 Linux内核内存管理之内核非连续物理内存分配
Linux内核内存管理之内核非连续物理内存分配
1 非连续内存区的线性地址
2 非连续内存区的描述符
3 申请非连续物理内存区
4 释放非连续内存区
5 vmalloc和kmalloc
我们已经知道,最好将虚拟地址映射到连续页帧,从而更好地利用缓存并实现更低的平均内存访问时间。然而,如果对内存区域的请求并不频繁,那么考虑基于通过连续线性地址访问非连续页帧的分配方案是有意义的。该模式的主要优点是避免了外部碎片,而缺点是需要修改内核页表。显然,非连续内存区域的大小必须是4096的倍数。Linux使用非连续物理内存区的场景有几种:(1)为swap区分配数据结构;(2)为模块分配空间(参见附录B);(3)或者为一些I/O驱动程序分配缓冲区。此外,非连续物理内存区还提供了另一种利用高端内存的方法。
1 非连续内存区的线性地址
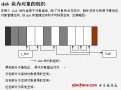
要查找线性地址的空闲范围,我们可以从PAGE_OFFSET开始的区域(通常是0xc0000000,3G→4G)。下图展示了这1G的线性地址的使用方式:
这1G大小的线性地址的第一部分是映射前896M物理内存的线性地址;与直接映射的物理内存的结尾对应的线性地址存储在high_memory变量中。
这1G大小的线性地址的最后部分是固定映射的线性地址。
从PKMAP_BASE线性地址开始,是高端内存页帧的永久内核映射使用的线性地址空间。
余下的线性地址空间用作非连续内存区域的映射。在前896M的线性地址之后与第一个非连续内存空间插入一个安全桩(大小为8M的地址间隔,使用宏VMALLOC_OFFSET获取该值),以便捕获越界内存访问。基于这个目的,后面每个非连续内存区域之间都插入一个4K大小的地址间隔。
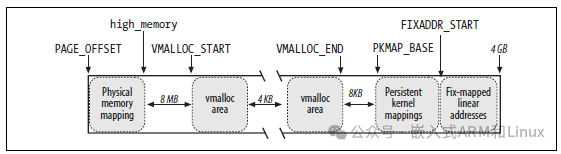
图8-8 内核地址空间的布局
VMALLOC_START宏定义了为非连续内存区保留的线性空间的起始地址,而VMALLOC_END定义了它的结束地址。
2 非连续内存区的描述符
每个非连续内存区都有一个类型为vm_struct的描述符进行表达,各个成员如下所示:
表8-13 vm_struct各个成员的描述
| 类型 | 名称 | 描述 |
|---|---|---|
| void * | addr | 该区域的第一个存储单元的线性地址 |
| unsigned long | size | 该区域的大小+4096(内存区域间的安全间隔) |
| unsigned long | flags | 映射的内存类型 |
| struct page ** | pages | 指向页描述符的nr_pages指针数组 |
| unsigned int | nr_pages | 该区域填充的页数 |
| unsigned long | phys_addr | 设置为0,除非是创建的内存区用来映射硬件设备的I/O共享内存 |
| struct vm_struct* | next | 指向下一个vm_struct结构 |
这些描述符通过“next”字段插入到一个简单的列表中;列表中第一个元素的地址存储在vmlist变量中。通过“vmlist_lock”读/写自旋锁保护对该列表的访问。flags字段标识该内存区映射的内存类型:VM_ALLOC用于通过vmalloc()获得的页面,VM_MAP用于通过vmap()映射的已经分配的页面(参见下一节),VM_IOREMAP用于通过ioremap()映射的硬件设备的板载内存(参见第13章)。
get_vm_area()负责在VMALLOC_START和VMALLOC_END之间找一段空闲的连续线性地址。这个函数作用于两个参数:size,要创建的内存区的字节数;flag,指定要创建的内存类型。执行以下步骤:
structvm_struct*__get_vm_area(unsignedlongsize,unsignedlongflags,
unsignedlongstart,unsignedlongend)
{
structvm_struct**p,*tmp,*area;
unsignedlongalign=1;
unsignedlongaddr;
//...省略
addr=ALIGN(start,align);
/*1.创建一个内核slab通用对象,
*保存vm_struct(一段虚拟内存的描述符)的内容
*/
area=kmalloc(sizeof(*area),GFP_KERNEL);
if(unlikely(!area))
returnNULL;
/*
*2.创建一个保护页(4K大小的间隔)
*/
size+=PAGE_SIZE;
if(unlikely(!size)){
kfree(area);
returnNULL;
}
/*3.获取用于写入的vmlist_lock锁,
*并扫描类型为vm_struct的描述符列表(也就是vmlist),
*查找至少包含size+4096的线性地址空间
*(4k是内存区域之间的安全间隔的大小)。
*/
write_lock(&vmlist_lock);
for(p=&vmlist;(tmp=*p)!=NULL;p=&tmp->next){
if((unsignedlong)tmp->addr< addr) {
if((unsigned long)tmp->addr+tmp->size>=addr)
addr=ALIGN(tmp->size+
(unsignedlong)tmp->addr,align);
continue;
}
if((size+addr)< addr)
goto out;
