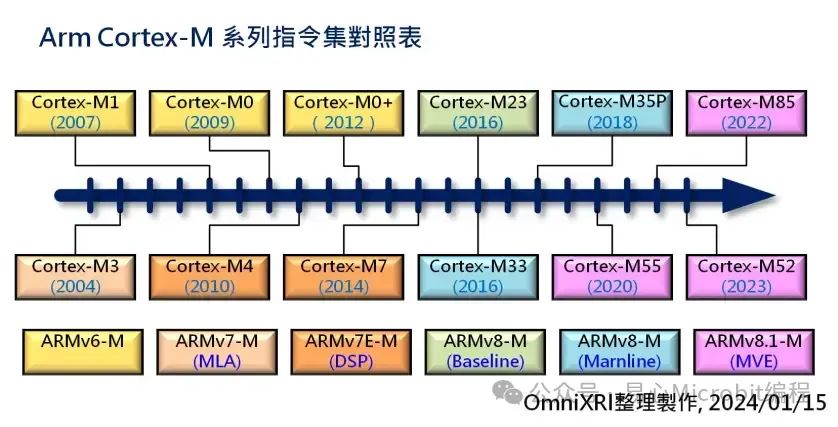
Fig. 1 Arm Cortex-M 系列指令集对照表。
2. Cortex-M指令如何加速计算
其中「v7-M」指令集就开始支持单频率乘加指令MLA,即将原来需要二道指令MUL, ADD分别计算乘法和加法变成一道指令,如此就能将计算速度提升两倍。到了「v7E-M」DSP扩展指令集时开始支持单指令多数据流(Single Instruction Multiple Data, SIMD),如QADD,QADD16, QADD8等,可将32bit分拆成2个16bit或4个8bit数据一起计算,如此就能增加2~4倍计算速度。
当再搭配工作频率从数十MHz提升到数百MHz后,对于语音唤醒词(Key Word Spotting, KWS), 传感器异常侦测(AnomalyDetection, AD), 运动手势辨识(Motion / Gesture Dectection)等微型AI应用大概都能完成,但若遇到有影像类应用则远远不够。
Arm Cortex-A系列为64bit CPU,所以其上有NEON(进阶SIMD)指令集,可处理128bit或64bit的SIMD计算,让计算速度更快,但这样的指令在32bit的Cortex-M并没有支持,所以Arm在v8.1M指令中加入Helium M型向量扩展指令(M-Profile Vector Extension, MVE)来提升Cortex-M单芯片的算力。
Helium可以处理128bit的向量运算(相当于SIMD16x8bit, 8x16bit, 4x32bit),共有8个向量缓存器,可处理整数、定点数(Q7,Q15,Q31)及浮点数(半精度FP16/单精度FP32)计算,有超过150个新指令。
若为了处理128bit的向量计算就把数据总线(Data bus)及单芯片内部静态内存(SRAM)都改成128bit宽是不合理的。最简单的作法是利用四个频率周期将128bit数据当成4个32bit的数据来处理,但这样就会变成和单指令周期32bit SIMD指令没什么不同。因此Helium在向量计算时可以将加载(VLDR)和乘加(VMLA)计算进行重迭,一边加载一边计算,这样就可以再加速一倍以上。如Fig. 2右下所示。
在Cortex-M55/M85采取双节拍(Dual Beat)作法,就是1个频率周期(Clock Cycle)读取二个节拍(Beat),即2×32=64bit,所以128bit的向量要2个频率周期才能处理完成,而1个频率周期处理的内容可以是下列组合。
2个32bit(Q31定点数或32位整数或32位浮点数)
4个16bit(Q15定点数或16位整数或16位浮点数)
8个8bit(Q7定点数或8位整数)
而Cortex-M52则采单节拍(Single Beat)作法,可处理长度则减半为32bit(1x32bit, 2x16bit, 4x8bit),128bit的向量需要4个频率周期才能处理完成。
