 一座“超级工厂”:让中国没有流不通的数据
一座“超级工厂”:让中国没有流不通的数据
新春伊始,中国各个行业、领域都在关注一个热词:新质生产力。
新质生产力代表着一种生产力的跃迁,意思是“以科技创新发挥主导作用的生产力”。简单来说,就是新兴科技催生而来的颠覆性发展引擎。尤其在这个万物互联的数字时代,发展这种更具融合性、更体现革新内涵的生产力质态,是企业与行业的微观诉求,同时也是地区与国家的宏观诉求。
如何才能获得新质生产力,是千行万业共同面对的时代考题。
想要回答这道考题,就需要认识一个基本逻辑:生产力的迭代是人类文明发展的内生引擎,其来自对生产要素的有效激活,而新质生产力的来源,就要依靠对新型生产要素的激活。
提到新生产要素,一个关键词将映入眼帘,这就是“数据要素”。
与传统生产活动消耗自然资源不同,数字经济的发展消耗的是“数据要素”。在2019年,相关政策明确指出了“健全劳动、资本、土地、知识、技术、管理、数据等生产要素由市场评价贡献、按贡献决定报酬的机制”,标志着数据要素正式投入到中国经济的产出与分配阶段,成为继劳动力、土地、资本、技术之后的“第五生产要素”。
去年,国家数据局的成立受到全球瞩目。随后在年底,国家数据局等17部门联合印发了《“数据要素×”三年行动计划(2024—2026年)》,明确开展“数据要素×科技创新”行动。探索激活数据要素价值、获得新质生产力的方法,成为今年国民经济与企业发展最重要的议题之一。

然而在实践中,企业经常发现数据并不匮乏,缺乏的是管理、使用与流通。粗犷而富有生命力的数据散落在田野间蓄势待发,但想让它们形成数据资产、变成真实的生产力,还需要一座座现代化的“工厂”来完成。
2月20日,伴随着万千企业新春开工的音信,华为举办了2024数据存储新春新品发布会。期间,华为率先发布了业界全新的数据湖解决方案。
这个解决方案,就是一座面向数据要素的超级工厂,它可以把大量原始数据进行智能加工,从而满足数据产品的多样化需求,解锁了迈向数据资产化进程的层层桎梏,让数据焕发出勃勃生机。
属于中国大地的新质生产力从何而来?在这个AI技术唤醒每一比特数据的黄金年代,只要让数据要素看得清、理得顺、用得好、流通好,那么千行万业自然就有了蓬勃新生的信心与底气。
从数据要素,到数据资产:最壮阔的时代机遇
近几年,全球范围内迎来了以AI大模型为代表的智能技术大爆发。智能的来源是对数据的洞察与学习,因此数据要素的价值正在经历跨世代的升级,各行业都在爆发出巨大的数据要素红利。
举例来看,华为盘古大模型通过对超过300PB全球天气历史数据,以及近10年超过70PB的卫星降水历史数据进行学习,实现了降雨预测准确率提升20%,从而将实现在全国范围内每年减少百亿元的暴雨经济损失。
某大型银行,通过将53年内积累的超100PB数据,以及每天实时产生的300TB数据进行融合分析,实现了降低约5%的不良贷款率,每年减少直接损失约5亿元。
这些数据要素带来的直观红利,意味着巨大的产业机遇。这也让数据要素开始向数据资产进行升级,成为企业核心资产的组成部分。同时我们知道,一种生产要素的资产化,要求其具备可量化、可估值、可流通的特性。但在数据要素的生产与流通实践里,企业还是需要大量面对诸如数据管理困难、认证授权复杂、流通安全难以保障等问题。
简言之,高速成长的数据要素,正在成为这个时代机遇最大、价值提升最为迅猛的生产要素。数据资产化,是每家企业都必须关注的方向,而让这一切机遇成真的前提,是扫清数据资产化进程中的挑战。
只有数据无碍,企业无忧,数据要素才能真正变为数据资产。
从野蛮生长,到工业化体系:建立数据要素市场面临的挑战
为什么提起数据资产化时,很多企业会觉得为时过早,或者障碍重重?
根据国家工业信息安全发展研究中心发布的数据,在2022年至2025年,中国数据要素市场复合增速将达到28.99%,全国数据产量将达到8.1ZB,位居全球第二。中国已经成为名副其实的“数据大国”,但从数据大国到数据强国,是千行万业普遍面临着数据质量不高、流通机制不畅、应用潜力释放不足等问题。
在企业的实践中,很容易发现数据并不像土地、资金、技术专利等传统生产要素那样清晰和标准化。绝大多数产业数据,都是企业在生产实践中自然形成的,从收集到加工、流通都处于野蛮生长状态。具体表现为数据要素的权属判断更为复杂,聚集和归档非常困难,价值密度难有标准,甚至隐私泄露、数据错用等问题可能会给企业带来负面影响。将这些直观的挑战归类整理,华为在发布会中提到,当前在建立数据要素市场体系过程中,主要需面对四大难点:
1.数据看不清。
大中型企业、连锁企业、跨国企业经常会面对分散在各地的海量数据。这些数据标准不一、格式多样、源头散落各地,从而导致企业事实上很难全盘纵览整体性数据。与此同时,数据盘点依赖人工操作,导致盘点成本大、讹误多,进一步加重了数据“看不清”的问题。
2.数据理不顺。
数据收集之后,需要整理分类。但目前大量企业的数据分类依赖人工,这就导致分类标准难以统一,数据容易变得杂乱无章。当前阶段,中国企业数据分类依赖人工比例超过了60%,在海量数据时代,提升数据分类自动化水平迫在眉睫。
3.数据用不好。
在收集与分类之后,数据需要真正加工成数据产品才能发挥其价值。但在这个阶段,企业往往面临数据应用方式较为传统,数据加工成本过大等问题。比如说,用自身数据训练AI大模型是企业非常关注的领域。但在AI训练之前,需要大量时间进行数据清洗与标注,这个成本是很多企业难以承受的。
4.数据流不动。
数据资产化的最后一环在于数据的高效流通。但在这个阶段,企业一方面是“不敢流”,需要承担安全与合规方面的风险,一旦流通起来就可能面临“隐私裸奔”的危机。另一方面是“流得慢”,数据流通过程中所需的存、算、网等数字基础设施开支也是挡在企业面前的一座大山。这导致很多企业在数据流通时,还在选择快递硬盘这种原始且不安全的方法。
这四大挑战,关注到了数据从生成、管理到流通的每一个环节,可以说是所有企业都将面对的数据资产化难题。如何才能把千行万业野蛮生长的数据,变成精密、可靠、标准化的工业品,是数据要素时代的核心考题。
为此,华为希望搭建一座“超级工厂”,来帮助海量数据走向工业化的全新时代。
从千行万业,到一座“超级工厂”:华为数据湖解决方案
千行万业,都需要加速数据资产化进程。这也意味着千行万业的数据,也都需要这样一座“超级工厂”。它像流水线一样完成原始数据的加工、盘点、分类,完成一站式处理,并且构建可靠的流通传输环境,让数据要素从野蛮粗放走向清晰规整。
这座工厂,就是华为基于GFS打造的数据湖解决方案。GFS(Global File System)是指全局文件系统,它作为整个方案的灵魂组件与驱动引擎,与上层的数据服务层和下层的数据存储层协同,构筑了一个完善而高效的数据编织层,以全局命名空间,帮助数据资产实现可视、可管、可用。

