 请问AMBA总线之AXI是如何提高性能的呢?
请问AMBA总线之AXI是如何提高性能的呢?
很多读者对AXI是如何提高吞吐量,提高带宽的方式还不够Make sense。本篇文章将从概念本身,结合配图,带大家充分理解AXI是如何提高性能的。
1、如何评估性能?
性能中一个关键的指标就是延迟,什么是延迟(Latency)呢?
比如有个人,叫做小明,在上大学需要用钱,因此给父亲寄信。父亲收到信以后将钱寄给小明同学。整个过程一共花费了2+3=5days。这就是整个寄信加寄钱所花费的延迟。
我们假设每次寄钱只能够寄两万,由此我们又可以引出带宽(Bandwidth)的概念。所谓的带宽即单位时间可以传输的数据量多少。在上述的例子中BW=2W/5days = 0.4W/day。
如果按照这样的一个带宽速度,寄100万需要多久呢?我们用数据量除以带宽:100W/(0.4W/day)=250days!
如何让寄100万更快呢?一种很直接的方法,就是在收到钱之前,狂发信。父亲每收到一封就把钱寄回去。理论上这样只需要5天多一点,就可以寄100W!
2、Outstanding对性能的影响
有了上面的例子,大家已经知道了什么是延迟和带宽了。由此我们接着往下讲。在之前的文章已经讲过,AXI提高传输速度主要有三板斧,以下排名分先后顺序:
Outstanding
Out-of-orde(ooo)
Interleave
最直截了当提高总线性能的方法是什么呢?首先就是提高频率,再一个就是提高数据位宽。这两种方式对所有的总线实际上都是成立的,但由于过于简单粗暴,一般不能作为某个总线的优势或者卖点所在。
因此我们重点讲一下AXI的三板斧,首先是Outstanding。所谓的Outstanding就是在任务完成之前就可以下达新的任务,即“在路上”。Outstanding是上面三种方法中,提高总线性能最有效最简单的方法!
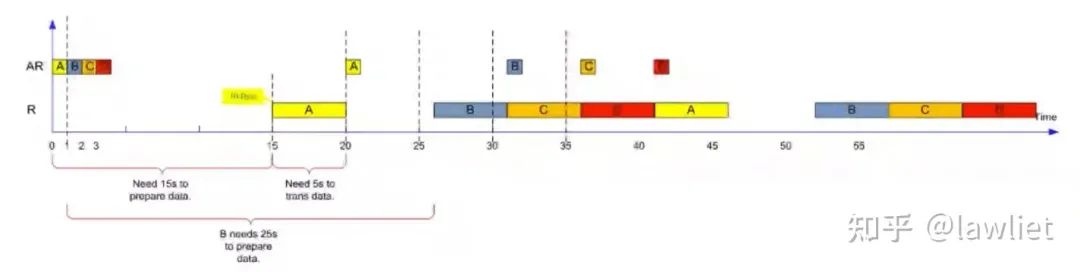
我们看一下Outstanding的延迟怎么算。下图显然是不支持Outstanding的例子,可以看到AR发出以后,需要15个Cycle准备数据,又需要5个Cycle传回数据。因此总共需要20个Cycle。
这个例子中绝对延迟和平均延迟都是20s。
这个例子中带宽BW=30B/60s=0.5Bps,然而最大的瞬时带宽是2Bps。
有75%的时间都因为Master和Slave之间的巨大延迟而浪费掉了!
