 利用知识图谱与Llama-Index技术构建大模型驱动的RAG系统(上)
利用知识图谱与Llama-Index技术构建大模型驱动的RAG系统(上)
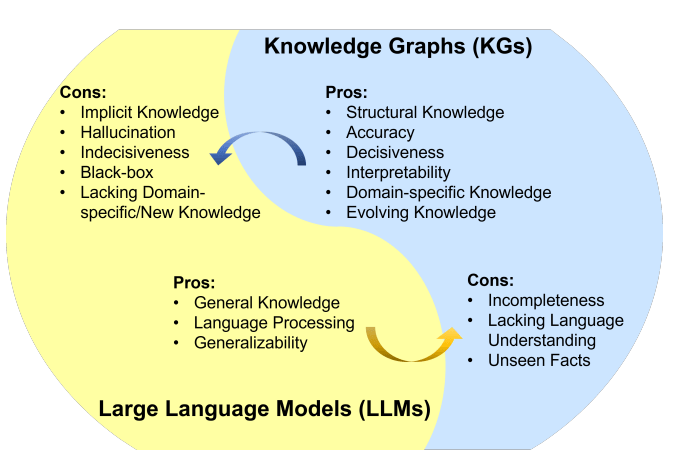
幻觉是在处理大型语言模型(LLMs)时常见的问题。LLMs生成流畅连贯的文本,但经常产生不准确或不一致的信息。防止LLMs中出现幻觉的一种方法是使用外部知识源,如提供事实信息的数据库或知识图谱。
矢量数据库和知识图谱使用不同的方法来存储和表示数据。矢量数据库适合基于相似性的操作,知识图谱旨在捕捉和分析复杂的关系和依赖关系。
对于LLM中的幻觉问题,知识图谱是一个比向量数据库更好的解决方案。知识图谱为LLM提供了更准确、相关、多样化、有趣、逻辑和一致的信息。因此,使用知识图谱可以减少LLM中的幻觉,使其在生成准确和真实的文本时更加可靠。但关键是文档需要清楚地展示关系,否则知识图谱将无法捕捉到它。
向量数据库
向量数据库是一组高维向量的集合,用于表示实体或概念,例如单词、短语或文档。向量数据库可以根据实体或概念的向量表示来度量它们之间的相似性或关联性。
举个例子,向量数据库可以告诉你“巴黎”和“法国”比“巴黎”和“德国”更相关,基于它们的向量距离。
知识图谱
知识图谱是一组节点和边,用于表示实体或概念以及它们之间的关系,例如事实、属性或类别。知识图谱可以根据节点和边的属性来查询或推断不同实体或概念的事实信息。
举个例子,知识图谱可以告诉你“巴黎”是“法国”的首都,基于它们的边标签。
知识图谱组件
顶点/节点:表示知识领域中的实体或对象。每个节点对应一个唯一的实体,并由唯一的标识符进行标识。例如,在关于Chennai Kings的知识图谱中,节点可以具有诸如“Philadelphia Phillies”和“Major League Cricket”这样的值。
边:表示两个节点之间的关系。例如,一条“compete in”的边可以将“Chennai Kings”节点连接到“Major League Cricket”节点。
知识图谱中的基本数据单元
三元组是图中的基本数据单元。它由三个部分组成:
主语:三元组所关于的节点。
宾语:关系指向的节点。
谓语:主语和宾语之间的关系。
在以下三元组示例中,“Chennai Kings”是主语,“compete in”是谓语,“Major League Cricket”是宾语。
(Chennai Kings) — [compete in]->(Major League Cricket)
知识图谱数据库可以通过存储三元组来高效地存储和查询复杂的图数据。
查询图数据库
查询涉及遍历图结构并根据特定标准检索节点、关系或模式。下面是一个简单的示例,展示了如何查询图数据库:假设你有一个代表社交网络的图数据库,其中用户是节点,而它们的关系(例如友谊)由连接节点的边表示。你想要找到给定用户的朋友圈(共同的连接)。
从参考用户开始:在图数据库中,通过查询特定的用户标识符或其他相关标准来识别代表参考用户的节点。
遍历图:使用图形查询语言(如Neo4j中使用的Cypher或Gremlin)从参考用户节点遍历图。编写一个查询,指定要探索的模式或关系。在这种情况下,您想要找到朋友的朋友。示例Cypher查询:MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User) RETURN fof这个查询从参考用户开始,沿着FRIEND关系找到另一个节点(朋友),然后再沿着另一个FRIEND关系找到朋友的朋友(fof)。
检索结果:在图数据库上执行查询,根据查询模式检索出相应的节点(朋友的朋友)。如果需要,还可以获取检索到的节点的特定属性或附加信息。
呈现结果:将检索到的朋友的朋友显示给用户或按照需求进一步处理数据。这些信息可以用于建议、网络分析或其他相关目的。
图数据库提供了更高级查询功能,包括过滤、聚合和复杂模式匹配。具体的查询语言和语法可能有所不同,但总体过程涉及遍历图结构以检索与所需条件匹配的节点和关系。
查询向量数据库
通常涉及搜索相似向量或根据特定条件检索向量。以下是查询向量数据库的简单示例:假设你有一个包含客户配置文件的向量数据库,这些配置文件表示为高维向量,你想找到与给定参考客户相似的客户。
定义参考客户向量:首先,为参考客户定义一个向量表示。这可以通过提取相关特征或属性并将它们转换为向量格式来完成。
执行相似性搜索:使用合适的算法,如k-最近邻(k-NN)或余弦相似度,在向量数据库中执行相似性搜索。该算法将根据相似性分数识别参考客户向量的最近邻居。
检索相似客户:检索与上一步中识别的最近邻居向量对应的客户配置文件。这些配置文件将根据定义的相似性度量表示与参考客户相似的客户。
呈现结果:最后,将检索到的客户配置文件或相关信息呈现给用户,例如显示他们的名字、人口统计信息或购买历史。此信息可用于推荐、定向营销活动或个性化体验。
知识图谱的优势
相比于向量数据库,知识图谱提供了更精确和具体信息。向量数据库表示两个实体或概念之间的相似性或关联性,而知识图谱能够更好地理解它们之间的关系。例如,知识图谱可以告诉你“埃菲尔铁塔”是“巴黎”的地标,而向量数据库只能表示这两个概念的相似程度。这可以帮助LLM生成更准确和相关的文本。