if (size + addr <= (unsigned long)tmp->addr)
gotofound;
addr=ALIGN(tmp->size+(unsignedlong)tmp->addr,align);
if(addr>end-size)
gotoout;
}
found:
/*4.如果找到合适的一段线性地址空间,
*则初始化申请的描述符并释放锁,
*然后返回描述符的地址。
*/
area->next=*p;
*p=area;
area->flags=flags;
area->addr=(void*)addr;
area->size=size;
area->pages=NULL;
area->nr_pages=0;
area->phys_addr=0;
write_unlock(&vmlist_lock);
returnarea;
out:
/*5.释放获得的描述符,并释放锁,并返回NULL*/
write_unlock(&vmlist_lock);
kfree(area);
returnNULL;
}
3 申请非连续物理内存区
vmalloc()函数为内核分配了一个非连续物理内存。参数size表示请求内存的大小。如果函数能够满足请求,则返回新区域的初始线性地址;否则,它返回一个NULL指针:
void*vmalloc(unsignedlongsize)
{
structvm_struct*area;
structpage**pages;
unsignedintarray_size,i;
//将size按照4k对齐
size=(size+PAGE_SIZE-1)&PAGE_MASK;
//创建新的页描述符并返回对应的线性地址
//标志是VM_ALLOC,表示非连续物理页帧将被映射到一段线性地址空间
area=get_vm_area(size,VM_ALLOC);
if(!area)
returnNULL;
area->nr_pages=size>>PAGE_SHIFT;
array_size=(area->nr_pages*sizeof(structpage*));
//申请一个数组的物理内存对象,保存页描述符指针数组
area->pages=pages=kmalloc(array_size,GFP_KERNEL);
if(!area_pages){
remove_vm_area(area->addr);
kfree(area);
returnNULL;
}
//将指针数组的元素清零。
memset(area->pages,0,array_size);
/*根据需要的内存页数,重复调用alloc_page函数
*给每一个页分配一个页帧,并将相应的页描述符存入数组中。
*注意,这儿使用数据保存页描述符是非常有必要的,
*因为这些页帧属于高端内存,它们不用映射为线性地址。
*/
for(i=0;inr_pages;i++){
area->pages[i]=alloc_page(GFP_KERNEL|__GFP_HIGHMEM);
if(!area->pages[i]){
area->nr_pages=i;
fail:vfree(area->addr);
returnNULL;
}
}
/*到这儿,我们已经获得了一段线性地址空间;
*也获得了一组非连续的物理页帧。那么关键的一步就是,
*修改页表项,将每个分配的页帧与一个线性地址建立映射关系
*实现的函数就是map_vm_area
*/
if(map_vm_area(area,__pgprot(0x63),&pages))
gotofail;
returnarea->addr;
}
将线性地址与非连续物理页帧建立映射关系由map_vm_area()函数实现,使用3个参数:
area:指向该内存区域的vm_struct描述符的指针。
prot:已分配页帧的保护位。总是设为0x63,对应于Present、Accessed、Read/Write和Dirty
pages: 指向页描述符指针数组的变量的地址(因此,struct page ***用作数据类型!)。
具体代码如下所示:
intmap_vm_area(structvm_struct*area,pgprot_tprot,structpage***pages)
{
/*1.获取线性地址的起始位置、结束位置*/
unsignedlongaddress=(unsignedlong)area->addr;
unsignedlongend=address+(area->size-PAGE_SIZE);
unsignedlongnext;
pgd_t*pgd;
interr=0;
inti;
/*2.使用pgd_offset_k宏在主内核PGD页全局目录中
*导出与该区域的初始线性地址相关的表项
*/
pgd=pgd_offset_k(address);
/*3.申请内核页表自旋锁*/
spin_lock(&init_mm.page_table_lock);
for(i=pgd_index(address);i<= pgd_index(end-1); i++) {
/* 4. 为新内存分配PUD页表中间目录,
* 并将其正确的物理地址写入PGD目录中
*/
pud_t *pud = pud_alloc(&init_mm, pgd, address);
if (!pud) {
err = -ENOMEM;
break;
}
/* 5. 分配与新PUD目录关联的所有页表。
* map_area_pud将单个PUD所跨越的线性地址范围的大小
* (如果启用了PAE,则为常数2^30,否则为2^22)加到当前的
* address值上,并增加指向PGD的指针pgd。
* 重复这个循环,直到所有指向非连续内存区的页表项都设置好。
*/