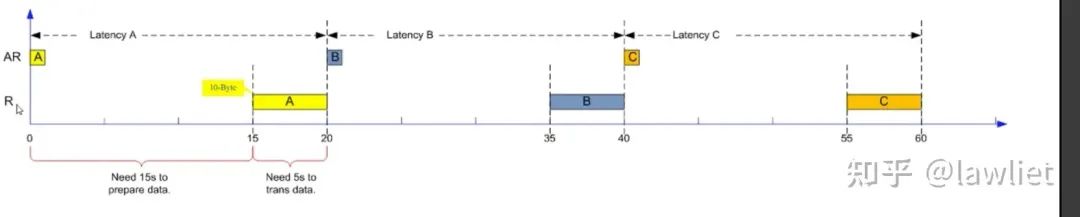
我们再看一下Outstanding做到3的时候是怎样的结果,下图这个例子中,绝对延迟依然是20s。但是平均延迟变为了30s/3=10s。相应的带宽也变成了1Bps。
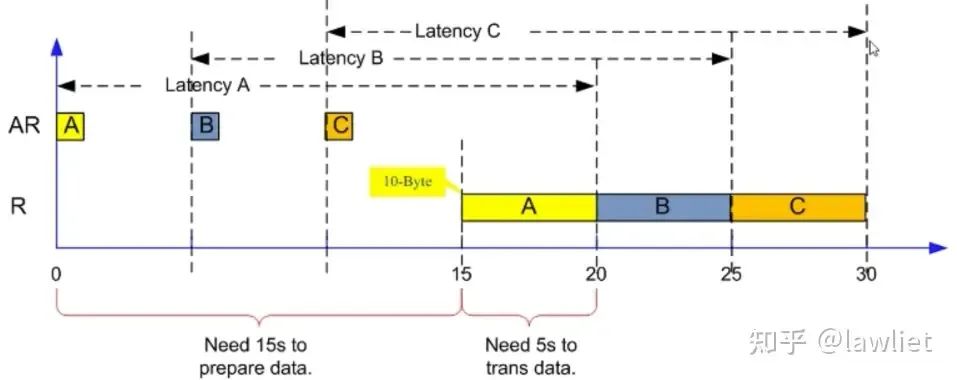
上面那个例子中,是过了5s再发出下一个Outstanding命令,实际上一般不会考虑这么多。当还没有发满的时候,就接着发。我们看下面这个例子:
绝对延迟分别是20/24/28s。由此可以看到Outstanding有可能还会使绝对延迟变长(当然B、C也可以向流水线一样和A紧贴着,这个取决于具体设计。当需要维持住5个Cycle的时候,那自然就需要等待了)
平均延迟是50/6=8.33s。
BW=60B/50s=1.2Bps
也可以用平均延迟算,BW=10B/8.33=1.2Bps
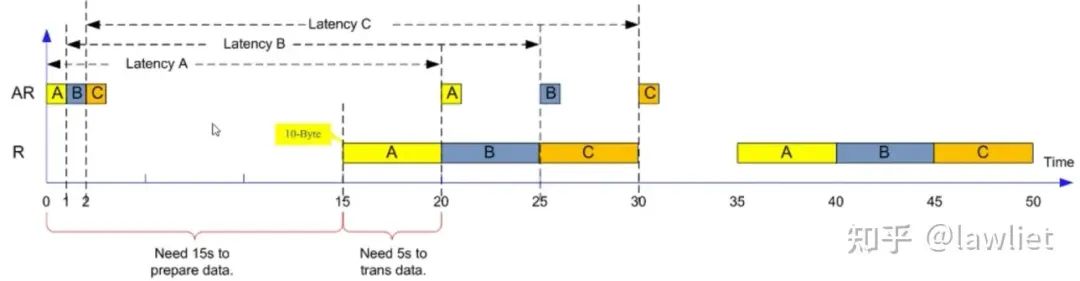
上面那个例子中,R这个信道实际上也是没有占满的,当Outstanding为4的时候呢?可以看看下图这个例子:
绝对延迟分别是20/24/28/32s
平均延迟是55s/8=6.875s,极限是lim�→∞(15+�∗5)/�=5�
BW=80B/55s=1.45Bps,极限是lim�→∞(10∗�)/(15+�∗5)=2���
可以看到理论极限就是5s,这个时间对应于真正需要传输数据或者是维持住某个数据不变的时间。极限的带宽实际上就是10/5=2Bps
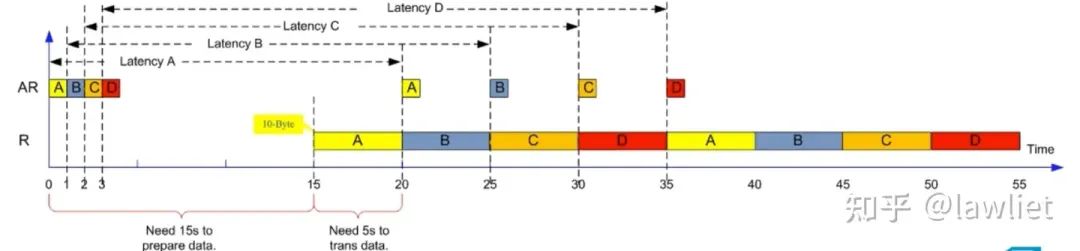
我们再来思考一个问题:Outstanding数量越多越好吗?