(华为分布式存储领域总裁袁远)
具体而言,为了应对数据资产化进程中的四大挑战,华为数据湖解决方案包含这样一些技术创新特性:
首先,是数据资产一张图。
华为数据湖解决方案可以实现跨地域、跨站点、跨厂家的统一元数据纳管,同时实现不同格式、协议的数据均无损地统一入湖。除此之外,为了应对远数据扫描上报过程中的低效率、重人工问题,数据湖解决方案还能将增量数据在业务侧无感知地实时更新,从而横跨时间、空间的限制,帮助企业将所有数据尽收眼底。

某世界500强企业,需要面对来自全球超过200家子公司,130多家全球代表处的数据汇总,导致经营报告变成了巨大工程。通过应用全局资产一张图,这家公司将超过100万张表格进行了高效地盘点、注册,从而使月度报告生成时间从18天缩短为3天,年度报告生成时间从三周缩短至一周,大幅提升了经营决策效率,真正做到了全球数据一览无遗。
其次,是智能数据目录。
面对数据的整理、分类难题,华为数据湖解决方案提供智能数据目录能力,从而实现自动化的数据标签与聚合,满足数据的高效检索与呈现。从应用场景上看,智能数据目录有两类应用。一是进行数据合规的自动分级,对敏感数据、隐私信息进行自动识别。二是数据内容的自动分类,将数据按照业务需求进行智能的属性化标签处理。
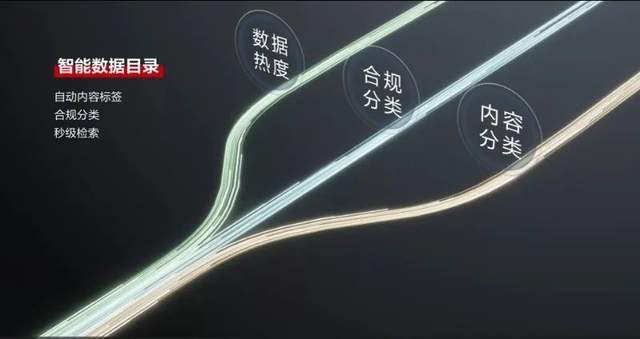
某海外企业在进行AI质检实践中,就应用了智能数据目录能力。通过自动化的数据标签与数据处理,将需要数天完成的数据处理时长缩短到了18分钟,相关服务器数量也减少了一半,全方位提升了数据整理效率,降低了相关成本。
最后,是通过构建可信的数据交换空间,让数据真正安全高效地流通。
华为数据湖解决方案提出了可信数据空间的概念。在这个空间里,企业可以通过合法性认证、安全管控策略、全链路加解密、日志留痕等能力,实现数据的可信、可控和可追溯流转,并支持第三方监管与运营,从而在数据流通双方或者多方之间搭建了安全可信的数据要素通道。