next = (address + PGDIR_SIZE) & PGDIR_MASK;
if (next < address || next >end)
next=end;
if(map_area_pud(pud,address,next,prot,pages)){
err=-ENOMEM;
break;
}
address=next;
pgd++;
}
spin_unlock(&init_mm.page_table_lock);
flush_cache_vmap((unsignedlong)area->addr,end);
returnerr;
}
map_area_pud()对PUD指向的所有页表也执行相似的循环:
do{
pmd_t*pmd=pmd_alloc(&init_mm,pud,address);
if(!pmd)
return-ENOMEM;
if(map_area_pmd(pmd,address,end-address,prot,pages))
return-ENOMEM;
address=(address+PUD_SIZE)&PUD_MASK;
pud++;
}while(address< end);
map_area_pmd()对PMD指向的所有页表也执行相似的循环:
do{
pte_t*pte=pte_alloc_kernel(&init_mm,pmd,address);
if(!pte)
return-ENOMEM;
if(map_area_pte(pte,address,end-address,prot,pages))
return-ENOMEM;
address=(address+PMD_SIZE)&PMD_MASK;
pmd++;
}while(address< end);
pte_alloc_kernel()函数分配一个新页表,并更新PMD页中间目录的对应表项。接下来,调用map_area_pte()为新页表中的每一项分配物理页帧。变量address的值增加2^22(正好是一个PMD页表中一项跨越的线性地址范围。
map_area_pte()主要工作是:
do{
structpage*page=**pages;
set_pte(pte,mk_pte(page,prot));
address+=PAGE_SIZE;
pte++;
(*pages)++;
}while(address< end);
要映射的页帧的页描述符地址page从地址pages的变量所指向的数组项中读取。新页帧的物理地址通过set_pte和mk_pte宏写入页表。在为地址添加常数4096(页帧的长度)后,重复这个循环。
注意,map_vm_area()还没有修改当前进程的页表。因此,当内核态的进程访问非连续内存区域时,就会发生Page Fault,因为进程页表中没有该区域的映射关系。然而,Page Fault处理程序根据主内核页表(即init_mm.pgdPGD页全局目录及其子页表)检查错误的线性地址;一旦处理器发现一个主内核页表包含一个非空的地址项,它就把它的值复制到相应进程的页表项中,然后恢复进程的正常执行。该机制在第9章的“页面错误异常处理程序”一节中进行了描述。
除了vmalloc()之外,非连续内存区的分配还可以由vmalloc_32()完成。它与vmalloc()类似,但是只分配ZONE_NORMAL和ZONE_DMA内存区。
Linux v2.6还有一个vmap()函数,它映射已经在非连续内存区中分配的页帧:本质上,这个函数接收一个指向页描述符的指针数组作为它的参数,调用get_vm_area()来获得一个新的vm_struct描述符,然后调用map_vm_area()来映射页帧。因此,该函数类似于vmalloc(),但它不分配页帧。
所以说,vmalloc和vmap的操作,大部分的逻辑是一样的,比如从VMALLOC_START ~ VMALLOC_END非连续物理内存映射区之间查找并分配vmap_area。不同之处,在于vmap建立映射时,page是函数传入进来的,而vmalloc是通过调用alloc_page接口向Buddy系统申请分配的。
4 释放非连续内存区
vfree()函数释放由vmalloc()或vmalloc_32()创建的非连续内存区域,而vunmap()函数释放由vmap()创建的内存区域。两个函数都有一个参数-待释放区域的初始线性地址的地址;它们都依赖于__vunmap()函数来完成实际的工作。
__vunmap()函数接收两个参数:要释放的区域的初始线性地址的地址addr和标志deallocate_pages,如果在该区域中映射的页帧应该被释放到ZONE页帧分配器(vfree()调用),则设置该标志,否则将被清除(vunmap()调用)。该函数的主要功能如下:
void__vunmap(void*addr,intdeallocate_pages)
{
//...省略
/*1.获取vm_struct描述符的地址;
*解除非连续物理内存与线性地址在页表中的映射关系。
*/
area=remove_vm_area(addr);
if(unlikely(!area)){
//...省略
return;
}
if(deallocate_pages){
inti;
/*
*2.扫描页描述符指针数据;对数组每个元素调用__free_page(),
*将页帧释放回`ZONE`页帧分配器中。
*/
for(i=0;i< area->nr_pages;i++){
//...省略
__free_page(area->pages[i]);
}
if(area->nr_pages>PAGE_SIZE/sizeof(structpage*))
vfree(area->pages);
else
/*释放指针数组,因为它是从连续物理内存中申请的,