答案当然是否定的,更多的Outstanding意味着更多的硬件资源开销,比如就需要很多的Buffer去存储已经发送的CMD。但通过上面的例子我们可以看出,当Outstanding再增加,其性能也已经饱和了,不会再增加。因此选择一个合适的Outstanding数量,基于此进行设计很重要。
既然Outstanding不是越大越好,那我们怎么去估计Outstanding数量呢?
我们考虑一个非常简单的例子:
假设始终频率是500MHz,相应的周期是2ns
假设AXI cmd是基于burst-8传输的。即对于一个cmd,至少需要8个cycle传输相应的数据。
第一笔数据返回的时候,需要200ns
由此可以估算Outstanding的数量为200/(2ns*8),可以设置为8或者16(一般是用2的幂次方)。实际中会比这个例子复杂的多,该例子只是帮助大家梳理一下基本思路。
我们再看一下Outstang的优缺点:
优点:提高带宽,减少平均延迟
缺点:可能会增加绝对延迟,一定会增加面积(需要Buffer存CMD,如果没有乱序,这个时候额外的面积其实还不太多,如果要支持乱序,那额外的面积开销就大了,因为还要存DATA)
此外,Outstanding是ooo和Interleave的基础,没有Outstanding,后面二者是无从谈起的。
3、Out of Order对性能的影响
讲完了Outstanding,我们来看一下乱序。在上面的例子中,大家可能会觉得:咦?不是R信道已经占满了吗?难道还可以提速吗?为什么还需要乱序?
因为在上面的例子中,我们是假定各个模块准备数据的延迟是一样久的。但是在下面这个例子中,可以看到B需要更多的周期去准备相应的数据,又浪费了Cycle!假如B的数据是来自DDR的,此时还用这种方式且不支持乱序,那就非常Naive了,可能百分之九十多的周期都被浪费了。
