 TikTok引入前谷歌VideoPoet负责人蒋路,发力AI视频生成
TikTok引入前谷歌VideoPoet负责人蒋路,发力AI视频生成
独家获悉,谷歌高级科学家、卡内基梅隆大学(CMU)计算机学院兼职教授蒋路,已经加入TikTok。
蒋路是谷歌 VideoPoet 项目负责人,VideoPoet 是谷歌在 2023 年 12 月推出的视频生成大模型,类似 OpenAI 刚刚发布的 Sora。
近期,昆仑万维创始人周亚辉在朋友圈表示,有个论文的作者加入字节北美做Tech Leader,正是指《VideoPoet: A large language model for zero-shot video generation》论文的作者蒋路。
资料显示,蒋路先后在西安交通大学、布鲁塞尔自由大学、卡内基梅隆大学学习计算机,并先后进入微软亚洲研究院、谷歌研究院、雅虎研究院实习。
2017 年,蒋路毕业后加入谷歌。他是谷歌云 AI 的创始成员,也是李佳博士和李飞飞博士首次聘请的研究员。此后,蒋路进入谷歌研究院工作。
蒋路的研究曾被应用到谷歌多个产品,如 YouTube、云服务、云 AutoML、广告、Waymo 和翻译服务,影响了全球数十亿用户的日常生活。
蒋路的工作在自然语言处理(ACL)和计算机视觉(CVPR)的顶级会议上被提名为最佳论文。他是研究社区的活跃成员,担任美国国家种子基金(NSF SBIR)的 AI 评审专家,并定期担任 CVPR、ICCV、NeurlPS、ACM Multimedia 和 AAAI 等著名会议的领域主席。
蒋路的研究兴趣主要在多媒体交叉领域,他专注于生成式 AI 和视频创作。2019 年起,他就开始尝试将 Transformer 用在图像、视频生成研究上。
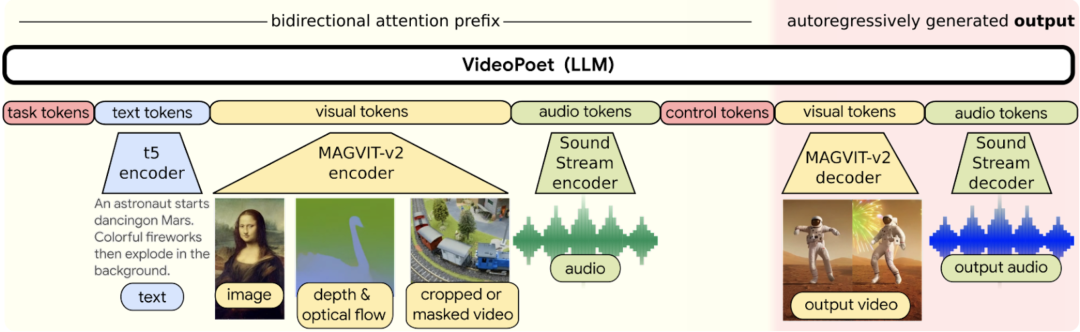
与 Sora 采用的 Diffusion + Transformer 架构不同,蒋路负责的 VideoPoet 视频生成模型采用了单 Transformer 架构,可以将任何自回归语言模型或大型语言模型转换为高质量的视频生成器,支持生成方形或纵向视频,以针对短格式内容定制生成视频,并支持视频输入生成音频。
VideoPoet 采用了名为 Tokenizer 的数据处理技术,可以将视频和音频片段编码为离散标记序列(discrete tokens),这些标记也可以被转换回原始表示。其中,视频和图像数据使用名为 MAGVIT V2 的技术,音频数据使用 SoundStream 的技术。
VideoPoet 通过使用多个 Tokenizer 训练一个自回归语言模型,以学习跨视频、图像、音频和文本模态。一旦模型根据某些上下文生成了标记,这些标记就可以通过分词器解码器转换回可查看的表示。
3 周前,蒋路本人在职场社交平台宣布了自己在谷歌的 Last Day,并特别表示对在谷歌所做的视频生成项目(VideoPoet,MAGVIT,WALT等)感到自豪。
蒋路表示自己将继续留在湾区,开始视频生成领域的新旅程。现在来看,新的旅程就是 TikTok。
值得一提的是,字节跳动已经在大模型领域全面布局,模型层推出了自研的「云雀大模型」以及类 ChatGPT 对话机器人产品豆包。2023 年底,字节跳动成立新的 AI 应用部门 Flow,并在海外推出了 Coze 等多款产品。抖音集团 CEO 张楠也于近期卸任,专注于 AI 工具剪映的发展。
字节跳动近期辟谣了推出中文版 Sora,并表示:“还无法完善产品落地,距离国外模型有很大差距。”但另一方面,字节跳动正在大力招揽人才。
大模型战场,字节跳动将会如何搅局?
审核编辑:刘清
-
机器人
+关注
关注
210文章
28191浏览量
206487 -
计算机视觉
+关注
关注
8文章
1696浏览量
45927 -
OpenAI
+关注
关注
9文章
1042浏览量
6404 -
TikTok
+关注
关注
2文章
213浏览量
7215
原文标题:独家:TikTok引入前谷歌VideoPoet负责人蒋路,发力AI视频生成|甲子光年
文章出处:【微信号:jazzyear,微信公众号:甲子光年】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
字节跳动自研视频生成模型Seaweed开放
火山引擎推出豆包·视频生成模型
OpenAI硬件负责人热议AI基础设施扩展与节能方案
谷歌任命原Character.AI首席执行官为Gemini联合技术负责人
MediaTek与快手携手创新,端侧视频生成技术引领AI新纪元
MediaTek联合快手推出高效端侧视频生成技术
三星电子任命半导体业务新负责人,加码AI芯片市场
谷歌发布全新视频生成模型Veo与Imagen文生图模型
阿里云视频生成技术创新!视频生成使用了哪些AI技术和算法
小鹏汽车迎来新AI负责人,研发XNGP技术
除了刷屏的Sora,国内外还有哪些AI视频生成工具

openai发布首个视频生成模型sora
AI视频年大爆发!2023年AI视频生成领域的现状全盘点






 工商网监
工商网监
评论