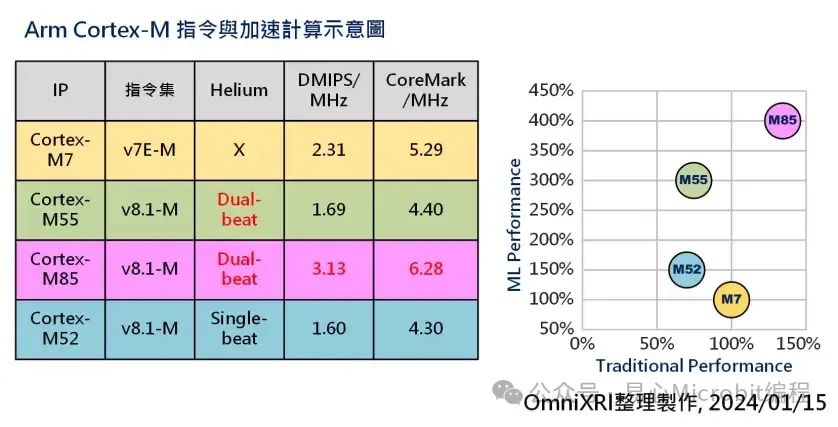
Fig. 2 Arm Cortex-M指令与加速计算示意图。
3. Helium指令集效能比较
目前有支持Helium指令的MCU共有四家公司,如下所示。
Cortex-M55:
ALIF – Ensemble E1(@160MHz), E3(@160MHz),E5(dual core,@160MHz, 400MHz), E7(dual core,@160MHz, 400MHz)
奇景(Himax) – WiseEye2 HX6538(dual Core, @150MHz, 400MHz)
新唐(Nuvoton) – NuMicro M55M1(@200MHz)
Cortex-M85:
瑞萨(Renesas) – RA8D1(@480MHz), RA8M1(@480MHz)
Cortex-M52:
None
以下就以Cortex-M7为基准(100%)和Cortex M55/M85/M52进行比较。如Fig. 3所示,横轴为传统性能(DMIPS/MHz),纵轴则为机器学习推论性能(ML Performance)。以M55为例,虽然传统性能较M7低,但机器学习性能却高出3倍,由此可看出Helium指令集提供的效能提升。
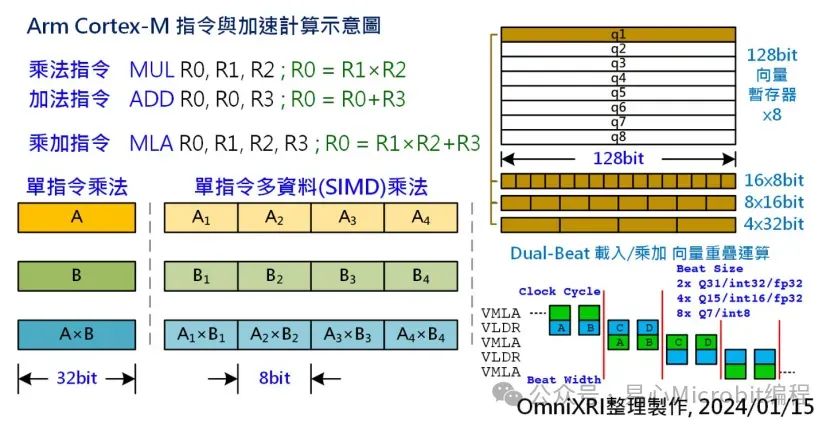
Fig. 3 Arm Cortex-M 指令与加速计算示意图。
以上算力对于非影像的微型AI应用大致能满足,但若遇到影像类应用则单靠CPU的SIMD及MVE指令集可能还是不够。幸运地是以上提及的ALIF, Himax, Nuvoton的MCU都有内建Arm Ethos U55 NPU,这样就能将算力再推高数十倍,可以满足低分辨率、低频度的影像分类、对象侦测甚至姿态估测等应用。
小结
随着半导体技术的提升及配套的软件开发工具逐渐到位,利用单芯片提高工作频率及高度平行乘加运算(SIMD, MVE),开启了可以不依靠网络就能完成微型AI运算的契机,使得平价、低耗能的边缘智能装置(Edge AI & TinyML Device)有了更大的创意发挥空间,让智慧生活、智能照护、智能制造、智能建筑等更多应用能快速实现。
审核编辑:刘清
-
传感器
+关注
关注
2550文章
51046浏览量
753160 -
加速器
+关注
关注
2文章
799浏览量
37846 -
神经网络
+关注
关注
42文章
4771浏览量
100723 -
单芯片
+关注
关注
3文章
419浏览量
34572 -
NPU
+关注
关注
2文章
282浏览量
18585
原文标题:谁说单芯片没有神经网络加速器NPU就不能玩微型AI应用?
文章出处:【微信号:易心Microbit编程,微信公众号:易心Microbit编程】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论