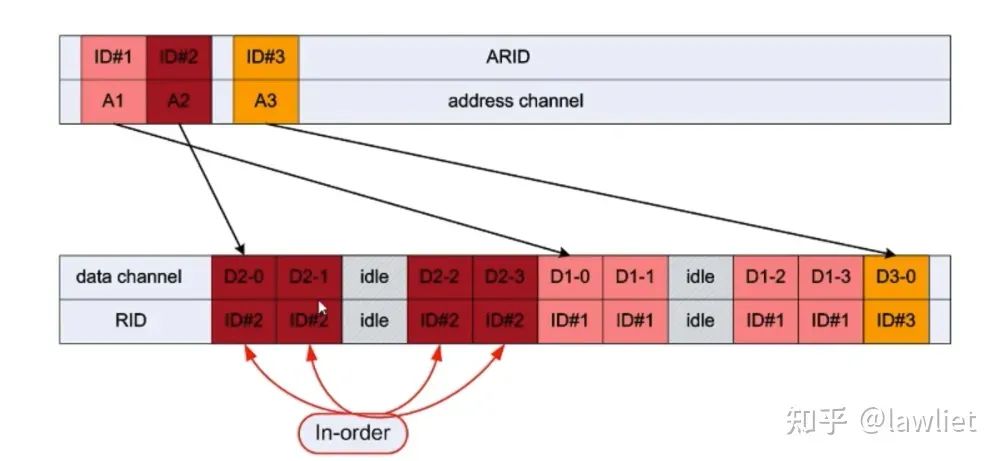
这种情况下,我们就要使出第二板斧,乱序。可以看到下图这个例子,我们可以让快速的Slave先传,然后再传慢的Buffer。

如果要做Out of Order。那么Master端就需要一个非常大的Buffer了。以上图例子中,就需要40Byte的Buffer了。因为最差的情况,数据ABCD是倒着回给你的,但是你还是得按照顺序用,那只能用额外的Buffer存储了。因此如果不是某个Slave一定会乱序,且对性能影响很大,一般做Master是不建议支持Out of Order的。
4、Interleave对性能的影响
Interleave就是交织,在AXI中的Interleave,按照我的理解就是更加细粒度的乱序。
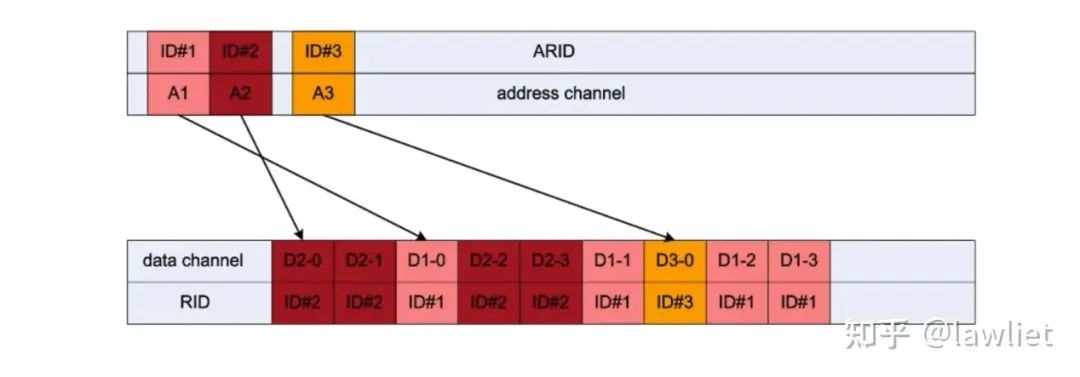
我们考虑这样的例子,每次CMD需要4次Transfer。我们假设Slave准备数据很慢,每次只能准备2次Transfer的数据,如下图所示。可以看到,又有Cycle浪费了(可以看到这个例子中,是Out of Order的,但是同样有周期的浪费)。
当允许交织以后,如下图所示:可以看到每个周期都充分利用上了,非常的棒啊。这样性能会更加好。但是Interleave显然,比Out of Order更麻烦。它消耗的面积和乱序实际上是差不多的,但是控制逻辑复杂的多。正因为如此,AXI4已经移除了写交织,仅保留读交织。