知识图谱支持比向量数据库更多样化和复杂的查询。向量数据库主要基于向量距离、相似度或最近邻来回答问题,这些仅限于直接相似度测量。相比之下,知识图谱可以处理基于逻辑运算符(如“具有属性Z的所有实体是什么?”或“W和V的共同类别是什么?”)的查询。这可以帮助LLM生成更多样化和有趣的文本。
知识图谱比向量数据库能够进行更多的推理和推断。向量数据库只能提供直接存储在数据库中的信息。相比之下,知识图谱可以从实体或概念之间的关系推导出间接信息。例如,知识图谱可以根据“巴黎是法国的首都”和“法国位于欧洲”的事实推断出“埃菲尔铁塔位于欧洲”。这可以帮助LLM生成更符合逻辑和一致的文本。
LlamaIndex
LlamaIndex是一个编排框架,用于简化将私有数据与公共数据集成以构建使用大型语言模型(LLMs)的应用程序。它提供了数据摄取、索引和查询的工具,使其成为生成式AI需求的一种多功能解决方案。
嵌入模型
嵌入模型需要将文本转换为所提供文本的信息的数字表示形式。该表示形式捕获了所嵌入内容的语义含义,使其适用于许多行业应用。在这里,我们使用了“thenlper/gte-large”模型。
LLM
大型语言模型需要根据提供的问题和上下文生成响应。在这里,我们使用了Zephyr 7B beta模型。
代码实现
1、安装所有依赖库
pipinstallllama_indexpyvisIpythonlangchainpypdf
2、设置日志
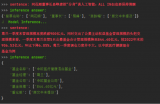
importlogging importsys # logging.basicConfig(stream=sys.stdout,level=logging.INFO) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
3、导包
fromllama_indeximport(SimpleDirectoryReader, LLMPredictor, ServiceContext, KnowledgeGraphIndex) # fromllama_index.graph_storesimportSimpleGraphStore fromllama_index.storage.storage_contextimportStorageContext fromllama_index.llmsimportHuggingFaceInferenceAPI fromlangchain.embeddingsimportHuggingFaceInferenceAPIEmbeddings fromllama_index.embeddingsimportLangchainEmbedding frompyvis.networkimportNetwork
SimpleDirectoryReader:用于读取非结构化数据。
LLMPredictor:用于使用大型语言模型(LLM)生成预测。
ServiceContext:提供协调各种服务所需的上下文数据。
KnowledgeGraphIndex:用于构建和操作知识图谱。
SimpleGraphStore:用作存储图数据的简单仓库。
HuggingFaceInferenceAPI:用于利用开源LLM的模块。
4、引入LLM
HF_TOKEN='YourHuggaingfaceapikey' llm=HuggingFaceInferenceAPI( model_name='HuggingFaceH4/zephyr-7b-beta',token=HF_TOKEN )
5、引入embedding
embed_model=LangchainEmbedding( HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name='thenlper/gte-large') )
6、装载数据
documents=SimpleDirectoryReader('/content/Documents').load_data()
print(len(documents))
审核编辑:黄飞
-
数据库
+关注
关注
7文章
3845浏览量
64665 -
大模型
+关注
关注
2文章
2543浏览量
3118
原文标题:借助知识图谱和Llama-Index实现基于大模型的RAG-上
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
KGB知识图谱基于传统知识工程的突破分析
KGB知识图谱技术能够解决哪些行业痛点?
KGB知识图谱通过智能搜索提升金融行业分析能力
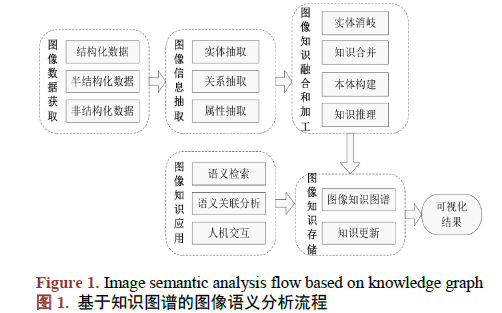
如何使用知识图谱对图像语义进行分析技术及应用研究
知识图谱在工程应用中的关键技术、应用及案例

通用知识图谱构建技术的应用及发展趋势

知识图谱Knowledge Graph构建与应用
基于本体的金融知识图谱自动化构建技术
如何利用大模型构建知识图谱?如何利用大模型操作结构化数据?
知识图谱与大模型结合方法概述
利用知识图谱与Llama-Index技术构建大模型驱动的RAG系统(下)






 工商网监
工商网监
评论