*所以调用kfree
*/
kfree(area->pages);
}
/*3.释放vm_struct描述符*/
kfree(area);
return;
}
remove_vm_area()执行下面的循环:
structvm_struct*remove_vm_area(void*addr)
{
structvm_struct**p,*tmp;
//申请锁
write_lock(&vmlist_lock);
/*搜索从addr开始的内核虚拟内存区域,
*找到要释放的线性地址区域area
*/
for(p=&vmlist;(tmp=*p)!=NULL;p=&tmp->next){
if(tmp->addr==addr)
gotofound;
}
write_unlock(&vmlist_lock);
returnNULL;
found:
/*释放area*/
unmap_vm_area(tmp);
*p=tmp->next;
write_unlock(&vmlist_lock);
returntmp;
}
write_lock(&vmlist_lock);
for(p=&vmlist;(tmp=*p);p=&tmp->next){
if(tmp->addr==addr){
unmap_vm_area(tmp);
*p=tmp->next;
break;
}
}
write_unlock(&vmlist_lock);
returntmp;
map_vm_area()函数的内容如下所示,执行与map_vm_area()函数相逆的过程:
address=area->addr;
end=address+area->size;
pgd=pgd_offset_k(address);
for(i=pgd_index(address);i<= pgd_index(end-1); i++) {
next = (address + PGDIR_SIZE) & PGDIR_MASK;
if (next <= address || next >end)
next=end;
unmap_area_pud(pgd,address,next-address);
address=next;
pgd++;
}
继而,unmap_area_pud()执行与map_area_pud()相逆的过程:
do{
unmap_area_pmd(pud,address,end-address);
address=(address+PUD_SIZE)&PUD_MASK;
pud++;
}while(address&&(address< end));
unmap_area_pmd()执行与map_area_pmd()相逆的过程:
do{
unmap_area_pte(pmd,address,end-address);
address=(address+PMD_SIZE)&PMD_MASK;
pmd++;
}while(address< end);
最后,unmap_area_pte()执行与map_area_pte()相逆的过程:
do{
pte_tpage=ptep_get_and_clear(pte);
address+=PAGE_SIZE;
pte++;
if(!pte_none(page)&&!pte_present(page))
printk("Whee...Swappedoutpageinkernelpagetable
");
}while(address< end);
在循环的每次迭代中,pte指向的页表项被ptep_get_and_clear宏设置为0。
至于vmalloc(),内核修改主内核页全局目录及其子页表的项(参见第2章的“内核页表”一节),但它保持进程页表映射第4G的项不变。这很好,因为内核永远不会回收基于主内核页全局目录的页上目录(PUD)、页中间目录(PMD)和页表。
例如,假设内核态进程访问了一个非连续内存区域,该内存区域随后被释放。进程的PGD项等于主内核PGD的相应项,这要归功于第9章“Page Fault异常处理程序”一节中解释的机制;它们指向相同的页上目录、页中间目录和页表。unmap_area_pte()函数只清除页表的项(不回收页表本身)。由于页表项为空,进程对释放的非连续内存区域的进一步访问将触发Page fault。然而,处理程序会认为这样的访问是一个错误,因为主内核页表不包括有效的项。
5 vmalloc和kmalloc
到现在,我们应该能清楚vmalloc和kmalloc的差异了吧,kmalloc会根据申请的大小来选择基于slab分配器或者基于buddy系统来申请连续的物理内存。而vmalloc则是通过alloc_page申请order = 0的页面,再映射到连续的虚拟空间中,物理地址不连续。此外vmalloc可以休眠,不应在中断处理程序中使用。与vmalloc相比,kmalloc使用ZONE_DMA和ZONE_NORMAL空间,性能更快,缺点是连续物理内存空间的分配容易带来碎片问题,让碎片的管理变得困难。
审核编辑:汤梓红
-
内核
+关注
关注
3文章
1362浏览量
40216 -
Linux
+关注
关注
87文章
11219浏览量
208872 -
内存管理
+关注
关注
0文章
168浏览量
14122
原文标题:Linux内核8.8-内存管理之内核非连续物理内存分配
文章出处:【微信号:嵌入式ARM和Linux,微信公众号:嵌入式ARM和Linux】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

Linux内核内存管理架构解析

鸿蒙内核源码分析: 虚拟内存和物理内存是怎么管理的






 工商网监
工商网监
评论