实际上很多Master压根不支持读交织,大家设计模块的时候,还是要根据实际需求,确定是否需要支持这些功能。毕竟一旦支持这些功能,一个简单的DMA Master的代码都奔着上千行去了,还非常容易出错。(笔者当时就做了一个可以乱序和读交织的DMA,仅仅和验证配合调试都花了两个多月)。
5、其它提高AXI性能的办法
这里主要讲两点:
QoS
数据/传输的重定义,优化
5.1、QoS
QoS实际上是计算机网络的概念,QoS(Quality of Service)即服务质量。在有限的带宽资源下,QoS为各种业务分配带宽,为业务提供端到端的服务质量保证。例如,语音、视频和重要的数据应用在网络设备中可以通过配置QoS优先得到服务。
ARM基于此概念,在AXI4新增QoS相关的信号,为AxQOS,共4bit,其定义了每次传输的优先级。我们一般认为0xF代表最高的优先级,0x0代表最低的优先级。QoS一般有如下的作用:
QoS可以用来解决访问冲突问题,当同时访问先仲裁得到优先级高的;
Slave可以根据QoS来reorder或者优先考虑先回应哪笔传输;
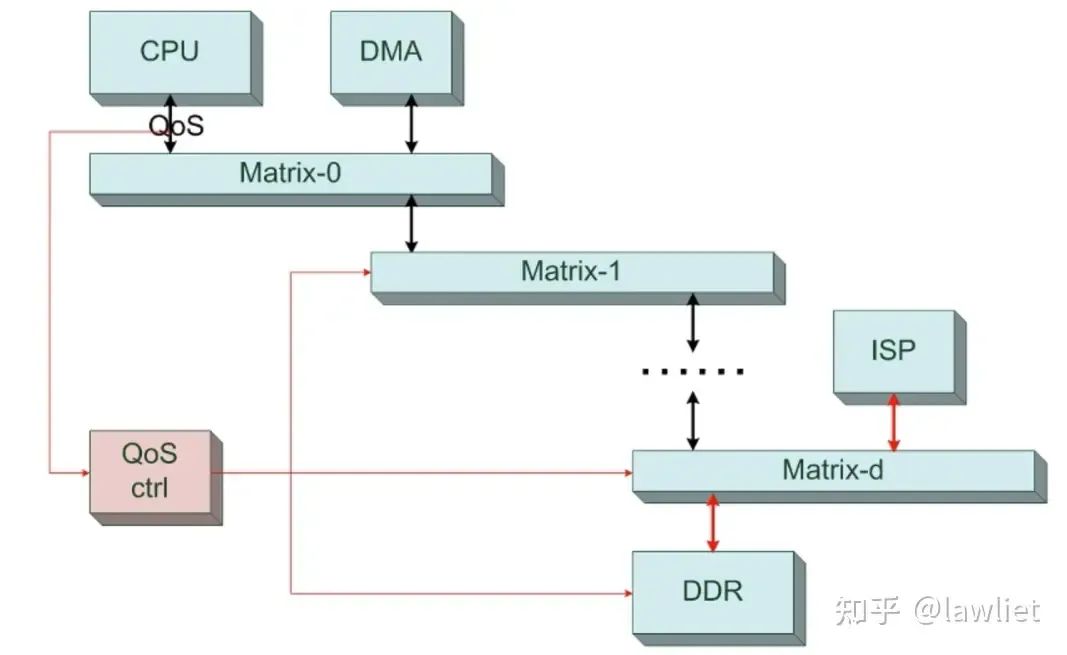
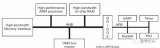
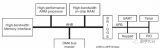
下图是一个典型的复杂系统,这种系统就需要QoS来确定,到底哪个Master可以优先获得总线访问机制,因此就需要设计复杂的QoS控制系统,此系统一般是可以通过软件实时的去改配。
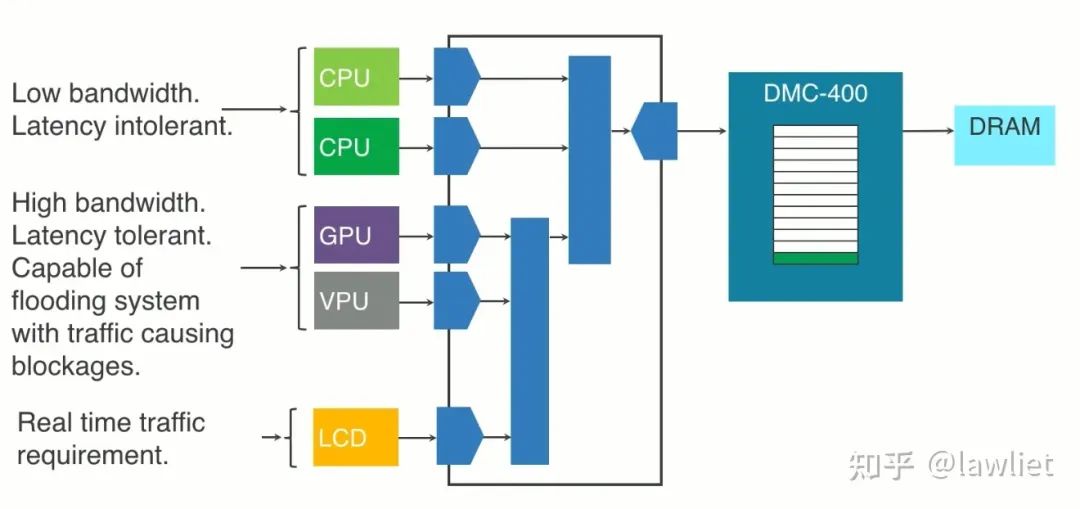
我们再思考一下,QoS主要是优化延迟还是带宽呢?