针对数据流通效率低、成本高的问题,华为数据湖解决方案也提供了面向跨域访问的数据智能缓存能力,访问任何地域的数据都像访问本地一样高效。此外,在数据传输过程中提供2:1的无损压缩能力,从而降低数据传输压力,节省相关成本。
总之,华为数据湖解决方案这座为数据要素而生的“超级工厂”,蕴含了针对数据资产化过程中每项挑战的解题思路。
踏着数据资产化的脚步,一场引爆数字时代的熊熊烈火便至此燃烧起来,迸发出超乎想象的巨大能量。
从实践,到未来:让中国没有流不通的数据
从当前阶段企业的数据资产化实践,到未来更广阔的数据市场构建,可以看到华为数据湖解决方案将展现巨大的潜力,最终推动新质生产力在每个行业、每家企业中涌现出来。事实上,在当前的数据资产化实践中,先行一步的数字化、智能化探索者们已从中获益。
举例来说,在某家大型银行中,原本需要面对总行与分行之间、银行同业之间缺乏安全、高效数据流通手段,导致业务上线慢,安全顾虑大的问题。
通过在总行、分行统一部署华为数据湖解决方案,该银行实现了一系列数据要素的价值跃升。比如,通过可信数据空间与GFS的结合,银行数据实现高效流通,并且全行数据使用违规的次数降低了80%,再比如,通过全局数据可视、可管,这家银行实现了全行一张图,从而加速数据报表生产,并让产品开发更加敏捷,新业务上线时间从1月缩短到1周。此外,通过GFS与华为OceanStor分布式存储的结合,这家银行在满足多样化业务负载、协议诉求的同时,通过热、温、冷数据智能分级实现了TCO下降30%。
这一案例不仅对金融行业具有参考价值,对于各个行业的数据资产化来说,都有积极的借鉴意义。
而望向更远的未来,华为将推动open-GFS开源计划,面向伙伴及用户开放包括异构接入框架、全局视图管理以及数据流动引擎等核心能力,从而完成更贴近行业的数据流通能力、加速数据资产化进程,让用户免除后顾之忧。

如果说,农业时代比拼土地,工业时代比拼劳动力和资本,信息时代比拼技术,那么未来企业迈出的每一个脚步、登上的每一层楼、跨过的每一座山峰,都嵌在那一次次数据涌动之中。谁能率先将数据纳为生产要素,能从数据中汲取资产化价值,谁就能率先获得智能时代的船票,激发出面向未来的新质生产力。
而这一切的开端与前提,是数据要素走进“工厂”。
在这座工厂的宏伟蓝图里,每一条历史与实时数据都有其价值,每一个智能体都能被数据点燃。无垠的中国大地之上,将没有流不通的数据。
-
数据
+关注
关注
8文章
7085浏览量
89245 -
华为
+关注
关注
216文章
34481浏览量
252251 -
分布式存储
+关注
关注
4文章
172浏览量
19548 -
超级工厂
+关注
关注
0文章
99浏览量
3943 -
盘古大模型
+关注
关注
1文章
109浏览量
306
发布评论请先 登录
相关推荐
欣旺达:越南再建一座电池工厂

博世超级工厂里有哪些超级力量
特斯拉中国上海超级工厂已完成60%

美国半导体设备供应商MKS计划在马来西亚建设“超级中心”工厂

施耐德电气签署协议为辉能科技法国电池超级工厂开发智能制造技术
特斯拉进军储能行业 上海储能超级工厂计划2025年第一季度实现量产
特斯拉上海储能超级工厂已获施工许可证

格力电器将于6月投产全球第二座SiC全自动化化合物芯片工厂






 工商网监
工商网监
评论