AXI的QoS主要是为了解决延迟问题。通过此值,可以更好的仲裁,以避免延迟大的阻塞住整个总线,而严重影响其它模块的访问延迟。当然它一定程度上也会影响到带宽。
AXI的QoS实际上我没参与设计过,这里就不展开讲具体设计了,以避免误导大家。
5.2、Data/Transfer
上面我们讲的这些AXI的优化策略,其实ARM的初衷,主要是为了DDR设计的。因为大部分Slave和Master之间都是紧耦合的,根本就不需要Out of Order和Interleave。那么如何针对DDR的读写去优化呢?简单来讲就是你的CMD和DATA要更加符合DDR的胃口。
地址对齐;
增加Burst Length;Burst Combine;
避免Partial Write。即WSTRB有1有0。因为很多DDR是不支持此功能的,你要读回去再写,非常耗时;
Read/Write Group。即不要写一个读一个,最好是写一组读一组;
避免Locked/Exclusive access;(Locked就不说了,Exclusive是一读一写,对DDR非常不友好)
6、AHB vs AXI
最后我们总结一下AXI和AHB的区别,再回顾一下AXI的优势所在。
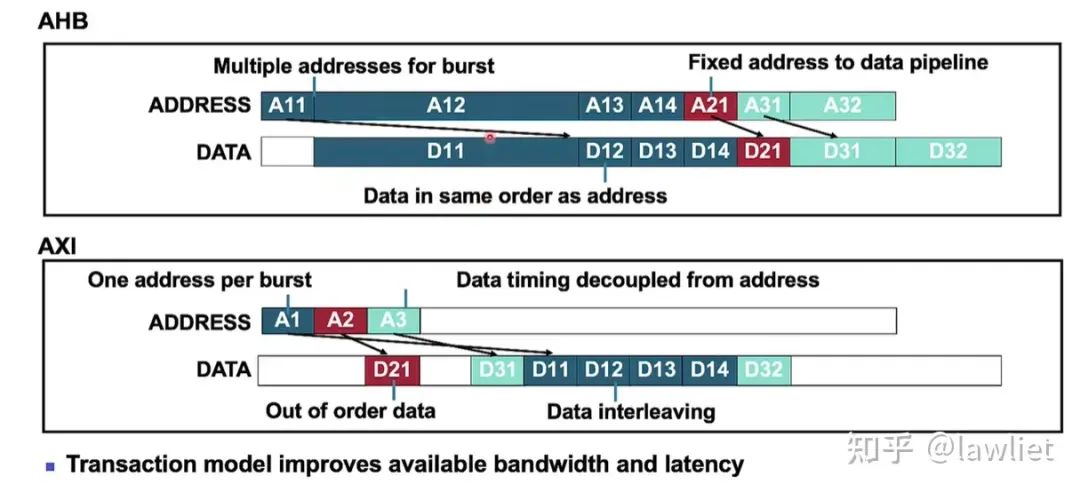
如下图所示,是AHB和AXI的读例子:
尽管AHB也可以突发传输,但是它每一次都是需要更新相应的地址,而AXI只需要给一次地址即可。后续的数据可以让Slave自己根据首地址不停地去算。
此外AXI支持乱序,如果针对地址A1的transaction没能及时响应,没关系,可以先回地址A2和A3的数据。减少了可能存在的周期浪费。
此外AXI读还支持Interleave,即更加细粒度的乱序。可以看到针对地址A3的回数据,可能回了一笔突然回不了了,没关系,可以马上回地址A1的数据,再回地址A3的数据。
审核编辑:刘清
-
控制系统
+关注
关注
41文章
6605浏览量
110581 -
DDR
+关注
关注
11文章
712浏览量
65318 -
QoS
+关注
关注
1文章
136浏览量
44781 -
AMBA总线
+关注
关注
0文章
35浏览量
9542 -
AHB
+关注
关注
0文章
21浏览量
9782
原文标题:深入理解AMBA总线之AXI是如何提高性能的
文章出处:【微信号:Rocker-IC,微信公众号:路科验证】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
学习架构-AMBA AXI简介
AMBA3.0 AXI总线接口协议的研究与应用
AMBA总线AHB、APB、AXI性能对比分析及AHB详解
AMBA总线概述(二)
AMBA3.0 AXI总线接口协议的研究与应用
AMBA 3.0 AXI总线接口协议的研究与应用
基于AMBA总线介绍
介绍AMBA2.0总线





 工商网监
工商网监
评论